1.本发明涉及语音合成技术领域,特别涉及一种基于韵律特征的并行语音合成方法及装置、介质、设备。
背景技术:
2.语音合成是指从文本中合成出可理解的、自然的语音,又称文本转语音(text to speech,tts)在人类通信中有着广泛的应用,一直是人工智能、自然语言和语音处理领域的热点研究课题。语音合成经历了三个发展阶段,分别是基于拼接的语音合成、基于统计参数的语音合成和基于神经网络的语音合成。随着深度学习的蓬勃发展,基于神经网络的语音合成得到了井喷式发展,语音合成的音质和自然流畅度都得到明显改善。目前基于神经网络的主流语音合成技术分为两类:自回归语音合成和非自回归语音合成。自回归语音合成的语音音质和流畅度高,但是由于其自回归结构导致合成速度较慢、鲁棒性较低,且会出现重复字和吞字的问题。目前,解决自回归语音合成慢的方法主要是通过将整句进行切片处理,从而达到并行的目的。但是,这种方法本质上还是自回归结构的语音合成,合成速度较慢,且没有从根本上避免鲁棒性低的问题。非自回归合成的速度较快且鲁棒性高,但是合成的语音音质和流畅度低。
3.本专利从实用角度出发,提出了一种基于韵律特征的并行语音合成方法及装置、介质、设备。首先,将待合成语音文本正则化;其次,将所述正则化语音文本并行转换为音素序列和音素韵律序列;然后,将所述音素序列和所述音素韵律序列利用声学模型预测其梅尔频谱图;最后,将所述梅尔频谱图利用hifi-gan声码器转换为所述待合成语音文本的语音信号。本专利融自回归语音合成和非自回归语音合成的优势,不仅能有效提升语音合成的音质、流畅度、速度和鲁棒性,而且能实现实时的高效语音合成。基于本专利开发的系统可广泛应用于人工智能领域的智能化语音合成,如智能客服、智能音响、语音播报、地图导航和有声读物等人机交互场景。
技术实现要素:
4.鉴于上述问题,本发明提供了一种基于韵律特征的并行语音合成方法及装置、介质、设备。
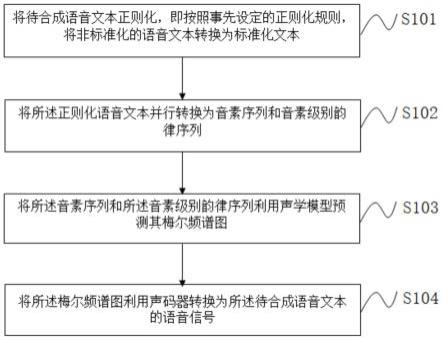
5.根据本发明的一个方面,提供了一种基于韵律特征的并行语音合成方法,包括:
6.(1)将待合成语音文本正则化,即按照事先设定的正则化规则,将非标准化的语音文本转换为标准化文本;
7.(2)将所述正则化语音文本并行转换为音素序列和音素级别韵律序列;
8.(3)将所述音素序列和所述音素级别韵律序列利用声学模型预测其梅尔频谱图;
9.(4)将所述梅尔频谱图利用声码器转换为所述待合成语音文本的语音信号。
10.进一步的,所述步骤2中所述正则化语音文本转换为音素序列,包括:
11.利用基于条件随机场的中文文本转音素模型g2pc将所述正则化语音文本转换为
拼音;
12.利用自定义的拼音和音素字典将所述拼音映射到对应音素并生成所述音素序列。
13.进一步的,所述步骤2中所述正则化语音文本转换为音素级别韵律序列,包括:
14.对所述正则化语音文本进行分词及词性标注工作;
15.利用韵律预测网络,将标注后的所述正则化语音文本转换为词级别韵律序列;
16.利用长度对齐机制将所述词级别韵律序列映射到所述音素级别韵律序列。
17.进一步的,所述韵律预测网络为两个双向长短期记忆人工神经网络lstm与两个线性层组成的语言模型或预训练语言模型bert。
18.进一步的,所述步骤3中的声学模型,包括编码器模块、解码器模块和后处理网络;
19.所述编码器模块和解码器模块均基于conformer blocks;所述解码器模块采用非自回归的结构;
20.所述后处理网络对所述预测的梅尔频谱图进行校正,同时捕捉所述音素序列和所述音素级别韵律序列间长期依赖关系和细节特征,以提升合成语音的音质和流畅度。
21.进一步的,所述编码器模块为4层conformer blocks,所述解码器模块为6层conformer blocks,所述后处理网络为5层一维卷积,且卷积核大小为1
×
3。
22.进一步的,所述步骤4中的声码器是hifi-gan声码器。
23.根据本发明的另一个方面,还提供了一种基于韵律特征的并行语音合成装置,包括:
24.信息获取模块,适于获取待合成语音文本,并将其进行正则化;
25.音素序列生成模块,适于将所述正则化语音文本转换为音素序列;
26.音素级别韵律序列生成模块,适于将所述正则化语音文本转换为音素级别韵律序列;
27.频谱生成模块,适于将所述音素序列和所述音素级别韵律序列利用声学模型预测其梅尔频谱图;
28.语音合成模块,适于将所述梅尔频谱图利用声码器转换为所述待合成语音文本的语音信号。
29.根据本发明的又一个方面,还提供了一种计算机可读存储介质,其特征在于,所述计算机可读存储介质用于存储程序代码,所述程序代码用于执行上述任一项所述的基于韵律特征的并行语音合成方法。
30.根据本发明的又一个方面,还提供了一种计算设备,其特征在于,所述计算设备包括处理器以及存储器:
31.所述存储器用于存储程序代码,并将所述程序代码传输给所述处理器;
32.所述处理器用于根据所述程序代码中的指令执行上述任一项所述的基于韵律特征的并行语音合成方法。
33.本发明的有益效果:
34.本专利融合自回归合成和非自回归合成的优势,不仅能有效提升语音合成的音质、流畅度、速度和鲁棒性,而且能实现实时的高效语音合成。基于本专利开发的系统可广泛应用于人工智能领域的智能化语音合成领域,如智能客服、智能音响、语音播报、地图导航、有声读物等人机交互场景。语音合成系统的好坏最直观的判断是合成的音频质量好坏,
即常用的平均意见得分(mean opinion score,mos)值。本专利基于标贝公开语音合成数据集的合成语音韵律和流畅度的mos值分别为4.16和4.05。
附图说明
35.图1是本发明实施例的基于韵律特征的并行语音合成方法流程示意图。
36.图2是本发明实施例的基于韵律特征的并行语音合成方法结构示意图。
37.图3是本发明实施例的文本前端处理模块结构示意图。
38.图4是本发明实施例的韵律预测结构示意图。
39.图5是本发明实施例的声学模型结构示意图。
40.图6是本发明实施例的基于韵律特征的并行语音合成装置结构示意图。
具体实施方式
41.以下将结合具体实施例对本发明的一种基于韵律特征的并行语音合成方法及装置、介质、设备作进一步的详细描述。
42.图1示出了根据本发明实施例的基于韵律特征的并行语音合成方法流程示意图,图2示出了根据本发明实施例的基于韵律特征的并行语音合成方法结构示意图。参见图1、图2可知,包括以下步骤:
43.s101:将待合成语音文本正则化;
44.输入:待合成语音文本
45.输出:正则化语音文本
46.该模块主要是通过人工设定正则化规则,将非标准化的语音文本转换为标准化文本。具体规则包括但不限于:
47.基础的编码转换,例如:将繁体字符转换为简体字符。
48.日期正则,例如:将2022-03-28转换为二零二二年三月二十八日。
49.时间正则,例如:将10:30等转换为十点三十分钟。
50.温度正则,例如:将
°
和℃转换为标准温度形式度和摄氏度。
51.分数正则,例如:将1/2转换为二分之一。
52.百分数正则,例如:将90%转换为百分之九十。
53.固定电话/手机号码和身份证号码正则,例如:将固定电话/手机号码和身份证号码中的1转换为幺。
54.范围正则,例如:将1-9转换为一至九。
55.数字 量词正则化,例如:将2棵树中的量词2转换为两。
56.数字正则,将语音文字中的阿拉伯数字转换为中文字符。
57.网址和邮箱正则,例如:将www.sues.edu.cn转换为三w点sues点edu点cn。
58.s102:将所述正则化语音文本并行转换为音素序列及音素级别韵律序列;
59.图3示出了本发明实施例的文本前端处理模块结构示意图。如图3所示,正则化语音文本被分别转换为音素序列和音素级别韵律序列。
60.正则化语音文本转换为音素序列
61.输入:正则化语音文本(s101的输出)
62.输出:音素序列
63.首先,利用基于条件随机场的中文文本转音素模型g2pc(grapheme-to-phoneme for chinese)将正则化语音文本转换为拼音,能有效处理中文多音字的问题,如行可以读hang和xing。其次,利用自定义的拼音和音素字典,将拼音映射到对应音素并生成音素序列。
64.正则化语音文本转换为音素级别韵律序列
65.输入:正则化语音文本(s101的输出)
66.输出:音素级别韵律序列
67.图4给出了本发明实施例的韵律预测结构示意图。首先,对正则化语音文本进行分词及词性标注工作。其次,利用两个双向长短期记忆人工神经网络(long short-term memory,lstm)与两个线性层,将标注后的正则化语音文本转换为词级别韵律序列。其中基于两个双向lstm与两个线性层的韵律预测网络可以替换的技术包括预训练语言模型bert(bidirectional encoder representations from transformers)。
68.最后,利用长度对齐机制将词级别韵律序列映射到音素级别韵律序列。例如:一个词包含两个音素,则将这个词的韵律序列进行复制扩充到音素的长度。
69.s103:将所述音素序列和所述音素级别韵律序列利用声学模型预测其梅尔频谱图;
70.输入:音素序列(s102的输出)和音素级别韵律序列(s102的输出)
71.输出:梅尔频谱图
72.声学模型是语音合成最重要的模块,图5示出了本发明实施例的声学模型结构示意图。本专利基于序列到序列(sequence to sequence,seq2seq)的思想,在声学模型中使用传统的编码器模块与解码器模块。特别地,在解码器中利用非自回归的结构,使得整体语音合成速度更快。同时,为了使语音合成音质和自然流畅度更高,基于conformer blocks构建声学模型并利用后处理网络对预测的梅尔频谱进行校正,可同时捕捉音素(韵律)序列间长期依赖关系和细节特征,继而提升合成语音音质和流畅度。本专利中,编码器默认为4层conformer blocks,解码器默认为6层conformer blocks,后处理网络默认为5层一维卷积,且卷积核大小为1
×
3。
73.s104:将所述梅尔频谱图利用声码器转换为语音信号。
74.输入:梅尔频谱图(s103的输出)
75.输出:语音信号
76.声码器也是合成高质量语音一个关键因素,传统方法大多利用统计参数模型,如griffin-lim等。随着生成对抗神经网络(generative adversarial net,gan)的发展,基于gan的声码器技术得到快速发展,不仅语音合成质量高,而且语音合成速度快。本专利采用的是hifi-gan声码器(v1版本),可以替换的技术包括parallel wave gan(pwg)等其他声码器。
77.本发明实施例还提供了一种基于韵律特征的并行语音合成装置,如图6所示,包括:
78.信息获取模块610,适于获取待合成语音文本,并将其进行正则化;
79.音素序列生成模块620,适于将所述正则化语音文本转换为音素序列;
80.音素级别韵律序列生成模块630,适于将所述正则化语音文本转换为音素级别韵律序列;
81.频谱生成模块640,适于将所述音素序列和所述音素级别韵律序列利用声学模型预测其梅尔频谱图;
82.语音合成模块650,适于将所述梅尔频谱图利用声码器转换为所述待合成语音文本的语音信号。
83.在本发明一可选实施例中,还提供了一种计算机可读存储介质,计算机可读存储介质用于存储程序代码,程序代码用于执行上述一实施例的基于韵律特征的并行语音合成方法。
84.在本发明一可选实施例中,还提供了一种计算设备,计算设备包括处理器以及存储器:存储器用于存储程序代码,并将程序代码传输给处理器;处理器用于根据程序代码中的指令执行上述一实施例的基于韵律特征的并行语音合成方法。
85.本发明实施例提供了一种基于韵律特征的并行语音合成方法及装置、介质、设备。在本发明实施例提供的方法中,融合自回归语音合成和非自回归语音合成的优势,不仅能有效提升语音合成的音质、流畅度、速度和鲁棒性,而且能实现实时的高效语音合成。基于本专利开发的系统可广泛应用于人工智能领域的智能化语音合成领域,如智能客服、智能音响、语音播报、地图导航和有声读物等人机交互场景。语音合成系统的好坏最直观的判断是合成的音频质量好坏,即常用的mos值。本专利基于标贝公开语音合成数据集的合成语音韵律和流畅度的mos值分别为4.16和4.05。
86.在本发明各个实施例中的各功能单元可以物理上相互独立,也可以两个或两个以上功能单元集成在一起,还可以全部功能单元都集成在一个处理单元中。上述集成的功能单元既可以采用硬件的形式实现,也可以采用软件或者固件的形式实现。
87.本领域普通技术人员可以理解:所述集成的功能单元如果以软件的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,其包括若干指令,用以使得一台计算设备(例如个人计算机,服务器,或者网络设备等)在运行所述指令时执行本发明各实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom)、随机存取存储器(ram),磁碟或者光盘等各种可以存储程序代码的介质。
88.或者,实现前述方法实施例的全部或部分步骤可以通过程序指令相关的硬件(诸如个人计算机,服务器,或者网络设备等的计算设备)来完成,所述程序指令可以存储于一计算机可读取存储介质中,当所述程序指令被计算设备的处理器执行时,所述计算设备执行本发明各实施例所述方法的全部或部分步骤。
89.最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:在本发明的精神和原则之内,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案脱离本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。