一种融合vit与卷积神经网络的毛笔字体类型快速识别方法
技术领域
1.本发明涉及人工智能技术领域,具体涉及一种融合视觉(vision transformer,vit)与卷积神经网络(convolutional neural networks,cnn)的毛笔字体类型快速识别方法。
背景技术:
2.毛笔书法是我国汉字的一种传统艺术表现形式。在书法界公认的有五体,分别是篆书、隶书、楷书、草书和行书。每种字体都有其独特的书写风格。篆书是象形表意的字体,特点是画笔灵动、栩栩如生。隶书点画分明,横长竖断,讲究“蚕头雁尾”、“一波三折”。楷书形体方正,笔画平直,讲究“丰腴雄浑”,“结体遒劲”。草书与楷书规矩的笔法不同,它有着“飘若浮云”、“矫若惊龙”的特点。而行书既有楷书的规整,又有草书的放纵流动,是结合了艺术与实用的一种字体。这五类字体的风格各有不同,但又存在相似之处。
3.目前,书法字体的识别主要依靠专业人员的经验判断,但仅凭人工的方法不仅需要投入大量的时间和精力,而且不同人员之间差异化严重。字体图像中包含着很多字形信息,肉眼识别很难抓住这些微小的特征。初学者由于不了解字体间的区别,常常出现书写不规范的问题。普通深度学习方法虽然能获取到字体图像的更多特征信息,但却忽略了字体偏旁与笔画顺序的细微特征,这些信息对于毛笔字体类型的判断具有重要影响。
技术实现要素:
4.本发明的目的在于,提出一种基于细粒度形态信息的毛笔字体类型快速识别方法,其将毛笔字体的分类问题转化为人工智能领域的图像分类问题,进而得到字形中丰富的特征信息。
5.为实现上述目的,本技术提出的一种融合vit与卷积神经网络的毛笔字体类型快速识别方法,包括:
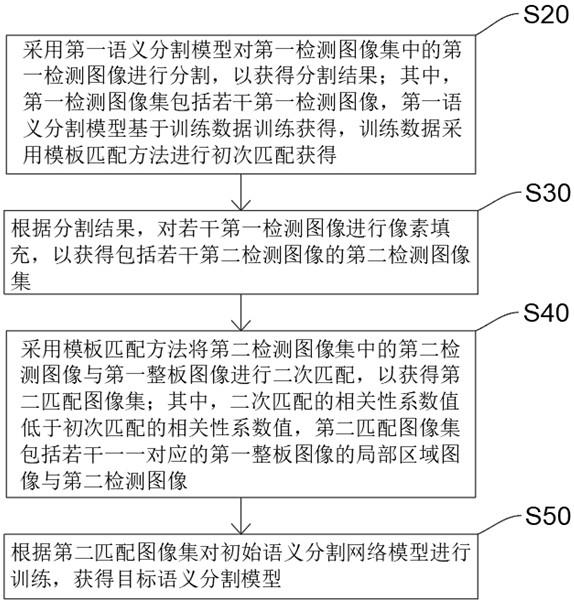
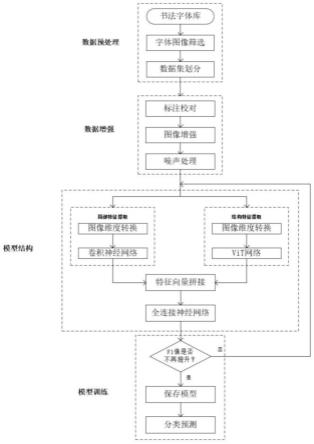
6.步骤1:对从书法字体库获得的多种类别毛笔字体图像数据进行预处理,然后分类存储;
7.步骤2:对分类存储的毛笔字体图像数据的亮度、对比度饱和度进行调整,并随机添加噪声,实现数据集的增强和扩充;
8.步骤3:将所述数据集中的毛笔字体图像调整成相同分辨率格式,并按一定比例分为训练集和验证集;
9.步骤4:调整后的毛笔字体图像以及标注数据送入cnn中,提取出字体的局部特征信息;
10.步骤5:调整后的毛笔字体图像以及标注数据送入vit中,提取出字体的结构特征信息;
11.步骤6:将所述字体的局部特征信息和结构特征信息进行结合,送入分类模型中进行训练,并保存效果最佳的分类模型;
12.步骤7:加载所述分类模型,将待检验的毛笔字体图像传入模型中判断该字体的类别。
13.进一步地,步骤1中对从书法字体库获得的多种类别毛笔字体图像数据进行预处理,然后分类存储,具体包括:
14.步骤1.1:对来自书法字体库中的毛笔字体图像数据进行筛选,删除图像质量低的数据;
15.步骤1.2:将不同类别毛笔字体图像数据收集整理,分别存储在篆书、隶书、楷书、草书和行书对应的文件夹下;
16.进一步地,步骤2中对分类存储的毛笔字体图像数据的亮度、对比度饱和度进行调整,并随机添加噪声,实现数据集的增强和扩充,具体包括:
17.步骤2.1:采用人工方式对分类存储的毛笔字体图像数据进行清洗操作,对照数据集中的标注实例,标注错误的图像;
18.步骤2.2:对于数据集中的毛笔字体图像,按照50%的概率进行翻转,在图像翻转过程中,分别按照50%的概率进行水平翻转和垂直翻转;对于每一张毛笔字体图像,按照100%的概率进行亮度、对比度和饱和度的调整,在调整过程中,分别按照33.3%的概率进行亮度与对比度和饱的随机变换;
19.步骤2.3:在数据集中按照30%的概率添加噪声,在添加过程中,分别按照33.3%的概率添加高斯噪声、胡椒噪声和盐噪声;然后保留处理后的毛笔字体图像和原始毛笔字体图像,实现了数据集的增强和扩充。
20.进一步地,步骤3中将所述数据集中的毛笔字体图像调整成相同分辨率格式,并按一定比例分为训练集和验证集,具体包括:
21.步骤3.1:调用python库的torchvision函数库,转换毛笔字体图像的分辨率,并将其统一为64
×
64;
22.步骤3.2:随机选取部分毛笔字体图像数据,按照8:2的比例,构造训练集与验证集;
23.步骤3.3:将统一分辨率后的毛笔字体图像数据转换为tensor形式。
24.进一步地,步骤4中调整后的毛笔字体图像以及标注数据送入cnn中,提取出字体的局部特征信息,具体包括:
25.步骤4.1:将步骤3得到的毛笔字体图像tensor进行卷积操作;考虑到不同类型的字体之间外形差异较为细微,所以使用不同大小卷积核的卷积神经网络强化模型提取特征的能力;
26.步骤4.2:采用批归一化(batchnorm)方式对输入层和隐藏层标准化,利用视觉激活函数(frelu)加速收敛,传入最大池化层(maxpool)进行池化操作,得到字体的局部特征信息。
27.更进一步地,步骤5中调整后的毛笔字体图像以及标注数据送入vit中,提取出字体的结构特征信息,具体包括:
28.步骤5.1:将步骤3得到的毛笔字体图像tensor进行分块,展平成序列,输入vit模型的编码器encoder部分,其采用了堆叠的6个encoder模块结构;
29.步骤5.2:通过拆分毛笔字体图像,重新进行位置编码,使用可学习的一维位置嵌
入作为位置编码的输入;
30.步骤5.3:将位置编码后的输出划分为8个注意力模块,得到每个注意力模块的值,并进行拼接;
31.所述注意力模块使用式(1)进行拼接:
32.multiheadattention(q,k,v)=concat(head1,...,head8)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
33.headi=attention(qw
iq
,kw
ik
,vw
iv
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
34.其中,headi表示注意力模块;
35.所述注意力模块的值获取公式如下:
[0036][0037]
其中dk表示输入维度,q、k、v分别表示query,key和value矩阵,t表示矩阵的转置,如果q*k
t
的值过大,softmax的偏导数将趋近于0,为了解决这种影响,所以乘以缩放因子
[0038]
步骤5.4:将多个注意力模块的输出与位置编码的输出做残差连接,这个结构的设计解决了全连接层过深导致的神经网络退化问题;
[0039]
步骤5.5:做残差连接后的毛笔字体图像送入前馈神经网络,最后进行层归一化得到字体的结构特征信息。
[0040]
更进一步地,所述残差连接和层归一体化具体公式如下:
[0041]
y=layernorm(x multiheadattention(x))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0042]
其中,x为位置编码后的特征向量,y为残差连接和层归一化后的输出。
[0043]
更进一步地,所述前馈神经网络公式如下:
[0044]
feedforward(x)=max(0,xw1 b1)w2 b2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0045]
其中wi表示全连接层的权重,bi表示全连接层的偏置。
[0046]
作为更进一步地,步骤6中将所述字体的局部特征信息和结构特征信息进行结合,送入分类模型中进行训练,并保存效果最佳的分类模型,具体包括:
[0047]
步骤6.1:将cnn输出的向量展平后与vit输出的向量连接,其连接两种特征向量公式如下:
[0048]
featureunion(x
cnn
,x
vit
)=concat(flatten(x
cnn
),x
vit
)
ꢀꢀꢀꢀꢀꢀ
(6)
[0049]
步骤6.2:将连接后的总体特征向量传入全连接神经网络中,进行分类模型的训练;为了得到最好的模型效果,采用了焦点损失函数(focal loss)对模型进行优化,并保存效果最佳的分类模型。
[0050]
作为更进一步地,步骤7中加载所述分类模型,将待检验的毛笔字体图像传入模型中判断该字体的类别,具体包括:
[0051]
加载步骤6.2中保存的分类模型,将待分类的毛笔字体图像输入模型中,判断字体的特征信息,并输出预测的字体类别。
[0052]
本发明采用的以上技术方案,与现有技术相比,具有的优点是:本发明首先利用移动便携设备拍摄书法字体的图像,然后将图像作为输入,使用保存的模型进行字体识别,预测出图像对应字体。其有效矫正书法不规范的问题,并且取得了良好的识别精度,极大的提
高了书法字体识别的速度和便捷性,为智能设备的开发应用提供了技术保障。
附图说明
[0053]
图1为一种融合vit与卷积神经网络的毛笔字体类型快速识别方法流程图;
[0054]
图2为毛笔字体分类的模型结构图;
[0055]
图3为毛笔字体分类展示图。
[0056]
具体实施方法
[0057]
为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本技术,并不用于限定本技术,即所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。
实施例
[0058]
基于不同字体的落笔规律和书法辅导工具目前的缺点,提供一种融合vit与卷积神经网络的毛笔字体类型快速识别方法,本实施例以pycharm为开发平台,python为开发语言和pytorch为深度学习框架,采用本发明上述方法,如图1所示,进行字体的识别和分类,以下为具体过程:
[0059]
步骤1:使用手机、相机等移动便携设备进行书法字体图像的拍摄;
[0060]
步骤2:以步骤1获取的图像作为输入,如图2所示,加载本方法中的分类模型,预测得到图像中字体的分类结果。本发明使用的评价指标包含准确率(acc)、f1值(f1 score);
[0061]
具体公式如下:
[0062][0063][0064][0065][0066]
其中,tp:真正例,将正类正确预测为正类数;fp:假正例,将负类错误预测为正类数;fn:假负例,将正类错误预测为负类数;tn:真负例,将负类正确预测为负类数。
[0067]
步骤3:采用了识别速度fps(frame per second,即每秒内可以处理的图片数量)作为模型识别速度的评价指标,其公式定义如下:
[0068][0069]
其中,framenum表示需要推理的图片总数,elapsedtime表示推理过程的总耗时(秒)。
[0070]
步骤4:将生成的图像进行结构输出展示,如图3所示,并保存到本地文件。
[0071]
前述对本发明的具体示例性实施方案的描述是为了说明和例证的目的。这些描述并非想将本发明限定为所公开的精确形式,并且很显然,根据上述教导,可以进行很多改变
和变化。对示例性实施例进行选择和描述的目的在于解释本发明的特定原理及其实际应用,从而使得本领域的技术人员能够实现并利用本发明的各种不同的示例性实施方案以及各种不同的选择和改变。本发明的范围意在由权利要求书及其等同形式所限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。