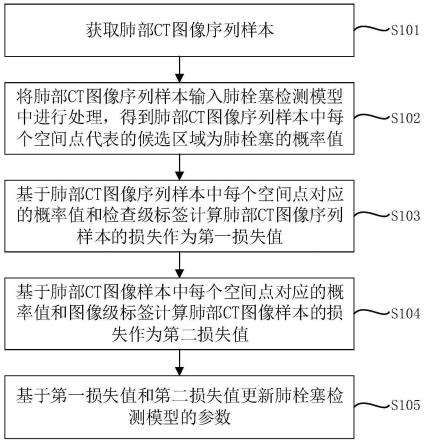
创建fpga电路的时延表和获取时延的方法及设备
技术领域:
:1.本发明涉及集成电路
技术领域:
:,尤其涉及创建现场可编程门阵列(field-programmablegatearray,fpga)电路的时延表和获取fpga电路的时延的方法及设备。
背景技术:
::2.fpga芯片的设计流程主要包括设计输入、功能仿真、逻辑综合、技术映射、逻辑打包、布局、布线、时序仿真、比特流生成等阶段,其中,逻辑打包、布局、布线等物理实现阶段是很复杂和关键的一个阶段,其结果直接影响了电路性能、面积、可靠性、功率和制造产量等。3.随着制造工艺的进步,fpga芯片中连接线的寄生参数(如寄生电容、电阻、电感)在不断增大,连接线的时延也随之增大,使得fpga电路的设计难以满足时序约束。技术实现要素:4.本发明解决的技术问题包括连接线的时延使得fpga电路的设计难以满足时序约束等。5.本发明实施例提供一种创建fpga电路的时延表的方法,fpga电路包括多个slice,时延表包括内部时延表,该方法包括:确定从多个slice中每个slice内部的输入引脚到其输出引脚的若干线路;基于若干线路分别计算出从输入引脚到输出引脚的内部时延;将每个slice的若干线路分别对应的输入引脚、输出引脚和这二个引脚之间相应的内部时延保存于内部时延表中。6.可选地,时延表包括引脚时延表,该创建fpga电路的时延表的方法包括:计算多个slice中每个slice的输出引脚到与其紧邻且位于其下游的第一连接盒的输出引脚时延;计算多个slice中每个slice的输入引脚到与其紧邻且位于其上游的第二连接盒的输入引脚时延;将每个slice的输出引脚和与其对应的输出引脚时延、以及输入引脚和与其对应的输入引脚时延都保存于引脚时延表中。7.可选地,slice包括lut、ff和mux,输入引脚包括lut的输入端,输出引脚包括lut的输出端、ff的输出端和mux的输出端。8.可选地,时延表包括路径时延表,该创建fpga电路的时延表的方法包括:基于任意二个slice的坐标、一者的输出引脚和另一者的输入引脚、以及这二个slice之间经过的若干线段确定从与输出引脚紧邻且位于其下游的第一连接盒到与输入引脚紧邻且位于其上游的第二连接盒的路径;通过如下公式计算路径的路径时延、并且将任意二个slice的坐标、一者的输出引脚和另一者的输入引脚和路径时延保存于路径时延表中:[0009][0010]其中,path_delay表示路径时延,ini_delay表示初始时延,m表示路径经过的线段类型的个数,ni表示第i类线段的个数,base_delayi表示第i类线段的基本时延。[0011]可选地,线段类型基于线段的长度和方向而确定。[0012]可选地,时延表包括修正时延表,该创建fpga电路的时延表的方法包括:基于任意二个slice的坐标、一者的输出引脚和另一者的输入引脚确定从输出引脚到输入引脚的路径;确定路径上经过的非slice模块的类型和数量;基于非slice模块的类型和数量确定路径的修正时延;将任意二个slice的坐标、一者的输出引脚、另一者的输入引脚以及路径的修正时延保存于修正时延表中。[0013]可选地,非slice模块的类型包括dsp和ram。[0014]可选地,修正时延表包括第一表和第二表,该创建fpga电路的时延表的方法包括:通过第一表的相关行记录一条路径中分别经过各个非slice模块的各个线段在第二表中对应的行数;第二表的各行分别记录与各个线段中的连线分别对应的电阻值和电容值;通过如下公式计算经过非slice模块的修正时延:[0015]τ2=in2(r1c1 (r1 r2)c2),[0016]其中,τ2表示经过非slice模块的修正时延,in2表示以e为底的对数的值的平方,r1和c1分别表示非slice模块连接与其紧邻并且位于上游的连接盒的连线所对应的电阻值和电容值,r2和c2分别表示非slice模块连接与其紧邻并且位于下游的连接盒的连线所对应的电阻值和电容值。[0017]本发明实施例还提供一种创建fpga电路的时延表的设备,包括存储器和处理器,存储器上存储有可在处理器上运行的计算机指令,处理器运行计算机指令时执行上述任一种创建fpga电路的时延表的方法的步骤。[0018]本发明实施例还提供一种获取fpga电路的时延的方法,包括:基于源slice的输出引脚和终端slice的输入引脚从内部时延表中分别获取源slice的内部时延和终端slice的内部时延;基于源slice的输出引脚和终端slice的输入引脚从引脚时延表中分别获取源slice的输出引脚时延和终端slice的输入引脚时延;基于源slice的坐标和输出引脚、以及终端slice的坐标和输入引脚从路径时延表中获取从与输出引脚紧邻且位于其下游的第一连接盒到与输入引脚紧邻且位于其上游的第二连接盒的路径时延;通过如下公式计算从源slice到终端slice的第一总时延:[0019]total_delay1=inertal_delay pin_delay path_delay,[0020]其中,total_delay1表示第一总时延,inertal_delay表示内部时延,其包括源slice的内部时延和终端slice的内部时延,pin_delay表示引脚时延,其包括源slice的输出引脚时延和终端slice的输入引脚时延,path_delay表示路径时延。[0021]可选地,该获取fpga电路的时延的方法包括:基于源slice的坐标和输出引脚、以及终端slice的坐标和输入引脚从修正时延表中获取从输出引脚到输入引脚的修正时延;通过如下公式计算从源slice到终端slice的第二总时延:[0022]total_delay2=inertal_delay pin_delay path_delay modify_delay,[0023]其中,total_delay2表示第二总时延,modify_modify表示修正时延。[0024]本发明实施例还提供一种获取fpga电路的时延的设备,包括存储器和处理器,存储器上存储有可在处理器上运行的计算机指令,处理器运行计算机指令时执行上述任一种获取fpga电路时延的方法的步骤。[0025]与现有技术相比,本发明实施例的技术方案具有有益的技术效果。[0026]例如,本发明实施例所创建的fpga电路的时延表包括内部时延表,由于fpga芯片为基于模块的阵列结构,而模块的内部时延在线网或者路径的总时延中占有很大的一部分,通过计算该内部时延,可以使得总时延的估计较为准确,从而使得基于该估计所设计或者优化的fpga电路能够满足时序约束。[0027]又例如,本发明实施例所创建的fpga电路的时延表包括引脚时延表、路径时延表和修正时延表中的一个或多个,基于这些时延表而计算出的总时延较为准确,从而使得基于该估计所设计或者优化的fpga电路能够满足时序约束。[0028]又例如,本发明实施例所创建的fpga电路的时延表包括内部时延表、引脚时延表、路径时延表和修正时延表中的一个或多个,将总的时延具体区分为内部时延、引脚时延、路径时延和修正时延,其考虑到fpga芯片的内部结构和资源分布十分对称,例如,模块结构一致性(即,在不同位置上同一类型模块的内部时延基本一致)、路径相关性(即,经过相同模块或使用相同线段的路径所产生的时延基本一致)、距离相关性(即,距离恒定的两个模块在fpga不同位置上,其对应的时延基本一致)、竖直对称性(即,fpga每一列只包含一种类型的模块,模块上下平移后的总时延一致);不同位置处的相同元件(例如,相同的可配置逻辑块(configurablelogicblock,clb),相同的基本可编程逻辑单元slice(其位于clb内),相同的查找表(lookuptable,lut)、触发器(ff)、多路选择器(mux)等电路元素(其位于slice内))的时延是基本相同的,该时延仅与这些模块、slice或者电路元素的位置和输入和输出引脚的布置相关,从而可以通过较少的存储空间来记录这些时延。这使得时延的计算可以基于fpga芯片内部的对称性而减少冗余计算,还可以减少与记录时延信息相关的存储空间,又可以减少查找这些时延信息的时间,从而可以准确而高效地估计时延。[0029]又例如,本发明实施例所创建的fpga电路的时延表可以用于在fpga的打包、布局、布线以及时序仿真等物理实现阶段估计电路的时延,并且,基于该估计的时延可以快速而有效地进行逻辑打包、布局和布线,以及进行相应的时序分析,以避免电路存在时序错误,并且保证关键路径具有正常的时序。附图说明[0030]图1是本发明实施例中fpga芯片的阵列结构的示意图;[0031]图2是本发明实施例中fpga芯片中连接线资源的示意图;[0032]图3是本发明实施例中分布式rc模型的示意图;[0033]图4是本发明实施例中创建fpga电路的时延表的流程图;[0034]图5是本发明实施例中slice内输入引脚和输出引脚的示意图;[0035]图6是本发明实施例中从源slice到终端slice的路径的示意图;[0036]图7是本发明实施例中slice的结构示意图;[0037]图8是本发明实施例中从源slice经过若干模块到终端slice的示意图;[0038]图9是本发明实施例中经过非slice模块的路径的示意图;[0039]图10是本发明实施例中非slice模块及其连线示意图;[0040]图11是本发明实施例中获取fpga电路时延的流程图。具体实施方式[0041]为使本发明实施例的上述目的、特征和有益效果能够更为明显易懂,下面结合附图对本发明的具体实施例进行详细说明。[0042]如图1所示,fpga芯片采用规则的阵列结构;可以以阵列的中心为原点,水平向右和左的方向分别为x轴的正和负方向(“x方向”),竖直向上和下的方向分别为y轴的正和负方向(“y方向”)。[0043]阵列中的点可以为模块,模块包括clb、随机存取存储器(randomaccessmemory,ram)、可编程输入输出单元(inputoutputblock,iob)、数字信号处理模块(digitalsignalprocessor,dsp)等。[0044]在fpga芯片内部,数量最多的是clb,其是最基本的模块;1个clb通常包括2个slice,可用于实现组合逻辑电路以及时序逻辑电路。[0045]如图2所示,fpga芯片还包括大量的连接线资源,例如,连接盒(connectionbox,cb)、开关盒(switchbox,sb)和许多线段(segment),cb主要用于将clb的输入、输出端与布线资源相连,sb则位于横竖布线通道的交点处,用于选择连接的segment,sb描述了通过可选择的可编程互连点(programmableinterconnectionpoint,pip)以将任意一条segment转换到其余segment的拓扑连接关系,通过cb、sb和pip连接的多个segment可以形成从一个slice到另一个slice的线网(net)。[0046]在深亚米制造工艺下,fpga芯片的线网中源点(source)到终点(sink)的路径上连接线或导线的寄生参数(如寄生电阻、电容)对时延的影响不可忽视。可以采用电阻-电容模型(rc模型)来近似,但是,将一段导线的电阻和电容基于集总模型而作为1个电阻和1个电容是不太精确的。[0047]本发明实施例提供分布式的rc模型。[0048]如图3所示,可以将一段导线分为n段,ri和ci表示其中某段的电阻和电容,i为不小于1且不大于n的整数;该导线的时延可以通过如下公式计算:[0049]τ1=r1c1 … (r1 … ri)ci … (r1 … rn)cnꢀꢀ(1)[0050]其中,τ1表示该段导线的时延,r1、ri和rn分别表示第1、i和n段导线的电阻,c1、ci和cn分别表示第1、i和n段导线的电容。[0051]如果n为1,则公式(1)为集总模型的计算方式;n取值越大,则公式(1)的计算结果越精确。[0052]图4是本发明实施例中创建fpga电路的时延表方法100的具体流程图,其中,fpga电路包括多个slice,时延表包括内部时延表。[0053]在本发明的实施例中,fpga芯片基于slice而非clb等模块进行布局布线,这一方面增加了布局布线的灵活性,另一方面提高了时延计算的精确性。[0054]如图5所示,1个slice包括多个输入引脚(inputpin)、多个输出引脚(outputpin)、lut、ff、mux以及进位链。[0055]fpga芯片内任意二个slice之间可以形成路径,例如,由源slice(slice_source)的inputpin或outputpin到终端slice(slice_sink)的outputpin或inputpin的路径。[0056]如图6所示,信号从slice_source的inputpin(即其中lut的输入端)、经其outputpin、第一cb(cb1)、sb、第二cb(cb2)到slice_sink的inputpin(即其中lut的输入端)。slice_source的坐标为(x_loc1,y_loc1),slice_sink的坐标为(x_loc2,y_loc2)。[0057]图6示意了从slice_source到slice_sink的路径仅经过2个cb和1个sb,应理解,从slice_source到slice_sink的路径可以经过多个cb、多个sb、多个slice、若干个dsp和/或若干个ram等。[0058]方法100可以包括步骤110、120和130。[0059]在步骤110的执行中,确定从多个slice中每个slice的inputpin到其outputpin的若干线路。[0060]slice的内部时延表示从slice的一个输入端到其输出端所产生的时延,包括slice内部走线所产生的时延、以及经过电路元素lut、mux、ff等产生的时延。[0061]1个slice可以包括4个lut、若干个ff和mux。[0062]图7示意了1个slice中的1个lut(即luta,其余3个未示出的lut可以表示为lutb、lutc和lutd)、1个ff和1个mux。[0063]每个lut可以具有若干个输入端,例如,luta的6个输入端(从a1、a2至a6),lutb的6个输入端(从b1、b2至b6),lutc的6个输入端(从c1、c2至c6),lutd的6个输入端(从d1、d2至d6)。[0064]每个lut可以具有1个输出端,例如,luta的输出端(pin_a),lutb的输出端(pin_b),lutc的输出端(pin_c),lutd的输出端(pin_d)。[0065]mux具有输出端pin_mux、ff具有输出端pin_q。在1个slice内,mux和ff都可以具有多个,相应地,输出端pin_mux和pin_q也都可以具有多个,例如,与luta相关的输出端pin_muxa和pin_qa,与lutb相关的输出端pin_muxb和pin_qb,与lutc相关的输出端pin_muxc和pin_qc,与luta相关的输出端pin_muxd和pin_qd。[0066]4个lut各自的输入端都可以称为slice的inputpin,4个lut各自的输出端、mux的输出端以及ff的输出端都可以称为slice的outputpin。[0067]如图7所示,在1个slice内部,从其inputpin到outputpin具有若干线路,包括:从lut的输入端到lut的输出端的线路(第一线路),从lut的输入端、经mux到mux的输出端的线路(第二线路),从lut的输入端、经ff和mux到mux的输出端的线路(第三线路),从lut的输入端、经ff到ff的输出端的线路(第四线路);其中,第一线路和第二线路为组合逻辑电路,第三线路和第四线路为时序逻辑电路。[0068]在步骤120的执行中,基于若干线路分别计算出从inputpin到outputpin的内部时延。[0069]在1个slice内,各个inputpin到各个outputpin的多条线路中的每一条线路都可以被电路元素(例如lut、ff、mux)分成若干段连线(wire),每一段wire都具有电阻和电容,从而形成类似于图3的电路,并且可以通过公式(1)分别计算每一条线路的内部时延;其中,inputpin包括4个lut各自的输入端,outputpin包括4个lut各自的输出端、mux的输出端以及ff的输出端。[0070]在步骤130的执行中,将每个slice的若干线路分别对应的inputpin、outputpin和相应的内部时延保存于内部时延表中。[0071]如表1示意,luta的各输入端作为inputpin以及luta的输出端、mux的输出端和ff的输出端均作为outputpin时分别对应的时延记录于内部时延表a。[0072]表1[0073][0074][0075]在表1中,由inputpin到pin_mux的路径包括经过ff和未经过ff的路径,前者的时延类型属于时序时延(sequentialdelay),后者的时延类型属于组合时延(combinationaldelay),其中sequentialdelay表示时序电路所产生的时延,combinationaldelay表示组合电路所产生的时延;由inputpin到pin_a的路径属于combinationaldelay;由inputpin到pin_q的路径属于sequentialdelay。[0076]lutb的各输入端作为inputpin以及lutb的输出端、mux的输出端和ff的输出端均作为outputpin时分别对应的时延记录于内部时延表b;lutc的各输入端作为inputpin以及lutc的输出端、mux的输出端和ff的输出端均作为outputpin时分别对应的时延记录于内部时延表c;lutd的各输入端作为inputpin以及lutd的输出端、mux的输出端和ff的输出端均作为outputpin时分别对应的时延记录于内部时延表d。内部时延表b、c和d均与内部时延表a的结构类似。[0077]由于slice内部的电路和引脚在fpga芯片制造完成后就已经确定,相关的内部时延也已确定,因此,可以将inputpin、outputpin和这二个引脚之间的内部时延保存于内部时延表中,以便于在需要的时候读取。[0078]在本发明的实施例中,时延表可以包括引脚时延表。[0079]任一个slice中各inputpin都具有与其紧邻的cb,可以计算该cb到对应的inputpin这段走线的时延(从信号传输的路径看,该cb位于inputpin的上游),例如通过公式(1)计算这段走线的时延;该时延与inputpin相关,其可称为inputpin时延。[0080]在本发明的各实施例中,上游、下游基于信号的流向而确定;即,靠近slice_source的方向为上游方向,靠近slice_sink的方向为下游方向。[0081]如图6所示,cb2到slice_sink的inputpin的时延即为inputpin时延。[0082]如表2示意,luta的各输入端作为inputpin,位于这些inputpin的上游且与之紧邻的cb到该inputpin的这段走线的时延记录于引脚时延表a。[0083]表2[0084][0085]lutb的各输入端作为inputpin,位于这些inputpin的上游且与之紧邻的cb到该inputpin的这段走线的时延记录于引脚时延表b;lutc的各输入端作为inputpin,位于这些inputpin的上游且与之紧邻的cb到该inputpin的这段走线的时延记录于引脚时延表c;lutd的各输入端作为inputpin,位于这些inputpin的上游且与之紧邻的cb到该inputpin的这段走线的时延记录于引脚时延表d。引脚时延表b、c和d均与引脚时延表a的结构类似。[0086]可以计算任一个slice中各outputpin到与其紧邻的cb的这段走线的时延(从信号传输的路径看,该cb位于outputpin的下游),例如通过公式(1)计算这段走线的时延;该时延与outputpin相关,其可称为outputpin时延。[0087]如图6所示,slice_source的outputpin到cb1的时延即为outputpin时延。[0088]如表3示意,lut的输出端、mux的输出端和ff的输出端作为outputpin到与其紧邻的cb的这段走线的时延记录于引脚时延表e。[0089]表3[0090][0091][0092]由于outputpin到与其紧邻且位于其下游的cb的这段走线以及inputpin到与其紧邻且位于其上游的cb的这段走线在fpga芯片制造完成后就已经确定,相关的outputpin时延以及inputpin时延也已确定,因此,可以将outputpin和与之对应的outputpin时延、以及inputpin和与之对应的inputpin时延都保存于引脚时延表中,以便于在需要的时候读取。[0093]在本发明的实施例中,引脚时延表a、b、c、d和e的内容可以保存于一张表内。[0094]在本发明的实施例中,时延表可以包括路径时延表。[0095]对于fpga芯片内的任意二个slice,其中一者和另一者可以分别作为slice_source和slice_sink,可以确定slice_source的坐标、slice_sink的坐标、slice_source的outputpin、slice_sink的inputpin、以及从slice_source到slice_sink所经过的若干segment,从而获得从与outputpin紧邻且位于其下游的cb到与inputpin紧邻且位于其上游的cb的路径。[0096]可以通过如下公式计算该路径的路径时延:[0097][0098]其中,path_delay表示路径时延,ini_delay表示初始时延(即经过与slice_source紧邻且位于其下游的cb所产生的时延),m表示该路径经过的线段类型的个数,ni表示第i类segment的个数,base_delayi表示第i类segment的基本时延。[0099]线段类型基于线段的长度和方向(如x方向、y方向)而确定。[0100]基于线段类型的基本时延base_delayi可以基于该线段中的一个或多个wire对应的电阻值和电容值以及公式(1)进行计算。[0101]一条segment可能经过多个sb,可以根据经过sb的数目定义segment的长度,例如,segment的长度可以为x1、x2、x4、x6、x12和x18,其分别表示segment的长度经过1、2、4、6、12和18个sb。[0102]如图8所示,slice_source和slice_sink之间的路径经过若干个cb,其中,相邻的cb之间通过一个sb连接;该路径包括3个x1类型的segment(其经过1个sb)和2个x2类型的segment(其经过2个sb)。[0103]该示例中,slice_source和slice_sink之间的路径时延可以根据公式(2)计算,大小为:ini_delay1 3*base1_delay 2*base2_delay,其中,ini_delay1表示该示例中的初始时延,bsae_delay1表示x1类型的segment的基本时延,base_delay2表示x2类型的segment的基本时延。[0104]可以将上述任意二个slice的坐标、一者的输出引脚和另一者的输入引脚和路径时延保存于路径时延表中。[0105]在本发明的实施例中,时延表可以包括修正时延表。[0106]可以基于任意二个slice的坐标、一者的outputpin和另一者的inputpin确定从outputpin到inputpin的路径,其中,一个slice为slice_source,另一个slice为slice_sink。[0107]slice包括于clb内,而非slice模块内没有slice,其类型包括dsp和ram。[0108]在从源slice到终端slice的路径可能会存在若干个非slice模块,其会使得时延发生变化。为了准确地估计路径的时延,需要考虑非slice模块产生的修正时延。[0109]如图9所示,从slice_source到slice_sink的路径上,经过ram和dsp,该路径的时延total_delay可以包括ram和dsp产生的修正时延modify_delay。[0110]修正时延的计算基于非slice模块的类型,不同类型的非slice模块,例如ram和dsp,具有不同的修正时延;还基于非slice模块的数量,数量越多,相应的修正时延也越大。[0111]可以基于路径上经过的非slice模块的类型和数量等确定该路径的修正时延。即,分别计算经过各类型非slice模块的修正时延,再基于不同类型slice模块的数量而将它们各自的修正时延相加,就可以得到该路径的修正时延。[0112]具体而言,可以先计算经过非slice模块的修正时延。[0113]如图10所示,非slice模块的上下游分别有与其紧邻的sb(即sb1、sb2),并且通过连线(wire)相互连接;其中,wire_1连接位于上游的sb1,wire_2连接位于下游的sb2,而wire_1和wire_2形成了经过该非slice模块的线段。[0114]可以通过如下公式计算经过该非slice模块的修正时延:[0115]τ2=in2(r1c1 (r1 r2)c2)ꢀꢀ(3)[0116]其中,τ2表示修正时延,in2表示以e为底的对数的值的平方,r1和c1分别表示wire1对应的电阻值和电容值,r2和c2分别表示wire2对应的电阻值和电容值。[0117]修正时延表可以包括第一表和第二表。[0118]第一表的各行可以记录一条路径上分别经过各个非slice模块的各个线段对应的数字,该数字对应第二表的行数;第二表的各行记录与经过非slice模块的线段中各个wire对应的电阻值和电容值。[0119]如表4示意,第1-5行对应5条路径,每条路径上具有经过一个或多个非slice模块的线段,例如,第一行包括4个线段,各自相关的电阻值和电容值可以在第二表的第122、133、12和19行查到。[0120]表4[0121][0122]可以从第二表的相应行获得经过一个非slice模块的线段中wire所对应的电阻值和电容值。[0123]如表5示意,第1-5行对应5个非slice模块或者与其相关的5个线段,其中,第2列表示非slice模块的横坐标和纵坐标,r1和c1表示经过非slice模块的线段中wire_1的电阻值和电容值,r2和c2表示经过非slice模块的线段中wire_2的电阻值和电容值。[0124]在一些情形中,wire_1和wire_2中的一者或者二者的电阻值和/或电容值为0。例如,表5的第3至5行中的每一行,wire_2的电阻值和电容值均为0,因此,该值未记录于表中。[0125]表5[0126][0127]在获得与一个非slice模块连接的wire所对应的电阻值和电容值后,可以基于公式(3)可以计算经过该非slice模块的修正时延;接着,可以分别计算第一表的一行中经过各个非slice模块的修正时延,并且累加各修正时延,从而获得一条路径的修正时延;然后,可以分别对第一表的各行进行类似的计算,从而获得fpga芯片中任意二个slice之间各个路径的修正时延。[0128]通过设置二张表(第一表和第二表),使得各个路径可以复用经过非slice模块的修正时延,这极大地节约了存储空间,相应地,减少了查找这些修正时延的时间。[0129]即使同一类型的非slice模块,如果其处于不同的位置,可能具有不同的位置时延。因此,修正时延可以包括基于非slice模块的位置而确定的位置时延。该位置时延可以基于测试而获得。[0130]可以将任意二个slice的坐标、一者的outputpin、另一者的inputpin以及该路径的修正时延保存于修正时延表中,从而可以基于二个slice的坐标、一者的outputpin、另一者的inputpin查找到对应路径的修正时延。[0131]本发明的实施例还提供一种创建fpga电路的时延表的设备,包括存储器和处理器,存储器上存储有可在所述处理器上运行的计算机指令,处理器运行计算机指令时执行上述结合图1至10所述的创建fpga电路的时延表的方法的步骤。[0132]本发明的实施例还提供一种根据上述时延表获取fpga电路时延的方法。[0133]在fpga芯片上进行布局布线后,可以进行时序仿真。可以选取任一条路径进行分析,以估计它的时延。该时延可以包括静态时延和动态时延。[0134]静态时延包括slice的内部时延和引脚时延,其与路径无关,只受设计的逻辑影响,在设计确定之后,slice的内部时延和引脚时延是静态不变的。[0135]动态时延包括路径时延和修正时延,其受到布局布线算法的影响,不同的算法可能会使得从起点到终点的路径不同,修正时延也可能不同,从而得到不同的时延结果。[0136]如图11所示,获取fpga电路时延的方法200包括步骤210、220、230和240。[0137]在步骤210的执行中,基于源slice的outputpin和终端slice的inputpin从内部时延表中分别获取源slice的内部时延和终端slice的内部时延。[0138]在步骤220的执行中,基于源slice的outputpin和终端slice的inputpin从引脚时延表中分别获取源slice的输出引脚时延和终端slice的输入引脚时延。[0139]在步骤230的执行中,基于源slice的坐标和outputpin、以及终端slice的坐标和inputpin从路径时延表中获取从与outputpin紧邻且位于其下游的cb到与inputpin紧邻且位于其上游的cb的路径时延。[0140]在步骤240的执行中,通过如下公式计算从源slice到终端slice的第一总时延:[0141]total_delay1=inertal_delay pin_delay path_delayꢀꢀ(4)[0142]其中,total_delay1表示第一总时延,inertal_delay表示内部时延,其包括源slice的内部时延和终端slice的内部时延,pin_delay表示引脚时延,其包括源slice的输出引脚时延和终端slice的输入引脚时延,path_delay表示路径时延。[0143]从从源slice到终端slice的总时延还可以包括路径的修正时延。[0144]可以基于源slice的坐标和outputpin、以及终端slice的坐标和inputpin从修正时延表中获取从outputpin到inputpin的修正时延。[0145]可以通过如下公式计算从源slice到终端slice的第二总时延:[0146]total_delay2=inertal_delay pin_delay path_delay modify_delayꢀꢀ(5)[0147]其中,total_delay2表示第二总时延,modify_delay表示修正时延。[0148]本发明的实施例还提供一种获取fpga电路时延的设备,包括存储器和处理器,存储器上存储有可在所述处理器上运行的计算机指令,处理器运行计算机指令时执行上述获取fpga电路时延的方法的步骤。[0149]虽然本发明披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。当前第1页12当前第1页12
技术领域:
:1.本发明涉及集成电路
技术领域:
:,尤其涉及创建现场可编程门阵列(field-programmablegatearray,fpga)电路的时延表和获取fpga电路的时延的方法及设备。
背景技术:
::2.fpga芯片的设计流程主要包括设计输入、功能仿真、逻辑综合、技术映射、逻辑打包、布局、布线、时序仿真、比特流生成等阶段,其中,逻辑打包、布局、布线等物理实现阶段是很复杂和关键的一个阶段,其结果直接影响了电路性能、面积、可靠性、功率和制造产量等。3.随着制造工艺的进步,fpga芯片中连接线的寄生参数(如寄生电容、电阻、电感)在不断增大,连接线的时延也随之增大,使得fpga电路的设计难以满足时序约束。技术实现要素:4.本发明解决的技术问题包括连接线的时延使得fpga电路的设计难以满足时序约束等。5.本发明实施例提供一种创建fpga电路的时延表的方法,fpga电路包括多个slice,时延表包括内部时延表,该方法包括:确定从多个slice中每个slice内部的输入引脚到其输出引脚的若干线路;基于若干线路分别计算出从输入引脚到输出引脚的内部时延;将每个slice的若干线路分别对应的输入引脚、输出引脚和这二个引脚之间相应的内部时延保存于内部时延表中。6.可选地,时延表包括引脚时延表,该创建fpga电路的时延表的方法包括:计算多个slice中每个slice的输出引脚到与其紧邻且位于其下游的第一连接盒的输出引脚时延;计算多个slice中每个slice的输入引脚到与其紧邻且位于其上游的第二连接盒的输入引脚时延;将每个slice的输出引脚和与其对应的输出引脚时延、以及输入引脚和与其对应的输入引脚时延都保存于引脚时延表中。7.可选地,slice包括lut、ff和mux,输入引脚包括lut的输入端,输出引脚包括lut的输出端、ff的输出端和mux的输出端。8.可选地,时延表包括路径时延表,该创建fpga电路的时延表的方法包括:基于任意二个slice的坐标、一者的输出引脚和另一者的输入引脚、以及这二个slice之间经过的若干线段确定从与输出引脚紧邻且位于其下游的第一连接盒到与输入引脚紧邻且位于其上游的第二连接盒的路径;通过如下公式计算路径的路径时延、并且将任意二个slice的坐标、一者的输出引脚和另一者的输入引脚和路径时延保存于路径时延表中:[0009][0010]其中,path_delay表示路径时延,ini_delay表示初始时延,m表示路径经过的线段类型的个数,ni表示第i类线段的个数,base_delayi表示第i类线段的基本时延。[0011]可选地,线段类型基于线段的长度和方向而确定。[0012]可选地,时延表包括修正时延表,该创建fpga电路的时延表的方法包括:基于任意二个slice的坐标、一者的输出引脚和另一者的输入引脚确定从输出引脚到输入引脚的路径;确定路径上经过的非slice模块的类型和数量;基于非slice模块的类型和数量确定路径的修正时延;将任意二个slice的坐标、一者的输出引脚、另一者的输入引脚以及路径的修正时延保存于修正时延表中。[0013]可选地,非slice模块的类型包括dsp和ram。[0014]可选地,修正时延表包括第一表和第二表,该创建fpga电路的时延表的方法包括:通过第一表的相关行记录一条路径中分别经过各个非slice模块的各个线段在第二表中对应的行数;第二表的各行分别记录与各个线段中的连线分别对应的电阻值和电容值;通过如下公式计算经过非slice模块的修正时延:[0015]τ2=in2(r1c1 (r1 r2)c2),[0016]其中,τ2表示经过非slice模块的修正时延,in2表示以e为底的对数的值的平方,r1和c1分别表示非slice模块连接与其紧邻并且位于上游的连接盒的连线所对应的电阻值和电容值,r2和c2分别表示非slice模块连接与其紧邻并且位于下游的连接盒的连线所对应的电阻值和电容值。[0017]本发明实施例还提供一种创建fpga电路的时延表的设备,包括存储器和处理器,存储器上存储有可在处理器上运行的计算机指令,处理器运行计算机指令时执行上述任一种创建fpga电路的时延表的方法的步骤。[0018]本发明实施例还提供一种获取fpga电路的时延的方法,包括:基于源slice的输出引脚和终端slice的输入引脚从内部时延表中分别获取源slice的内部时延和终端slice的内部时延;基于源slice的输出引脚和终端slice的输入引脚从引脚时延表中分别获取源slice的输出引脚时延和终端slice的输入引脚时延;基于源slice的坐标和输出引脚、以及终端slice的坐标和输入引脚从路径时延表中获取从与输出引脚紧邻且位于其下游的第一连接盒到与输入引脚紧邻且位于其上游的第二连接盒的路径时延;通过如下公式计算从源slice到终端slice的第一总时延:[0019]total_delay1=inertal_delay pin_delay path_delay,[0020]其中,total_delay1表示第一总时延,inertal_delay表示内部时延,其包括源slice的内部时延和终端slice的内部时延,pin_delay表示引脚时延,其包括源slice的输出引脚时延和终端slice的输入引脚时延,path_delay表示路径时延。[0021]可选地,该获取fpga电路的时延的方法包括:基于源slice的坐标和输出引脚、以及终端slice的坐标和输入引脚从修正时延表中获取从输出引脚到输入引脚的修正时延;通过如下公式计算从源slice到终端slice的第二总时延:[0022]total_delay2=inertal_delay pin_delay path_delay modify_delay,[0023]其中,total_delay2表示第二总时延,modify_modify表示修正时延。[0024]本发明实施例还提供一种获取fpga电路的时延的设备,包括存储器和处理器,存储器上存储有可在处理器上运行的计算机指令,处理器运行计算机指令时执行上述任一种获取fpga电路时延的方法的步骤。[0025]与现有技术相比,本发明实施例的技术方案具有有益的技术效果。[0026]例如,本发明实施例所创建的fpga电路的时延表包括内部时延表,由于fpga芯片为基于模块的阵列结构,而模块的内部时延在线网或者路径的总时延中占有很大的一部分,通过计算该内部时延,可以使得总时延的估计较为准确,从而使得基于该估计所设计或者优化的fpga电路能够满足时序约束。[0027]又例如,本发明实施例所创建的fpga电路的时延表包括引脚时延表、路径时延表和修正时延表中的一个或多个,基于这些时延表而计算出的总时延较为准确,从而使得基于该估计所设计或者优化的fpga电路能够满足时序约束。[0028]又例如,本发明实施例所创建的fpga电路的时延表包括内部时延表、引脚时延表、路径时延表和修正时延表中的一个或多个,将总的时延具体区分为内部时延、引脚时延、路径时延和修正时延,其考虑到fpga芯片的内部结构和资源分布十分对称,例如,模块结构一致性(即,在不同位置上同一类型模块的内部时延基本一致)、路径相关性(即,经过相同模块或使用相同线段的路径所产生的时延基本一致)、距离相关性(即,距离恒定的两个模块在fpga不同位置上,其对应的时延基本一致)、竖直对称性(即,fpga每一列只包含一种类型的模块,模块上下平移后的总时延一致);不同位置处的相同元件(例如,相同的可配置逻辑块(configurablelogicblock,clb),相同的基本可编程逻辑单元slice(其位于clb内),相同的查找表(lookuptable,lut)、触发器(ff)、多路选择器(mux)等电路元素(其位于slice内))的时延是基本相同的,该时延仅与这些模块、slice或者电路元素的位置和输入和输出引脚的布置相关,从而可以通过较少的存储空间来记录这些时延。这使得时延的计算可以基于fpga芯片内部的对称性而减少冗余计算,还可以减少与记录时延信息相关的存储空间,又可以减少查找这些时延信息的时间,从而可以准确而高效地估计时延。[0029]又例如,本发明实施例所创建的fpga电路的时延表可以用于在fpga的打包、布局、布线以及时序仿真等物理实现阶段估计电路的时延,并且,基于该估计的时延可以快速而有效地进行逻辑打包、布局和布线,以及进行相应的时序分析,以避免电路存在时序错误,并且保证关键路径具有正常的时序。附图说明[0030]图1是本发明实施例中fpga芯片的阵列结构的示意图;[0031]图2是本发明实施例中fpga芯片中连接线资源的示意图;[0032]图3是本发明实施例中分布式rc模型的示意图;[0033]图4是本发明实施例中创建fpga电路的时延表的流程图;[0034]图5是本发明实施例中slice内输入引脚和输出引脚的示意图;[0035]图6是本发明实施例中从源slice到终端slice的路径的示意图;[0036]图7是本发明实施例中slice的结构示意图;[0037]图8是本发明实施例中从源slice经过若干模块到终端slice的示意图;[0038]图9是本发明实施例中经过非slice模块的路径的示意图;[0039]图10是本发明实施例中非slice模块及其连线示意图;[0040]图11是本发明实施例中获取fpga电路时延的流程图。具体实施方式[0041]为使本发明实施例的上述目的、特征和有益效果能够更为明显易懂,下面结合附图对本发明的具体实施例进行详细说明。[0042]如图1所示,fpga芯片采用规则的阵列结构;可以以阵列的中心为原点,水平向右和左的方向分别为x轴的正和负方向(“x方向”),竖直向上和下的方向分别为y轴的正和负方向(“y方向”)。[0043]阵列中的点可以为模块,模块包括clb、随机存取存储器(randomaccessmemory,ram)、可编程输入输出单元(inputoutputblock,iob)、数字信号处理模块(digitalsignalprocessor,dsp)等。[0044]在fpga芯片内部,数量最多的是clb,其是最基本的模块;1个clb通常包括2个slice,可用于实现组合逻辑电路以及时序逻辑电路。[0045]如图2所示,fpga芯片还包括大量的连接线资源,例如,连接盒(connectionbox,cb)、开关盒(switchbox,sb)和许多线段(segment),cb主要用于将clb的输入、输出端与布线资源相连,sb则位于横竖布线通道的交点处,用于选择连接的segment,sb描述了通过可选择的可编程互连点(programmableinterconnectionpoint,pip)以将任意一条segment转换到其余segment的拓扑连接关系,通过cb、sb和pip连接的多个segment可以形成从一个slice到另一个slice的线网(net)。[0046]在深亚米制造工艺下,fpga芯片的线网中源点(source)到终点(sink)的路径上连接线或导线的寄生参数(如寄生电阻、电容)对时延的影响不可忽视。可以采用电阻-电容模型(rc模型)来近似,但是,将一段导线的电阻和电容基于集总模型而作为1个电阻和1个电容是不太精确的。[0047]本发明实施例提供分布式的rc模型。[0048]如图3所示,可以将一段导线分为n段,ri和ci表示其中某段的电阻和电容,i为不小于1且不大于n的整数;该导线的时延可以通过如下公式计算:[0049]τ1=r1c1 … (r1 … ri)ci … (r1 … rn)cnꢀꢀ(1)[0050]其中,τ1表示该段导线的时延,r1、ri和rn分别表示第1、i和n段导线的电阻,c1、ci和cn分别表示第1、i和n段导线的电容。[0051]如果n为1,则公式(1)为集总模型的计算方式;n取值越大,则公式(1)的计算结果越精确。[0052]图4是本发明实施例中创建fpga电路的时延表方法100的具体流程图,其中,fpga电路包括多个slice,时延表包括内部时延表。[0053]在本发明的实施例中,fpga芯片基于slice而非clb等模块进行布局布线,这一方面增加了布局布线的灵活性,另一方面提高了时延计算的精确性。[0054]如图5所示,1个slice包括多个输入引脚(inputpin)、多个输出引脚(outputpin)、lut、ff、mux以及进位链。[0055]fpga芯片内任意二个slice之间可以形成路径,例如,由源slice(slice_source)的inputpin或outputpin到终端slice(slice_sink)的outputpin或inputpin的路径。[0056]如图6所示,信号从slice_source的inputpin(即其中lut的输入端)、经其outputpin、第一cb(cb1)、sb、第二cb(cb2)到slice_sink的inputpin(即其中lut的输入端)。slice_source的坐标为(x_loc1,y_loc1),slice_sink的坐标为(x_loc2,y_loc2)。[0057]图6示意了从slice_source到slice_sink的路径仅经过2个cb和1个sb,应理解,从slice_source到slice_sink的路径可以经过多个cb、多个sb、多个slice、若干个dsp和/或若干个ram等。[0058]方法100可以包括步骤110、120和130。[0059]在步骤110的执行中,确定从多个slice中每个slice的inputpin到其outputpin的若干线路。[0060]slice的内部时延表示从slice的一个输入端到其输出端所产生的时延,包括slice内部走线所产生的时延、以及经过电路元素lut、mux、ff等产生的时延。[0061]1个slice可以包括4个lut、若干个ff和mux。[0062]图7示意了1个slice中的1个lut(即luta,其余3个未示出的lut可以表示为lutb、lutc和lutd)、1个ff和1个mux。[0063]每个lut可以具有若干个输入端,例如,luta的6个输入端(从a1、a2至a6),lutb的6个输入端(从b1、b2至b6),lutc的6个输入端(从c1、c2至c6),lutd的6个输入端(从d1、d2至d6)。[0064]每个lut可以具有1个输出端,例如,luta的输出端(pin_a),lutb的输出端(pin_b),lutc的输出端(pin_c),lutd的输出端(pin_d)。[0065]mux具有输出端pin_mux、ff具有输出端pin_q。在1个slice内,mux和ff都可以具有多个,相应地,输出端pin_mux和pin_q也都可以具有多个,例如,与luta相关的输出端pin_muxa和pin_qa,与lutb相关的输出端pin_muxb和pin_qb,与lutc相关的输出端pin_muxc和pin_qc,与luta相关的输出端pin_muxd和pin_qd。[0066]4个lut各自的输入端都可以称为slice的inputpin,4个lut各自的输出端、mux的输出端以及ff的输出端都可以称为slice的outputpin。[0067]如图7所示,在1个slice内部,从其inputpin到outputpin具有若干线路,包括:从lut的输入端到lut的输出端的线路(第一线路),从lut的输入端、经mux到mux的输出端的线路(第二线路),从lut的输入端、经ff和mux到mux的输出端的线路(第三线路),从lut的输入端、经ff到ff的输出端的线路(第四线路);其中,第一线路和第二线路为组合逻辑电路,第三线路和第四线路为时序逻辑电路。[0068]在步骤120的执行中,基于若干线路分别计算出从inputpin到outputpin的内部时延。[0069]在1个slice内,各个inputpin到各个outputpin的多条线路中的每一条线路都可以被电路元素(例如lut、ff、mux)分成若干段连线(wire),每一段wire都具有电阻和电容,从而形成类似于图3的电路,并且可以通过公式(1)分别计算每一条线路的内部时延;其中,inputpin包括4个lut各自的输入端,outputpin包括4个lut各自的输出端、mux的输出端以及ff的输出端。[0070]在步骤130的执行中,将每个slice的若干线路分别对应的inputpin、outputpin和相应的内部时延保存于内部时延表中。[0071]如表1示意,luta的各输入端作为inputpin以及luta的输出端、mux的输出端和ff的输出端均作为outputpin时分别对应的时延记录于内部时延表a。[0072]表1[0073][0074][0075]在表1中,由inputpin到pin_mux的路径包括经过ff和未经过ff的路径,前者的时延类型属于时序时延(sequentialdelay),后者的时延类型属于组合时延(combinationaldelay),其中sequentialdelay表示时序电路所产生的时延,combinationaldelay表示组合电路所产生的时延;由inputpin到pin_a的路径属于combinationaldelay;由inputpin到pin_q的路径属于sequentialdelay。[0076]lutb的各输入端作为inputpin以及lutb的输出端、mux的输出端和ff的输出端均作为outputpin时分别对应的时延记录于内部时延表b;lutc的各输入端作为inputpin以及lutc的输出端、mux的输出端和ff的输出端均作为outputpin时分别对应的时延记录于内部时延表c;lutd的各输入端作为inputpin以及lutd的输出端、mux的输出端和ff的输出端均作为outputpin时分别对应的时延记录于内部时延表d。内部时延表b、c和d均与内部时延表a的结构类似。[0077]由于slice内部的电路和引脚在fpga芯片制造完成后就已经确定,相关的内部时延也已确定,因此,可以将inputpin、outputpin和这二个引脚之间的内部时延保存于内部时延表中,以便于在需要的时候读取。[0078]在本发明的实施例中,时延表可以包括引脚时延表。[0079]任一个slice中各inputpin都具有与其紧邻的cb,可以计算该cb到对应的inputpin这段走线的时延(从信号传输的路径看,该cb位于inputpin的上游),例如通过公式(1)计算这段走线的时延;该时延与inputpin相关,其可称为inputpin时延。[0080]在本发明的各实施例中,上游、下游基于信号的流向而确定;即,靠近slice_source的方向为上游方向,靠近slice_sink的方向为下游方向。[0081]如图6所示,cb2到slice_sink的inputpin的时延即为inputpin时延。[0082]如表2示意,luta的各输入端作为inputpin,位于这些inputpin的上游且与之紧邻的cb到该inputpin的这段走线的时延记录于引脚时延表a。[0083]表2[0084][0085]lutb的各输入端作为inputpin,位于这些inputpin的上游且与之紧邻的cb到该inputpin的这段走线的时延记录于引脚时延表b;lutc的各输入端作为inputpin,位于这些inputpin的上游且与之紧邻的cb到该inputpin的这段走线的时延记录于引脚时延表c;lutd的各输入端作为inputpin,位于这些inputpin的上游且与之紧邻的cb到该inputpin的这段走线的时延记录于引脚时延表d。引脚时延表b、c和d均与引脚时延表a的结构类似。[0086]可以计算任一个slice中各outputpin到与其紧邻的cb的这段走线的时延(从信号传输的路径看,该cb位于outputpin的下游),例如通过公式(1)计算这段走线的时延;该时延与outputpin相关,其可称为outputpin时延。[0087]如图6所示,slice_source的outputpin到cb1的时延即为outputpin时延。[0088]如表3示意,lut的输出端、mux的输出端和ff的输出端作为outputpin到与其紧邻的cb的这段走线的时延记录于引脚时延表e。[0089]表3[0090][0091][0092]由于outputpin到与其紧邻且位于其下游的cb的这段走线以及inputpin到与其紧邻且位于其上游的cb的这段走线在fpga芯片制造完成后就已经确定,相关的outputpin时延以及inputpin时延也已确定,因此,可以将outputpin和与之对应的outputpin时延、以及inputpin和与之对应的inputpin时延都保存于引脚时延表中,以便于在需要的时候读取。[0093]在本发明的实施例中,引脚时延表a、b、c、d和e的内容可以保存于一张表内。[0094]在本发明的实施例中,时延表可以包括路径时延表。[0095]对于fpga芯片内的任意二个slice,其中一者和另一者可以分别作为slice_source和slice_sink,可以确定slice_source的坐标、slice_sink的坐标、slice_source的outputpin、slice_sink的inputpin、以及从slice_source到slice_sink所经过的若干segment,从而获得从与outputpin紧邻且位于其下游的cb到与inputpin紧邻且位于其上游的cb的路径。[0096]可以通过如下公式计算该路径的路径时延:[0097][0098]其中,path_delay表示路径时延,ini_delay表示初始时延(即经过与slice_source紧邻且位于其下游的cb所产生的时延),m表示该路径经过的线段类型的个数,ni表示第i类segment的个数,base_delayi表示第i类segment的基本时延。[0099]线段类型基于线段的长度和方向(如x方向、y方向)而确定。[0100]基于线段类型的基本时延base_delayi可以基于该线段中的一个或多个wire对应的电阻值和电容值以及公式(1)进行计算。[0101]一条segment可能经过多个sb,可以根据经过sb的数目定义segment的长度,例如,segment的长度可以为x1、x2、x4、x6、x12和x18,其分别表示segment的长度经过1、2、4、6、12和18个sb。[0102]如图8所示,slice_source和slice_sink之间的路径经过若干个cb,其中,相邻的cb之间通过一个sb连接;该路径包括3个x1类型的segment(其经过1个sb)和2个x2类型的segment(其经过2个sb)。[0103]该示例中,slice_source和slice_sink之间的路径时延可以根据公式(2)计算,大小为:ini_delay1 3*base1_delay 2*base2_delay,其中,ini_delay1表示该示例中的初始时延,bsae_delay1表示x1类型的segment的基本时延,base_delay2表示x2类型的segment的基本时延。[0104]可以将上述任意二个slice的坐标、一者的输出引脚和另一者的输入引脚和路径时延保存于路径时延表中。[0105]在本发明的实施例中,时延表可以包括修正时延表。[0106]可以基于任意二个slice的坐标、一者的outputpin和另一者的inputpin确定从outputpin到inputpin的路径,其中,一个slice为slice_source,另一个slice为slice_sink。[0107]slice包括于clb内,而非slice模块内没有slice,其类型包括dsp和ram。[0108]在从源slice到终端slice的路径可能会存在若干个非slice模块,其会使得时延发生变化。为了准确地估计路径的时延,需要考虑非slice模块产生的修正时延。[0109]如图9所示,从slice_source到slice_sink的路径上,经过ram和dsp,该路径的时延total_delay可以包括ram和dsp产生的修正时延modify_delay。[0110]修正时延的计算基于非slice模块的类型,不同类型的非slice模块,例如ram和dsp,具有不同的修正时延;还基于非slice模块的数量,数量越多,相应的修正时延也越大。[0111]可以基于路径上经过的非slice模块的类型和数量等确定该路径的修正时延。即,分别计算经过各类型非slice模块的修正时延,再基于不同类型slice模块的数量而将它们各自的修正时延相加,就可以得到该路径的修正时延。[0112]具体而言,可以先计算经过非slice模块的修正时延。[0113]如图10所示,非slice模块的上下游分别有与其紧邻的sb(即sb1、sb2),并且通过连线(wire)相互连接;其中,wire_1连接位于上游的sb1,wire_2连接位于下游的sb2,而wire_1和wire_2形成了经过该非slice模块的线段。[0114]可以通过如下公式计算经过该非slice模块的修正时延:[0115]τ2=in2(r1c1 (r1 r2)c2)ꢀꢀ(3)[0116]其中,τ2表示修正时延,in2表示以e为底的对数的值的平方,r1和c1分别表示wire1对应的电阻值和电容值,r2和c2分别表示wire2对应的电阻值和电容值。[0117]修正时延表可以包括第一表和第二表。[0118]第一表的各行可以记录一条路径上分别经过各个非slice模块的各个线段对应的数字,该数字对应第二表的行数;第二表的各行记录与经过非slice模块的线段中各个wire对应的电阻值和电容值。[0119]如表4示意,第1-5行对应5条路径,每条路径上具有经过一个或多个非slice模块的线段,例如,第一行包括4个线段,各自相关的电阻值和电容值可以在第二表的第122、133、12和19行查到。[0120]表4[0121][0122]可以从第二表的相应行获得经过一个非slice模块的线段中wire所对应的电阻值和电容值。[0123]如表5示意,第1-5行对应5个非slice模块或者与其相关的5个线段,其中,第2列表示非slice模块的横坐标和纵坐标,r1和c1表示经过非slice模块的线段中wire_1的电阻值和电容值,r2和c2表示经过非slice模块的线段中wire_2的电阻值和电容值。[0124]在一些情形中,wire_1和wire_2中的一者或者二者的电阻值和/或电容值为0。例如,表5的第3至5行中的每一行,wire_2的电阻值和电容值均为0,因此,该值未记录于表中。[0125]表5[0126][0127]在获得与一个非slice模块连接的wire所对应的电阻值和电容值后,可以基于公式(3)可以计算经过该非slice模块的修正时延;接着,可以分别计算第一表的一行中经过各个非slice模块的修正时延,并且累加各修正时延,从而获得一条路径的修正时延;然后,可以分别对第一表的各行进行类似的计算,从而获得fpga芯片中任意二个slice之间各个路径的修正时延。[0128]通过设置二张表(第一表和第二表),使得各个路径可以复用经过非slice模块的修正时延,这极大地节约了存储空间,相应地,减少了查找这些修正时延的时间。[0129]即使同一类型的非slice模块,如果其处于不同的位置,可能具有不同的位置时延。因此,修正时延可以包括基于非slice模块的位置而确定的位置时延。该位置时延可以基于测试而获得。[0130]可以将任意二个slice的坐标、一者的outputpin、另一者的inputpin以及该路径的修正时延保存于修正时延表中,从而可以基于二个slice的坐标、一者的outputpin、另一者的inputpin查找到对应路径的修正时延。[0131]本发明的实施例还提供一种创建fpga电路的时延表的设备,包括存储器和处理器,存储器上存储有可在所述处理器上运行的计算机指令,处理器运行计算机指令时执行上述结合图1至10所述的创建fpga电路的时延表的方法的步骤。[0132]本发明的实施例还提供一种根据上述时延表获取fpga电路时延的方法。[0133]在fpga芯片上进行布局布线后,可以进行时序仿真。可以选取任一条路径进行分析,以估计它的时延。该时延可以包括静态时延和动态时延。[0134]静态时延包括slice的内部时延和引脚时延,其与路径无关,只受设计的逻辑影响,在设计确定之后,slice的内部时延和引脚时延是静态不变的。[0135]动态时延包括路径时延和修正时延,其受到布局布线算法的影响,不同的算法可能会使得从起点到终点的路径不同,修正时延也可能不同,从而得到不同的时延结果。[0136]如图11所示,获取fpga电路时延的方法200包括步骤210、220、230和240。[0137]在步骤210的执行中,基于源slice的outputpin和终端slice的inputpin从内部时延表中分别获取源slice的内部时延和终端slice的内部时延。[0138]在步骤220的执行中,基于源slice的outputpin和终端slice的inputpin从引脚时延表中分别获取源slice的输出引脚时延和终端slice的输入引脚时延。[0139]在步骤230的执行中,基于源slice的坐标和outputpin、以及终端slice的坐标和inputpin从路径时延表中获取从与outputpin紧邻且位于其下游的cb到与inputpin紧邻且位于其上游的cb的路径时延。[0140]在步骤240的执行中,通过如下公式计算从源slice到终端slice的第一总时延:[0141]total_delay1=inertal_delay pin_delay path_delayꢀꢀ(4)[0142]其中,total_delay1表示第一总时延,inertal_delay表示内部时延,其包括源slice的内部时延和终端slice的内部时延,pin_delay表示引脚时延,其包括源slice的输出引脚时延和终端slice的输入引脚时延,path_delay表示路径时延。[0143]从从源slice到终端slice的总时延还可以包括路径的修正时延。[0144]可以基于源slice的坐标和outputpin、以及终端slice的坐标和inputpin从修正时延表中获取从outputpin到inputpin的修正时延。[0145]可以通过如下公式计算从源slice到终端slice的第二总时延:[0146]total_delay2=inertal_delay pin_delay path_delay modify_delayꢀꢀ(5)[0147]其中,total_delay2表示第二总时延,modify_delay表示修正时延。[0148]本发明的实施例还提供一种获取fpga电路时延的设备,包括存储器和处理器,存储器上存储有可在所述处理器上运行的计算机指令,处理器运行计算机指令时执行上述获取fpga电路时延的方法的步骤。[0149]虽然本发明披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。当前第1页12当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。