1.本发明属于电子信息技术技术领域,涉及一种算法与硬件协同优化的混合精度存内计算加速器。
背景技术:
2.近年来,神经网络凭借其在图像检测和目标分类中的优越性能,被广泛地研究和应用。当前主流的神经网络的连接点都数以亿计,是一种访存密集型和计算密集型的计算模式。庞大的神经网络模型导致它们很难被部署到硬件资源和能耗都受限的嵌入式系统中。
3.为了解决这些问题,在算法方面,目前最热门的技术就是对神经网络中的权重进行二值化处理,从而极大地减少神经网络加速器的数据搬移与计算。但二值化神经网络的推理准确度损失较大,系统稳定性有待考证。
4.在硬件方面,最近许多研究工作表明,避免不必要数据搬移的存内计算加速器是有望解决基于冯
·
诺依曼加速器中“存储墙”的问题。例如,相比于冯
·
诺依曼加速器,一种支持量化神经网络的基于dram的存内计算加速器架构drisa,实现了8.8倍的速度提升和1.2倍的能效提升。也有人提出支持二值化神经网络的存内计算加速器,如nand-net,用于减少存内计算硬件开销。
5.现有的支持神经网络推理的存内计算可分为支持量化神经网络(如8位量化)的存内计算加速器和支持二值化神经网络的存内计算加速器。支持量化神经网络的存内计算加速器虽然可以达到与全精度相当的神经网络准确度,但其模型尺寸大。与此带来的不仅是所需的存储单元多,而且存内计算加速器中的外围电路(包括模数转换器、移位器、加法器、解码器、缓冲器等)的硬件成本也会成倍增加。与此同时,这些外围电路的面积、延迟和功耗通常占存内计算加速器的大部分。另一方面,支持二值化神经网络的存内计算加速器,如nand-net,虽然其硬件开销减少了,但牺牲了神经网络的准确度。因此,现有技术难以兼顾神经网络准确度高与存内计算加速器硬件开销小的技术难题。
技术实现要素:
6.本发明的目的是提供一种算法与硬件协同优化的混合精度存内计算加速器,该加速器在神经网络准确度损失有限的范围内,大幅缩减存内计算加速器的硬件开销。
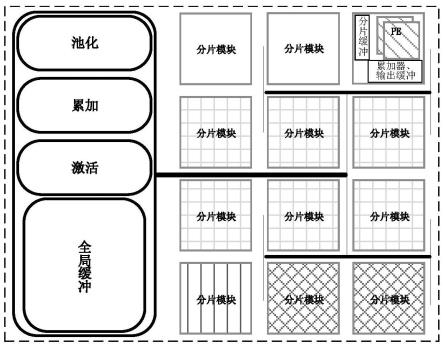
7.本发明所采用的技术方案是,一种算法与硬件协同优化的混合精度存内计算加速器,包括池化模块、累加模块、激活模块、全局缓冲模块及若干个分片模块。
8.本发明的特点还在于:
9.分片模块中包括处理单元pe。
10.处理单元pe包括若干个突触阵列、pe缓冲器、累加器及输出缓冲器。
11.突触阵列包括存储单元阵列、模数转换器adc、位线译码器、字线译码器、模拟多路选择器、位移寄存器。
12.加速器用于支持混合精度神经网络,通过caffe平台、tensorflow平台、或者pytorch平台对神经网络进行分层混合精度量化。
13.每层神经网络按各自的量化精度,部署到分片模块中。
14.如果一个分片模块不足以部署某一层的权重,则使用多个相同的分片模块。
15.部署不同的神经网络层的分片模块,该分片模块的内部电路设计不一定相同。
16.部署同一层神经网络的分片模块,该分片模块的内部电路设计完全一致。
17.神经网络层的权重、激励用低位宽的权重代替了全精度位宽或者8位位宽。
18.本发明的有益效果是,相比基于冯
·
诺依曼架构的神经网络加速器,本发明中的混合精度存内计算加速器将存储和计算融为一体,即在存储单元内部完成计算,以更高效能更高性能地实现神经网络运算。
19.相比于支持量化神经网络的存内计算加速器,本发明的混合精度存内计算加速器在功耗与芯片面积方面大幅降低。
20.相比于支持二值化神经网络的存内计算加速器,本发明的混合精度存内计算加速器不会对神经网络推理的准确度产生较大的损失。
附图说明
21.图1是本发明一种算法与硬件协同优化的混合精度存内计算加速器的结构示意图;
22.图2是本发明一种算法与硬件协同优化的混合精度存内计算加速器中的处理单元pe和突触阵列的示意图。
具体实施方式
23.下面结合附图和具体实施方式对本发明进行详细说明。
24.本发明一种算法与硬件协同优化的混合精度存内计算加速器,如图1、2所示,包括池化模块、累加模块、激活模块、全局缓冲模块及若干个分片模块。
25.分片模块中包括处理单元pe。
26.处理单元pe包括若干个突触阵列、pe缓冲器、累加器及输出缓冲器。
27.突触阵列包括存储单元阵列、模数转换器adc、位线译码器、字线译码器、模拟多路选择器、位移寄存器。
28.加速器用于支持混合精度神经网络,通过caffe平台、tensorflow平台、或者pytorch平台对神经网络进行分层混合精度量化。
29.每层神经网络按各自的量化精度,部署到分片模块中。
30.如果一个所述分片模块不足以部署某一层的权重,则使用多个相同的分片模块。
31.部署不同的神经网络层的分片模块,该分片模块的内部电路设计(如存储阵列的大小、使用多少个存储单元表示一个权重)不一定相同。
32.部署同一层神经网络的分片模块,该分片模块的内部电路设计完全一致。上述存储单元可以为但不仅限于是sram、dram、edram、nvm、忆阻器等可以实现存内计算的存储单位。
33.权重位宽的降低导致其所需要的存储单元数目大幅减少,相应地存储阵列的外围
电路(主要包括模数转换器adc、位线译码器、字线译码器、模拟多路选择器、移位寄存器等模块)也会成比例缩减。从而硬件功耗和面积开销大幅减少。同时,由于激励位宽减少,每个激励计算所需循环的次数也成比例减少,进而降低运算延迟提高运算能力。
34.神经网络层的权重、激励用低位宽的权重代替了全精度位宽或者8位位宽。
35.本发明提出一种支持混合精度的神经网络的存内计算加速器,并且优化神经网络在硬件上的部署机制。该设计首先利用神经网络各层特征的分布,设定各层量化精度,再通过程序软件对神经网络进行混合精度量化,以达到预定的神经网络精确度。然后,设计支持混合精度的神经网络的存内计算加速器,使得存内计算加速器的运算能力大幅提升、同时功耗、芯片面积大幅降低。在神经网络部署中,灵活调整神经网络各层的部署策略,利用神经网络各层输入激励的特点,使得存内计算加速器在芯片面积与运算能力之间达到进一步的优化。
36.在算法方面,本发明针对神经网各层特征分布的特点,通过程序软件(包括但不限于基于caffe平台、tensorflow平台或者pytorch平台)对神经网络进行分层(包括输入层与输出层)混合精度量化。该方法不但有效压缩神经网络模型而且对神经网络准确度不会造成较大的损失。具体地,例如,在浅层中,各个特征均比较相似相近,因此需要用高精度量化;而随着神经网络的传播计算,各个特征越来越明显,因此深层网络对量化误差不敏感,可采用较低精度进行量化。本发明以resnet18神经网络为例,将其各层的权重和激活的位宽依次设置为8-4-4-2-1-4。
37.在混合精度神经网络向混合精度存内计算加速器部署过程中,本发明对各层的部署机制进行定制差异化。一般常见的部署机制,可分为“无权重复制”映射方法和“有权重复制”映射方法。对于“无权重复制”映射方法,权重不会复制到多个存储单元,但每个计算周期只会计算激励的一个点,并同时只得到一个输出激活。因此,对于激励尺寸较大的神经网络层,需要循环多次来完成一层的卷积,这将耗费很多的计算时间。对于“有权重复制”的映射方法,权重被复制多份存到存储单元中,于是在一个计算周期内,权重可以同时完成与多个激励的计算,极大的提高了推理运算能力。但是,“有权重复制”的映射方法会成倍地增加硬件开销,只适用于权重数目少的层。
38.本发明中,神经网络各层选用权重映射方法不尽相同。对于浅层的神经网络层,一般激励尺寸比较大,采用“有权重复制”的映射方法,来减少推理延迟。而对于其他层,采用“无权重复制”映射方法来节省芯片面积与功耗。
39.本发明通过算法与硬件实现协同优化,提出支持混合精度神经网络的存内计算加速器,在神经网络准确度损失有限的范围内,大幅减小存内计算加速器的硬件开销。在算法上,利用神经网络各层特征的分布,设定各层量化精度,再通过程序软件对神经网络进行混合精度量化,以达到在不损失神经网络精确度的前提下压缩神经网络模型。在硬件实现上,本发明的混合精度存内计算加速器支持混合精度量化的神经网络,使得该混合精度存内计算加速器在运算能力、功耗、芯片面积得到大幅度的优化。在神经网络部署中,本发明利用神经网络各层输入激励的特点,优化选择“有权重复制”或者“无权重复制”的映射方法,使得存内计算加速器在芯片面积与运算能力之间达到进一步的优化。
40.本发明混合精度存内计算加速器不仅可应用于神经网络,也可应用于近似计算等混合精度的算法,同样能减少硬件面积与功耗开销。
41.实施例
42.本发明提出的一种算法与硬件协同优化的混合精度存内计算加速器,在32nm工艺节点上,选择sram作为存储单元,进行实验模拟验证。在对resnet18神经网络进行混合精度量化后,其对cifar10数据集的推理准确度相比于全精度神经网络只降低3%。相比于支持8位精度量化的神经网络的存内计算加速器,本发明混合精度存内计算加速器的面积节约了84.1%,功耗节约了45.5%,同时运算能力提升了3.54倍。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。