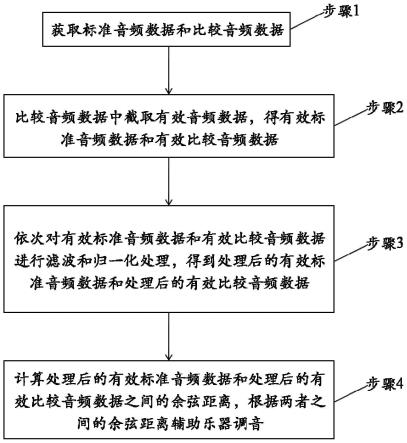
1.本发明涉及语音信号降噪技术领域,尤其涉及一种期望声源方向可调的双麦克风降噪方法。
背景技术:
2.蓝牙耳机等便携设备自从问世以来逐渐成为人们日常生活中提升效率的好工具,但是用户在使用其拨打或接听电话时,如果受到背景噪声及非目标方向语音等的干扰,通话质量会急剧下降。在这种情况下,保留靠近用户说话方向的语音,在保证语音不失真的前提下尽可能地抑制背景噪声及非目标方向语音成为迫切需求。
3.现有的广义旁瓣抵消器(generalized sidelobe canceller,gsc)和延迟波束形成器使用多个麦克风记录信号进行空间滤波。对于蓝牙耳机等便携设备来说,gsc过于复杂,超出了微型器件的能力范围。延迟波束形成技术如一阶差分麦克风(the first-order differential microphone,fdm)和自适应零形成方法(adaptive null-forming,anf)只需要两个麦克风,是适合于尺寸限制和实时处理的设置。但这种固定波束形成器在0
°
处有一个最大增益,在180
°
处有一个零点,不能消除零点以外方向的噪声。基于输入信号之间的相干函数的算法,讨论了相干函数中实部和虚部的性质,以产生不同的掩蔽噪声的手段。基于相干函数的方法不依赖于噪声统计量,但目标方向不可调整。用于助听器的竞争方向噪声消除方法将频谱估计和阵列波束形成相结合来抑制噪声。在纯噪声区间估计指向性系数,并对其进行更新以适应移动噪声。类似地,此方法只能将期望方向设置为0
°
附近的有限范围。由于声源的位置有时是不恒定的,因此在实际应用中设计声源方向可调的降噪算法是很重要的。
4.为了解决波束形成直接应用于近距离双麦克风系统时无法准确消除非目标方向声音及期望声源方向不能根据需求设定等问题,提出一种基于波束形成与维纳滤波的两步去噪方法。测试结果表明:在低信噪比、多种类型噪声源共同存在的情境下,此方法可以有效地恢复原始信号的能量分布特点,降低背景噪声和非目标方向语音,明显提升信噪比,另外,本发明可预置期望声源方向,以适应声源变化的场景。
技术实现要素:
5.根据现有技术存在的问题,本发明公开了一种期望声源方向可调的双麦克风降噪方法,具体包括:
6.预处理过程:对双麦克风接收到的带噪信号x1(t)和x2(t)进行离散采样、预加重、分帧及加窗处理,再经过短时傅里叶变换得到频域信号x1(ω)和x2(ω);
7.波束形成过程:在双麦克风连线的中点处引入虚拟麦克风,根据中心差分格式对频域信号x1(ω)和x2(ω)进行差分变换,构造差分信号y1(ω)和y2(ω),计算差分信号y1(ω)和y2(ω)的功率谱的统计平均值,并将统计平均值的比值记为方向性函数γ(ω,θ),分析方向性函数γ(ω,θ)的性质,通过归一化函数将其直接映射为噪声掩蔽值λ(ω),将频
域信号x1(ω)与噪声掩蔽值λ(ω)相乘得到消除掉竞争方向噪声后的信号r1(ω);
8.后置维纳滤波过程:对r1(ω)中的信号能量和噪声能量进行估计得到通道信噪比并计算增益函数,从而消除信号r1(ω)中的残余噪声。
9.进一步的,所述预处理过程为:
10.将带噪信号x1(t)和x2(t)进行离散采样,再对语音的高频部分进行预加重处理;
11.将采样信号x1(n)和x2(n)分为长度为10ms的帧后加等长的汉明窗w(n),加窗后的信号通入缓存区留待处理,经过短时傅里叶变换得到当前帧频域信号,根据实数序列傅里叶变换的共轭对称性,输出前1/2个频点的信号进行波束形成处理。
12.进一步的,所述波束形成过程包括幅度对齐、计算功率谱、计算方向性函数值、计算阈值和归一化映射;
13.幅度对齐方式为对频域信号x1(ω)和x2(ω)分别乘以比例因子进行幅度对齐;
14.计算功率谱时:假设期望波束为s(ω),其方向预置为α,在双路麦克风中点处引入虚拟麦克风接收期望波束s(ω),根据中心差分格式和频域信号x1(ω)、x2(ω)与期望波束s(ω)的空间关系构造差分信号y1(ω)和y2(ω),计算差分信号y1(ω)和y2(ω)的功率谱;
15.计算方向性函数值时:其中差分信号y1(ω)和y2(ω)功率谱的统计平均值的比值为方向性函数γ(ω,θ)的值,讨论γ(ω,θ)的性质,当声源实际入射方向θ等于给定的期望声源入射方向α时,γ(ω,θ)趋于无穷,并且在θ=α轴的两边,函数值单调且近似对称;
[0016][0017]
计算阈值及归一化映射时:由于γ(ω,θ)趋于无穷大,根据预先设定的主瓣宽度θ计算一个阈值ω,通过sigmoid函数的归一化映射,直接将γ(ω,θ)映射成对应频点的噪声掩蔽值λ(ω),将x1(ω)与λ(ω)相乘得到消除掉竞争方向噪声后的信号r1(ω)。
[0018][0019][0020]
进一步的,所述后置维纳滤波过程包括计算信噪比指数、计算对数谱偏差、修改或重置噪声标志和计算增益函数值;
[0021]
计算信噪比指数时,将信号r1(ω)根据临界带宽准则分为若干个通道,估计每个通道的能量,将通道噪声能量估计初始化为前四帧的通道能量,据此计算通道信噪比指数;
[0022]
计算对数谱偏差时,设计非线性数据表作为语音指标表,将信噪比指数映射成度量语音质量的一组数字,将一定频率范围内的语音指标总和作为当前通道的语音质量评估结果,对当前通道的信号能量取对数,并计算长时对数谱能量与短时对数谱能量的偏差;
[0023]
修改或重置噪声标志,根据计算所得的语音指标总和、信噪比指数、对数谱偏差参数信息,判断当前帧是语音帧还是噪声帧,重置噪声更新标志,检查前几帧的更新标志,如
果噪声长时间得不到更新,认为结果已不可靠,则强制更新信噪比指数;
[0024]
计算增益函数值时,利用通道信噪比指数计算通道增益值去除残余的背景噪声,根据噪声更新标志的结果,更新下一帧的噪声能量估计。
[0025]
由于采用了上述技术方案,本发明提供的一种期望声源方向可调的双麦克风降噪方法,该方法在对双麦克风信号进行预处理后,首先计算构造的差分信号功率谱统计平均值的比值作为方向性函数的值,然后通过归一化函数的映射得到噪声的掩蔽值。同时,在下一步安装维纳滤波器,通过估计信噪比指数及计算增益函数来减少残余噪声;本发明提出的算法简单高效,不同的噪声场景中受非目标声音干扰的语音被增强后,其信噪比和质量均有显著提高。
附图说明
[0026]
为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0027]
图1为本发明方法的整体示意图;
[0028]
图2为本发明中预处理过程的示意图;
[0029]
图3为本发明中波束形成过程的示意图;
[0030]
图4为本发明中声源传播示意图;
[0031]
图5为本发明中方向性函数示意图;
[0032]
图6为本发明中后置维纳滤波过程的示意图;
[0033]
图7为单噪声源不同信噪比时本发明与其他降噪方法pesq对比结果图;
[0034]
图8为多噪声源不同信噪比时本发明与其他降噪方法pesq对比结果图;
[0035]
图9为单噪声源不同信噪比时本发明与其他降噪方法segsnr对比结果图;
[0036]
图10为多噪声源不同信噪比时本发明与其他降噪方法segsnr对比结果图;
[0037]
图11为本发明中期望声源方向不同时结果示意图。
具体实施方式
[0038]
为使本发明的技术方案和优点更加清楚,下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚完整的描述:
[0039]
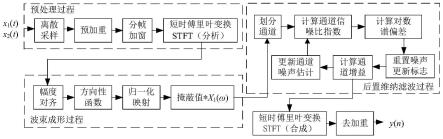
如图1所示的一种期望声源方向可调的双麦克风降噪方法,在实施过程中包括:预处理过程、波束形成过程和后置维纳滤波过程。本发明公开的方法具体步骤如下:
[0040]
s1:预处理过程如图2,对双麦克风接收的带噪信号x1(t)和x2(t)进行离散采样、预加重、分帧及加窗后,通过短时傅里叶变换得到频域信号x1(ω)和x2(ω),具体采用如下方式:
[0041]
s11:对带噪的连续信号x1(t)和x2(t)先进行离散采样,采样频率为16khz。通过一阶fir高通数字滤波器来实现对语音高频部分的预加重,其中emp_fac为预加重系数。设n时刻的语音信号采样值为x(n),经过预加重处理后的结果为:
[0042]
z(n)=x(n)-emp_fac*x(n-1)
ꢀꢀꢀꢀ
(1)
[0043]
取emp_fac=0.8,在经过降噪过程后,利用短时傅里叶变换合成时域信号,还需要对其进行去加重操作,还原高频部分。
[0044]
s12:将采样信号x1(n)和x2(n)分帧,帧长为10ms,对分帧后的信号加等长的汉明窗,窗函数公式如式(2),加窗后的信号通入缓存区,缓存区长度是fft点数的5倍。
[0045][0046]
s13:经过快速傅里叶变换得到当前帧频域信号,根据实数序列快速傅里叶变换的共轭对称性,输出前1/2个频点的信号进行后续的算法处理。
[0047]
s2:波束形成过程如图3,在双麦克风连线的中点处引入一个虚拟麦克风,将得到的频域信号x1(ω)和x2(ω)根据中心差分格式进行差分变换,构造差分信号y1(ω)和y2(ω),计算y1(ω)和y2(ω)的功率谱的统计平均值,并将统计平均值的比值记为方向性函数γ(ω,θ)。分析γ(ω,θ)的性质,通过归一化函数可将其直接映射为噪声掩蔽值,具体采用如下方式:
[0048]
s21:幅度对齐,尽管将声场假设为远场,但双麦克风的接收信号在幅度上还是有细微的差异。为了进一步符合假设,先对两路频域信号x1(ω)和x2(ω)分别乘以比例因子进行幅度对齐。
[0049]
s22:假设期望波束为s(ω),其方向预置为α,在双路麦克风中点处引入一个虚拟麦克风接收此信号,声源传播示意图如图4。x1(ω)、x2(ω)与s(ω)的空间关系为:
[0050][0051][0052]
其中,d为麦克风间距,v为声速,θ为实际的声源入射方向;根据中心差分格式和x1(ω)、x2(ω)与s(ω)的空间关系,构造差分信号y1(ω)和y2(ω),并计算y1(ω)和y2(ω)的功率谱。
[0053][0054]
s23:y1(ω)和y2(ω)功率谱的统计平均值的比值即为方向性函数γ(ω,θ)的值。
[0055][0056]
γ(ω,θ)的图像如图5,发现当声源实际入射方向θ等于给定的期望声源入射方向α时,γ(ω,θ)趋于无穷;并且在θ=α轴的两边,函数值单调且近似对称;
40db)时,缓慢平滑(alpha=0.99);低tce(-60db)时,快速平滑(alpha=0.50)。
[0076][0077]
s37:计算并更新长时对数谱能量。
[0078][0079]
s38:根据计算所得的语音指标总和、信噪比、对数谱偏差等参数,通过比较,重置噪声更新标志update_flag。“update_flag=true”表示当前帧是噪声帧,“update_flag=false”表示当前帧是语音帧。之后还需要检查前几帧的噪声更新标志,如果噪声长时间得不到更新,认为现结果不可靠,需要强制更新信噪比指数。
[0080]
s39:利用得到的通道信噪比指数计算通道增益ftmp2。
[0081][0082][0083]
如果噪声更新标志update_flag=true,即认为当前帧判定为噪声帧,此时需要更新噪声的能量估计。
[0084]
为了验证本发明的有效性,进行了若干测试。需要说明,为了验证方法适用于多种类型的声音,用于评估的语音数据来源于timit数据库,噪声包括babble噪声和竞争方向语音。本发明中的实验结果均是处理10段语音数据平均得到的结果。
[0085]
将本发明与coherence和snr-coherence两种方法进行了比较,首先设置α=0
°
。图7及图8为不同方法在加入各种噪声(包括竞争语音和babble噪声)后的pesq得分。显然,本发明优于coherence方法,与snr-coherence相差不多。一般情况下,本发明的pesq结果比未处理信号至少高0.5,且在多个噪声源条件下仍能保持该效果。
[0086]
图9和图10显示了当干扰为非目标语音和babble噪声时,在低信噪比(-5db和0db)的情况下,本发明的segsnr值比未处理时至少提高了5db。本发明的segsnr结果既高于snr-coherence方法,又几乎等于coherence方法。此外,在有多个噪声源的情况下,本发明保持了最优效果。
[0087]
同时,将期望方向设置在其他角度时的评价结果如图11所示。可以看出,与处理前的声音相比,本发明仍能保持良好的噪声抑制能力。
[0088]
以上比较性测试均显示了本发明良好的降噪性能和不错的工作稳定性。
[0089]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。