1.本发明涉及过程的监测。该过程是例如水处理厂、造纸机等。
背景技术:
2.现今,机器学习算法与系统一起使用,这些系统对类似造纸机或水处理的过程的行为进行建模、分析和估计。过程通常是多变量过程,因此进行大量测量,并且这些过程可能非常难以监测或理解。尤其当每天在线获得测量时,产生和处理大量的数据。
3.机器学习为系统提供了自动学习和通过经验得到改善而无需被显式编程的能力。因此,机器学习(ml)利用算法和统计模型,计算机系统使用算法和统计模型执行特定任务或多个任务而不使用显式指令。存在若干ml算法。在此仅提及它们中的一些:线性回归、逻辑回归、k-均值、前馈神经网络等。
4.ml算法的结果通常难以解释,特别是来自复杂过程的结果。因此,解释值用于帮助用户解释ml的结果。通过使用例如shap(shapley加性解释)值、lime方法或deeplift方法来获得解释值。
5.仍然需要识别过程干扰的源或源头,对其进行监测。
技术实现要素:
6.本发明的目的是提供一种监测过程的方式。本发明的另一目的是提供一种用于识别、任选地评估过程中的过程干扰源(或多个)或质量缺陷源的方法。本发明的另外的目的是一种使用关于干扰源/来源的信息控制该过程的方法。本发明利用解释值。过程的监测可自动完成。目标是以在独立权利要求中描述的方式实现的。从属权利要求说明了本发明的不同实施例。
7.一种用于监测过程和/或识别过程干扰源或质量缺陷源的创造性方法,包括用于创建过程的ml模型的预备步骤。ml模型利用来自过程的测量结果作为ml模型的输入并形成模型输出。该方法还包括用于将输入分类成分组的第二预备步骤。这可以利用包含关于输入如何属于分组的信息的预定数据库来完成。该方法具有计算步骤,用于计算每个输入的解释值,解释值指示输入对模型输出的贡献,并且用于计算每个分组的指示值的总和,指示值与解释值相关。进一步地,该方法包括监测步骤,用于监测所计算的总和,每个总和指示所讨论的分组的状态。可以以分组特定的方式来进行监测。分组可包括主分组和主分组中的子分组。该方法的输出可以用于该过程或该过程的子过程的手动或自动控制。
附图说明
8.在下面,通过参考所附附图更详细地描述本发明,其中:
9.图1示出了用于说明的ml建模的简单示例,
10.图2示出了根据本发明的方法的流程图示例,
11.图3示出了根据本发明的系统的示例,
12.图4示出了根据本发明的用于输入的主分组的计算总和的示例,
13.图5示出了根据本发明的主分组的子分组的计算总和的示例。
14.图6示出了用于具有预警和警报阈值(分别为较低和较高水平线)的化学分组计算的shap值的总和的示例
15.图7示出了将输入分组为主分组和子分组的示例。
具体实施方式
16.图1示出了用于说明的ml建模的简单示例。真实的模型可能要复杂得多,包含大量的变量。在图1中,x轴示出了一变量,例如,供应给造纸机的辊筒的电力。y轴表示另一个变量,例如辊筒的旋转速度。这个简单的示例对这些变量之间的关系进行建模。随着供应电力的增加,旋转速度也随之增加。点1为被测旋转点,对应的x轴表示被测的供应电力。另一个示例可以是x轴示出了造纸机的水网(wire wate)中疏水污染物的量,以及y轴示出了造纸机的洗涤间隔。
17.可以看到,测量可以被建模为递增的直线2。该直线的值是实际测量的平均值。在方程式中,直线可以是y=ax b,直线及其方程可以是两个变量之间关系的简单的ml模型。正如所说,实际过程通常要复杂得多,所以ml模型在实际中也更复杂。在图1的示例中,很容易看出电力对旋转速度的影响程度,所以解释值并不那么有用。但是,如果有更多的变量,例如十个变量,情况将会是很难理解每个变量对模型输出的贡献程度。
18.虽然在本文中,过程被称为一个过程,但它可以包括许多不同的过程,这些过程共同执行整个过程。因此,本描述中的过程实际上可以包括几个过程和子过程。例如,造纸机过程可以具有一个或多个子过程,例如水循环、湿端部和损纸(break)线等中的一个或多个。废水处理过程可以包括例如初级、二级和三级处理,或其中的一些。类似地,整个过程的ml模型可以包括多个模型,这些模型也可以称为子模型。因此,整个ml模型可以有几个输出(即子模型的输出)。每个输出都模拟/预测过程的某个属性。
19.过程可以是工业过程。该过程可以是例如纸浆处理、造纸、制板或分组织制造过程、造纸机、纸浆厂、纸巾机、纸板机、水处理过程、废水处理过程、原水处理过程、水再利用过程、工业水处理过程、市政水或废水处理过程、污泥处理过程、采矿过程、油回收过程或任何其他工业过程。
20.子过程和模型输出可以根据所讨论的过程进行适当的选择。
21.现在,在本发明中,已经发现可以利用机器学习的解释值(例如shap值)来监测该过程。在本文中,示例指的是shap值,但示例也可以利用lime方法的值、deeplift方法的值或任何其他可能的解释值。shap(shapley加性解释)解释值将每个特征归因于在该特征条件下预期模型预测的变化。这些值解释了如果我们不知道当前输出f(x)的任何特征,如何从基值中得到被预测的期望e[f(z)]。在期望事实中添加特征的顺序很重要。但是,在shap值中考虑到了这一点。
[0022]
lime方法解释个体模型预测,这些预测基于围绕给定预测的模型的局部近似。lime将简化的输入x称为可解释的输入。映射x=hx(x)将可解释输入的二进制向量转换为原始输入空间。不同类型的hx映射用于不同的输入空间。
[0023]
deeplift是递归预测解释方法。它为每个输入xi赋予值cδxiδy,该值表示将该
输入设置为参考值而不是其原始值的效果。这意味着deeplift映射x=hx(x)将二进制值转换为原始输入,其中1表示输入采用其原始值,0表示采用参考值。参考值表示特征的典型非信息背景值。
[0024]
针对指示输入对模型输出的贡献的每个输入计算shap值(或机器学习的其他解释值)。例如,当考虑造纸机流浆箱时,可以将泵转速和纸浆ph值输入子模型,并计算它们的shap值。造纸机的另一部分可以由另一个子模型使用其他输入(如机器的网(wire)的网速度)来建模。现在,当用于整个过程的模型的输入和/或用于子过程的模型的输入被分类为分组时,并且利用为模型输出计算的shap值,并计算每个分组的shap值的总和,可以监测分组输入对模型输出的贡献。
[0025]
将分类输入成分组是预备步骤。它利用预定数据库,该数据库包含关于输入如何属于分组的信息。如何将输入分组的知识是有关过程的专家具有的知识。在许多情况下,专家的知识可能包括经验和过程知识,如化学知识、化学相关现象知识等。专家知识可以是表单、图表、表格或其他形式,用于提供所述预定数据库。例如,数据库可以是表单、图表或表格的形式。可以看出,数据库包含了专家知识。这样的预定数据库可以以任何已知的方式建立。在建立数据库时,可以对历史数据进行数据分析。
[0026]
另一个示例可以是损纸线子模型的输出是有害污染的量。该子模型的输入可以是例如未涂覆和涂覆损纸的体积或质量流量、阴离子电荷、胶体数。另一个示例性子模型的输出可以是例如来自水循环和纸浆处理的有害化合物的量或原水的质量。整个过程模型的输出可以是例如造纸机的运转能力(例如损纸)或最终产品的一定质量,例如缺陷(例如斑点、孔洞)、强度、施胶性能、边缘芯吸、形成、孢子数、微生物数、水处理过程中的某些水质参数或所讨论过程的任何合适的目标参数。缺陷可以是例如纸张或纸板质量上的缺陷,诸如斑点或孔洞之类的缺陷,强度、施胶性能、边缘芯吸、形成、孢子数或微生物数的缺陷。例如,强度缺陷或其他缺陷意味着描述缺陷的值不符合目标值。例如,强度缺陷可能意味着强度值过低或不均匀/随时间变化。
[0027]
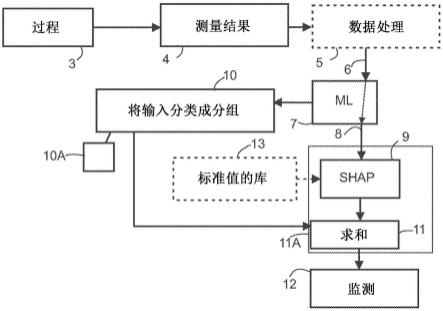
图2示出了本发明方法的示例。一种用于监测过程和/或识别过程干扰的源或质量缺陷的源的方法,包括用于创建过程的ml模型的预备步骤21。历史数据可以用于模型的训练(例如1-2年的数据)。根据需要,可以一次或以一定的间隔(定期,例如每年一次)或不定期进行预备步骤。如上所述,该过程可以有几个过程(子过程)。ml模型利用来自过程的测量结果作为ml模型的输入,并形成模型输出。参照图3。因此,ml模型或多个ml模型的模型输出表达过程运行得怎么样,如上所述。这是如上所知的。该方法还包括第二预备步骤22,用于利用预定数据库将输入分类成分组。分组可以包括主分组和可选的主分组中的子分组。这些分组是预先定义的,例如由用户或过程的所有者预先定义的。分组可以反映预定确定的质量指标和/或过程状况。分组可以包括一个或多个输入,并且输入可以被包括在一个或多个分组中。
[0028]
来自过程的测量结果可以是例如化学有关的测量结果(例如ph、氧化还原、电导率、电荷、阳离子需要量、木材提取物浓度、浊度、磷、磷酸盐、化学需氧量、总固体、悬浮固体),这些测量结果可以是实时测量、连续测量或实验室测量,化学品的投药量、要投药到过程中的化学品的流速、水和纸浆流的流速和浓度、生产信息(例如,等级、克重、生产的产品吨数、机器速度、损纸(break)、损纸类型)、塔和罐的填充水平、过程延迟、产品质量的测量
(如缺陷、强度、cobb值)。相关/合适的测量结果取决于所讨论的过程,可以包括该过程的任何相关/合适的测量结果。
[0029]
该模型具有用于计算机器学习的解释值(解释值)的计算步骤23,解释值例如是用于指示输入对模型输出的贡献的每个输入的shap值,并且计算步骤计算用于每个分组的指示值的总和。计算步骤通常可以在规则的时间频率下进行,例如每分钟、每10分钟、每60分钟。应当注意,解释值是针对已知ml模型的所有输入计算的。此外,本发明计算所述预定分组的解释值的特定总和。因此,指示值与解释值(例如shap值)相关。指示值是解释值,例如shap值,或解释偏差值,例如shap偏差值。解释偏差值(例如shap偏差值)是解释值(例如shap值)和标准解释值(例如shap值)之间的差。标准值可以从该过程的良好运行周期中获得。因此,可以说标准解释值(例如标准shap值)是稳定过程(在可运行性或最终产品质量方面没有干扰)的解释值(例如shap值)。此外,该方法包括监测步骤24,用于监测所计算的总和,每个总和指示所述分组的状态。输入可以是实时值,监测也可以是实时的。本发明还可用于其他分析目的。例如,输入可以是用于分析的历史数据。
[0030]
监测步骤可以定义输入的每个分组的状态。这些分组被建立成与分组特定的项相关。换句话说,分组的输入与特定项有关。shap值的总和或shap值本身(或其他解释值)可以缩放到合适的水平,这便于使用。例如,当总和为负或相对接近于零时,分组的状态是好的,即模型和过程运行良好。另一方面,当总和为正时,分组的状态不是很好,即过程有一个或多个问题或有过程问题/干扰增加的风险。因此,为特定组计算的解释值的总和旨在确定过程的特定一个或多个状况的而设计的。总和的缩放可以用许多方法进行,这里的零或负值表示适当的状况。对计算出的总和的解释/含义已经变得容易。
[0031]
应当指出,总和的解释/含义取决于每个单独的分组。例如,如果该分组的解释/含义是表示例如纸张强度,那么高强度值(高和)是好的,而低强度值(低和)是坏的。解释值的解释现在与上面的示例不同。当总和为负值时,分组的状态不佳(贡献者减少力量)。当总和为正时,分组的状态很好(贡献者增加力量)。
[0032]
因此,以特定分组的方式监测计算的总和,每个总和表明所讨论的分组状态。
[0033]
该分组的状态可以用适当的方式表示,例如“交通灯”:绿色、黄色和红色。如果分组的状态为绿色,则分组对模型输出的贡献较低(即过程不稳定、干扰或问题或产品质量差的风险较低或减少)。绿色状态表示该群体状态良好。如果分组的状态为黄色,则分组对模型输出的贡献是中等的(即过程不稳定、干扰或问题或产品质量差的风险增加)。黄色状态意味着该分组的状态还可以或处于可接受的水平。黄色状态可称为预警状态。如果状态为红色,则分组对模型输出的贡献很高(即过程不稳定、干扰或问题或产品质量差的风险很高)。红色状态可称为警报状态。该分组的状态也可以是例如数值(例如0、1、2、3)或文本值(良好、预警、警报)。可以基于shap值(或其他解释值)的总和的预定阈值来定义分组的状态。预定阈值可以取决于模型、过程和作为模型中输入的测量结果。可以根据处理的历史数据来定义预定阈值。
[0034]
输入的分类可以方便地分为主分组和子分组。如上所述,分类利用预定的数据库。图4显示了主分组41的示例,即i、ii、iii、iv、v、vi。纵轴显示了每个分组shap值的总和。我们假设要监测的过程是造纸过程,主分组是生产i、化学ii、子过程1中的塔iii、子过程2中的塔iv、中断v和其他vi。圆形42、矩形43和十字44显示了不同的情况,所以图4实际上显示
了三个示例。这些示例都有来自真实造纸的真实依据。圆形表示卷纸上有超过500个质量缺陷的情况。矩形表示卷纸上有50到500个质量缺陷的情况,十字表示卷纸上有小于50个质量缺陷的情况。可以看到,十字相对接近于零或为零,这表明每个分组的情况都很好。缺陷在可接受的水平。矩形内的情况不太好,因为可以看到化学分组的总和的值高于零。因此,监测表明可以在该分组中完成一些事情,即使用输入和与提供有输入的过程相关。这些圆形表明,现在化学分组和生产的情况更糟。因此,可以注意到,总和值的层级也可以表明缺陷的严重程度。例如,当参考图4时,总和值低于0.05的阈值表明情况良好,因此缺陷的数量很少,它们不会对过程产生很大影响。阈值0.05到0.15之间的总和值表明过程中有问题,过程可能变得不稳定,即过程干扰的风险可能正在增加,但还不需要立即采取任何措施。在图4中,矩形情况指示在分组ii中具有该层级,而圆形情况指示了在分组i中具有该层级。超过阈值0.15的总和值表示需要立即采取措施,因此该层级的缺陷是最严重的缺陷。圆形情况指示了在分组ii中的该层级。分组的状态的阈值是预定的,并且可以依赖于例如模型、过程和在模型中用作输入的测量结果中的一者或多者。
[0035]
过程或子过程的主分组可以是化学分组(过程或子过程的化学相关的测量)、生产分组(过程或子过程的生产相关的测量)、产品质量、塔和/或任何其他合适分组。化学分组的子分组的示例是在过程或子过程中,或在该过程或子过程中的特定化学处理步骤中的特定水或纸浆或滤液流中溶解化合物、颗粒、疏水颗粒、微生物活性、有机化合物、无机化合物或化学性(例如ph、温度、电导率、任何其他与该过程的化学状态有关的测量)。生产的子分组的示例有等级、克重、生产的产品的量、过程的中断/停止、处理水的体积、处理水的流量。例如,如果过程是纸张或纸板机,化学的子分组可以是进浆质量、进浆的阴离子废料、进浆的微生物活性、进浆的疏水污染、湿端的化学性、湿端的微生物活性、湿端的阴离子废料(溶解阴离子化合物的量或浓度)、湿端的疏水污染、保留物、施胶、损纸流质量(s)、损纸流中的疏水污染、损纸流中的微生物活性、损纸流中的阴离子废料、原水质量、水循环质量。分组的预定义可以依赖于过程和模型(模型的目标值)。
[0036]
例如,该过程可以是纸张、纸板或薄纸制造过程,主分组包括生产、化学、塔和其他中的一个或多个。
[0037]
由于主分组相对较大,他们可能会给出正确的方向来采取纠正措施,但主分组的子分组可以给出更准确的方向。虽然使用主分组和子分组有一些优点,但也可以使用没有主分组和子分组的分组分类。在这类实施例中,输入只是被分类为分组。
[0038]
图5示出了子分组51的示例,即a、b、c、d、e、f、g、h、i、j、k和l。垂直轴显示了每个子分组的shap值的总和。此处认识到,要监测的过程是与图4中相同的造纸过程,子分组属于化学主分组ii。这些子分组可以是保留物、疏水性污染、凝聚、阴离子废料、纸浆质量、施胶、原水、废水、微生物活性、消泡剂、配料温度和配料ph值。圆形52与图4中的圆形的情况有关。矩形53与图4中的矩形的情况有关,而十字54与图4中的十字的情况有关。可以看出,十字的情况很好。在矩形的情况下,纸浆质量会出现一些问题。而且,在圆形的情况中,存在着保留物(retention)和纸浆质量方面的问题。总和值的层级也可以指示子分组中缺陷的严重程度。
[0039]
进一步,子分组可包括以下中的一种或多种:进浆的质量,进浆的阴离子废料,进浆的疏水性污染,进浆的微生物活性,湿端化学过程,湿端微生物活性,湿端的阴离子废料
(溶解的阴离子化合物的量或浓度),湿端的疏水性污染,保留物,施胶,损纸流的质量,损纸流的疏水性污染,损纸流的阴离子废料,损纸流的微生物活性,原水的质量,水循环的质量,层级,克重,生产的产品的量,过程的中断/停止。
[0040]
图3示出了监测过程的本发明系统的示例。该系统包括ml模块7,用于创建过程的ml模型。ml模型利用来自过程3的测量结果4作为ml模型的输入6并形成模型输出8。在用作ml模型中的输入之前,可以对测量结果4进行预处理5。预处理可以例如包括数据合并、数据过滤、对齐时间格式、修改元数据、数据验证等。
[0041]
该系统还包括分类模块10,用于将输入分类横主分组和主分组中的子分组。如前所述,将输入分类成分组是预备步骤。它利用包含关于输入如何属于分组的信息的预定的数据库。如何对输入进行分组的知识是所讨论过程的专家知识。许多案例经验以及其他过程知识都涉及专家知识。专家知识可以是表单、图表、表格或其他形式,用于提供所述预定数据库。因此,例如,数据库可以是表单、图表或表格的形式。可以看出,数据库包含了专家知识。因此,分类模块利用包含关于输入如何属于分组的信息的预定数据库。
[0042]
该系统还具有计算模块11a,用于计算每个输入的shap值的该shap值指示输入对模型输出8的贡献,并计算每个分组的指示值的总和。指示值与shap值相关。计算模块11a可以包括用于这些计算的不同单元,即shap计算单元9和求和单元11。此外,该系统包括监测模块12,用于监测计算的总和,每个总和指示所讨论分组的状态。注意,当计算shap值时,使用输入6,为了清楚地说明,示出了从ml模型的输入6到shap模块的虚线。
[0043]
用于将输入分类成分组的分类模块(10)可以被配置为利用包含关于输入如何属于分组的信息的预定数据库,并且监测模块(12)可以被配置为以分组特定的方式监测计算的总和。
[0044]
如上所述,指示值是shap值或shap偏差值。shap偏差值是shap值与标准shap值之间的差值。标准值可以从过程的良好运行周期中获得,并可以保存在存储器中。因此,该系统还可以包括库模块13,以保持标准的shap值,该值可由shap计算模块9使用。如上所述,可以使用其他解释值代替shap值。
[0045]
如上所述,分组可以是预定的,并且在实施例中,当总和为负或相对接近于零时,当可能的缺陷的数量很小并且情况处于可接受范围时,分组的状态是好的(可接受的)。当总和为正时,分组的状态是不好的。总和还可能表明状态的严重程度。总和越大,分组内的情况就越严重。参照上面与图4有关的总和的不同层级的示例。当使用实时值作为输入时,监测可以是实时的。
[0046]
图6示出了预定阈值61、62作为时间函数(x轴指示小时)的化学分组状态的示例。在该示例中,当shap值60(或其他解释值)的总和等于或低于阈值零62时,分组的状态是好的。因此,当分组的状态良好时,该分组不会增加过程干扰或过程的最终产品质量缺陷的风险。当总和大于零且等于或小于值为0.07的另一阈值61时,化学分组的状态处于预警层级。在这一层级上,过程干扰或过程最终产品质量缺陷的风险已经增加,应开始准备纠正措施。当shap值的总和高于0.07(即另一阈值61)时,化学分组的状态处于警报层级。当阈值处于警报层级时,过程干扰或过程最终产品质量缺陷的风险很高。当分组的状态处于警报层级时,需要立即采取纠正措施。最终产品可以是例如工业过程的最终产品。最终产品可以是例如相应过程的纸张、纸板或薄纸,或者例如来自水处理厂或装置的净化水。因此,从示例中
可以看出,可以利用用于总和的至少一个阈值来定义分组的状态。
[0047]
用户可以预定义用于解释值的总和的阈值,解释值为例如分组或子分组的shap值。阈值可用于指示每个分组或子分组的状态和指示措施的需要。该方法还可以包含针对每个分组或子分组的预定的措施建议。如果分组或子分组的shap值的总和超过用于预警或警报的预定义的阈值,该方法给出措施建议,例如增加或减少化学剂量或纸浆、滤液或水流的流速,降低或增加过程温度,降低或增加过程流中的ph值,启动化学物投药或停用化学物投药。分组或子分组的shap值的总和可用于手动或自动过程控制,如控制化学投药、过程流程、ph、温度等。
[0048]
一个或多个分组的状态和/或一个或多个分组的解释值的总和可用于自动或手动控制过程、过程的故障排除或过程的优化。控制和或优化该过程可以包括以下中的一个或多个:化学品的投药量、化学品的投药点、在该过程中使用的化学品类型的选择。
[0049]
因此,根据本发明的方法和系统可以包括至少一个下一步骤,该下一步骤用于基于一个或多个分组的状态提供用于纠正措施的措施建议。
[0050]
因此,根据本发明的方法和系统可以包括至少一个下一步骤,该下一步骤用于基于一个或多个分组的状态来对过程进行控制、优化或故障排除。根据本发明的控制和/或优化步骤可以包括以下一个或多个:控制化学品的投药量、化学品的投药点、化学品的投药间隔、在过程中使用的化学品类型的选择、过程条件,例如ph、温度、过程流的流速,以及过程流延迟,例如在塔、罐、碎浆机、盆或其它过程设备中的纸浆、损纸或水流延迟。
[0051]
该方法还可用于预测最终产品中的过程干扰、运行性和质量问题的风险,例如未来几小时或几天的风险。
[0052]
本发明使得监测复杂的过程成为可能,该过程用已知的方式安排是非常繁琐的。监测可以在两个层级上进行,并且不影响现有的ml模型。由于输入变量被分类成分组或主分组和子分组,所以还可以通过改变分类来改变要监测的实体,或者甚至可以使用交织分类。这意味着可以根据专家知识改变输入属于分组的方式。过程的专家可能会注意到过程中必须考虑的变化,通过改变输入的分组或创建新的分组可以考虑到这些变化。可以将改变的分组或新的分组插入到数据库中。因此,可以更新预定的数据库。因此,本发明的监测方法和系统是灵活的。监测可以自动进行。
[0053]
图7还示出了如何将输入(变量)放入主分组和子分组的示例。我们可以考虑ml模型使用20个输入。如shap值的解释值是以已知的方式计算的,用于解释ml模型的输出。除此之外,本发明还具有预定分组,在图7的示例中,有一个主分组和六个子分组。分组和变量以图7中的表格形式存在,但在实际解决方案中,相同的信息以某种数据格式存在于数据库中。此信息包含前面所说的专家知识。在图7中,输入/变量2-19属于主分组,这些输入的计算解释值被求和。总和指示过程的某个状况,如一般故障情况,或其他状况。此指示不需要输入1和20。
[0054]
输入/变量4-1属于子分组1,这些输入的计算解释值被求和。而且,总和指示过程的一定状况,比如更具体的故障情况,或另一个更具体的状况。类似地,某些输入属于指示某些状况或故障的其他子分组2-6。
[0055]
应当注意,解释值是针对已知ml模型的所有输入计算的。此外,本发明计算所述预定分组的解释值的具体总和。本发明的好处是显而易见的。现有的解释值(如shap值)可以
通过利用用于ml模型的输入的预定分组来用于指示特定的状况或故障。由于预定分组是基于专家知识的,如果需要,它们也可以被更新。形成预定分组也是灵活的。不需要改变一个或多个ml模型,也不需要创建新的ml模型。
[0056]
相比于使用shap值,当使用shap值的差值时,监测系统可以更好地聚焦于指示过程中有问题事件的输入变量。
[0057]
本发明可以用软件实现,也可以用专用集成电路实现,还可以用软硬件结合实现。具有标准值的模块13是存储器,其自然可以包括软件和硬件。输入是来自过程的测量结果。ml模型和解释值是以这样的已知方式计算的。此外,将输入分类成预定分组并以分组特定的方式计算分组的输入的解释值的总和形成用以监测过程的不同状况的多功能配置,其中每个总和指示所讨论分组的状态。
[0058]
本发明的装置可以位于与被监测的过程相同的地方。但是,也有可能位于另一个地方,这使得远程监测过程成为可能。例如,测量数据4通过通信网络发送到本发明的监测器,该监测器处理测量数据并提供过程状态数据作为监测器的输出,其可用于许多目的,如调整过程的建议。
[0059]
从上面可以明显看出,本发明不限于本文中描述的实施例,而是可以利用独立权利要求书范围内的许多其他不同实施例来实现。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
