1.本发明属于计算机视觉及人工智能技术领域,涉及一种点云物体的参数化边缘曲线提取方法。
背景技术:
2.随着激光扫描技术的日臻成熟,三维点云数据变得越来越成熟可靠,对于物体信息的表达也更为真实。在三维物体的表达中,边缘信息可以准确地反映物体的结构信息,在物体进行精简表示方面发挥着不可替代的作用,因此一直以来受到学者的广泛关注,通过提取物体的边缘特征信息有助于实现工业产品模型的三维重建、数据精简、点云分割、点云配准等,准确提取物体的边缘特征具有重要理论意义和研究价值。
3.一直以来,研究学者主要使用传统的方法提取点云物体的边缘曲线,但是传统的方法存在着当点云数量较大时,提取边缘耗时较长;容易受到噪声点的影响;提取出的边缘曲线存在着结构的缺失;容易提取出较多非边界点等问题。近年来,随着深度学习的优势逐渐显示出来,研究人员开始尝试使用深度学习的方法对物体的特征边缘进行提取,但当前方法仍然存在着特征点分类不准确,边缘曲线存在结构缺失等问题。因此,对点云物体的精确边缘提取技术的研究与探索是非常有必要的。
技术实现要素:
4.本发明的目的是提供一种点云物体的参数化边缘曲线提取方法,解决了现有技术中存在的特征点分类不准确的问题。
5.本发明所采用的技术方案是,一种点云物体的参数化边缘曲线提取方法,具体按照如下步骤实施:
6.步骤1,通过最远点采样算法对于原始点云数据进行下采样,获得下采样后的点云数据,然后对于点云数据进行参数化表示,并基于主成分分析法得到点云数据各点的法向量;
7.步骤2,设计网络模型结构,对步骤1获得的下采样后点云数据进行特征点的分类;
8.步骤3,根据步骤2获得的特征点生成开合候选曲线和闭合候选曲线;
9.步骤4,根据步骤3获得的开合候选曲线和闭合候选曲线选择出最佳曲线。
10.本发明的特征还在于,
11.步骤1具体为:
12.步骤1.1,对于原始点云数据通过最远点采样算法进行下采样,获得下采样后的点云数据;
13.步骤1.2,对于步骤1.1得到的下采样后点云数据进行参数化表示;
14.步骤1.3,基于主成分分析法对于步骤1.1得到的下采样后点云数据进行法向量估计。
15.步骤1.1具体为:
16.步骤1.1.1,在计算机中定义并初始化集合a、b,sample_data,其中a记为null,原始点云数据存入b,sample_data记为null;
17.步骤1.1.2,随机排序集合b,选取第一个点,将其存入集合a中;
18.步骤1.1.3,分别计算出此时集合b中每个点到集合a中点的距离,选取距离最大的点,存入集合a;
19.步骤1.1.4,分别计算出此时集合b中的点pb到集合a中点的距离,从计算出的距离值中选取最小的距离值作为点pb到集合a的距离;
20.步骤1.1.5,对于集合b中的所有点,每个点按照步骤1.1.4计算出来一个距离值,选出最大距离值对应的点存入集合a中;
21.步骤1.1.6,重复步骤1.1.4-1.1.5,直至选出8096个点为止,保存到sample_data。
22.步骤1.2具体为:
23.步骤1.2.1,将直线通过连接两个角点参数化表示;
24.步骤1.2.2,将圆参数化表示为:
25.β=(p1,p2,p3)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
26.式(1)中,p1、p2,p3是圆上不共线的任意三个点,将式(1)用圆的法线、中心和半径表示为:
27.β=(n,c,r)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
28.式(2)中,n是圆的法线,c是圆的中心,r是圆的半径,接着,在圆上随机采样点,并将其表示为β的函数,生成随机样本:
29.p(α|β)=c r(ucos(α) vsin(α))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
30.式(3)中,α是圆上随机采样点,α∈[0,2π],且u=p
1-c,v=u
×
n;
[0031]
步骤1.2.3,使用四个控制点来参数化b-样条曲线,其中pi是表示曲线变化情况的控制顶点,用b
i,k(
·
)
来表示第i阶基函数的k次b-样条曲线,并均匀采样点α,α∈[0,1],生成均匀随机样本:
[0032]
p(α|β)=∑ip
ibi,k(α)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0033]
步骤1.3具体为:
[0034]
步骤1.3.1,对于下采样后初始点云数据中的点,利用k近邻查找法找到k个与其邻近的点,k=10,由主成分分析法可知:
[0035][0036]
使得该点与其每个近邻点所构成的向量与法向量垂直,式(5)中,f(m)表示所有点在所构成的向量上投影的最小方差,c为所有近邻点和该点的平均值,m为邻域中所有点的个数,xi为邻域中所有点;
[0037]
步骤1.3.2,将c取为邻域中所有点的中心点,即:
[0038][0039]
令yi=x
i-c,yi表示去中心化后的点,于是,式(5)表示为:
[0040][0041]
步骤1.3.3,化简式(7),得到:
[0042]
f(m)=minm
t
sm
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0043]
其中,s=(yy
t
),y表示去中心化后的新数据矩阵,s.t.(m
t
m=1),s表示一个3
×
3的协方差矩阵;
[0044]
步骤1.3.4,将步骤1.3.3得到的协方差矩阵s求解特征值和对应的特征向量分别为λ1、λ2、λ3和a1、a2、a3,其中最小特征值λ3所对应的特征向量a3即为该点处切平面的法向量;
[0045]
步骤1.3.5,重复步骤1.3.1-1.3.4,得到点云数据中所有点的法向量,保存到mat文件中。
[0046]
步骤2具体为:
[0047]
步骤2.1,通过pointnet 网络的四个点集抽象层和四个特征传播层对于步骤1获得的下采样后点云数据进行初始特征提取;
[0048]
步骤2.2,在每个特征传播层后面嵌入残差模块、结合了通道注意力机制和空间注意力机制的注意力机制模块casp;
[0049]
步骤2.3,在步骤2.2嵌入的最后一个注意力机制模块后嵌入spp空间金字塔池化机制模块;
[0050]
步骤2.4,通过全连接层进行初始特征点的分类,预测点云物体中每个点属于边缘点、角点的概率;
[0051]
步骤2.5,对步骤2.4得到的初始特征点分类结果使用非极大抑制算法优化,得到最终特征点分类结果。
[0052]
步骤2.1具体为:
[0053]
步骤2.1.1,将步骤1获得的下采样后点云数据作为输入数据,表示为一个n
×
3的二阶张量,其中n代表点云数量,初始点云数量为8096,3对应坐标维度;
[0054]
步骤2.1.2,通过pointnet 网络的四个点集抽象层首先使用最远点采样法得到npoint个中心点,接着使用半径为radius的球查询方法在中心点附近寻求nsample个点,组成npoint个局部区域,通过多层感知机mlp对于各个局部区域进行初始特征提取,其中点集抽象层表示为sa(npoint,radius,nsample,mlp),其中npoint是采样点总数量,radius是采样半径,nsample是每个采样区域内采样到的点数,mlp是多层感知机参数,四个点集抽象层分别为sa(4096,0.05,32,[32,64]),sa(2048,0.1,32,[64,128]),sa(1024,0.2,32,[128,256])和sa(512,0.4,32,[256,512]);
[0055]
步骤2.1.3,通过pointnet 网络的四个特征传播层使用反距离加权插值法对于点云数据进行上采样并提取点云特征,以恢复原有的点云数量,其中特征传播层表示为fp(mlp),其中mlp是多层感知机参数,四个特征传播层分别为fp(256,256),fp(256,256),fp(256,128),fp(128,128,128);
[0056]
步骤2.2具体为:
[0057]
步骤2.2.1,在步骤2.1中的每个特征传播层后面嵌入残差模块,提取特征。
[0058]
步骤2.2.2,对于步骤2.2.1得到的初始特征分别使用池化卷积核沿着水平方向和
垂直方向聚合特征;
[0059]
步骤2.2.3,对于水平方向和垂直方向分别经过一个二维卷积操作与sigmoid激活操作;
[0060]
步骤2.2.4,将步骤2.2.3得到的张量与经过relu函数激活的输入特征进行逐元素的相乘操作,得到最终的通道注意力输出特征;
[0061]
步骤2.2.5,对步骤2.2.4得到的最终通道注意力输出特征沿着通道轴进行最大池化和平均池化操作,接着concat连接两个特征信息,再经过尺寸为7
×
7的二维卷积操作和maxout激活操作;
[0062]
步骤2.2.6,将步骤2.2.5得到的输出特征与步骤2.2.4得到的最终通道注意力输出特征进行逐元素的相乘,得到结合了通道注意力机制和空间注意力机制的输出特征。
[0063]
步骤2.3具体为:
[0064]
步骤2.3.1,将步骤2.2得到的输出特征通过划分进行最大池化,通道数为128,将划分得到的特征进行拼接,最终得到8096*128的输出特征。
[0065]
步骤2.4具体为:
[0066]
步骤2.4.1,通过全连接层估计点云物体中每个点属于边缘点以及角点的概率值;
[0067]
步骤2.4.2,根据候选点中包括所需要的主要特征点又不含过多的非特征点为原则设置边缘点对应阈值τe和角点对应阈值τc,τe=0.75,τc=0.95;
[0068]
步骤2.4.3,将步骤2.4.1得到的概率值大于对应阈值的点作为初始特征点分类结果;
[0069]
步骤2.4.4,为了减少深度神经网络中的泛化误差,在全连接层后面进行数据批量标准化处理和下降率为0.5的dropout正则化处理。
[0070]
步骤2.5具体为:
[0071]
步骤2.5.1,在计算机中定义并初始化集合s、c,f,其中将步骤2.4得到的初始角点数据存入s,c记为null,f记为null;
[0072]
步骤2.5.2,使用距离阈值δ=0.05l将集合s划分成包含角点的h个窗口,其中l为窗口对角线长度;
[0073]
步骤2.5.3,对于窗口j,j=1,2,...,h,h是不为0的自然数,j中每两个角点的概率值进行排序,较大的一个放入集合c中,并把该点从s中删除;
[0074]
步骤2.5.4,在集合c中取一个概率值最大的点放入集合f中,将集合c置为null;
[0075]
步骤2.5.5,重复步骤2.5.3-2.5.4,集合f中点数据即为最终特征点分类结果。
[0076]
步骤3具体为:
[0077]
步骤3.1,根据步骤2得到的集合f中具有的m个角点生成角点组合o(m2),并创建角点对{pi={f
i1
,f
i2
}|f
i1
,f
i2
∈f},每个角点对都将与开合候选曲线对应起来;
[0078]
步骤3.2,对于每个角点对,通过启发式算法在中心为(f
i1
f
i2
)/2、半径r为||f
i1-f
i2
||/2的球体内均匀采样一个子集得到相应的开合点;
[0079]
步骤3.3,首先嵌入pointnet 网络的四个点集抽象层和四个特征传播层,之后在每个特征传播层后面嵌入残差模块,结合了通道注意力机制与空间注意力机制的注意力机制模块casp,并在最后一个特征传播层后面嵌入spp空间金字塔池化机制模块,最后对于步骤2得到的l个边缘点使用上述网络结构生成相应特征c(
·
),其中点集抽象层与特征传播
层中多层感知机参数分别为sa(32,32,64)、sa(64,64,128),sa(128,128,256)和sa(256,256,512)以及fp(256,256),fp(256,256),fp(256,128),fp(128,128,128);
[0080]
步骤3.4,通过多层感知机mlp创建一个相似性矩阵d∈r
l
×
l
,满足:
[0081]dij
=||c(λi)-c(λj)||2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0082]
式(9)中,d
ij
表示特征c(λi)与特征c(λj)之间的距离,而λi与λj是边缘点的概率值,将相似性矩阵d的每一行作为一个备选子集,并将集合作为第m个备选子集的边缘点集合,其中是一个阈值,用于过滤相差很大特征分数的点,由此得到的相应的闭合点;
[0083]
步骤3.5,将步骤3.2得到的开合点应用于pointnet网络,其中使用了两个mlp层,参数分别为[128,256,512]和[256,256],接着通过全连接层以及损失函数对于特定点是否属于候选曲线进行判断、识别候选曲线的类型(直线、圆或者b-样条曲线),以及预测候选曲线的参数,得到开合候选曲线;
[0084]
步骤3.6,通过三个点β={pa δa,pb δb,pc δc}来参数化每个圆形闭合候选曲线,并对步骤3.4得到的边缘点集合fm进行最远点采样,同时使用pa=pm进行初始化,得到{pa,pb,pc};
[0085]
步骤3.7,将集合fm应用于pointnet网络,通过全连接层以及损失函数进行闭合候选曲线参数预测以及置信度估计,得到闭合候选曲线。
[0086]
步骤4具体为:
[0087]
步骤4.1,给定与步骤3得到的两个开合候选曲线相关联的两组点集,通过o(a,b)=max{i(a,b)/a,i(a,b)/b}来测量两组点集的重叠程度,其中i(a,b)是两组点集相交的基数;
[0088]
步骤4.2,如果o(a,b)大于通过超参数调整确定的阈值τo,就合并这两组点集,并通过保留较大基数者来选择开合最佳曲线,其中τo=0.8;
[0089]
步骤4.3,对于两个闭合候选曲线,当iou(a,b)>τ
iou
时,对闭合候选曲线进行层次聚类,其中τ
iou
设为0.6;
[0090]
步骤4.4,对于步骤4.3聚类得到的每个簇中,通过切角距离衡量候选曲线的匹配分数,最后以最高的置信度在聚类得到的簇当中选择闭合最佳曲线。
[0091]
本发明的有益效果是:
[0092]
本发明首先对于原始点云数据进行预处理工作,包括通过最远点采样算法进行下采样,参数化以及基于主成分分析法的法向量估计,提高了点云物体边缘提取的效率;然后,在pointnet 网络的基础上嵌入了融合残差的注意力机制模块casp,对于通道注意力机制和空间注意力机制进行了结合,并将位置信息嵌入通道注意力当中,使得点云物体边缘部分信息可以得到凸显,并为了进一步提升网络对于全局上下文信息捕获的能力,还引入了金字塔池化机制,通过改进的网络模型进行点云物体特征点分类;接着,根据特征点进行开合点与闭合点的预测,并生成相应的开合候选曲线与闭合候选曲线;最后通过测量点集的重叠程度以及层次聚类对于开合候选曲线与闭合候选曲线选择出最佳曲线。本发明改善了对于点云物体特征点分类不准确的问题,并且提升了点云物体边缘曲线提取的准确度。
附图说明
[0093]
图1是本发明一种点云物体的参数化边缘曲线提取方法实施例中下采样后点云数据;
[0094]
图2是本发明一种点云物体的参数化边缘曲线提取方法实施例中法向量估计结果;
[0095]
图3是本发明一种点云物体的参数化边缘曲线提取方法实施例中初始特征点分类结果;
[0096]
图4是本发明一种点云物体的参数化边缘曲线提取方法实施例中最终特征点分类结果;
[0097]
图5是本发明一种点云物体的参数化边缘曲线提取方法实施例中开合点与闭合点预测结果;
[0098]
图6是本发明一种点云物体的参数化边缘曲线提取方法实施例中候选曲线提取结果;
[0099]
图7是本发明一种点云物体的参数化边缘曲线提取方法实施例中最佳曲线提取结果。
具体实施方式
[0100]
下面结合附图和具体实施方式对本发明进行详细说明。
[0101]
本发明一种点云物体的参数化边缘曲线提取方法,具体按照如下步骤实施:
[0102]
步骤1,通过最远点采样算法对于原始点云数据进行下采样,获得下采样后的点云数据,如图1所示,然后对于点云数据进行参数化表示,并基于主成分分析法得到点云数据各点的法向量,如图2所示;具体为:
[0103]
步骤1.1,对于原始点云数据通过最远点采样算法进行下采样,获得下采样后的点云数据;具体为:
[0104]
步骤1.1.1,在计算机中定义并初始化集合a、b,sample_data,其中a记为null,原始点云数据存入b,sample_data记为null;
[0105]
步骤1.1.2,随机排序集合b,选取第一个点,将其存入集合a中;
[0106]
步骤1.1.3,分别计算出此时集合b中每个点到集合a中点的距离,选取距离最大的点,存入集合a;
[0107]
步骤1.1.4,分别计算出此时集合b中的点pb到集合a中点的距离,从计算出的距离值中选取最小的距离值作为点pb到集合a的距离;
[0108]
步骤1.1.5,对于集合b中的所有点,每个点按照步骤1.1.4计算出来一个距离值,选出最大距离值对应的点存入集合a中;
[0109]
步骤1.1.6,重复步骤1.1.4-1.1.5,直至选出8096个点为止,保存到sample_data;
[0110]
步骤1.2,对于步骤1.1得到的下采样后点云数据进行参数化表示;具体为:
[0111]
步骤1.2.1,将直线通过连接两个角点参数化表示;
[0112]
步骤1.2.2,将圆参数化表示为:
[0113]
β=(p1,p2,p3)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0114]
式(1)中,p1、p2,p3是圆上不共线的任意三个点,将式(1)用圆的法线、中心和半径
表示为:
[0115]
β=(n,c,r)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0116]
式(2)中,n是圆的法线,c是圆的中心,r是圆的半径,接着,在圆上随机采样点,并将其表示为β的函数,生成随机样本:
[0117]
p(α|β)=c r(ucos(α) vsin(α))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0118]
式(3)中,α是圆上随机采样点,α∈[0,2π],且u=p
1-c,v=u
×
n;
[0119]
步骤1.2.3,使用四个控制点来参数化b-样条曲线,其中pi是表示曲线变化情况的控制顶点,用b
i,k(
·
)
来表示第i阶基函数的k次b-样条曲线,并均匀采样点α,α∈[0,1],生成均匀随机样本:
[0120]
p(α|β)=∑ip
ibi,k(α)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0121]
步骤1.3,基于主成分分析法对于步骤1.1得到的下采样后点云数据进行法向量估计;具体为:
[0122]
步骤1.3.1,对于下采样后初始点云数据中的点,利用k近邻查找法找到k个与其邻近的点,k=10,由主成分分析法可知:
[0123][0124]
使得该点与其每个近邻点所构成的向量与法向量垂直,式(5)中,f(m)表示所有点在所构成的向量上投影的最小方差,c为所有近邻点和该点的平均值,m为邻域中所有点的个数,xi为邻域中所有点;
[0125]
步骤1.3.2,将c取为邻域中所有点的中心点,即:
[0126][0127]
令yi=x
i-c,yi表示去中心化后的点,于是,式(5)表示为:
[0128][0129]
步骤1.3.3,化简式(7),得到:
[0130]
f(m)=minm
t
sm
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0131]
其中,s=(yy
t
),y表示去中心化后的新数据矩阵,s.t.(m
t
m=1),s表示一个3
×
3的协方差矩阵;
[0132]
步骤1.3.4,将步骤1.3.3得到的协方差矩阵s求解特征值和对应的特征向量分别为λ1、λ2、λ3和a1、a2、a3,其中最小特征值λ3所对应的特征向量a3即为该点处切平面的法向量;
[0133]
步骤1.3.5,重复步骤1.3.1-1.3.4,得到点云数据中所有点的法向量,保存到mat文件中;
[0134]
步骤2,设计网络模型结构,对步骤1获得的下采样后点云数据进行特征点的分类;具体为:
[0135]
步骤2.1,通过pointnet 网络的四个点集抽象层和四个特征传播层对于步骤1获得的下采样后点云数据进行初始特征提取;具体为:
[0136]
步骤2.1.1,将步骤1获得的下采样后点云数据作为输入数据,表示为一个n
×
3的二阶张量,其中n代表点云数量,初始点云数量为8096,3对应坐标维度;
[0137]
步骤2.1.2,通过pointnet 网络的四个点集抽象层首先使用最远点采样法得到npoint个中心点,接着使用半径为radius的球查询方法在中心点附近寻求nsample个点,组成npoint个局部区域,通过多层感知机mlp对于各个局部区域进行初始特征提取,其中点集抽象层表示为sa(npoint,radius,nsample,mlp),其中npoint是采样点总数量,radius是采样半径,nsample是每个采样区域内采样到的点数,mlp是多层感知机参数,四个点集抽象层分别为sa(4096,0.05,32,[32,64]),sa(2048,0.1,32,[64,128]),sa(1024,0.2,32,[128,256])和sa(512,0.4,32,[256,512]);
[0138]
步骤2.1.3,通过pointnet 网络的四个特征传播层使用反距离加权插值法对于点云数据进行上采样并提取点云特征,以恢复原有的点云数量,其中特征传播层表示为fp(mlp),其中mlp是多层感知机参数,四个特征传播层分别为fp(256,256),fp(256,256),fp(256,128),fp(128,128,128);
[0139]
步骤2.2,在每个特征传播层后面嵌入残差模块、结合了通道注意力机制和空间注意力机制的注意力机制模块casp;具体为:
[0140]
步骤2.2.1,在步骤2.1中的每个特征传播层后面嵌入残差模块,提取特征。
[0141]
步骤2.2.2,对于步骤2.2.1得到的初始特征分别使用池化卷积核沿着水平方向和垂直方向聚合特征;
[0142]
步骤2.2.3,对于水平方向和垂直方向分别经过一个二维卷积操作与sigmoid激活操作;
[0143]
步骤2.2.4,将步骤2.2.3得到的张量与经过relu函数激活的输入特征进行逐元素的相乘操作,得到最终的通道注意力输出特征;
[0144]
步骤2.2.5,对步骤2.2.4得到的最终通道注意力输出特征沿着通道轴进行最大池化和平均池化操作,接着concat连接两个特征信息,再经过尺寸为7
×
7的二维卷积操作和maxout激活操作;
[0145]
步骤2.2.6,将步骤2.2.5得到的输出特征与步骤2.2.4得到的最终通道注意力输出特征进行逐元素的相乘,得到结合了通道注意力机制和空间注意力机制的输出特征;
[0146]
步骤2.3,在步骤2.2嵌入的最后一个注意力机制模块后嵌入spp空间金字塔池化机制模块;具体为:
[0147]
步骤2.3.1,将步骤2.2得到的输出特征通过划分进行最大池化,通道数为128,将划分得到的特征进行拼接,最终得到8096*128的输出特征;
[0148]
步骤2.4,通过全连接层进行初始特征点的分类,预测了点云物体中每个点属于边缘点、角点的概率,分类结果如图3所示;具体为:
[0149]
步骤2.4.1,通过全连接层估计点云物体中每个点属于边缘点以及角点的概率值;
[0150]
步骤2.4.2,根据候选点中包括所需要的主要特征点又不含过多的非特征点为原则设置边缘点对应阈值τe和角点对应阈值τc,τe=0.75,τc=0.95;
[0151]
步骤2.4.3,将步骤2.4.1得到的概率值大于对应阈值的点作为初始特征点分类结果;
[0152]
步骤2.4.4,为了减少深度神经网络中的泛化误差,在全连接层后面进行数据批量
标准化处理和下降率为0.5的dropout正则化处理;
[0153]
步骤2.5,对步骤2.4得到的初始特征点分类结果使用非极大抑制算法优化,得到最终特征点分类结果,如图4所示;具体为:
[0154]
步骤2.5.1,在计算机中定义并初始化集合s、c,f,其中将步骤2.4得到的初始角点数据存入s,c记为null,f记为null;
[0155]
步骤2.5.2,使用距离阈值δ=0.05l将集合s划分成包含角点的h个窗口,其中l为窗口对角线长度;
[0156]
步骤2.5.3,对于窗口j,j=1,2,...,h,h是不为0的自然数,j中每两个角点的概率值进行排序,较大的一个放入集合c中,并把该点从s中删除;
[0157]
步骤2.5.4,在集合c中取一个概率值最大的点放入集合f中,将集合c置为null;
[0158]
步骤2.5.5,重复步骤2.5.3-2.5.4,集合f中点数据即为最终特征点分类结果;
[0159]
步骤3,根据步骤2获得的特征点生成开合候选曲线和闭合候选曲线;具体为:
[0160]
步骤3.1,根据步骤2得到的集合f中具有的m个角点生成角点组合o(m2),并创建角点对{pi={f
i1
,f
i2
}|f
i1
,f
i2
∈f},每个角点对都将与开合候选曲线对应起来;
[0161]
步骤3.2,对于每个角点对,通过启发式算法在中心为(f
i1
f
i2
)/2、半径r为||f
i1-f
i2
||/2的球体内均匀采样一个子集得到相应的开合点;
[0162]
步骤3.3,首先嵌入pointnet 网络的四个点集抽象层和四个特征传播层,之后在每个特征传播层后面嵌入残差模块,结合了通道注意力机制与空间注意力机制的注意力机制模块casp,并在最后一个特征传播层后面嵌入spp空间金字塔池化机制模块,最后对于步骤2得到的l个边缘点使用上述网络结构生成相应特征c(
•
),其中点集抽象层与特征传播层中多层感知机参数分别为sa(32,32,64)、sa(64,64,128),sa(128,128,256)和sa(256,256,512)以及fp(256,256),fp(256,256),fp(256,128),fp(128,128,128);
[0163]
步骤3.4,通过多层感知机mlp创建一个相似性矩阵d∈r
l
×
l
,满足:
[0164]dij
=||c(pi)-c(pj)||2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0165]
式(9)中,d
ij
表示特征c(λi)与特征c(λj)之间的距离,而λi与λj是边缘点的概率值,将相似性矩阵d的每一行作为一个备选子集,并将集合作为第m个备选子集的边缘点集合,其中是一个阈值,用于过滤相差很大特征分数的点,由此得到的相应的闭合点,预测的开合点与闭合点结果如图5所示;
[0166]
步骤3.5,将步骤3.2得到的开合点应用于pointnet网络,其中使用了两个mlp层,参数分别为[128,256,512]和[256,256],接着通过全连接层以及损失函数对于特定点是否属于候选曲线进行判断、识别候选曲线的类型(直线、圆或者b-样条曲线),以及预测候选曲线的参数,得到开合候选曲线;
[0167]
步骤3.6,通过三个点β={pa δa,pb δb,pc δc}来参数化每个圆形闭合候选曲线,并对步骤3.4得到的边缘点集合fm进行最远点采样,同时使用pa=pm进行初始化,得到{pa,pb,pc};
[0168]
步骤3.7,将集合fm应用于pointnet网络,通过全连接层以及损失函数进行闭合候选曲线参数预测以及置信度估计,得到闭合候选曲线,候选曲线提取结果如图6所示;
[0169]
步骤4,根据步骤3获得的开合候选曲线和闭合候选曲线选择出最佳曲线;具体为:
[0170]
步骤4.1,给定与步骤3得到的两个开合候选曲线相关联的两组点集,通过o(a,b)=max{i(a,b)/a,i(a,b)/b}来测量两组点集的重叠程度,其中i(a,b)是两组点集相交的基数;
[0171]
步骤4.2,如果o(a,b)大于通过超参数调整确定的阈值τo,就合并这两组点集,并通过保留较大基数者来选择开合最佳曲线,其中τo=0.8;
[0172]
步骤4.3,对于两个闭合候选曲线,当iou(a,b)>τ
iou
时,对闭合候选曲线进行层次聚类,其中τ
iou
设为0.6;
[0173]
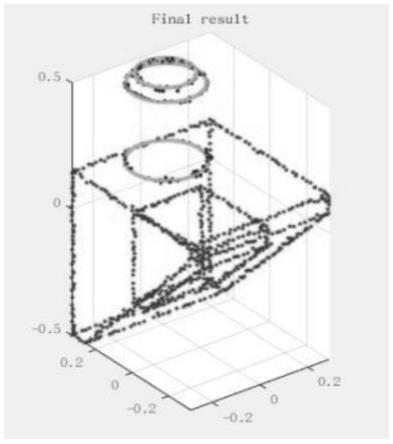
步骤4.4,对于步骤4.3聚类得到的每个簇中,通过切角距离衡量候选曲线的匹配分数,最后以最高的置信度在聚类得到的簇当中选择闭合最佳曲线,最佳曲线提取结果如图7所示。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。