1.本发明涉及脑成像基因组学领域技术领域,特别涉及了一种基于脑成像基因组特征的阿尔兹海默症识别方法。
背景技术:
2.阿尔兹海默式症(ad)是一种不可逆的神经退行性疾病,患者大脑随着病程的发展出现一定的脑萎缩情况,并且随着年龄的增长而隐藏恶化。临床表现为一系列精神和认知障碍,包括记忆力下降、行为改变,影响人们的正常生活能力。轻度认知功能障碍(mci)是介于正常和痴呆之间的状态,可以认为是ad的早期阶段。正常人随着年龄增长出现的大脑正常老化与早期患者的脑萎缩在数据空间中存在一定的重叠现象,这给疾病的早期诊断带来了困难。我们需要解决的问题是从细微的变化中精确的辨识出早期mci患者与正常对照者,在认知障碍阶段尽早识别、尽早采取干预措施。
3.脑成像基因组学是一个新兴的研究领域。通过影像基因水平的脑结构、功能和脑网络组的研究方法,可以发现阿尔兹海默症所对应的特定遗传学标记。脑成像基因组学在研究阿尔兹海默症的发病机制和挖掘高风险生物标志方面取得了重大进展。例如apoe,clu,picalm和cr1等位点被确定与阿尔兹海默症有关。目前使用影像学材料在阿尔兹海默症和健康对照者之间的识别准确率基本都可达到90%以上。如中国专利局2020年6月5日公开了一种名称为一种基于融合网络的阿尔兹海默病分类方法的发明,其公开号为cn111242233a,该发明包括以下步骤:1、给定被试的磁共振图像数据集,进行预处理;2、将样本划分训练集和测试集,进行图像扩增、归一化操作;3、将训练集输入训练网络;4、对样本进行特征提取及特征融合;5、对各基网络的分类决策和特征融合的分类决策进行融合;6、对输出标签进行误差计算,并通过反向传播进行参数更新;7、对分类模型评估并获得最优模型,重复第3-7步直至迭代结束;8、训练完成的最优模型,输入通过预处理的被试磁共振影像数据,得到被试的标签。该发明使用了行卷积神经网络,实现了有效使用被试的磁共振影像数据进行阿尔兹海默病分类的方法,具有较好的鲁棒性。但该发明仅使用了磁共振成像数据,未使用遗传信息,在早期诊断上还存在着局限性。
4.相较于阿尔兹海默症患者的识别,早期认知障碍患者的识别准确率相对较低。这是因为患者早期认知障碍阶段的脑萎缩情况是细微且难以发现的,并且健康人大脑的正常老化也存在一定的脑萎缩,它们在数据空间中可能存在重叠现象,大大增加了识别的难度。为此,我们使用基因和影像特征对阿尔兹海默症进行分类,希望通过添加基因特征来提高早期诊断的精确度。
技术实现要素:
5.本发明的目的是克服现有技术中存在的问题,提供了一种基于脑成像基因组特征的阿尔兹海默症识别方法,通过在特征选择阶段添加合理的约束来共同学习,将所选特征与学习所得特征进行元素乘积,作为分类决策中的高风险特征,充分利用基因特征的前沿
性以此提高早期识别精确度。
6.为了实现上述目的,本发明采用以下技术方案:一种基于脑成像基因组特征的阿尔兹海默症识别方法,其特征在于,它包括下列步骤:
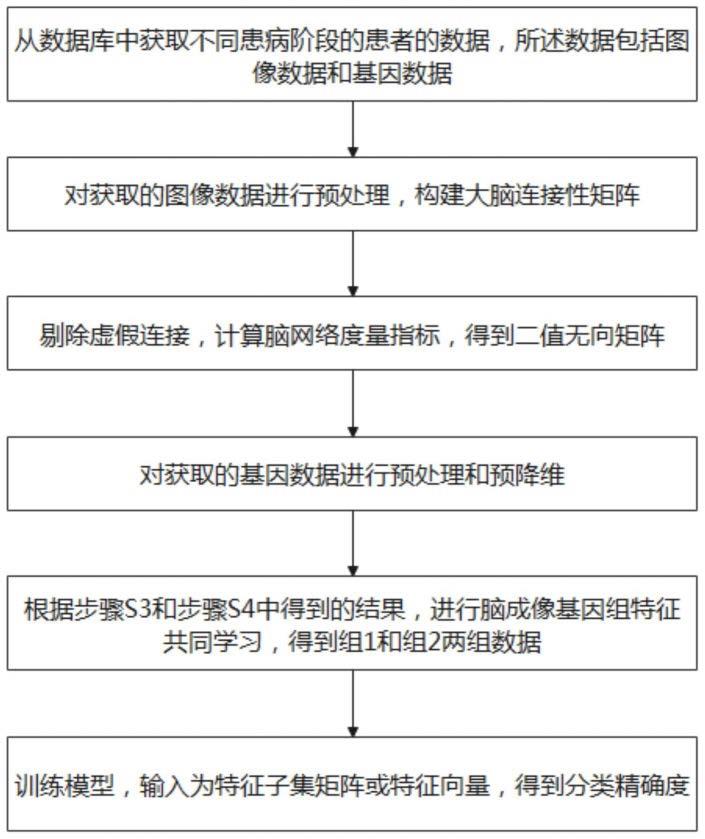
7.s1:从数据库中获取不同患病阶段的患者的数据,所述数据包括图像数据和基因数据;
8.s2:对获取的图像数据进行预处理,构建大脑连接性矩阵;
9.s3:剔除虚假连接,计算脑网络度量指标,得到二值无向矩阵;
10.s4:对获取的基因数据进行预处理和预降维;
11.s5:根据步骤s3和步骤s4中得到的结果,进行脑成像基因组特征共同学习,得到组1和组2两组数据;
12.s6:训练模型,输入为特征子集矩阵或特征向量,得到分类精确度。
13.研究表明基因与患者大脑变异之间存在一定的相关性,本发明通过在特征选择阶段添加合理的约束来共同学习,将所选特征与学习所得特征进行元素乘积,作为分类决策中的高风险特征。所选高风险特征有望成为临床诊断的依据,可以提高早期诊断的精确度。
14.作为优选,所述的步骤s1中,不同患病阶段的患者包括早期认知功能障碍换准则、晚期认知功能障碍患者以及阿尔兹海默症患者,还包括健康对照者;获取的图像数据包括相同年龄时测量的结构磁共振成像数据以及功能磁共振成像数据;获取的基因数据为基因分型数据,获取的数据还包括通过临床医生诊断、主观心理学测评或简易精神量表得到的分类标签。
15.简易精神量表内容简练、测定时间短,容易被老人接受,是目前临床上最常见的量表。简易精神量表的得分与文化教育程度有关,如果文盲≤17分,小学程度≤20分,中学程度≤22分,大学程度≤23分,则说明存在认知功能损害。可以从adni公开数据库中获取相同年龄时测量的数据。
16.作为优选,所述的步骤s2中,对获取的图像数据进行预处理,构建大脑连接性矩阵:
17.s2.1:对得到的图像数据进行空间图像预处理,所述预处理包括失真校正和图像对齐;
18.s2.2:将处理后的图像数据投影到2mm的标准连接信息技术倡议(connectivity informatics technology initiative,cifti)空间中,图像数据包括皮质灰质表面顶点和皮质下灰质体素;
19.s2.3:通过联合人类连接组多模态脑区分割(joint human connectome project multi-modal parcellation,j-hcpmmp)对皮质表面和皮质下体积进行组合分析,将大脑分割成360个功能地区,得到360
×
360的大脑连接性矩阵。
20.首先进行空间图像预处理,包括失真矫正和图像对齐,使相对于受试者解剖空间的畸变最小,并使数据空间平滑。hcpmmp是一种现有技术,是美国华盛顿大学圣路易斯校区科学家们在2016年提出的最新的脑分区方案,绘制出迄今为止最为详细的人类大脑皮层图谱。cifti是分区坐标空间,是hcpmmp分区方法所对应的几何坐标集合。
21.作为优选,所述的步骤3中,计算脑网络度量指标的具体步骤为:
22.s3.1:使用最强权重比例对大脑连接性矩阵进行去噪,即使全局成本效率参数最
大时对应的值:
23.max
psw
gce=e-psw
[0024][0025]
式中,psw表示最强权重比例,gce表示全局成本效率参数,e表示效率,d
ij
表示节点i和某一节点j之间的最短路径长度,n表示选定的指标数目,n表示节点集合;
[0026]
s3.2:对于单个网络度量形成一个360
×
1的向量,计算度量指标;
[0027]
s3.3:利用选择的度量指标分别对大脑分割的每个功能地区进行分析,得到360
×
n的特征矩阵,其中n为所选的指标数目。
[0028]
脑网络节点是根据分区数据划分的,而节点之间的连接边是借助分区之间的fmri时间序列维度上的相关系数得到的。在连接权重薄弱的的地方,可能出现虚假连接。为了提高数据精度,使用最强权重比例对矩阵进行去噪。对于单个网络度量形成一个360
×
1的向量,代表来自大脑皮层相应功能区域的特征值。优选通过brain connectivity工具箱计算度量指标,得到360
×
n的特征矩阵。
[0029]
作为优选,所述的步骤s3.3中,利用选择的度量指标分别对大脑分割的每个功能地区进行分析:选择6种区域性指标和1种全局指标分别对大脑分割的每个功能地区进行分析,得到360
×
7个特征,所述的6种区域性指标为:节点强度s、介数中心性bc、局部效率le、网络k核、特征向量中心ec以及流量系数fc,所述的1种全局指标为节点的聚类系数cc。
[0030]
根据以往研究表明,分类预测时区域性指标比全局性指标在敏感性和显著性上更加优越,所以选择6种区域性指标以及1种全局指标对大脑的之前划分的每个功能地区进行分析。
[0031]
作为优选,利用6种区域性指标和1种全局指标分别对大脑的每个脑区进行分析,得到360
×
7个特征:
[0032]
a1:利用节点强度s表示与脑网络中其他连通节点的权值之和:
[0033]
s(i)=∑
j∈nmij
[0034]
式中,m
ij
表示二值无向矩阵即样本矩阵中(i,j)处的值;
[0035]
a2:利用介数中心性表示遵循最短路径要求计算的评价指标:
[0036][0037]
式中,vg表示脑网络中所有节点的集合,v是需要计算的节点,u,v是不包括v的任意两个节点,σ(u,w)表示节点u,w之间的最短路径,σ(u,v,w)表示三者共同连接的最短路径;
[0038]
a3:利用局部效率表示所有节点间最短路径长度的反比:
[0039][0040]
式中,d
ij
表示节点i和某一节点j之间的最短路径长度;
[0041]
a4:利用网络k核表示脑网络种节点的最大子集,该节点在k核内,则该节点网络k
核值就为k;
[0042]
a5:利用特征向量中心表示脑网络中节点和其他节点的链接前度关系,假设a是数据矩阵,将节点i的特征向量中心度xi定义为归一化特征向量中属于a的最大特征值的第i个条目节点:
[0043]
ax=x或者
[0044]
式中,λ表示特征值,a
ij
表示矩阵a(i,j)处的值;
[0045]
a6:流量系数作用于局部脑网络,与节点的聚类系数有数学关系:
[0046]
fc cc≤1;
[0047]
a7:利用聚类系数表示脑网络的整体连通性,表示一个一个节点上连接多个节点时对应的系数:
[0048][0049]
d=ki=∑
j∈naij
;
[0050][0051]
式中,i、j、z代表脑网路中的三个节点,a代表三个节点在网络中的连接情况(1通常,0阻塞),ti代表与顶点i成三角形结构的节点联通状态下的几何平均值,ki表示与节点i有连接的节点的边数,ci表示节点i的聚类系数,ci=0,ki《2。
[0052]
作为优选,所述的步骤s4中,对获取的基因数据进行预处理和预降维的具体步骤为:
[0053]
s4.1:对基因分型得到的数据进行质量控制,所述质量控制包括检出率、性别检查、次要等位基因频率、平衡测试、兄弟姐妹配对识别以及群体检测;
[0054]
s4.2:对基因数据进行预降维,删除冗余、不相关特征,使其维度与影像特征在相同的等量级。
[0055]
相较于影像特征,基因数据是非常庞大的,直接用于学习可能会对结果产生不良影响。为了降低计算成本和提高分类精度,需要对基因数据进行预降维删除冗余、不相关特征,使其维度与影像特征在相同的等量级。
[0056]
作为优选,所述的步骤s4.2中,删除冗余、不相关特征的具体步骤为:
[0057]
利用fisher score算法寻找特征子集:假设数据集中有c个类,定义第i个特征的类间散度sb(xi)和第k类样本的第i个特征的类间散度s
t
(xi)为:
[0058][0059][0060]
式中,nk为第k类的样本数目,ui是整体样本第i个特征的均值,是第k类样本第i
个特征的均值,是第k类样本中第j个样本第i个特征的取值;当使类间散度尽量大类内散度尽量小,得到第i个特征的fisher范数表达如公式:
[0061][0062]
fisher score是一种有效的特征选择方法,具有计算简单、节约时间、准确性高的优点,主要思想是根据fisher线性判别寻找特征子集,使得所选特征在数据空间中,不同类的数据点之间的距离尽可能大,而同一类中的数据点之间的距离尽可能小。
[0063]
作为优选,所述的步骤s5中,进行脑成像基因组特征共同学习:
[0064]
s5.1:根据最小二乘法,定义损失函数如式:
[0065][0066]
式中,w表示权重系数矩阵,x表示数据矩阵,y表示标签向量,f表示frobenius范数;
[0067]
s5.2:添加群体稀疏性l2,1范数,将跨任务特征耦合在一起进行联合特征选择,最终得到损失函数如式:
[0068][0069]
式中,r1和r2表示正则化参数;
[0070]
对w求导并令其等于零,得到:
[0071]
w=(xx r1d1 r2d2)-1
xy
[0072]
式中,d1是以第k个对角块为的块对角矩阵,d2是以第k个对角块为的块对角矩阵。
[0073]
l2范数的平方作为损失函数时对较小的异常值不敏感,对较大的异常值敏感,而l1范数作为损失函数则恰恰相反。添加群体稀疏性l
2,1
范数将跨任务特征耦合在一起进行联合特征选择。我们将每个度量指标看作一组,一共1 7=8组,通过group1(g1)范数在组间使用l1范数,在组内使用l2范数,加强不同组的稀疏性。最终得到损失函数。
[0074]
作为优选,所述的步骤s6中,利用支持向量机训练模型。
[0075]
支持向量机(svm)是一种二元分类模型,可以寻找用于分割样本的超平面,并且在小样本数据集上有较强的鲁棒性。数据特征的维度高,样本量少,是一个线性可分问题,故选用支持向量机进行训练。
[0076]
因此,本发明具有如下有益效果:通过计算不同程度患者以及健康对照者的脑网络度量,并通过质量控制、基因数据预降维等选出与影像数据相同数量级的候选基因子集,最后通过迭代优化损失函数求解高风险特征用于分类,引入基因型数据进行分类,提高早期诊断的精确度。
附图说明
[0077]
图1为本发明方法的具体操作流程图。
具体实施方式
[0078]
下面结合附图与具体实施方式对本发明作进一步详细描述:
[0079]
如图1所示的实施例中,可以看到一种基于脑成像基因组特征的阿尔兹海默症识别方法,其操作流程为:步骤一,从数据库中获取不同患病阶段的患者的数据,所述数据包括图像数据和基因数据;步骤二,对获取的图像数据进行预处理,构建大脑连接性矩阵;步骤三,剔除虚假连接,计算脑网络度量指标,得到二值无向矩阵;步骤四,对获取的基因数据进行预处理和预降维;步骤五,根据步骤三和步骤四中得到的结果,进行脑成像基因组特征共同学习;步骤六,训练模型,输入为特征子集矩阵或特征向量,得到分类精确度。通过在特征选择阶段添加合理的约束来共同学习,将所选特征与学习所得特征进行元素乘积,作为分类决策中的高风险特征。所选高风险特征有望成为临床诊断的依据,提高早期诊断的精确度。
[0080]
下面继续通过具体的例子,进一步说明本发明的技术方案和技术效果,是对本发明的解释而本发明并不局限于以下实例。故凡依照本专利范围所述的原理等做的阿尔兹海默症识别方法,均应包括于本专利申请范围内。
[0081]
第一步:从数据库中获取不同患病阶段的患者的数据
[0082]
本实施例可以从adni公开数据库中获取相同年龄时测量的结构磁共振成像数据(smri)、功能磁共振成像(fmri)数据以及基因分型数据,以及通过临床医生诊断及主观心理学测评分数(如简易精神量表)等得到的分类标签。通过在adni公开数据库中检索,从adni2/go中获得共120名受试者影像基因组信息,其中包括健康对照者26名、早期认知功能障碍患者45名、晚期认知功能障碍患者25名以及阿尔兹海默症患者24名。受试者人数120只是本实施例中的人数,不代表只能为120。
[0083]
第二步:对获取的图像数据进行预处理,构建大脑连接性矩阵
[0084]
首先进行空间图像预处理,包括失真矫正和图像对齐等,使相对于受试者解剖空间的畸变最小,并使数据空间平滑。然后将图像数据投影到2mm的标准cifti空间中,其中图像数据包括皮质灰质表面顶点和皮质下灰质体素。最后通过j-hcpmmp对皮质表面和皮质下体积进行组合分析,将大脑分割成360个功能地区,得到360
×
360的矩阵。
[0085]
第三步:计算脑网络度量指标
[0086]
脑网络节点是根据分区数据划分的,而节点之间的连接边是借助分区之间的fmri时间序列维度上的相关系数得到的。在连接权重薄弱的的地方,可能出现虚假连接。为了提高数据精度,使用最强权重比例(proportion of the strongest weights,psw)对矩阵进行去噪,即使全局成本效率参数(global cost efficiency,gce)最大时对应的值,公式为:
[0087]
max
psw
gce=e-psw
[0088][0089]
式中,psw表示最强权重比例,gce表示全局成本效率参数,e表示效率,d
ij
表示节点i和某一节点j之间的最短路径长度,n表示选定的指标数目,n表示节点集合。
[0090]
对于单个网络度量形成一个360
×
1的向量,代表来自大脑皮层相应功能区域的特征值。本实施例通过brain connectivity工具箱计算度量指标,得到360
×
n的特征矩阵,其
中n为所选的指标数目。
[0091]
根据以往研究表明,分类预测时区域性指标比全局性指标在敏感性和显著性上更加优越,因此选择6种区域性指标以及1种全局指标对大脑的每个脑区进行分析,得到360
×
7=2520个特征,如下所示:
[0092]
a1:利用节点强度s表示与脑网络中其他连通节点的权值之和:
[0093]
s(i)=∑
j∈nmij
[0094]
式中,m
ij
表示二值无向矩阵即样本矩阵中(i,j)处的值;
[0095]
a2:利用介数中心性表示遵循最短路径要求计算的评价指标:
[0096][0097]
式中,vg表示脑网络中所有节点的集合,v是需要计算的节点,u,v是不包括v的任意两个节点,σ(u,w)表示节点u,w之间的最短路径,σ(u,v,w)表示三者共同连接的最短路径;
[0098]
a3:利用局部效率表示所有节点间最短路径长度的反比:
[0099][0100]
式中,d
ij
表示节点i和某一节点j之间的最短路径长度;
[0101]
a4:利用网络k核表示脑网络种节点的最大子集,该节点在k核内,则该节点网络k核值就为k;
[0102]
a5:利用特征向量中心表示脑网络中节点和其他节点的链接前度关系,假设a是数据矩阵,将节点i的特征向量中心度xi定义为归一化特征向量中属于a的最大特征值的第i个条目节点:
[0103]
ax=x或者
[0104]
式中,λ表示特征值,a
ij
表示矩阵a(i,j)处的值;
[0105]
a6:流量系数作用于局部脑网络,与节点的聚类系数有数学关系:
[0106]
fc cc≤1;
[0107]
a7:利用聚类系数表示脑网络的整体连通性,表示一个一个节点上连接多个节点时对应的系数:
[0108][0109]
d=ki=∑
j∈naij
;
[0110][0111]
式中,i、j、z代表脑网路中的三个节点,a代表三个节点在网络中的连接情况(1通常,0阻塞),ti代表与顶点i成三角形结构的节点联通状态下的几何平均值,ki表示与节点i
有连接的节点的边数,ci表示节点i的聚类系数,ci=0,ki《2。
[0112]
第四步:对获取的基因数据进行预处理和预降维
[0113]
对基因分型得到的数据进行了质量控制,包括:检出率、性别检查、次要等位基因频率maf、平衡测试、兄弟姐妹配对识别以及群体检测,其中maf≥0.05。
[0114]
相较于影像特征,基因数据是非常庞大的,直接用于学习可能会对结果产生不良影响。为了降低计算成本和提高分类精度,对基因数据进行预降维删除冗余、不相关特征,使其维度与影像特征在相同的等量级。
[0115]
fisher score是一种有效的特征选择方法,具有计算简单、节约时间、准确性高的优点,主要思想是根据fisher线性判别寻找特征子集,使得所选特征在数据空间中,不同类的数据点之间的距离尽可能大,而同一类中的数据点之间的距离尽可能小。
[0116]
假设数据集中有c个类,定义第i个特征的类间散度sb(xi)和第k类样本的第i个特征的类间散度s
t
(xi)为:
[0117][0118][0119]
式中,nk为第k类的样本数目,ui是整体样本第i个特征的均值,是第k类样本第i个特征的均值,是第k类样本中第j个样本第i个特征的取值;当使类间散度尽量大类内散度尽量小,得到第i个特征的fisher分数表达如公式:
[0120][0121]
第五步:脑成像基因组特征共同学习
[0122]
根据最小二乘法,定义损失函数如式:
[0123][0124]
式中,w表示权重系数矩阵,x表示数据矩阵,y表示标签向量,f表示frobenius范数。
[0125]
l2范数的平方作为损失函数时对较小的异常值不敏感,对较大的异常值敏感,而l1范数作为损失函数则恰恰相反。添加群体稀疏性l2,1范数将跨任务特征耦合在一起进行联合特征选择。我们将每个度量指标看作一组,一共1 7=8组,通过g1范数在组间使用l1范数,在组内使用l2范数,加强不同组的稀疏性。最终得到损失函数如下:
[0126][0127]
步骤s4中得到的第i个特征的fisher分数表达是二次问题,故极值点就是最值点,对w求导并另其等于0,得到:
[0128]
w=(xx r1d1 r2d2)-1
xy
[0129]
式中,d1是以第k个对角块为的块对角矩阵,d2是以第k个对角块为
的块对角矩阵。
[0130]
第六步:分类与预测
[0131]
利用支持向量机训练模型,输入为特征子集矩阵或特征向量,得到分类精确度。
[0132]
支持向量机(svm)是一种二元分类模型,可以寻找用于分割样本的超平面,并且在小样本数据集上有较强的鲁棒性。数据特征的维度高,样本量少,是一个线性可分问题,故选用支持向量机进行训练。
[0133]
本发明通过计算不同程度患者以及健康对照者的脑网络度量,并通过质量控制、基因数据预降维等选出与影像数据相同数量级的候选基因子集,最后通过迭代优化损失函数求解高风险特征用于分类。所选高风险特征可以成为临床诊断的依据,有利于提高早期诊断的精确度。
[0134]
以上所述的实施例只是本发明的一种较佳的方案,并非对本发明作任何形式上的限制,在不超出权利要求所记载的技术方案的前提下还有其它的变体及改型。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。