1.本发明属于神经网络技术领域,具体涉及一种基于低维卷积神经网络的太阳耀斑时间序列分类方法。
背景技术:
2.突然破裂电磁辐射是在太阳表面,以光速传播,在499.0秒内到达地球,有能力影响无线电通信系统,影响全球定位系统(gps),中和空间设备,导致地球电力停电和宇航员的健康有害,当达到一定的大小。这种电磁爆发被称为太阳耀斑现象,当达到x级震级时,它会导致大规模的停电,造成的损失很容易超过数十亿美元的维修和数月的重建费用。因此,在考虑多个时间窗范围的情况下,建立准确可靠的太阳耀斑预报对于在任务危急情况下做出决策和采取保护措施是至关重要的。
3.现有技术存在的问题或者缺陷:基于机器学习(ml)算法对太阳耀斑进行预测的实验中,由于其本身的局限性和特征提取能力不足,导致太阳耀斑的预测准确率不高,同时在深层神经网络和大数据的巨大增长和硬件进步的背景下,基于深度神经网络对太阳耀斑的预测显得越来越急迫。
技术实现要素:
4.基于此,本发明提供了一种基于低维卷积神经网络的太阳耀斑时间序列分类方法,从goes任务中获取1分钟平均x射线(0.1-0.8nm)时间序列数据,并根据时间进行手动数据的划分并完成数据标注。完成数据收集后,对数据进行预处理,预处理包括数据分割,归一化。将预处理后的数据输入搭建好的低维卷积神经网络进行网络模型的训练,待到模型损失函数不再下降,保存模型,完成模型构建,最后通过测试集和不同的评价指标对模型的性能进行评估说明。
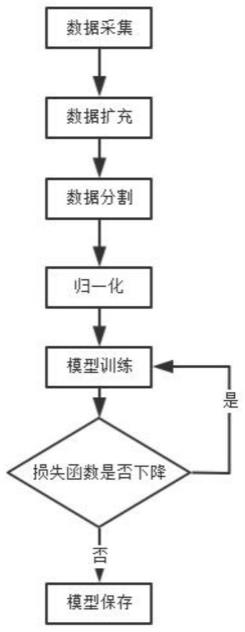
5.本技术公开的一种基于低维卷积神经网络的太阳耀斑时间序列分类方法,包括如下步骤,
6.s1、数据采集:采集太阳耀斑数据,并对其类别进行标注,完成模型训练所需数据集的构建;
7.s2、数据预处理:对数据进行预处理,通过不同的数据分割方法对太阳耀斑的不同类型进行划分,保证模型训练效果;
8.s3、模型构建:采用低维卷积神经网络搭建识别分类模型,输入训练数据,完成参数模型的搭建;
9.s4、模型保存:当模型的损失函数不再降低之后,保存模型;
10.s5、模型评估:通过不同的评价指标对保存后的模型进行性能评估,了解其性能。
11.进一步的,所述步骤s1中,从goes任务的数据库中获取1分钟平均x射线(0.1-0.8nm)时间序列数据,所述goes任务是利用成像仪设备收集地球表面和大气的红外辐射和可见光太阳反射,以及利用声波设备收集大气温度、湿度剖面、表面和云顶温度以及臭氧分
布。
12.进一步的,所述步骤s2中:包括数据分割和数据归一化处理。
13.进一步的,所述步骤s3中:利用低维卷积神经网络构建一个分类时间序列模型作为太阳耀斑的预测,模型由4个卷积层组成,其离散二维卷积公式如下:
14.其中表示第l层在索引i,j处的特征图k,xl-1表示第l-1层并为当前层的输入,是尺寸为(2n 1)
×
(2m 1)的核,s表示步长,p为边界的填充,每层后面有一个relu激活函数,4个最大池化层,一个全连接层和一个带有softmax激活函数的输出层,其公式分别如下:
15.relu(x)=max(0,x),
[0016][0017]
其中表示第i,j层的池化张量k在特征映射上的最大池化操作,s’,n’,m’分别为步长,x是实数的输入向量,k是类别的个数。
[0018]
进一步的,所述步骤s3中,还包括如下步骤:每个最大池化层后面都有一个dropout层,dropout概率为10%,用于正则化和避免模型过拟合,将训练数据输入分类模型中进行训练,通过四层卷积层输出相应的特征图,利用卷积层中的每个核与输入张量卷积,生成一个特征映射,最终在输出层通过softmax激活函数将输出映射到分类概率空间。
[0019]
进一步的,所述步骤s4中,通过使用交叉熵损失函数进行训练,当模型的损失函数不再降低之后,保存模型,交叉熵损失函数公式如下:
[0020][0021]
其中y为真实值,为模型输出预测向量,m为数据类型的总量。
[0022]
进一步的,所述步骤s5中,通过不同的评价指标对保存后的模型进行性能评估,了解其相关的性能,其评价指标如下:
[0023][0024][0025][0026]
其中acc为正确预测的数量的比率;ppv为不将负面事件标记为正的比率;tpr为找到所有正面事件的能力;f1为发现所有正面事件和不错误分类错误事件的能力;hss1对总是预测负面事件的模型的改进;hss2是一个技能得分;tss为测量真实阳性和假阳性率之间
的差异。而tp为真阳性,fn为假阴性,fp为假阳性,tn为真阴性,p为耀斑发生,n为耀斑未发生。
[0027]
本发明与现有技术相比,具有的有益效果是:
[0028]
本发明设计了一种基于低维卷积神经网络的太阳耀斑时间序列分类方法。方法仅根据23和24太阳周期的goesx射线时间序列数据进行训练。通过重点训练两个模型用于太阳耀斑的预测,一个模型预测了x级太阳耀斑事件,另一个模型预测了m级太阳耀斑事件。在事件发生前,x和m模型根据不同的预测时间框架进行了训练,并通过两种不同的数据集分割方法:随机的和按时间顺序的用于提高模型预测的随机性和准确性。
附图说明
[0029]
图1为本发明的流程框图。
具体实施方式
[0030]
下面将结合本发明实施例中的附图,对本发明实施例中的技术发明进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0031]
本技术公开的一种基于低维卷积神经网络的太阳耀斑时间序列分类方法,如图1所示,包括如下步骤,
[0032]
步骤s1中,数据采集:从goes任务中获取1分钟平均x射线(0.1-0.8nm)时间序列数据。其中第一艘goes-1在1975年发射,由美国国家海洋和大气管理局(noaa)的国家气象卫星、数据和信息服务部门操作。而allgoes任务航天器是一颗位于约35800公里高度的地球同步卫星,它提供了完整的地球盘视图和无遮挡的太阳视图。主要的goes任务是利用成像仪设备收集地球表面和大气的红外辐射和可见光太阳反射,以及利用声波设备收集大气温度、湿度剖面、表面和云顶温度以及臭氧分布。此外,goes航天器搭载的空间环境3监测仪(sem)由磁强计、x射线传感器、高能质子和阿尔法粒子探测器以及高能粒子传感器组成。在goes上发现的x射线传感器(xrs)能够记录两个波段:0.05-0.4nm和0.1-0.8nm。同时当达到一定阈值时,长波波段(0.1-0.8nm)的幅值所定义的x射线通量等级:x、m、c等级分别为10-4、10-5、10-6。根据goes x射线通量数据构成原始数据集,其原始数据集中goes-10数据范围为1998年7月至2009年12月,goes-14数据范围为2010年1月至2010年12月,goes-15数据范围为2011年1月至2019年12月,将这三个数据源合并成一个1分钟平均x射线信号的按时间顺序排列的序列,分别涵盖了1998年7月至2009年12月和2010年1月至2019年12月的几乎全部太阳活动周期。
[0033]
步骤s2中包括数据分割:通过x射线信号星发现所有的x和m太阳耀斑事件的相应阈值分别为1
·
10-4和1
·
10-5。为了分别为1、3、6、12、24、48、72、96小时不同预测帧的x和m太阳耀斑类创建两个单独的数据集,同时保留48小时的数据作为模型的输入,用goes-15的最小标称值1e-9替换时间序列中出现的所有缺失值“99999”,然后对每一个发现的太阳耀斑事件高峰(分别为m或x),确认更高级别的事件没有提前12小时出现,也没有在高峰前97小时出现相同或更高级别的事件(高峰前1小时和预测帧96小时),并通过选择随机时间点,
确认在12小时前或97小时前没有出现高于m类阈值的事件,从而选择一个无事件帧,以此消除带有主要标称最小值计数的帧。通过以上方式,事件/无事件帧的长度为144小时:96小时的预测帧和48小时的输入。最后x类集和m类集的事件帧总数分别为171和1522个事件,而无事件帧集计数1057个事件,同时将获取的数据集中选择均匀分布的样本将集合分割为训练集和测试集,即集合中的每个样本被选为训练或测试的概率相等,,将训练集输入模型中用于训练,实现参数调优,将测试集用于模型的性能评估。
[0034]
数据归一化:为了提高模型的整体性能,对数据集中每条数据进行归一化处理
[0035]
步骤s3中,模型构建:利用低维卷积神经网络构建一个分类时间序列模型作为太阳耀斑的预测。该模型由4个卷积层组成,其离散二维卷积公式如下:
[0036]
其中表示第l层在索引i,j处的特征图k,xl-1表示第l-1层并为当前层的输入,是尺寸为(2n 1)
×
(2m 1)的核,s表示步长,p为边界的填充。
[0037]
每层后面有一个relu激活函数,4个最大池化层,一个全连接层和一个带有softmax激活函数的输出层,其公式分别如下:
[0038]
relu(x)=max(0,x),
[0039][0040]
其中表示第i,j层的池化张量k在特征映射上的最大池化操作,s’,n’,m’分别为步长,x是实数的输入向量,k是类别的个数。
[0041]
此外,每个最大池化层后面都有一个dropout层,dropout概率为10%,用于正则化和避免模型过拟合。将训练数据输入分类模型中进行训练,通过四层卷积层输出相应的特征图,利用卷积层中的每个核与输入张量卷积,生成一个特征映射,最终在输出层通过softmax激活函数将输出映射到分类概率空间。
[0042]
步骤s4模型保存:通过使用交叉熵损失函数进行训练,当模型的损失函数不再降低之后,保存模型,交叉熵损失函数公式如下:
[0043]
其中y为真实值,为模型输出预测向量,m为数据类型的总量。
[0044]
步骤s5模型评估:通过不同的评价指标对保存后的模型进行性能评估,了解其相关的性能,其评价指标如下:
[0045]
[0046][0047][0048]
其中acc为正确预测的数量的比率;ppv为不将负面事件标记为正的比率;tpr为找到所有正面事件的能力;f1为发现所有正面事件和不错误分类错误事件的能力;hss1对总是预测负面事件的模型的改进;hss2是一个技能得分;tss为测量真实阳性和假阳性率之间的差异。而tp为真阳性,fn为假阴性,fp为假阳性,tn为真阴性,p为耀斑发生,n为耀斑未发生。
[0049]
上面仅对本发明的较佳实施例作了详细说明,但是本发明并不限于上述实施例,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化,各种变化均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。