1.本发明属于图像分类技术领域,具体涉及一种基于小训练数据集的超声图像分类方法。
背景技术:
2.超声成像是一种应用广泛的医学成像方式,经常用于临床应用和生物医学研究的许多领域。最流行的超声成像模式是b(亮度)模式,它是通过将透射的超声波扫过平面来生成强度图像。然而,在医学图像背景下获取大数据集具有极大的困难,尤其是超声图像。
3.现有技术存在的问题或者缺陷:目前在只有少量数据集的应用中,基于cnn的模型通常采用迁移学习的方法,然而,由于自然图像和超声图像之间存在较大的差异,从计算机视觉域到超声域的迁移学习效果有限,导致图像识别准确率不高,出现极大的误差。
技术实现要素:
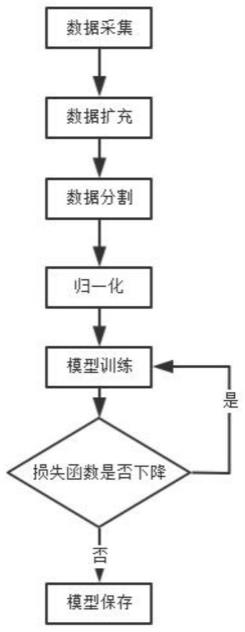
4.本技术通过使用超声成像设备对相关的乳腺癌病人和正常人进行诊断,获取相对应得病灶图像和正常图像,并对获取得到得所有图像进行图像标注。完成数据标注后,对数据进行预处理,预处理包括分割,加噪。将预处理后的数据输入搭建好的acgan网络进行网络模型的训练,待到模型损失函数不再下降,保存模型,完成模型构建。
5.本技术公开的一种基于小训练数据集的超声图像分类方法,包括如下步骤:
6.s1、数据采集:采集超声图像数据,并对其类别进行标注,完成模型训练所需数据集的构建;
7.s2、数据预处理:预处理包括归一化、数据切割,统一数据尺度,并且扩增数据集,保证模型训练效果;
8.s3、识别模型:采用深度学习相关技术搭建分类识别模型,输入训练数据,完成参数模型的搭建;
9.s4、模型保存:当模型的损失函数不再降低之后,保存模型。
10.进一步的,所述步骤s1中,通过使用超声成像设备对相关的乳腺癌病人和正常人进行诊断,获取相对应得病灶图像和正常图像,并对获取得到得所有图像进行图像标注。
11.进一步的,所述步骤s2中,数据扩充的具体方法为:训练图像中通过流行的数据增强技术进行处理,包括翻转、旋转(不同角度)、噪声添加,其中图像的加噪通过高斯公式进行加噪处理,其公式如下:p
out
=p
in
x
means
sigma*g(d),其中pout和pin分别为每个输出和输入像素,xmeans表示平均值,sigma表示平均方差,g(d)是随机数的高斯分布随机值。
12.进一步的,所述步骤s2中,数据分割具体方法为:出于验证的目的,通过使用5倍交叉验证,将250张图像的数据集分割为5个分割数据集,每个分割数据集中包含50张图像。
13.进一步的,所述步骤s3中,构建基于acgan的超声图像分类识别模型,该模型由生成器g和判别器d组成,训练数据集中的图像为x={xi,i=1,...,i},其图像标签为y={yi(yi∈{1,...,c}),其中c表示类别数,将训练数据输入分类识别模型中,首先通过生成器g
对数据集中的图像x进行图像的合成,生成器生成合成图像并对获取的合成图像进行类别标注其中生成器是使用一个由一系列置换的卷积层组成的多层深度网络来实现c的,判别器d的任务是将合成的图像从x中的图像中分离出来,同时它被设计用来预测正确的类yi,之后利用多任务学习过程实现了识别器的训练过程。
14.进一步的,所述步骤s3中,还包括对卷积层进行正则化,使用了批处理规范化层和激活函数relu层,最后反馈给两个独立的全连接(fc)层,对应于类的预测和源的预测,生成器g和判别器d通过对抗的方式进行训练,g不断优化其权值,以有效地再现目标数据的分布,d不断优化自身,以识别图像的类(yi),此外,该d通过对其权重进行优化,以有效区分图像是真实的还是合成的,生成器g通过与判别器d通过交互更新其权值,学习与训练图像相关的有用的语义特征,提高模型的整体分类效果,并最终实现模型的参数调优。
15.本发明提出了一种基于小训练数据集的超声图像分类方法。通过同时使用一个生成器进行数据增强和使用一个鉴别器训练分类器,结合数据增强和迁移学习的优点,可以用于处理非常有限的训练数据,提高图像的分类效果。
附图说明
16.图1本发明的系统模块框图。
具体实施方式
17.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
18.如图1所示本技术公开的一种基于小训练数据集的超声图像分类方法,包括如下步骤:
19.s1、数据采集:采集超声图像数据,并对其类别进行标注,完成模型训练所需数据集的构建;数据采集:通过使用超声成像设备对相关的乳腺癌病人和正常人进行诊断,获取相对应得病灶图像和正常图像,并对获取得到得所有图像进行图像标注。该数据集由250张超声图像组成,分别来自两类-良性和恶性。150张为恶性,其余为良性,同时这两个类别在视觉上没有明显的区别,使得分类具有挑战性,使得该分类任务具有极大得可信度和公证度。
20.s2、数据预处理:预处理包括归一化、数据切割,统一数据尺度,并且扩增数据集,保证模型训练效果;数据扩充:训练图像中通过流行的数据增强技术进行处理,包括翻转、旋转(不同角度)、噪声添加。其中图像的加噪通过高斯公式进行加噪处理,其公式如下:p
out
=p
in
x
means
sigma*g(d),其中pout和pin分别为每个输出和输入像素,xmeans表示平均值,sigma表示平均方差,g(d)是随机数的高斯分布随机值。
21.在加载用于训练的数据时,对数据进行动态的概率转换。该转换方法不是对所有的训练数据进行变换,而是对每个时间节点的部分图像进行变换。不同的影像在不同的时间节点被转化。虽然这样做的目的是为了增强数据,但这也给训练机制增加了随机性。但由
于数据增强是在加载训练数据时进行动态转换,不能有效地增加训练图像的数量,因此在测试期间不应用数据增强。
22.数据分割:出于验证的目的,通过使用5倍交叉验证,将250张图像的数据集分割为5个分割数据集,每个分割数据集中包含50张图像。对于每一个评估,在训练过程中使用由200张图像组成的4个分组。为了测试,将使用剩下的50个图像用于模型测试。以这种方式,执行5个独立的评估和准确性的平均值超过平均水准。200张训练图像远低于计算机视觉任务中一般使用的训练图像数量,因此,本数据集适合于测试本文方法在超声图像分析中处理训练不足图像的能力,体现该模型在小数据样本中的分类性能和能力。
23.数据归一化:对每条数据进行min-max归一化。
24.s3、识别模型:采用深度学习相关技术搭建分类识别模型,输入训练数据,完成参数模型的搭建;模型构建:构建基于acgan的超声图像分类识别模型,该模型由生成器g和判别器d组成。训练数据集中的图像为x={xi,i=1,...,i},其图像标签为y={yi(yi∈{1,...,c}),其中c表示类别数。将训练数据输入分类识别模型中,首先通过生成器g对数据集中的图像x进行图像的合成,生成器生成合成图像并对获取的合成图像进行类别标注其中生成器是使用一个由一系列置换的卷积层组成的多层深度网络来实现c的。判别器d的任务是将合成的图像从x中的图像中分离出来,同时它被设计用来预测正确的类yi,之后利用多任务学习过程实现了识别器的训练过程。该学习机制帮助判别器学习有用的特征来区分不同的类,实现隐式的辅助数据增强。鉴别器网络由一组卷积层组成。为了进一步对卷积层进行正则化,使用了批处理规范化层和激活函数relu层,最后反馈给两个独立的全连接(fc)层,对应于类的预测和源的预测。生成器g和判别器d通过对抗的方式进行训练。g不断优化其权值,以有效地再现目标数据的分布,d不断优化自身,以识别图像的类(yi)。此外,该d通过对其权重进行优化,以有效区分图像是真实的还是合成的。生成器g通过与判别器d通过交互更新其权值,学习与训练图像相关的有用的语义特征,提高模型的整体分类效果,并最终实现模型的参数调优。
25.s4、模型保存:当模型的损失函数不再降低之后,保存模型。
26.上面仅对本发明的较佳实施例作了详细说明,但是本发明并不限于上述实施例,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化,各种变化均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。