1.本发明属于数据挖掘和语音识别技术领域,具体涉及一种基于爬虫的弹幕播报分析方法。
背景技术:
2.弹幕指直接显现在视频上的评论,是观看视频的人发送的简短评论。然而目前在进行游戏直播、手机直播或者虚拟主播直播的时候,由于弹幕播放比较迅速,主播无法高效的参与弹幕互动。另外由于现有方法为对直播中的数据流进行统计,无法根据直播时的用户舆情去优化直播策略。
技术实现要素:
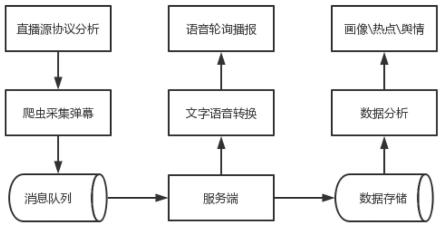
3.针对目前直播中的数据流无法进行统计,无法根据直播时的用户舆情去优化直播策略的缺陷和问题,本发明提供一种基于爬虫的弹幕播报分析方法。本发明解决其技术问题所采用的方案是:一种基于爬虫的弹幕播报分析方法,其特征在于:包括以下步骤:步骤一、选择直播平台,准备抓包工具,打开平台网页或app向直播源发起请求,查看弹幕数据的响应内容,从数据包提取出消息传输协议类型;步骤二、通过爬虫采集弹幕并将数据推送至消息列队;步骤三、本地轮询接收消息队列数据并进行语音转换和存储;步骤四、按需读取文件并进行语音播报;步骤五、提取出指定时间段的弹幕数据,通过数据挖掘算法对用户画像、直播热点以及舆情演化进行分析。
4.上述的基于爬虫的弹幕播报分析方法,步骤二中通过爬虫采集弹幕并将数据推送推送至消息列队,具体步骤为:(1)先创建一个消息队列接收和推送弹幕数据;(2)根据获得的数据包信息,通过编程语言构建出相同的请求报文;(3)通过编程语言的请求库向服务端发起模拟请求;(4)接收服务端返回的响应信息,构建解析规则从中提取出每一条弹幕文字信息;(5)将每一条弹幕推送到消息队列中,等待服务端接收。
5.上述的基于爬虫的弹幕播报分析方法,步骤(2)中所述编程语言为python语言、java语言、go语言的任一种,其中python语言可以使用requests请求库,java语言可以使用httpclient请求库,go语言可以使用req请求库。
6.上述的基于爬虫的弹幕播报分析方法,步骤三本地轮询接收消息队列数据并进行语音转换和存储的方法为:(1)在本地创建一个接收消息队列中数据的服务;(2)等待消息队列推送数据,对接收到的弹幕数据进行清洗并标注上当前时间戳,
标注后的数据存储到数据库中等待后续分析;(3)把每一条弹幕信息分别进行文字语音转换;(4)根据标注的时间戳按序生成本地语音文件。
7.上述的基于爬虫的弹幕播报分析方法,步骤(2)中对弹幕数据进行清洗是根据自定义的风险词典,过滤掉包含风险词汇的弹幕;同时根据清洗规则过滤掉一些噪音数据。
8.上述的基于爬虫的弹幕播报分析方法,步骤(2)中对弹幕数据进行标注是根据消息队列的推送时间对弹幕信息进行标注,以时间戳为标注信息。
9.上述的基于爬虫的弹幕播报分析方法,步骤四中读取文件并进行语音播报的规则是:当语音目录不为空或者每当有语音文件生成时扫描本地语音文件,根据标注的顺序播放语音文件,播放后根据标注对播报后的语音文件进行删除。
10.上述的基于爬虫的弹幕播报分析方法,步骤五中通过词频统计和分组统计分析用户画像和直播热点;其中词频统计方法为:先通过jieba进行文本分词,然后通过文本遍历提取出现次数较多的词汇,最后通过 tf/idf算法计算出现次数较多词汇的词频,式中:kw为待计算词频的词汇;wn为某段直播弹幕中kw出现的次数;wa为某段直播弹幕的总词数;da为总直播数;zn为出现kw的直播数;wf为词频;分组统计方法为:根据时间戳对每分钟内的弹幕数量进行分组统计,统计出数量最多的分组中出现的弹幕词汇,然后将其和词频统计中计算的词汇和词频进行匹配,得出直播中的热点词汇即为直播热点。
11.上述的基于爬虫的弹幕播报分析方法,步骤五中通过adaboost算法对每条弹幕进行情绪分类,将情绪分类结果按照时间形成时间序列来直观的查看在不同时间节点中用户对直播状态的舆情演化,然后通过lstm模型进行时间序列预测,预测下段直播中舆情演化趋势较大的时间段,根据预测结果可让从业人员提前制定运行策略和优化直播效果。
12.本发明的有益效果:本发明的基于爬虫的弹幕播报方法,首先通过分析直播协议,通过爬虫采集弹幕,解析出每一条弹幕数据,当本地服务接受到弹幕后进行数据清洗和过滤,然后通过语音合成引擎将文字转为语音播放出来,一方面减少了直播弹幕中的无用信息和风险信息,提高用户信息获取效率;另一方面可以让主播脱离屏幕的同时掌握弹幕情况,提高直播交互性和趣味性;另一方面通过分析直播弹幕数据,提取出用户画像、直播热点和舆情演化,来帮助从业人员提高直播内容和运营策略的优化。
附图说明
13.图1为本发明整体流程图。
14.图2为对直播源的弹幕消息传输协议分析流程图。
15.图3为弹幕采集及推送流程图。
16.图4为数据转换及存储流程图。
17.图5为语音读取及播报流程图。
18.图6为存储数据分析流程图。
具体实施方式
19.下面结合附图和实施例对本发明进一步说明。
20.实施例1:本实施例提供一种基于爬虫的弹幕播报分析方法,参见图1,该方法包括以下步骤:步骤一、分析直播源的弹幕消息传输协议:目前常见的消息传输协议有http/https和ws/wss两种,但是每个直播平台的传输协议都不相同,所以需要先确定直播平台,然后抓包分析传输协议。具体参见图2,1、选择直播平台,任何现有平台都可以,比如斗鱼、虎牙、抖音、快手、bilibili等。
21.2、准备抓包工具,任何抓包工具都可以,比如charles、fiddler、wireshark等。
22.3、打开平台网页或app向直播源发起请求,查看弹幕数据的响应内容,从数据包提取出消息传输协议类型。
23.步骤二、通过爬虫采集弹幕并将数据推送至消息列队,参见图3,具体步骤为:1、先创建一个消息队列,比如redis或rabbitmq,用于接收和推送弹幕数据;2、根据获得的数据包信息,通过编程语言构建出相同的请求报文;3、通过编程语言的请求库向服务端发起模拟请求;所述编程语言为python语言、java语言、go语言的任一种,其中python语言可以使用requests请求库,java语言可以使用httpclient请求库,go语言可以使用req请求库。
24.4、接收服务端返回的响应信息,构建解析规则从中提取出每一条弹幕文字信息;5、将每一条弹幕推送到消息队列中,等待服务端接收。
25.步骤三、本地轮询接收消息队列数据并进行语音转换和存储,参见图4,具体为:1、在本地创建一个接收消息队列中数据的服务。
26.2、等待消息队列推送数据,对接收到的弹幕数据进行清洗并标注上当前时间戳,标注后的数据存储到数据库中等待后续分析。
27.其中数据清洗是根据自定义的风险词典,过滤掉包含风险词汇的弹幕;同时根据清洗规则过滤掉一些噪音数据;而标注则是根据消息队列的推送时间对弹幕信息进行标注,以时间戳为标注信息。
28.3、把每一条弹幕信息分别进行文字语音转换,可以通过sapi5、deepspeech2、wav2letter等语音识别引擎将文字转为语音;4、根据标注的时间戳按序生成本地语音文件。
29.步骤四、按需读取文件并进行语音播报,具体如图5所示:1、当语音目录不为空或者每当有语音文件生成时扫描本地语音文件,根据步骤三中标注的顺序播放语音文件;2、播放后根据标注对播报后的语音文件进行删除;3、再次执行1,重新扫描本地语音文件。
30.步骤五、通过数据挖掘算法对存储数据进行分析,具体如图6所示。
31.1、提取出指定时间段的弹幕数据;2、通过词频统计和分组统计分析用户画像和直播热点;其中词频统计具体方法为:先通过jieba进行文本分词,然后通过文本遍历提取出现次数较多的词汇,最后通过 tf/idf算法计算出现次数较多词汇的词频。词频越高和直播
内容的相关性越高,也越能突出用户喜好和热点信息。
32.其中直播弹幕词频计算公式为:式中:kw为待计算词频的词汇;wn为某段直播弹幕中kw出现的次数;wa为某段直播弹幕的总词数;da为总直播数;zn为出现kw的直播数;wf为词频。
33.分组统计具体方法为:根据时间戳对每分钟内的弹幕数量进行分组统计,统计出数量最多的分组中出现的弹幕词汇,然后将其和词频统计中计算的词汇和词频进行匹配,得出直播中的热点词汇,即直播热点。
34.3、舆情演化分析(1)通过adaboost算法对每条弹幕进行情绪分类,根据直播特征归为like(喜欢)、hate(厌恶)、sorrow(悲伤)、quiet(宁静)四类情绪;(2)将情绪分类结果按照时间形成时间序列,时间序列可以直观的查看到在不同时间节点中用户对直播状态的舆情演化。
35.(3)通过lstm模型进行时间序列预测,预测下段直播中舆情演化趋势较大的时间段,根据预测结果可让从业人员提前制定运行策略和优化直播效果。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。