一种适用于awgn信道的1/n码率的卷积码参数盲识别方法
技术领域
1.本发明属于通信技术领域,更进一步涉及信道编码盲识别技术领域中的一种1/n码率的卷积码参数盲识别方法,可用于awgn(additive white gaussian noise)信道下卷积码生成多项式系数的盲识别。
背景技术:
2.信道编码技术作为通信系统中的重要组成部分,是提高通信传输可靠性的关键手段。但在一些应用中,编码参数对于接收方来说往往是未知的,为了对传送的数据进行解码,需要采用编码参数识别技术。因此,信道编码识别被认为是数字通信中的一项重要技术。卷积码是目前最常用的纠错码之一,其盲识别在认知无线电和非合作环境中受到了广泛的关注。然而目前的一些卷积码识别技术基于代数算法,仅利用接收数据的硬判决信息,因此只适用于无噪环境或低噪声环境,当噪声增强时,这些算法的识别性能便会大大降低。
3.西安电子科技大学在其申请的专利文献“一种高误码的任意码率卷积码编码参数盲识别方法”(申请日:2016年6月28日,申请号:201610496231.5,申请公开号:cn 106059712b)中公开了一种高误码的任意码率卷积码编码参数盲识别方法。该方法的具体步骤为:第一步,将得到的卷积码信息比特流vs排列成p
×
q的码率分析矩阵cq,分析每个矩阵非相关列数ci,确定有效列集合n;第二步,对列集合n中所有素取最大公约数,即可得到卷积码码长n;第三步,根据卷积码码长n和已知的卷积码信息比特流vs,识别信息位长度和卷积码校验序列;第四步,根据卷积码的码长n、信息位长度k和校验序列p
n-k
,对卷积码的寄存器长度m和生成矩阵g进行识别。该方法存在的不足之处是:由于该方法仅利用接收数据的硬判决信息,因此只适用于低噪声环境,当噪声增强时,识别性能便会大大降低,并且不适用于awgn信道。
4.p.yu等人在其发表的论文a least square method for parameter estimation of rsc sub-codes of turbo codes(ieee communications letters,2014.)中提出了一种在awgn信道下turbo码rsc(recursive systematic convolutional)编码器系数的识别方法,该方法利用接收数据的软信息,通过rsc编码器生成多项式系数与码字之间的关系,构建lsm(least square method)误差函数,随后在全局范围内搜寻最优解,通过不断迭代从而求解出生成多项式系数。然而,该方法在编码器约束长度增大时性能会急剧下降,并且在搜寻过程中,其简单搜寻方式容易陷入鞍点,导致在低信噪比时识别性能不高。
技术实现要素:
5.本发明的目的在于针对上述现有技术存在的不足,提出一种适用于awgn信道的1/n码率的卷积码参数盲识别方法,适用于awgn信道,在中低信噪比和卷积码约束长度增加时,也具有很好的识别性能,并且与现有方法相比,降低了时间复杂度。
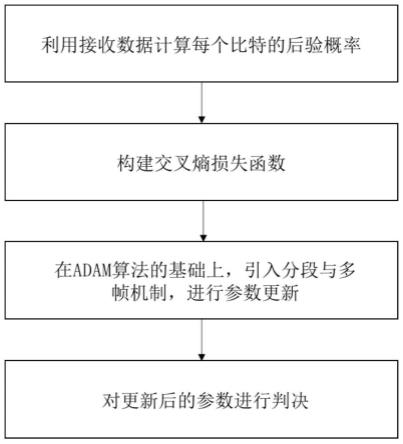
6.为实现上述目的,本发明基于adam的卷积码参数盲识别方法的具体步骤如下:
7.(1)利用接收数据计算每个比特的后验概率;
8.在解调器之前对经过awgn信道传输,帧长为l数据r进行接收,并根据噪声方差σ2计算每个比特的后验概率;
9.(2)将卷积码生成多项式系数定义为未知量参数q,利用卷积码码字与生成多项式系数之间的关系构建交叉熵损失函数:
10.(3)采用adam算法更新未知量参数q;
11.(3a)初始化未知量参数q为0到1之间的随机值,定义更新步长α;
12.(3b)损失函数对q求导,得到梯度g,进一步计算梯度的一阶矩估计与二阶矩估计
13.(3c)利用梯度的一阶矩估计与二阶矩估计与更新步长α完成对未知量参数q的更新;
14.(4)在步骤(3)中对未知量参数q进行更新时,采用分段与多帧机制;
15.(4a)定义分段大小segsize,将帧长为l的数据分为l/segsize段,在每一数据段的基础上执行步骤(3)中对q的更新;
16.(4b)对接收到的m帧数据,对每一帧数据执行(4a)中对q的更新,总共循环m次;
17.(5)定义迭代次数iter
num
,循环执行步骤(4)中的操作iter
num
次,完成对参数q的更新;
18.(6)对经过步骤(5)更新后的参数q进行判决,若0≤q≤0.5,则判为0,若0.5<q≤1,则判为1,完成对卷积码生成多项式系数的估计。
19.本发明与现有技术相比具有以下优点:
20.第一,本发明利用卷积码码字与生成多项式系数之间的关系构建交叉熵损失函数,可以更好的利用接收数据的软信息。
21.第二,由于本发明在参数更新时采用adam算法,利用梯度的一阶矩估计与二阶矩估计进行参数更新,对不同的参数具有不同的自适应学习率,使得整个更新过程具有更快的收敛性与更低的时间复杂度。
22.第三,由于本发明在参数更新过程中引入了分段机制,梯度的计算是基于每个数据段而非整帧数据,使得在梯度更新过程中引入了随机性,避免了在参数更新过程中陷入鞍点而导致性能下降,从而提升了识别性能。
23.第四,由于本发明在参数更新过程中引入了多帧机制,梯度更新是基于多帧数据而非一帧,从而使得本方法在中低信噪比以及卷积码约束长度增加时,也具有很好的识别性能。
附图说明
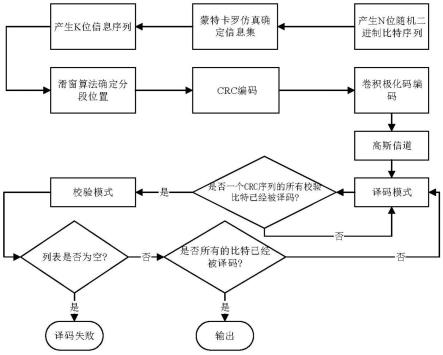
24.图1是本发明的实现流程图;
25.图2是本发明在卷积码(2,1,5),生成多项式为(53,75)上的仿真图;
26.图3是本发明在卷积码(2,1,7),生成多项式为(247,371)上的仿真图;
27.图4是本发明交叉熵损失函数的在更新过程中的等高线图;
具体实施方式
28.下面结合附图对本发明的实施例和效果作详细描述。
29.本发明是一种适用于1/n码率的卷积码参数盲识别方法,用于awgn信道下卷积码生成多项式系数的盲识别。
30.参照图1,本实例的实现步骤如下:
31.步骤1,利用接收数据计算每个比特的后验概率;
32.经过编码后的码字为c,awgn信道噪声方差为σ2,经过信道加噪传输后的数据为r,则每个比特的后验概率表示为:
[0033][0034]
步骤2,构建交叉熵损失函数;
[0035]
将卷积码生成多项式系数定义为未知量参数q,交叉熵损失函数表示为:
[0036][0037]
其中,m为卷积码寄存器长度,n为卷积码输出个数,l为接收数据帧长;
[0038]
步骤3,在adam算法的基础上,引入分段与多帧机制,进行参数更新。
[0039]
3.1)初始化未知量参数q为0到1之间的随机值,定义更新步长α与迭代次数iter
num
;3.2)定义分段大小segsize,将帧长为l的数据分为l/segsize个数据段;
[0040]
3.2.1)在每一数据段上,将交叉熵损失函数c(q)对q求导,得到第k轮迭代的梯度g[k]:
[0041][0042]
其中,
[0043][0044]
3.2.2)计算梯度的一阶矩估计u[k]与二阶矩估计v[k]:;
[0045]
u[k]=β1·
u[k-1] (1-β1)
·
g[k]
[0046]
v[k]=β2·
v[k-1] (1-β2)
·
g2[k];
[0047]
其中,β1与β2为矩估计的指数衰减速率,通常β1=0.9,β2=0.999;
[0048]
3.2.3)对梯度的一阶矩估计u[k]与二阶矩估计v[k]进行修正,即
[0049][0050][0051]
3.2.4)利用计算得到的梯度的一阶矩估计与二阶矩估计对未知量参数进行更新,即
[0052]
[0053]
其中,ε是一个非常小的数,通常为10e-08;
[0054]
3.3)对l/segsize个数据段,重复执行上述步骤3.2.1)-3.2.4);
[0055]
3.4)对接收到的m帧数据,对每一帧数据重复执行上述步骤3.2)-3.3);
[0056]
3.5)令k=k 1,迭代执行上述步骤3.2)-3.4),直到迭代次数k达到定义的最大迭代次数iter
num
;
[0057]
3.6)若迭代过程中q收敛到全零解,则将k置为1,重新开始执行上述步骤3.1)-3.5);步骤4,对更新后的参数进行判决
[0058]
对完成迭代后的参数q进行判决,若0≤q≤0.5,则判为0,若0.5<q≤1,则判为1,完成对卷积码生成多项式系数的估计。
[0059]
本发明的效果可通过以下仿真结果进一步说明:
[0060]
一.仿真条件
[0061]
本发明的仿真实验所采用的参数如下:信源发送长度为1000的信息序列,卷积编码器编码后得到长度为2000的编码序列,经过bpsk调制之后得到调制序列,经过awgn信道传输后得到帧长l=2000的接收数据。在使用adam算法进行参数更新时,最大迭代次数iter
num
=30,分段大小segsize=40。当不采用多帧机制时,m设置为1,更新步长α=0.1,当采用多帧机制时,m设置为40,更新步长α=0.01。
[0062]
本方法与上述lsm识别方法进行了性能对比。
[0063]
二.仿真内容与结果分析
[0064]
仿真1:仿真1的实验有四个。所识别的卷积码为(2,1,5)。生成多项式为(53,75)。第一个仿真实验是上述lsm方法的识别性能曲线。第二个仿真实验是本发明中只采用adam方法进行识别的性能曲线。第三个仿真实验是本发明中采用adam方法与分段机制进行识别时的性能曲线。第四个仿真实验是本发明中采用adam方法与分段和多帧机制进行识别时的性能曲线。四个仿真实验的结果曲线如图2所示。图2中横坐标表示信噪比。单位db。纵坐标表示识别准确率。
[0065]
由图2可见,本发明所提出的adam与分段和多帧机制识别性能最好,在-1db时就可以达到90%以上的识别准确率,远优于上述lsm识别方法,此外,从图2中也可以看出,单独采用adam方法和采用adam方法与分段机制都对识别性能有所提升,均优于lsm识别方法;
[0066]
仿真2:仿真2的实验有四个,所识别的卷积码为(2,1,7),生成多项式为(247,371)。第一个仿真实验是上述lsm方法的识别性能曲线,第二个仿真实验是本发明中只采用adam方法进行识别的性能曲线,第三个仿真实验是本发明中采用adam方法与分段机制进行识别时的性能曲线,第四个仿真实验是本发明中采用adam方法与分段和多帧机制进行识别时的性能曲线,四个仿真实验的结果曲线如图3所示,图3中横坐标表示信噪比,单位db,纵坐标表示识别准确率;
[0067]
由图3可见,当卷积码约束长度增加时,上述lsm方法识别性能会急剧下降,而本发明所提出的adam与分段和多帧机制在1db依然有接近90%的识别准确率,此外,从图中也可以看出当卷积码约束长度增加时,单独采用adam已经不能完成识别,而分段与多帧机制均可以不同程度的提升识别准确率;
[0068]
仿真3:仿真3以(2,1,5),生成多项式为(53,75)的卷积码为例,其生成多项式表示为g0(d)=1 d2 d4 d5,g1(d)=1 d d2 d3 d5,令q
0,0
=q
0,4
=q
0,5
=1,q
0,1
=q
0,3
=0,q
1,0
=q
1,1
=q
1,3
=q
1,5
=1,q
1,4
=0,将q
0,2
,q
1,2
作为变量,在-3db下分别画出m=1和m=20时损失函数的等高线图如图4所示;
[0069]
由图4可见,当m=1时,损失函数收敛于(0,0.6),此时q
0,2
将被判为0,q
1,2
将被判为1,而实际上q
0,2
与q
1,2
均为1;当m=20时,损失函数将收敛于(1,1),此时q
0,2
与q
1,2
均会被判为1,可见多帧机制对识别性能的改善。
[0070]
综上所述,本发明解决了现有方法在中低信噪比以及当卷积码约束长度增加时识别性能变差的问题,且时间复杂度更低。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。