1.本发明属于文档的顺序检测方法,尤其涉及一种古籍文档顺序检测方法。
背景技术:
2.文档的阅读顺序检测,作为理解视觉富文档内容的基础任务,即指得到能够让读者直接理解的排序片段输出。现有的大多数阅读顺序检测都是通过启发式的方法得到结果,即指从检测出的字符结果按照从上到下,从左到右的阅读顺序输出最终的内容。然而,对于无约束排布的文档内容,特别是古籍文档等多版面以及竖排的布局结构,这种启发式的方法得到的结果大多是错误的。错误的阅读顺序输出对于其它的文档理解任务,诸如信息抽取等,会带来错误的输出结果。因此,一种鲁棒且通用的文档顺序检测方案对于文档理解任务是不可或缺的。
3.近年来,相关学者提出用于解决文档顺序检测的方案,由于文档的顺序标注数据集需要很多的人力标注,这些方法都仅使用较少的数据集训练,也有相关学者提出一些启发式的规则来解决该问题。最新的,有学者提出基于深度学习的方法来解决电商场景下的顺序检测问题,然而该方法使用的数据集中文本的片段较少,不存在密集字符的挑战。因此,急需一种针对密集型的古籍文档顺序检测方法,特别的对于密集型的古籍文档图片数据,能够更进一步的进行纸质文档转录,减少人力的标注过程,进一步的加快文档数字化进程。
技术实现要素:
4.本发明的目的在于提出一种古籍文档顺序检测方法,使得文档类型的数据被精确地进行纸质文档转录。
5.为实现上述目的,本发明提供了一种古籍文档顺序检测方法,包括:
6.获取图像数据,基于所述图像数据进行各个字符的连接顺序标注以及整个文档的文本行顺序标注,获得训练数据集;
7.基于所述训练数据集,通过空间几何关系构造图的邻接矩阵,构造图中各个结点的特征以及边特征,训练字符连接关系预测模型,得到将字符连接后的文本行;
8.基于所述训练数据集,通过编码-解码的序列模型,构建并训练文本行顺序预测模型,获得文本行顺序预测结果;
9.根据所述图像数据,基于所述训练字符连接关系预测模型和所述训练文本行顺序预测模型,获得图像数据的符合阅读顺序的文档内容。
10.可选的,所述图像数据包括:手写无约束文本行数据集casia、字符排列规整古籍文档数据集tkh、单字排布多样古籍文档数据集mth;所述文本数据包括:使用文本行标注的古籍数据集。
11.可选的,连续顺序标注包括:各个单字字符的下一个连接字符。
12.可选的,构建训练字符连接关系预测模型包括:通过计算各个字符结点的l2距离,
对于每个字符结点找到最近的8个字符结点,构造k阶子图网络,基于各个字符的几何结构,构造图的结点特征以及边特征,基于空间几何关系构造图的邻接矩阵,训练得到基于字符结点的连接关系图网络预测模型。
13.可选的,构建训练字符连接关系预测模型还包括阈值,所述阈值用于判断所述图像数据能否进行训练;基于空间l2距离,构造每个结点的8邻域子图,计算节点数目的iou,当iou大于阈值则图像数据不进行训练,反之则进行训练。
14.可选的,所述构造k阶子图网络中,所述结点特征为各个字符的归一化中心点坐标以及归一化的宽高;所述边特征为字符间的宽高比以及横纵坐标距离差;构造的邻接矩阵为两个字符结点满足每个字符结点的knn矩阵中的前k个结点。
15.可选的,所述编码-解码的序列模型包括:基于文本行的版面坐标信息以及位置编号信息,通过transformer模型得到编码后的特征序列,通过decoder添加分类分支,预测各个时间步对应输入序列的索引,根据各个时间步的预测结果,基于交叉熵损失计算损失训练编码-解码的序列模型。
16.可选的,根据数据集中的字符输入,通过字符连接关系预测模型,得到连接后的文本行输出;通过文本行的输出,利用文本行顺序预测模型,得到最终的文档顺序化输出内容。
17.本发明技术效果:本发明公开了一种古籍文档顺序检测方法,针对密集字符型的文档图片,基于字符检测结果进行顺序检测,提出包括单字连接关系预测模型以及文本行顺序预测模型。将现代计算机信息技术和文档数字化内容相结合,对于数字遗产保护、信息发现、自动化纸质文档转录流程等工作具有重要的作用。
附图说明
18.构成本技术的一部分的附图用来提供对本技术的进一步理解,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:
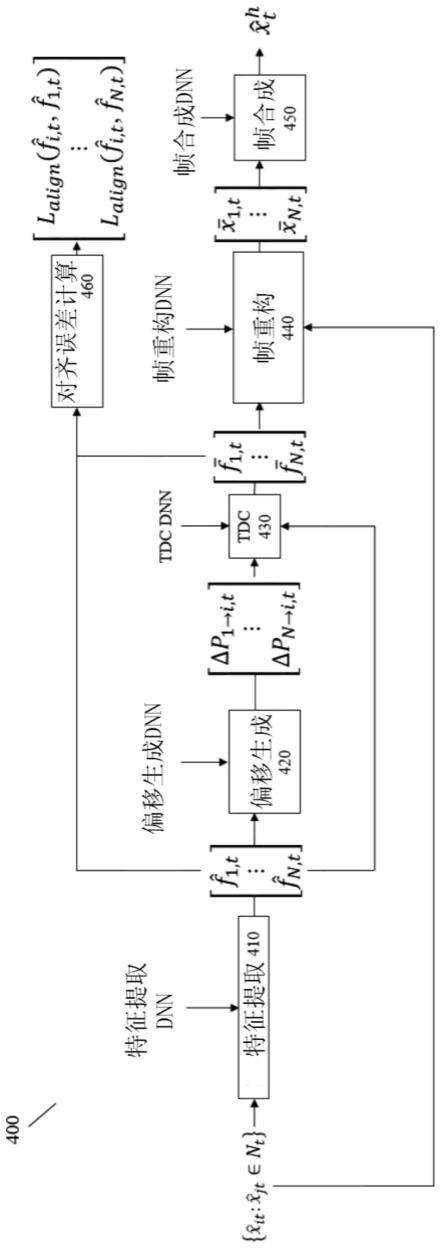
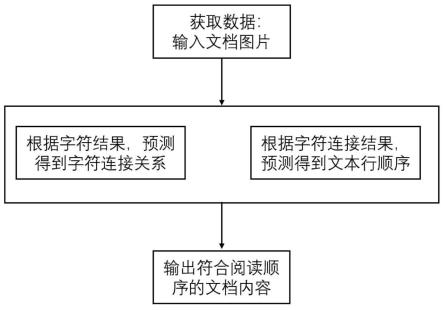
19.图1为本发明实施例古籍文档顺序检测方法的流程示意图;
20.图2为本发明实施例字符连接关系预测的网络图;
21.图3为本发明实施例文本行顺序预测的网络图;
22.图4为本发明实施例字符连接关系的可视化效果图,其中(a)图为casia数据集,(b)图为tkh数据集,(c)图为mth数据集;
23.图5为本发明实施例文本行顺序预测的可视化效果图。
具体实施方式
24.需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本技术。
25.需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
26.如图1-5所示,本实施例中提供一种古籍文档顺序检测方法,包括:
27.获取图像数据,基于所述图像数据进行各个字符的连接顺序标注以及整个文档的
文本行顺序标注,获得训练数据集;
28.基于所述训练数据集,通过空间几何关系构造图的邻接矩阵,构造图中各个结点的特征以及边特征,训练字符连接关系预测模型,得到将字符连接后的文本行;
29.基于所述训练数据集,通过编码-解码的序列模型,构建并训练文本行顺序预测模型,获得文本行顺序预测结果;
30.根据所述图像数据,基于所述训练字符连接关系预测模型和所述训练文本行顺序预测模型,获得图像数据的符合阅读顺序的文档内容。
31.进一步优化方案,所述图像数据包括:手写无约束文本行数据集casia、字符排列规整古籍文档数据集tkh、单字排布多样古籍文档数据集mth;所述文本数据包括:使用文本行标注的古籍数据集。
32.获取数据:针对单字连接关系预测以及文本行顺序预测,我们分为两部分进行实验数据集构建。其中单字连接关系预测包括手写无约束文本行数据集casia,该数据集特点是其中的单字都是手写的无约束文本行,同时含有标点符号;tkh数据集为古籍文档数据集,其中数据集字符排列规整;mth数据集为古籍文档数据集,该数据集单字排布多样,同时有多个版面区域以及双列夹注情形,训练难度更大。其中文本行顺序预测实验使用古籍数据集,不同于mth数据集,该数据集标注使用文本行标注,预测文本行的顺序索引。表1为单字连接关系预测数据集分布情况统计,表2为文本行顺序预测数据集分布情况统计,表1为用于单字连接关系预测的数据集分布情况统计;具体的训练测试数据统计如表1,表2所示。
33.表1
34.训练集图片数测试集图片数casia数据集5091300tkh数据集749250mth数据集1649551
35.表2
[0036] 训练集图片数测试集图片数mth textline1062119
[0037]
进一步优化方案,连续顺序标注包括:各个单字字符的下一个连接字符。
[0038]
进一步优化方案,构建训练字符连接关系预测模型包括:通过计算各个字符结点的l2距离,对于每个字符结点找到最近的8个字符结点,构造k阶子图网络,基于各个字符的几何结构,构造图的结点特征以及边特征,基于空间几何关系构造图的邻接矩阵,训练得到基于字符结点的连接关系图网络预测模型。
[0039]
进一步优化方案,构建训练字符连接关系预测模型还包括阈值,所述阈值用于判断所述图像数据能否进行训练;基于空间l2距离,构造每个结点的8邻域子图,计算节点数目的iou,当iou大于阈值则图像数据不进行训练,反之则进行训练。
[0040]
训练字符连接关系模型:对于输入的文档图片,由于文档中的字符数量较多,特别地,古籍中的字符数量存在上千个,因此直接基于文档中的所有字符构造图网络需要很大的计算量,因此基于字符在文档中的l2坐标距离,构造多个子图。同时子图间可能有较大的冗余度,为了避免重复的计算量以及使得网络能够有效的学习,计算子图间的iou,当iou大于设定阈值时,则忽略该子图的计算。对于各个子图,我们以字符作为图网络的结点,依次
构造图的结点特征、边特征以及邻接矩阵。
[0041]
对于某个结点,其邻接矩阵为是否其余字符结点满足l2距离在最近的k个结点中,满足则在邻接矩阵中赋值为1,其中k的值为4。图网络的结点特征包括视觉特征以及几何特征,其中视觉特征即,将图片经过resnet18网络,将对应坐标位置的区域经过roialign后得到固定维度大小的特征;几何特征即为归一化后的中心点坐标以及宽高。图网络的边特征包括各个字符框间的中心点坐标差以及宽高比。
[0042]
经过相邻结点的编码后,将编码后的边特征用于预测各个结点间的连接关系,由于正负样本比例相差大,训练中保持正负样本比例在1:1,使用交叉熵损失计算损失大小,优化更新模型参数。
[0043]
其中在三个数据集下的实验结果如表3-5所示,相比于启发式的方案以及直接使用全连接层分类的方法,本发明方法在精度(precision),召回率(recall),以及调和平均数上(f-score)能够有更加明显的优势,表3为casia数据集单字连接实验对比,表4为tkh数据集单字连接实验对比,表5为mth数据集单字连接实验对比。
[0044]
表3
[0045][0046]
表4
[0047][0048]
表5
[0049][0050]
进一步优化方案,所述构造k阶子图网络中,所述结点特征为各个字符的归一化中心点坐标以及归一化的宽高;所述边特征为字符间的宽高比以及横纵坐标距离差;构造的邻接矩阵为两个字符结点满足每个字符结点的knn矩阵中的前k个结点。
[0051]
进一步优化方案,所述编码-解码的序列模型包括:基于文本行的版面坐标信息以及位置编号信息,通过transformer模型得到编码后的特征序列,通过decoder添加分类分支,预测各个时间步对应输入序列的索引,根据各个时间步的预测结果,基于交叉熵损失计
算损失训练编码-解码的序列模型。
[0052]
训练文本行顺序预测模型:文本行顺序预测模型由编码-解码结构组成,其中编码模型输入包括文本行的版面坐标信息(layout embedding),以及位置编号信息,经过transformer模型得到各个编码后的序列;解码部分添加分类分支,预测各个时间步对应输入序列的索引。对于各个时间步的预测结果,通过交叉熵损失计算损失来训练模型。具体的,我们引入数据增强以及数据合成技术来进一步提高我们的模型性能。对于数据增强,即通过文本行替换、文本行删除的方法,增加原有的数据集图片数目;同时针对古籍数据集的文档布局,额外合成带有双列夹注的文档图片。
[0053]
进一步优化方案,根据数据集中的字符输入,通过字符连接关系预测模型,得到连接后的文本行输出;通过文本行的输出,利用文本行顺序预测模型,得到最终的文档顺序化输出内容。
[0054]
指标评测上,使用平均相对距离来评价模型的性能。具体来说,对于输入的序列框,查找对应在预测序列的索引,判断预测的索引和目标的索引之间的误差,计算相对差的绝对值来评估。如表6所示,为mth文本行顺序预测实验对比,我们的方案优于启发式的规则,有更低的误差结果。
[0055]
表6
[0056] 启发式的方案提出的方案mth textline0.09274.8269 数据增强0.09270.5708 数据合成0.09270.0894
[0057]
最后总结如下:通过输入一张古籍文档图片以及检测到的单字结果,经过单字连接关系预测,将输出单字连接得到文本行的输出;经过文本行顺序预测,对输入的文本行进行顺序排列,得到最终的顺序化输出结果。
[0058]
本发明通过分析现有方法存在的不足之处,提出了针对文档顺序检测的方案,主要包括单字连接关系预测模型以及文本行顺序预测模型。由于字符密集情况广泛存在于现有的数据集,通过先将单字连接成文本行、再进一步进行文本行顺序预测的方案能够更大的减少计算复杂度以及提高模型的效果。
[0059]
以上所述,仅为本技术较佳的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应该以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。