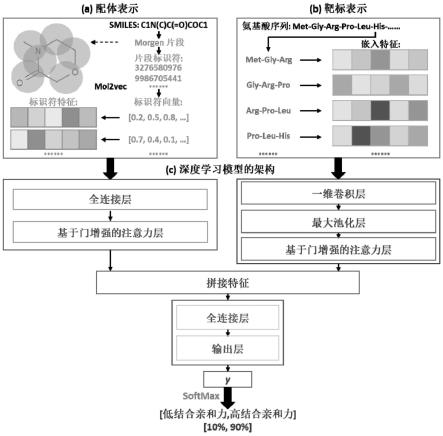
技术特征:
1.基于门控注意力机制的靶标-配体结合亲和力的深度学习预测方法,其特征在于,包括以下具体步骤:步骤1:建立结合亲和力数据库,用于后续的深度学习模型;步骤2:将配体的smiles字符串转换为配体矩阵,作为深度学习模型的输入;步骤3:将蛋白质的氨基酸序列转换为蛋白质矩阵,作为深度学习模型的输入;步骤4:构建用于模型训练的深度学习模型的架构,将配体矩阵送到一个全连接层和一个基于门增强的注意力层用于特征提取,通过矩阵行的加和方式来聚合配体片段的特征向量;步骤5:将蛋白质矩阵先送到一维卷积层和最大池化层,以减少蛋白质矩阵的行数,然后再送入基于门增强的注意力层用于特征提取,通过矩阵行的加和方式来聚合蛋白质高阶氨基酸的特征向量;步骤6:将聚合后的配体片段的特征向量与蛋白质高阶氨基酸的特征向量拼接在一起送入后续的全连接层以预测靶标-配体复合物的高/低结合亲和力的概率。2.根据权利要求1所述的基于门控注意力机制的靶标-配体结合亲和力的深度学习预测方法,其特征在于,步骤1具体包括:根据以下标准对结合亲和力数据库进行预处理:步骤1.1:删除涉及ic
50
性质的条目,保留涉及k
i
和k
d
性质的条目;步骤1.2:删除rdkit工具读取配体结构文件失败或mol2vec方法找不到配体morgen片段的条目;步骤1.3:分别删除morgen片段或氨基酸数大于阈值的靶标-配体复合物条目;步骤1.4:k
i/d
<n的靶标-配体复合物标记为高结合亲和力,用“1”表示,而k
i/d
≥n的靶标-配体复合物标记为低结合亲和力,用“0”表示,k
i/d
表示k
i
或k
d
,n表示抑制或解离常数阈值;最后,在应用上述步骤1.1-1.4标准后,获得独特的靶标-配体复合物样本存储在结合亲和力数据库中,用于后续的深度学习模型。3.根据权利要求1所述的基于门控注意力机制的靶标-配体结合亲和力的深度学习预测方法,其特征在于,步骤2具体包括:步骤2.1:使用morgan算法将分子的smiles字符串表示转换为morgen片段;步骤2.2:将mol2vec中的morgen片段的特征向量嵌入到步骤2.1得到的morgen片段中;将每个分子的morgen片段的特征向量求和来表示整个分子的特征向量;步骤2.3:基于mol2vec描述符,每个配体样本由一个二维矩阵表示,其中矩阵行表示morgen片段,矩阵列表示片段的特征向量。4.根据权利要求1所述的基于门控注意力机制的靶标-配体结合亲和力的深度学习预测方法,其特征在于,步骤3具体包括:步骤3.1:将蛋白质序列中每三个相邻的氨基酸视为一个高阶氨基酸;通过这种方式,将结合亲和力数据库中的蛋白质编写成高阶氨基酸字符串;步骤3.2:通过深度学习模型中的嵌入方法,给每个高阶氨基酸字符串嵌入一个特征向量;步骤3.3:每个蛋白质样本由一个二维矩阵表示,其中,矩阵行表示高阶氨基酸字符串,矩阵列表示高阶氨基酸字符串的特征向量。
5.根据权利要求1所述的基于门控注意力机制的靶标-配体结合亲和力的深度学习预测方法,其特征在于,步骤4具体包括:步骤4.1:将配体矩阵x
l
送到全连接层v以将配体特征的维数降低;步骤4.2:将获得的降维后的配体矩阵x
′
l
送到基于门增强的注意力层;在注意力层中,x
′
l
首先通过一个可学习的权重矩阵w1进行变换,以获得具有显著特征的新配体矩阵x
″
l
;步骤4.3:通过方程得到注意力系数e
ij
,其中e
ij
表示第j个片段特征对第i个片段特征的重要性,通过求和和来强制e
ij
等于e
ji
;步骤4.4:将e
ij
送到一个softmax激活函数,通过a
ij
=exp(e
ij
)/∑
j
exp(e
ij
)等式得到归一化的注意力系数a
ij
;步骤4.5:利用得到的a
ij
,通过x
″′
l,i
=∑
j
a
ij
x
″
l,j
等式将每个片段特征更新为相邻片段特征的线性组合,并且随后将relu激活函数添加到x
″′
l,i
;步骤4.6:应用门增强算法,通过前一个片段特征x
′
l,i
和x
″′
l,i
的线性组合使用方程来获得基于门增强的注意力层的输出片段特征z
i
表示为z
i
=σ((x
′
l,i
||x
″′
l,i
)u)并解释为x
′
l,i
和x
″′
l,i
传递给的权重系数,其中u是可学习向量,σ表示sigmoid激活函数,(
·
||
·
)是拼接两个向量的操作符;步骤4.7:通过等式,将配体片段的特征向量相加成一个表示配体特征的向量。6.根据权利要求1所述的基于门控注意力机制的靶标-配体结合亲和力的深度学习预测方法,其特征在于,步骤5具体包括:步骤5.1:将蛋白质矩阵x
p
送到一维卷积层和最大池化层;通过这种方式,一维卷积层和最大池化层能够从整个蛋白质序列中提取关键的高阶氨基酸,这有助于将氨基酸特征集中在靶标-配体复合物的口袋区域,同时减少模型冗余并节省下一个注意力层的计算时间成本;步骤5.2:将步骤5.1处理的蛋白质矩阵x
′
p
送到基于门增强的注意力层;在注意力层中,x
′
p
首先通过一个可学习的权重矩阵w2进行变换,以获得具有显著特征的新蛋白质矩阵x
″
p
;步骤5.3:通过方程得到注意力系数e
kl
,其中e
kl
表示第l个高阶氨基酸特征对第k个高阶氨基酸特征的重要性,通过求和和来强制e
kl
等于e
lk
;步骤5.4:将e
kl
送到一个softmax激活函数,通过a
kl
=exp(e
kl
)/∑
l
exp(e
kl
)等式得到归一化的注意力系数a
kl
;步骤5.5:利用得到的a
kl
,通过x
″′
p,k
=∑
l
a
kl
x
″
p,l
等式将每个高阶氨基酸特征更新为相邻高阶氨基酸特征的线性组合,并且随后将relu激活函数添加到x
″′
p,k
;步骤5.6:应用门增强算法,通过前一个高阶氨基酸特征x
′
p,k
和x
″′
p,k
的线性组合使用方程来获得基于门增强的注意力层的输出高阶氨基酸特征z
k
表示为z
k
=σ((x
′
p,k
||x
″′
p,k
)u)并解释为x
′
p,k
和x
″′
p,k
传递给的权重系数,其中u是可学习向量,σ表示sigmoid激活函数,(
·
||
·
)是拼接两个向量的操作符;
步骤5.7:通过等式,获得最终输出蛋白质特征的向量7.根据权利要求1所述的基于门控注意力机制的靶标-配体结合亲和力的深度学习预测方法,其特征在于,步骤6具体包括:步骤6.1:将输出的配体特征向量和输出的蛋白质特征向量拼接起来以表示靶标-配体复合物特征;步骤6.2:随后将特征送到含logsoftmax激活函数的全连接层和含logsoftmax激活函数的输出层;步骤6.3:在输出层之前还添加了一个dropout层,以克服训练过程中的过拟合问题;在训练过程之外执行额外的softmax运算从而归一化模型输出。
技术总结
本发明涉及基于门控注意力机制的靶标-配体结合亲和力的深度学习预测方法,属于计算机辅助药物设计技术以及生物和药物信息学领域。深度学习模型从配体的SMILES字符串和蛋白质的氨基酸序列开始,然后分别转换为配体矩阵和蛋白质矩阵。配体矩阵被送到全连接层和基于门增强的注意力层用于特征提取,将蛋白质矩阵送到一维卷积层和最大池化层,然后再送入基于门增强的注意力层。最后,通过矩阵行的加和来聚合配体矩阵的处理特征,并对蛋白质矩阵执行相同的过程,然后将两者拼接在一起送入后续的全连接层以预测蛋白质-配体复合物的高/低结合亲和力的概率。本发明有效减少与实验分析相关的时间和成本,提高药物设计和虚拟筛选的效率。率。率。
技术研发人员:刘奇磊 都健 赵雨靓 张磊 吴心远 孟庆伟
受保护的技术使用者:大连理工大学
技术研发日:2022.04.15
技术公布日:2022/7/12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。