1.本技术涉及农作物分类技术领域,尤其涉及一种基于改进随机森林算法的农作物分类方法、装置及计算机设备。
背景技术:
2.农作物的种植分布情况是宏观掌握粮食生产、制定农业政策和预测农业资源综合生产能力的重要依据。
3.植被指数特征被广泛应用于农业遥感研究领域,其能够反映不同植被类型在不同生长期的物候特征及在可见光、近红外等波段的光谱反射值差异,是作物识别的关键特征。农作物作为绿色植被中的一类,受作物类型、生长状况以及土壤肥力等因素影响,其光谱曲线特征存在一定差异。因此,根据农作物光谱特征差异,选取适当的植被指数可有效实现农作物分类。另外,纹理信息作为一种重要的影像空间特征信息,在基于遥感影像的分类中也被广泛应用。
4.但目前的研究大多基于单一植被指数或单一纹理信息进行分类,将其二者结合作为分类特征的研究相对较少,且缺乏对纹理信息提取尺度的研究导致模型分类精度难以提高,导致农作物分类精度不够的问题。
技术实现要素:
5.本发明目的是为了解决现有技术对农作物分类的精度不够的问题,提供了一种基于改进随机森林算法的农作物分类方法、装置及计算机设备。
6.本发明是通过以下技术方案实现的,本发明一方面,提供一种基于改进随机森林的农作物分类方法,所述方法包括:
7.获取研究区域的农作物原始影像,并对所述农作物原始影像进行预处理,获取农作物遥感影像数据;
8.根据所述农作物遥感影像数据,利用灰度矩阵法获取若干个纹理特征;
9.计算所述若干个纹理特征的最佳指数因子oif,将所述最佳指数因子oif按照从大到小的顺序进行排列;
10.设置预设值,选取前所述预设值个最佳指数因子oif对应的纹理特征构成最佳特征组合;
11.获取所述农作物遥感影像数据的归一化植被指数ndvi,利用融合工具将所述归一化植被指数ndvi与所述最佳特征组合进行融合,获取融合后的特征数据;
12.利用自适应权重粒子群算法对随机森林算法进行优化,获取改进后的随机森林算法;
13.根据所述融合后的特征数据,利用所述改进后的随机森林算法,获取农作物分类图像。
14.进一步地,所述若干个纹理特征包括mean、variance、homogeneity、contrast、di ssimilarity、entropy、second moment和correlation的8种纹理特征。
15.进一步地,所述根据所述农作物遥感影像数据,利用灰度矩阵法获取若干个纹理特征,还包括:
16.对所述农作物遥感影像数据进行主成分分析,获取第一主成分的影像;
17.根据第一主成分的影像,利用灰度矩阵法获取若干个纹理特征。
18.进一步地,所述最佳指数因子oif的计算公式为:
[0019][0020]
其中,oif为最佳指数因子;m为波段合成总数;sdi为i波段的标准差;r
ij
为i,j波段间的相关系数。
[0021]
进一步地,所述最佳特征组合由mean、variance和contrast构成。。
[0022]
进一步地,所述利用自适应权重粒子群算法对随机森林算法进行优化,具体包括:
[0023]
步骤1、将(k,m)作为粒子群算法中的一个粒子,其中,k为随机森林树的棵树,m为生成决策树时特征抽取个数,随机初始化种群中粒子的位置与速度;
[0024]
步骤2、评价各粒子的适应度,将当前各粒子的位置和适应度值存储在pbest中,将所有pbest中适应度值最优个体的位置和适应值存储于gbest中;
[0025]
步骤3、更新粒子的速度与位置,公式如下:
[0026]vid
=ωv
id
c1r1(pbest
id-x
id
) c2r2(pbest
id-x
id
)
[0027]
x
id
=x
id
v
id
[0028]
其中,v
id
为粒子速度,x
id
为粒子位置,c1,c2为学习因子,r1,r2为0至1的随机数;
[0029]
步骤4、更新粒子的权重,公式如下:
[0030][0031]
其中,ω为粒子的惯性权重,ω
max
,ω
min
分别表示ω的最大值与最小值,f表示粒子当前的适应度函数值,f
avg
和f
min
分别为当前所有粒子的平均适应度值和最小适应度值;
[0032]
步骤5、将当前粒子的适应度值与位置最好的粒子的适应度值进行比较,如果当前粒子的适应度值大于位置最好的粒子的适应度值时,将当前粒子位置作为最好位置;
[0033]
比较当前所有pbest和gbest的值,对gbest进行更新;
[0034]
步骤6、判断是否满足停止条件,若满足,输出结果,否则返回步骤3继续搜索。
[0035]
进一步地,所述灰度共生矩阵的滑动窗口的大小为3*3。
[0036]
第二方面,本发明提供一种基于改进随机森林算法的农作物分类装置,所述装置包括:
[0037]
图像预处理模块,用于获取研究区域的农作物原始影像,并对所述农作物原始影像进行预处理,获取农作物遥感影像数据;
[0038]
纹理特征获取模块,用于根据所述农作物遥感影像数据,利用灰度矩阵法获取若
干个纹理特征;
[0039]
最佳特征组合获取模块,用于计算所述若干个纹理特征的最佳指数因子oif,将所述最佳指数因子oif按照从大到小的顺序进行排列;
[0040]
设置预设值,选取前所述预设值个最佳指数因子oif对应的纹理特征构成最佳特征组合;
[0041]
融合后的特征数据获取模块,用于获取所述农作物遥感影像数据的归一化植被指数ndvi,利用融合工具将所述归一化植被指数ndvi与所述最佳特征组合进行融合,获取融合后的特征数据;
[0042]
改进的随机森林算法获取模块,用于利用自适应权重粒子群算法对随机森林算法进行优化,获取改进后的随机森林算法;
[0043]
农作物分类图像获取模块,用于将所述融合后的特征数据输入所述改进后的随机森林算法,获取农作物分类图像。
[0044]
第三方面,本发明提供一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机程序,当所述处理器运行所述存储器存储的计算机程序时执行如上文所述的一种基于改进随机森林的农作物分类方法的步骤。
[0045]
本发明的有益效果:
[0046]
首先,利用最佳指数法筛选纹理特征,结合ndvi构建特征数据集,使得用于农作物分类的特征选取更加精确,进而提升了农作物分类的精度;
[0047]
其次,利用自适应权重粒子群算法优化后的随机森林进行分类,以探究自适应权重粒子群算法算法对于随机森林模型分类精度的影响,进而选出合适的参数来提高随机森林模型的最终分类准确率。
[0048]
本发明适用于对农作物种植分布情况信息的获取。
附图说明
[0049]
为了更清楚地说明本技术的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0050]
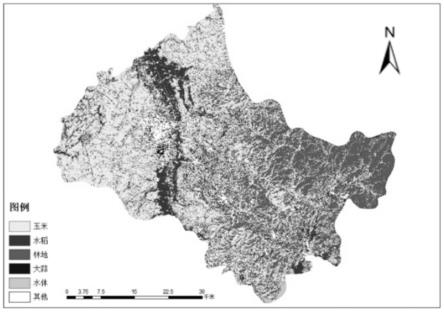
图1为阿城区典型农作物类型空间分布图;
[0051]
图2为3*3窗口下的glcm纹理特征(从左至右分别为mean、variance和contrast);
[0052]
图3为5*5窗口下的glcm纹理特征(从左至右分别为mean、variance和contrast);
[0053]
图4为7*7窗口下的glcm纹理特征(从左至右分别为mean、variance和contrast);
[0054]
图5为9*9窗口下的glcm纹理特征(从左至右分别为mean、variance和contrast)。
具体实施方式
[0055]
下面详细描述本发明的实施方式,所述实施方式的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施方式是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
[0056]
实施方式一、一种基于改进随机森林算法的农作物分类方法,所述方法包括:
[0057]
获取研究区域的农作物原始影像,并对所述农作物原始影像进行预处理,获取农
作物遥感影像数据;
[0058]
根据所述农作物遥感影像数据,利用灰度矩阵法获取若干个纹理特征;
[0059]
计算所述若干个纹理特征的最佳指数因子oif,将所述最佳指数因子oif按照从大到小的顺序进行排列;
[0060]
设置预设值,选取前所述预设值个最佳指数因子oif对应的纹理特征构成最佳特征组合;
[0061]
获取所述农作物遥感影像数据的归一化植被指数ndvi,利用融合工具将所述归一化植被指数ndvi与所述最佳特征组合进行融合,获取融合后的特征数据;
[0062]
利用自适应权重粒子群算法对随机森林算法进行优化,获取改进后的随机森林算法;
[0063]
根据所述融合后的特征数据,利用所述改进后的随机森林算法,获取农作物分类图像。
[0064]
本实施方式中,
[0065]
首先,利用最佳指数法筛选纹理特征,结合ndvi构建特征数据集。其中,灰度共生矩阵(gray-level co-occurrence matrix,glcm)是通过计算图像灰度级之间条件概率密度来提取纹理的一种经典分析方法,由于纹理特征之间具有一定相关性,采用最佳指数因子(optimum index factor,oif)构建最佳特征组合;通过原始影像的波段计算得出的归一化植被指数ndvi通过测量遥感影像的近红外波段(植被强烈反射)和红光波段(植被吸收)之间的差异来量化植被,能够准确反映植被物候信息,有效削弱“同物异谱、同谱异物”现象,因此实施方式引入ndvi作为分类特征,通过波段融合工具将其与上述最佳纹理特征组合进行融合,进而提升农作物分类的精度。
[0066]
其次,在基于随机森林算法进行分类时,随机森林树的棵树(k)与生成决策树时特征抽取个数(m)往往难以确定,一般通过人工挑选进行参数调节,尚未有基于最优化理论生成的最优参数。利用自适应权重粒子群算法优化后的随机森林进行分类,以探究自适应权重粒子群算法算法对于随机森林模型分类精度的影响,解决了随机森林树的棵树(k)与生成决策树时特征抽取个数(m)难以确定的难题,进而通过优化随机森林算法的参数,有效提高了模型的分类精度,进一步提升了农作物分类的实用性和准确性。
[0067]
实施方式二,本实施方式是对实施方式一所述的一种基于改进随机森林的农作物分类方法的进一步限定,本实施方式中,对所述若干个纹理特征,做了进一步限定,具体包括:
[0068]
所述若干个纹理特征包括mean、variance、homogeneity、contrast、dissimilarity、entropy、second moment和correlation的8种纹理特征。
[0069]
本实施方式中,为了保证最终选取特征的准确性,选取灰度共生矩阵中全部8种纹理量进行纹理特征分析,分别为mean、variance、homogeneity、contrast、dissimilarity、entropy、second moment以及correlation用于后续的分析。
[0070]
实施方式三,本实施方式是对实施方式一所述的一种基于改进随机森林的农作物分类方法的进一步限定,本实施方式中,对所述根据所述农作物遥感影像数据,利用灰度矩阵法获取若干个纹理特征这一步骤,做了进一步限定,具体包括:
[0071]
对所述农作物遥感影像数据进行主成分分析,获取第一主成分的影像;
[0072]
根据第一主成分的影像,利用灰度矩阵法获取若干个纹理特征。
[0073]
本实施方式中,首先对影像进行主成分分析,使用第一主成分来提取glcm。用主成分分析的第一主成分作为基影像来提取纹理特征比用原始影像作为基影像来提取纹理特征进行分类的效果更好。
[0074]
实施方式四,本实施方式是对实施方式一所述的一种基于改进随机森林的农作物分类方法的进一步限定,本实施方式中,对所述最佳指数因子oif的计算公式,做了进一步限定,具体包括:
[0075]
所述最佳指数因子oif的计算公式为:
[0076][0077]
其中,oif为最佳指数因子;m为波段合成总数;sdi为i波段的标准差;r
ij
为i,j波段间的相关系数。
[0078]
需要说明的是,本实施方式中输入模型的特征就是波段。
[0079]
本实施方式中,先计算出各个纹理特征的标准差和每个特征之间的相关系数,然后将其代入该最佳指数因子oif的计算公式,获取最佳指数因子oif的指数。oif指数越大,则说明其相对的波段含有最多的信息,从而根据oif指数,可以选取含有最多信息的波段特征,进而提升农作物分类的准确性。
[0080]
实施方式五,本实施方式是对实施方式四所述的一种基于改进随机森林的农作物分类方法的进一步限定,本实施方式中,对所述最佳特征组合,做了进一步限定,具体包括:
[0081]
所述最佳特征组合由mean、variance和contrast构成。
[0082]
本实施方式中,通过计算得出mean、variance和contrast的纹理特征组合oif值最高,因此选用这三个波段组合作为最佳纹理特征组合参与分类。并且用oif来选出三个代表信息最多的特征,可以减少信息冗余。
[0083]
实施方式六,本实施方式是对实施方式一所述的一种基于改进随机森林的农作物分类方法的进一步限定,本实施方式中,对所述利用自适应权重粒子群算法对随机森林算法进行优化,做了进一步限定,具体包括:
[0084]
步骤1、将(k,m)作为粒子群算法中的一个粒子,其中,k为随机森林树的棵树,m为生成决策树时特征抽取个数,随机初始化种群中粒子的位置与速度;
[0085]
步骤2、评价各粒子的适应度,将当前各粒子的位置和适应度值存储在pbest中,将所有pbest中适应度值最优个体的位置和适应值存储于gbest中;
[0086]
步骤3、更新粒子的速度与位置,公式如下:
[0087]vid
=ωv
id
c
l
r1(pbest
id-x
id
) c2r2(pbest
id-x
id
)
[0088]
x
id
=x
id
v
id
[0089]
其中,v
id
为粒子速度,x
id
为粒子位置,c1,c2为学习因子,r1,r2为0至1的随机数;
[0090]
步骤4、更新粒子的权重,公式如下:
[0091][0092]
其中,ω为粒子的惯性权重,ω
max
,ω
min
分别表示ω的最大值与最小值,f表示粒子当前的适应度函数值,f
avg
和f
min
分别为当前所有粒子的平均适应度值和最小适应度值;
[0093]
步骤5、将当前粒子的适应度值与位置最好的粒子的适应度值进行比较,如果当前粒子的适应度值大于位置最好的粒子的适应度值时,将当前粒子位置作为最好位置;
[0094]
比较当前所有pbest和gbest的值,对gbest进行更新;
[0095]
步骤6、判断是否满足停止条件,若满足,输出结果,否则返回步骤3继续搜索。
[0096]
本实施方式中,将(k,m)作为粒子群算法中的一个粒子,提出一种自适应权重粒子群算法迭代优化选取出相对较优的粒子,从而选出合适的参数来提高随机森林模型的最终分类准确率。基于以上步骤,利用自适应权重粒子群算法(awpso)算法对随机森林(random forest,rf)进行自主寻优,得到最优参数解。本实施方式是对原有粒子群算法进行优化,使搜索能力更强。
[0097]
针对随机森林算法参数选择较为困难的问题,本实施方式提出利用awpso算法实现随机森林的参数选择,有效提高了模型的分类精度。
[0098]
实施方式七,本实施方式是对实施方式一所述的一种基于改进随机森林的农作物分类方法的进一步限定,本实施方式中,对所述灰度共生矩阵的滑动窗口的大小,做了进一步限定,具体包括:
[0099]
所述灰度共生矩阵的滑动窗口的大小为3*3。
[0100]
本实施方式中,利用自适应权重粒子群算法(awpso)优化后的随机森林进行分类,分类结果表明当纹理特征提取窗口大小为3*3时,具有较高的分类精度,且随着纹理特征提取窗口的增大,其对于细节信息的保留效果下降,造成分类精度逐渐降低,因此为提高模型分类精度,实验采用3*3窗口大小提取所需纹理信息。
[0101]
灰度共生矩阵的滑动窗口,大的滑动窗口能描述大尺度纹理,但损失细节多,且可能包含其他对象的信息,模糊边缘。较小窗口能描述细纹理,但噪声较为严重,但不利用描述像元的分布规律。实验通过对比不同窗口大小纹理特征的分类结果发现,3*3窗口大小提取的纹理特征能够保留出更多的细节信息,相较于其他窗口,能够得到更高的分类精度。
[0102]
本实施方式对不同的灰度共生矩阵的滑动窗口的实验结果进行了对比,基于gf-1/wfv遥感影像,以黑龙江省哈尔滨市阿城区为研究区域,基于pca第一主成分提取不同窗口大小的纹理特征(包括3*3、5*5、7*7、9*9),探索不同窗口大小对分类精度的影响。
[0103]
如图2-5所示,由图中可以看出,虽然小窗口提取出的纹理信息噪声相对较多,但其纹理信息更为细致,随着纹理特征提取窗口的增大,影像的细节信息保留效果越来越差,且存在边缘模糊的问题,使较小规则地物的形状受到了影响,产生了较多不规则的地块,从而影响了后续的分类结果。
[0104]
实施方式八,本实施方式为基于上文的所述的一种基于改进随机森林的农作物分类方法的具体实施例。
[0105]
步骤1、研究区域为黑龙江省哈尔滨市阿城区。根据研究区的影像特点确定了分类
的类别包括玉米、水稻、白菜、林地、水体和其它。实验采用envi 5.3对获取的gf-1wfv影像进行辐射定标、大气校正和几何校正预处理,最后裁剪得到阿城区遥感影像数据。另外,实验基于野外调查数据和google earth高分辨率影像,最终获得实地样本数据1036个,其中玉米286个,水稻280个,白菜142个,林地103个,水体59个,其它166个。
[0106]
步骤2、纹理特征提取:灰度共生矩阵是通过计算图像灰度级之间条件概率密度来提取纹理的一种经典分析方法。选取灰度共生矩阵中全部8种纹理量进行纹理特征分析,分别为mean、variance、homogeneity、contrast、dissimilarity、entropy、second moment以及correlation。首先对影像进行主成分分析,使用第一主成分来提取glcm。由于纹理特征之间具有一定相关性,采用最佳指数因子(optimum index factor,oif)构建最佳特征组合。oif指数越大,则说明其相对的波段含有最多的信息。oif计算公式如下:
[0107][0108]
式中oif为最佳指数因子;m为波段合成总数;sdi为i波段的标准差;r
ij
为i,j波段间的相关系数。
[0109]
通过计算得出mean、variance和contrast的纹理特征组合oif值最高,因此选用这三个波段组合作为最佳纹理特征组合参与分类。
[0110]
步骤3、归一化植被指数ndvi通过测量近红外(植被强烈反射)和红光(植被吸收)之间的差异来量化植被,能够准确反映植被物候信息,有效削弱“同物异谱、同谱异物”现象,因此引入ndvi作为分类特征,通过波段融合工具将其与上述最佳纹理特征组合进行融合。
[0111]
步骤4、在基于随机森林算法进行分类时,随机森林树的棵树(k)与生成决策树时特征抽取个数(m)往往难以确定,一般通过人工挑选进行参数调节,尚未有基于最优化理论生成的最优参数。因此将(k,m)作为粒子群算法中的一个粒子,提出一种自适应权重粒子群算法迭代优化选取出相对较优的粒子,从而选出合适的参数来提高随机森林模型的最终分类准确率。自适应权重粒子群算法的基本步骤如下:
[0112]
(1)随机初始化种群中粒子的位置与速度;
[0113]
(2)评价各粒子的适应度,将当前各粒子的位置和适应度值存储在pbest中,将所有pbest中适应度值最优个体的位置和适应值存储于gbest中;
[0114]
(3)更新粒子的速度与位置,公式如下:
[0115]vid
=ωv
id
c1r1(pbest
id-x
id
) c2r2(pbest
id-x
id
)
[0116]
x
id
=x
id
v
id
[0117]
其中,v
id
为粒子速度,x
id
为粒子位置,c1,c2为学习因子,r1,r2为0至1的随机数;
[0118]
(4)更新粒子的权重,公式如下:
[0119][0120]
其中ω其惯性权重,ω
max
,ω
min
分别表示ω的最大值与最小值,f表示粒子当前的
适应度函数值,f
avg
和f
min
分别为当前所有粒子的平均适应度值和最小适应度值;
[0121]
(5)将粒子的适应度值与最好位置进行比较,如果较好,则将其作为当前的最好位置,比较当前所有pbest和gbest的值,对gbest进行更新;
[0122]
(6)判断是否满足停止条件,若满足,输出结果,否则返回步骤(3)继续搜索。
[0123]
基于以上步骤,利用awpso算法对rf进行自主寻优,得到最优参数解。
[0124]
步骤5、将融合后的特征数据输入至获取到最优参数解的随机森林算法模型,得到农作物分类图像。如图1所示,该图为3*3纹理特征提取窗口下,利用优化后的随机森林算法进行分类的结果,由图中可以看出研究区内农作物的空间分布,东部为山区,基本被林地覆盖,且存在少量玉米种植的情况。农作物种植区主要集中在西部平原地区,种植面积最大的作物为玉米,水稻主要分布在河流沿岸,白菜大多集中在城区东部,其他地区存在少量白菜与玉米混种的情况。
[0125]
表1、农作物分类结果精度表
[0126][0127]
本实施例中,利用3*3窗口提取纹理特征,将ndvi与最佳纹理组合作为分类特征,使用改进后随机森林模型、支持向量机以及未优化的随机森林算法进行分类,分类结果如表所示。
[0128]
结果表明:首先,当纹理特征提取窗口大小为3*3时,具有较高的分类精度,且随着纹理特征提取窗口的增大,其对于细节信息的保留效果下降,造成分类精度逐渐降低,因此为提高模型分类精度,实验采用3*3窗口大小提取所需纹理信息。
[0129]
其次,由表1可以看出,未优化的随机森林算法在3*3的纹理窗口下的总体分类精度为93.25%,kappa系数为0.9063,实验采用支持向量机模型作为对比实验,结果表明在3*3窗口下,支持向量机svm作用于遥感图像农作物分类,其总体分类精度为92.60%,kappa系数为0.9063,低于随机森林算法。考虑到svm是通过二次规划求解支持向量,对h矩阵的计算和存储将耗费大量的计算成本。同时,经典的svm只给出了二类分类的算法,在处理大规模、
多作物混作的分类情景时存在困难,当分类样本、分类目标增多时,svm的表现将有所下降。另外,引入自适应权重粒子群算法(awpso)后的随机森林模型分类精度有了一定的提升,这表明了awpso算法在寻找最佳参数的有效性。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
