1.本技术涉及数据处理技术领域,特别是涉及一种可自适应动态伸缩的时空多属性索引方法及其检索方法。
背景技术:
2.时空多属性索引是指可以同时索引时间信息、空间信息和其他多种属性信息的索引,即最后建立的索引只有1套,而不是针对每个维度单独建立1套索引。含有时间、空间和多属性的数据被时空多属性索引结构进行索引后,用户可以只针对这1套索引进行时间、空间和其他属性的同时检索。相比而言,传统概念的索引构建方式是针对时间、空间和众多属性一一建立索引,用户在检索时系统需要将查询条件投递到各个索引去检索,最后再进行汇总过滤。可见时空多属性索引无疑从节约存储空间和检索效率上来说都是较优的技术。
3.然而,目前的时空检索方法,由于时空多属性索引结构要涵盖的数据项较多(时间、空间以及其他众多索引),因此一般时空多属性索引比单一维度的索引所占用的存储空间要大。上述所涉及的技术未考虑在资源有限(如存储受限)的环境下如何能够自适应调节时空多属性索引的存储开销。另外,索引的构建效率是衡量索引的性能指标之一,为了追求更高的查询效率,索引在划分搜索空间时往往会划分得很细,这可以在利用索引检索时进行大量剪枝从而加快查找效率,但这在构建索引时会需要大量的时间,如何平衡构建效率和查询效率是时空多属性索引需要考虑的问题之一。上述技术均未考虑该问题,不能够使索引的构建效率动态自适应伸缩。
技术实现要素:
4.基于此,有必要针对上述技术问题,提供一种可自适应动态伸缩的时空多属性索引方法及其检索方法。
5.一种可自适应动态伸缩的时空多属性索引方法,所述方法包括:
6.构建待索引文档集;所述待索引文档集中每篇文档包括:时间信息、空间信息以及词列表;
7.构建所述待索引文档集的树状数据结构;所述树状数据结构包括:根节点和叶子节点;所述根节点向下展开包括多级时间多属性节点,所述时间多属性节点向下展开包括多级空间多属性节点,所述根节点通过根节点链表进行表示,所述时间多属性节点通过时间多属性节点链表进行表示,所述空间多属性节点通过空间多属性节点链表进行表示,所述根节点链表中包括:时间级别信息、时间值、位图索引、指向下一个链表元素的指针以及指向下一级节点的指针,所述多属性节点链表包括:时间级别、时间值、位图索引以及指向下一级节点的指针,所述空间多属性节点链表包括:r树的最小限定矩形、位图索引以及指向下一级节点的指针所述叶子节点通过元素结构进行表示,所述元素结构包括:空间信息、时间信息、词列表以及url地址;
8.将所述待索引文档集中的每一篇文档存储至所述树状数据结构。
9.在其中一个实施例中,还包括:提取所述待索引文档集中的每一篇文档的时间信息、空间信息以及词列表;
10.将所述词列表利用位图索引进行映射,得到位图元素;
11.根据所述时间信息,查询所述根节点链表,使得所述时间信息包含在所述根节点链表的时间值中,得到时间值元素;
12.当包含时间多属性节点链表时,查询所述时间多属性节点链表,使得时间信息包含在所述时间多属性节点链表的时间信息中,直至没有下一级时间多属性节点链表;
13.根据所述待索引文档集中的每一篇文档的空间信息,利用r树插入算法,将每一篇文档插入至所述时间多属性节点链表的下一级空间多属性节点链表中,直至插入所述叶子节点。
14.在其中一个实施例中,还包括:根据时间信息d.t,查询所述根节点链表,确定时间值value包含d.t的元素rln,构建命中关系为:
15.rln.bmi=rln.bmi|blw
16.其中,bmi为位图索引,blw为位图元素;
17.若未查询到元素rln,则创建一个根节点链表元素rln,并插入到根节点中,并使得rln.bmi=rln.bmi|blw。
18.在其中一个实施例中,还包括:当包含时间多属性节点链表时,查询根节点链表元素rln的下一级时间多属性节点中value包含d.t的元素rln1,构建命中关系为:
19.rln1.bmi=rln1.bmi|blw
20.若未查询到rln1,则创建一个时间多属性节点,并将该时间多属性节点插入到父节点并关联元素rln1,rln1.bmi=rln1.bmi|blw,直至元素rln1没有下一级时间多属性节点链表。
21.在其中一个实施例中,还包括从设置的初始比例m%开始,以步长δ为l%,按照(m% δ)的规模比例构建所述待索引文档集ds不同大小的子集;其中,待索引文档集的子集为ds_sub,ds_sub中每个元素为一个文档集;
22.对ds_sub中的每个文档集ds_subi中的每一篇文档的空间信息s,时间信息t进行抽取,并利用分词组件将文档中的词全部提取形成词列表lw;
23.针对每个ds_sub中的每个文档集ds_subi,变换不同的时间层级数构建所述树状数据结构的索引,其中,对ds_subi,将时间多属性节点的层级从1增长到m级,构建m种不同的树状数据结构的索引;
24.当|ds_sub|=n时,得到n
×
m个树状数据结构的索引,将n
×
m个树状数据结构的索引的存储量stor进行记录;
25.对每个ds_subi中的全部空间信息s,时间信息t和lw构建向量vsubi;
26.将ds_subi利用时间层级为j层级的索引构建算法所得存储量设置为stor
i,j
;
27.建立映射《v_subi,stor
i,j
》
→
j;
28.利用自回归模型对所有的映射进行训练,得到时空多属性索引存储机制的机器学习模型stor_m。
29.在其中一个实施例中,还包括:读取扫描所给定的存储空间stor;
30.针对待索引文档集ds,对其中的每一篇文档d,提取空间信息s,时间信息t,并利用
分词组件将文档中的词全部提取形成词列表lw;
31.根据全部的空间信息s,时间信息t和lw构建向量v;
32.根据机器学习模型stor_m,计算《u,stor》
→
j;
33.将j作为时间多属性节点的层级参数执行时空多属性索引构建步骤。
34.一种可自适应动态伸缩的时空多属性检索方法,所述方法包括:
35.获取检索条件;所述检索条件中包括:空间查询范围、时间查询范围以及查询关键词列表;
36.将所述查询关键词列表映射为bqw;
37.将所述时间查询条件与权利要求1至6中任一项所述的可自适应动态伸缩的时空多属性索引方法中的树状数据结构的根节点链表的各个元素的时间值value做交运算,得到元素集合为r_set;
38.将bqw与r_set中每个元素的位图索引bmi做交运算,得到元素集合为r_set
′
;
39.针对r_set
′
中每个元素,利用所述时间查询范围与元素子节点元素中value相交且bqw与bmi相交,直到递归到空间多属性节点;
40.针对空间多属性节点的每个元素,利用空间查询条件与元素中最小限定矩阵mbr相交且bqw与bmi相交,直到递归到叶节点;
41.当所述叶节点中的空间信息、时间信息、词列表满足所述检索条件时,输出检索结果。
42.在其中一个实施例中,还包括:给定待索引文档集ds;
43.从n%开始,以步长δ为l%,按照(n% δ)的规模比例构建待索引文档集ds不同大小的子集;其中,待索引文档集的子集为ds_sub,ds_sub中每个元素为一个文档集;
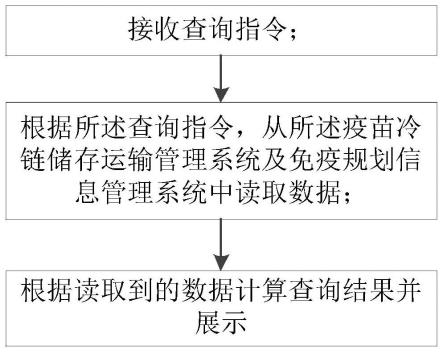
44.对ds_sub中的每个文档集ds_subi中的每一篇文档的空间信息s,时间信息t进行抽取,并利用分词组件将文档中的词提取形成词列表lw;
45.针对每个ds_sub中的每个文档集ds_subi,变换不同的时间层级数构建树状数据结构的索引;其中,对ds_subi,将多级时间多属性节点的时间层级从1增长到m级,构建m种不同的树状数据结构的索引;
46.记录每种树状数据结构的索引的构建时间,得到构建时间集合为记录每种树状数据结构的索引的构建时间,得到构建时间集合为其中,表示针对文档集ds_subi的第j种树状数据结构的索引的构建时间;
47.针对文档集ds_subi的每种树状数据结构的索引,采用随机生成空间范围、时间范围以及随机挑选若干查询关键字组成查询条件,进行检索,计算平均检索响应时间,形成检索时间集合表示针对文档集ds_subi的第j种树状数据结构的索引的统计平均检索时间;
48.计算的算术平均数的算术平均数
49.计算得到能够使最小的那个树状数据结构的索引的时间层级数pi;
50.对每个ds_subi中的全部空间信息s,时间信息t和lw构建向量v_subi;
51.建立映射v_subi→
pi;
52.利用自回归模型对所有的映射进行训练,得到时空多属性索引构建与检索效率平衡机制的机器学习模型brbal_m。
53.在其中一个实施例中,还包括:针对给定的待索引文档集ds,对其中的每一篇文档d,从中提取空间信息s,时间信息t,并利用分词组件将文档中的词全部提取形成词列表lw;
54.根据所述空间信息s,时间信息t和lw构建向量v;
55.根据机器学习模型brbal_m,计算v
→
p;
56.将p作为时间多属性节点的层级参数执行时空多属性索引的构建过程。
57.上述可自适应动态伸缩的时空多属性索引方法及其检索方法,提出时空多属性索引的树状数据结构,在该结构中,树状数据结构包括:根节点和叶子节点根节点向下展开包括多级时间多属性节点,时间多属性节点向下展开包括多级空间多属性节点,根节点通过根节点链表进行表示,时间多属性节点通过时间多属性节点链表进行表示,空间多属性节点通过空间多属性节点链表进行表示,根节点链表中包括:时间级别信息、时间值、位图索引、指向下一个链表元素的指针以及指向下一级节点的指针,多属性节点链表包括:时间级别、时间值、位图索引以及指向下一级节点的指针,空间多属性节点链表包括:r树的最小限定矩形、位图索引以及指向下一级节点的指针;叶子节点通过元素结构进行表示,所述元素结构包括:空间信息、时间信息、词列表以及url地址。该结构主要分为时间多属性结构和空间多属性结构,不管时间结构还是空间结构都考虑了带有关键词过滤的功能,这在检索时都可以利用关键词进行快速剪枝。除此以外,还利用了时间本身的分层特性(如年-月-日)设计了多层级的时间多属性索引结构,这为后续的索引自适应调节提供了机制,另外,该构建过程中位图索引将会加快构建效率,位图索引的并操作都是位操作,速度较快,再结合插入过程中树状的查找机制,这都加快了索引的一般构建过程。
附图说明
58.图1为一个实施例中可自适应动态伸缩的时空多属性索引方法的流程示意图;
59.图2为一个实施例中树状数据结构的示意图;
60.图3为另一个实施例中可自适应动态伸缩的时空多属性检索方法的流程示意图。
具体实施方式
61.为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
62.在一个实施例中,如图1所示,提供了一种可自适应动态伸缩的时空多属性索引方法,包括以下步骤:
63.步骤102,构建待索引文档集。
64.待索引文档集中每篇文档包括:时间信息、空间信息以及词列表。
65.步骤104,构建待索引文档集的树状数据结构。
66.树状数据结构包括:根节点和叶子节点;根节点向下展开包括多级时间多属性节点,时间多属性节点向下展开包括多级空间多属性节点,根节点通过根节点链表进行表示,
时间多属性节点通过时间多属性节点链表进行表示,空间多属性节点通过空间多属性节点链表进行表示,根节点链表中包括:时间级别信息、时间值、位图索引、指向下一个链表元素的指针以及指向下一级节点的指针,多属性节点链表包括:时间级别、时间值、位图索引以及指向下一级节点的指针,空间多属性节点链表包括:r树的最小限定矩形、位图索引以及指向下一级节点的指针;叶子节点通过元素结构进行表示,元素结构包括:空间信息、时间信息、词列表以及url地址。
67.步骤106,将待索引文档集中的每一篇文档存储至树状数据结构。
68.建立好的树状数据结构如图2所示。
69.上述可自适应动态伸缩的时空多属性索引方法中,提出时空多属性索引的树状数据结构,在该结构中,树状数据结构包括:根节点和叶子节点;根节点向下展开包括多级时间多属性节点,时间多属性节点向下展开包括多级空间多属性节点,根节点通过根节点链表进行表示,时间多属性节点通过时间多属性节点链表进行表示,空间多属性节点通过空间多属性节点链表进行表示,根节点链表中包括:时间级别信息、时间值、位图索引、指向下一个链表元素的指针以及指向下一级节点的指针,多属性节点链表包括:时间级别、时间值、位图索引以及指向下一级节点的指针,空间多属性节点链表包括:r树的最小限定矩形、位图索引以及指向下一级节点的指针;叶子节点通过元素结构进行表示,所述元素结构包括:空间信息、时间信息、词列表以及url地址。该结构主要分为时间多属性结构和空间多属性结构,不管时间结构还是空间结构都考虑了带有关键词过滤的功能,这在检索时都可以利用关键词进行快速剪枝。除此以外,还利用了时间本身的分层特性(如年-月-日)设计了多层级的时间多属性索引结构,这为后续的索引自适应调节提供了机制,另外,该构建过程中位图索引将会加快构建效率,位图索引的并操作都是位操作,速度较快,再结合插入过程中树状的查找机制,这都加快了索引的一般构建过程。
70.在其中一个实施例中,提取待索引文档集中的每一篇文档的时间信息、空间信息以及词列表;将所述词列表利用位图索引进行映射,得到位图元素;根据时间信息,查询根节点链表,使得时间信息包含在根节点链表的时间值中,得到时间值元素;当包含时间多属性节点链表时,查询时间多属性节点链表,使得时间信息包含在时间多属性节点链表的时间信息中,直至没有下一级时间多属性节点链表;根据待索引文档集中的每一篇文档的空间信息,利用r树插入算法,将每一篇文档插入至时间多属性节点链表的下一级空间多属性节点链表中,直至插入叶子节点。
71.在其中一个实施例中,根据时间信息d.t,查询根节点链表,确定时间值value包含d.t的元素rln,构建命中关系为:
72.rln.bmi=rln.bmi|blw
73.其中,bmi为位图索引,blw为位图元素;
74.若未查询到元素rln,则创建一个根节点链表元素rln,并插入到根节点中,并使得rln.bmi=rln.bmi|blw。
75.在其中一个实施例中,当包含时间多属性节点链表时,查询根节点链表元素rln的下一级时间多属性节点中value包含d.t的元素rln1,构建命中关系为:
76.rln1.bmi=rln1.bmi|blw
77.若未查询到rln1,则创建一个时间多属性节点,并将该时间多属性节点插入到父
节点并关联元素rln1,rln1.bmi=rln1.bmi|blw,直至元素rln1没有下一级时间多属性节点链表。
78.在其中一个实施例中,解决在多大的待索引数据量和多大的限定存储空间下,采用多少层级的时间索引结构是最优的。提取了时间、空间、关键词和存储空间作为映射的特征进行训练,这既体现了优化的关键特性也减少了训练数据量。
79.具体的,从设置的初始比例m%开始,以步长δ为l%,按照(m% δ)的规模比例构建所述待索引文档集ds不同大小的子集:其中,待索引文档集的子集为ds_sub,ds_sub中每个元素为一个文档集;m可以取10。
80.对ds_sub中的每个文档集ds_subi中的每一篇文档的空间信息s,时间信息t进行抽取,并利用分词组件将文档中的词全部提取形成词列表lw;
81.针对每个ds_sub中的每个文档集ds_subi,变换不同的时间层级数构建所述树状数据结构的索引,其中,对ds_subi,将时间多属性节点的层级从1增长到m级,构建m种不同的树状数据结构的索引;
82.当|ds_sub|=n时,得到n
×
m个树状数据结构的索引,将n
×
m个树状数据结构的索引的存储量stor进行记录;
83.对每个ds_subi中的全部空间信息s,时间信息t和lw构建向量v_subi;
84.将ds_subi利用时间层级为j层级的索引构建算法所得存储量设置为stor
i,j
;
85.建立映射《v_subi,stor
i,j
》
→
j;
86.利用自回归模型对所有的映射进行训练,得到时空多属性索引存储机制的机器学习模型stor_m。
87.在其中一个实施例中,读取扫描所给定的存储空间stor;
88.针对待索引文档集ds,对其中的每一篇文档d,提取空间信息s,时间信息t,并利用分词组件将文档中的词全部提取形成词列表lw;
89.根据全部的空间信息s,时间信息t和lw构建向量v;
90.根据机器学习模型stor_m,计算《v,stor》
→
j;
91.将j作为时间多属性节点的层级参数执行时空多属性索引构建步骤。
92.上述方法中,利用训练好的存储优化模型,可以随着给索引预设的存储空间大小而构建不同时间层级的索引,这在实际中会使得索引具有智能的伸缩性,特别适合云上透明化调节应用。
93.在其中一个实施例中,如图3所示,提供一种可自适应动态伸缩的时空多属性检索方法,包括:
94.步骤302,获取检索条件。
95.检索条件中包括:空间查询范围、时间查询范围以及查询关键词列表。
96.步骤304,将所述查询关键词列表映射为bqw。
97.步骤306,将时间查询条件与上述可自适应动态伸缩的时空多属性索引方法中的树状数据结构的根节点链表的各个元素的时间值value做交运算,得到元素集合为r_set。
98.步骤308,将bqw与r_set中每个元素的位图索引bmi做交运算,得到元素集合为r_set
′
。
99.步骤310,针对r_set
′
中每个元素,利用时间查询范围与元素子节点元素中value
相交且bqw与bmi相交,直到递归到空间多属性节点。
100.步骤312,针对空间多属性节点的每个元素,利用空间查询条件与元素中最小限定矩阵mbr相交且bqw与bmi相交,直到递归到叶节点。
101.步骤314,当叶节点中的空间信息、时间信息、词列表满足检索条件时,输出检索结果。
102.上述可自适应动态伸缩的时空多属性检索方法中,充分利用时间多属性结构、空间多属性结构对时间-关键词和空间-关键词的快速过滤实现高效的检索。
103.在其中一个实施例中,提供一种检索效率平衡优化的机器学习训练过程,具体如下:
104.1、给定待索引文档集ds;
105.2、从n%开始,以步长δ为l%,按照(n% δ)的规模比例构建待索引文档集ds不同大小的子集;其中,待索引文档集的子集为ds_sub,ds_sub中每个元素为一个文档集;
106.3、对ds_sub中的每个文档集ds_subi中的每一篇文档的空间信息s,时间信息t进行抽取,并利用分词组件将文档中的词提取形成词列表lw;
107.4、针对每个ds_sub中的每个文档集ds_subi,变换不同的时间层级数构建树状数据结构的索引;其中,对ds_subi,将多级时间多属性节点的时间层级从1增长到m级,构建m种不同的树状数据结构的索引;
108.5、记录每种树状数据结构的索引的构建时间,得到构建时间集合为5、记录每种树状数据结构的索引的构建时间,得到构建时间集合为其中,表示针对文档集ds_subi的第j种树状数据结构的索引的构建时间;
109.6、针对文档集ds_subi的每种树状数据结构的索引,采用随机生成空间范围、时间范围以及随机挑选若干查询关键字组成查询条件,进行检索,计算平均检索响应时间,形成检索时间集合表示针对文档集ds_subi的第j种树状数据结构的索引的统计平均检索时间;
110.7、计算的算术平均数的算术平均数
111.8、计算得到能够使最小的那个树状数据结构的索引的时间层级数pi;
112.9、对每个ds_subi中的全部空间信息s,时间信息t和lw构建向量v_subi;
113.10、建立映射v_subi→
pi;
114.11、利用自回归模型对所有的映射进行训练,得到时空多属性索引构建与检索效率平衡机制的机器学习模型brbal_m。
115.本实施例中,针对索引构建的层级多,查询效率会提高,但构建效率会降低反之索引构建的层级少,构建效率高,但查询效率低,因此要找到平衡点。本发明点主要解决在多大的待索引数据量下,采用多少层级的时间结构才能使得查询效率和构建效率平衡。
116.在其中一个实施例中,针对给定的待索引文档集ds,对其中的每一篇文档d,从中提取空间信息s,时间信息t,并利用分词组件将文档中的词全部提取形成词列表lw;
117.根据所述空间信息s,时间信息t和lw构建向量v;
118.根据机器学习模型brbal_m,计算v
→
p;
119.将p作为时间多属性节点的层级参数执行时空多属性索引的构建过程。
120.本实施例中,可以在构建索引时,针对不同的待索引数据量自动调节时间结构的层级数量,从而实现构建和查询的效率平衡。
121.本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本技术所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram以多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双数据率sdram(ddrsdram)、增强型sdram(esdram)、同步链路(synchlink)dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
122.以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
123.以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。