1.本发明涉及一种控制器,可用于例如控制水处理装置或造纸机等。
背景技术:
2.当今,机器学习算法被应用于控制器,以使控制器的设置比以前更容易。机器学习为系统提供了自动学习的能力,也可以在没有明确编程的情况下从经验中进行改进。因此,计算机系统使用机器学习(ml)实用算法和统计模型来执行一个或多个特定的任务,而不使用显式指令。目前有几种ml算法。这里只介绍其中的部分:线性回归算法、逻辑回归算法、k均值算法、前馈神经网络算法等。
3.例如,机器学习算法被用于分析多变量测量,如在造纸处理中。由于很难解释ml算法是如何得到预测的,解释值用于帮助用户评估每个输入参数对ml算法的预测结果的贡献。因此,解释值用于解释ml算法是如何得到特定结果,也用于对处理的工作方式进行分类。解释值通过使用例如shap(shapley加性解释,shapley additive explanations)值、lime法或deeplift法来获得。
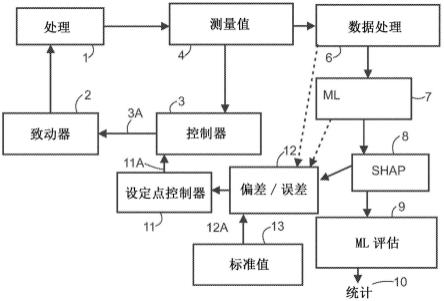
4.图1示出了已知的控制装置的示例,其中处理1由致动器2驱动,致动器2由控制器3控制。测量值4取自该处理,并用作针对控制器的反馈数据。控制器3将测量值与一个或多个设定值5进行比较,并形成针对致动器的一个或多个控制命令。
5.测量值4也可以用于其他目的,在这种情况下,在实际使用测量数据之前对其进行预处理6是方便的。预处理例如可以包括数据合并、对齐时间格式、修改元数据、数据验证等。在图1的示例中,机器学习(ml)7用于提取大型数据集中的信息和模式。机器学习算法通常基于统计模型,计算机可以使用统计模型来执行特定的任务,而不需要精确的指令,而是依赖于识别模式。通过基于训练数据集建立数学模型,可以得到识别的模式。可以通过向数学模型馈送新的数据进行预测(模拟)和模式识别。ml算法的输出可以用作输入信息以按照软传感器值(处理值的预测)的形式改变对于控制器3的设定点。
6.因为很难从ml的输出(预测/模拟)中看到处理中发生了什么,所以解释值8(如图1实施例中的shap值)用于跟踪ml预测如何链接回输入变量。对于每个预测,为每个输入变量计算评级数,指示该变量对最终预测做出贡献的程度。这些评级数可以被视为解释值,指示输入值在给定时间点的重要性。
7.解释值用于验证ml算法和ml模型的工作方式9。从解释值比从ml预测更容易做到这一点。因此,如果ml模型不能恰当工作,则可以更改ml模型。例如,解释值还可以用于更新统计数据10。
8.尽管解释值目前用于帮助分析系统(如具有多变量测量的系统),但在控制一个或多个致动器时,没有自动利用解释值的方法。
技术实现要素:
9.本发明的目的是提供一种控制装置,其中控制器被配置为自动地利用解释值来驱
动致动器。该目的以独立权利要求书中描述的方式实现。从属权利要求说明了本发明的不同实施方式。
10.根据本发明的控制装置具有控制器,该控制器被配置为驱动致动器。该控制装置还包括设定点控制器,设定点控制器被配置为利用机器学习的解释值和机器学习的标准解释值(normal explanation value)之间的偏差。设定点控制器形成针对控制器的设定点值。机器学习的解释值和机器学习的标准解释值例如是shap值、来自lime方法的值、来自deeplift方法的值或任何其他可能的解释值。
附图说明
11.在下面,通过参考所附附图更详细地描述本发明,其中
12.图1示出了现有技术控制装置的示例,
13.图2示出了根据本发明的控制装置的示例,
14.图3示出了根据本发明的设定点控制器的示例,
15.图4示出了根据本发明的设定点控制器的另一示例,
16.图5示出了一个le或模糊映射的示例,
17.图6示出了le或模糊映射的其他示例,以及
18.图7示出了根据本发明的设定点控制器的又一示例。
具体实施方式
19.图2示出了根据本发明的控制装置的示例。该控制装置具有控制器3,该控制器被配置为驱动致动器2。此外,控制装置包括设定点控制器11,设定点控制器11被配置为利用机器学习7的解释值8和机器学习的标准解释值13之间的偏差12。设定点控制器11形成用于控制器的设定点值11a。图2还示出了其他可能的实施方式,其中偏差误差不仅基于解释值,而且可以包括测量数据和/或ml算法预测。在这些其它实施例中,标准值模块13还具有测量数据的标准值和/或ml值的标准值,并且偏差计算模块12计算在实施方式中使用的所有偏差。
20.因此,设定点控制器11可以利用解释值的偏差,但是除了这些值之外,测量数据的偏差和/或ml值的偏差也可以用于形成设定点值。所有这些偏差都可以从处理1的正常运行时段中获得。可以看出,利用预处理的测量数据是方便的,因为至少可以滤除一些测量噪声和其他缺陷。
21.机器学习的解释值和机器学习的标准解释值例如是shap值、来自lime方法的值、来自deeplift方法的值或任何其他可能的解释值。
22.lime方法解释单个模型预测,基于给定预测周围的模型的局部近似。lime将简化的输入x称为可解释的输入。映射x=h
x
(x)将可解释输入的二进制向量转换到原始输入空间。不同类型的h
x
映射用于不同的输入空间。
23.deeplift是一种递归预测解释方法。它为每个输入xi赋予一个值c
δxiδy
,该值表示将输入设置为与其原始值相反的参考值的影响。这意味着deeplift映射x=h
x
(x)将二进制值转换为原始输入,其中1表示输入取其原始值,0表示它取参考值。参考值表示特征的典型的无信息背景值。
24.shap(shapley additive explanation)解释值赋予每个特征当条件化该特征时预期模型预测的变化。这些值解释了如果不知道当前输出f(x)的任何特征,如何从一个基值中得到一个将被预测的预期e[f(z)]。在预期中添加特性的顺序很重要。但是,在shap值中考虑到了这一点。
[0025]
图2还示出(与图1相同)由致动器2驱动的处理1,该致动器由控制器3控制。测量值4取自该处理,控制器将测量值与一个或多个设定值11a进行比较,并形成针对致动器2的一个或多个控制命令3a。该处理可包括几个处理,因此作为一个整体,它可以是一起运行的处理的组合。
[0026]
如上所述,测量值4也可用于其他目的,并且可被预处理6。预处理例如可以包括数据合并、对齐时间格式、修改元数据、数据验证等。在图2的示例中,机器学习7用于提取大型数据集中的信息和模式。通过基于训练数据集建立数学模型,可以得到识别的模式。预测(模拟)和模式识别可以通过向数学模型提供新的数据来进行。
[0027]
解释值8(如shap值)用于跟踪ml预测如何链接回输入变量。对于每个预测,为每个输入变量计算评级数,表明该变量对最终预测做出贡献的程度。这些评级数是解释值,表明输入值在给定时间点的重要性。
[0028]
可以注意到,标准解释值和来自当前ml预测/估计的解释值之间的偏差/误差被计算12。标准解释值可以是从处理的正常运行时段中找到的存储库值。因此,标准解释值已经从控制装置所控制的处理的正常运行时段中推导出来。例如,标准值可以导出为这些正常时段的简单值或中值。处理的正常运行发生在处理或组合处理正常运行的时间段。因此,对于所有数据(预处理、ml预测和ml解释值),可以(从存储的值中)给出或估计标准(最优)值。因此,可以有标准历史值库,在该库中,处理已被标识为最佳运行。
[0029]
因此,在单个或组合处理没有最佳运行的操作期间,从测量中检测到差异、偏差或误差。这些被检测为自标准值的发散。与标准值13的差值12a被用作对设定点控制器11的输入。尽管偏差计算模块12被示为单独的模块,但它也可能作为设定点控制器11的一部分属于设定点控制器11。一般说来,偏差与误差有关。误差的巨大程度表明需要改变设定点或设定点应该改变多少。
[0030]
图3示出了设定点控制器11的示例,其使用偏差/误差12a(图2)。图3的示例显示了针对两个变量的两个误差值14、15,但是如果需要,可以使用如图所示的更多的变量和误差值。因此,至少一个误差/偏差值在本发明的设定点控制器中是可用的。
[0031]
设定点控制器包括至少一个p模块16、16a,i模块17、17a、或d模块18、18a、或这些模块的任何组合。如上所述,偏差是输入到模块中的数据。设定点控制器还包括用于模块的每个输出22、23、24、22a、23a、24a的一个或多个输入映射模块19、20、21、19a、20a、21a。此外,设定点控制器包括:求和模块25,用于对一个或多个输入映射模块19、20、21、19a、20a、21a的一个或多个输出26、27、28、26a、27a、28a求和;以及输出缩放模块29,用于缩放求和模块的输出30。此外,设定点控制器包括:输出映射模块31,以提供归一化输出32;以及设定点调整模块33,利用归一化输出32以改变设定点值。值得提及的是,取决于实施方式,输出缩放模块可以给出正输出或负输出,并且模块30的映射曲线的形状确定改变,即,输出32。设定点调整模块33的输出是经调整的设定点34。调整后的设定值被用作控制器3的设定点11a。调整后的设定点也替换先前的设定点值35。可以看出,设定点调整模块33包括第二求
和模块,以便对归一化输出32和现有设定点值35求和。
[0032]
p、i和d模块16、16a、17、17a、18a及其组合pi、pd、id和pid是已知的,但是先前没有将解释值的偏差/误差用作输入。p模块16、16a具有与输入误差值相乘的加权系数。i模块包括积分器单元117、117a,其对某一时段的输入误差值进行积分。积分输入误差值与第二加权系数170、170a相乘。d模块包括微分器单元118、118a,其形成误差值在特定时段期间的导数。该导数乘以第三加权系数180、180a。可以看出,所有p、i和d模块及其组合都有一个加权系数单元。这些单元可以具有相同的加权系数,也可以具有不同的加权系数。加权系数使得可以对误差值的比例(p)、积分(i)和微分(d)部分的重要性进行加权,并且还可以通过增加或减少来自每个单个输入计算的贡献来调谐或微调设定点调整的性能。
[0033]
并不总是需要有所有的p、i和d模块,但如上所说,如果它们真的被使用和需要,它们可以在控制器中。在图3的实施例中,p、i和d模块一起提供误差值14和误差值15以及其他可能值的pid计算。注意,在另一实施方式中,仅一个误差值(如误差值14)就足以实现良好的设定点调整。
[0034]
图4显示了另一个可能的示例,其中不需要d模块,因此该示例的设定点控制器具有pi计算。如上所述,控制器可以仅具有设定点控制器的实施例的p、i、d、pi、pd、id或pid计算所需的那些模块。还值得一提的是,设定点控制器可能对不同的误差值有不同的计算。例如,图3的实施例可以修改为另一个解决方案,以便对误差值14进行pid计算,并且对另一个误差值15进行p计算(即,i模块17a和d模块18a已经被移除)。
[0035]
如上所述,设定点控制器还包括用于p、i和d模块的每个输出22、23、24、22a、23a、24a的输入映射模块19、20、21、19a、20a、21a。参见图3。输入映射将p、i或d模块的每个输出的结果转换为-2到2之间的值。这可以看作是值的归一化。输入映射由语言方程(le,linguistic equations)或模糊逻辑(fuzzy logic)形成。通过使用输入映射,可以方便地考虑非线性。因为在输入映射中考虑了处理的属性,所以设定点控制器的调谐也相对平滑。设定点控制器的映射模块可以单独地利用任何映射曲线。例如,在图3中,模块19和19a可以由le形成,或者一个模块19由le形成,另一个模块19a由模糊逻辑形成。
[0036]
图4还示出了其他可能的实施方式。除了基于解释值的偏差误差14之外,还可以使用ml偏差40。也可以使用测量数据的偏差,但图4中没有显示。如在图4中可以注意到的,对于ml偏差,还可以有p、i和d模块16b、17b,以及它们的组合pi、pd、id和pid,这在该实施方式中是必需的。图4的实施例示出了p模块16b和i模块17b(具有积分器单元117b和第二加权系数170b)的示例,它们具有到映射模块19b、20b的输出22b、23b。这些映射模块具有到求和模块25的输出26b、27b。
[0037]
图7示出了本发明实施方式的另一示例。图7的实施方式以与图4的实施方式类似的方式利用解释值的偏差14(如shap值)以及ml值的偏差40。此外,图7的实施方式还利用测量数据的偏差70。此外,对于测量数据偏差,还可以有该实施方式中所需的p、i和d模块16c、17c及其组合pi、pd、id和pid。图8的实施方式示出了p模块16c和i模块17c(具有积分器单元117c和第二加权系数170c)的示例,它们具有到映射模块19c、20c的输出22c、23c。这些映射模块具有到求和模块25的输出26c、27c。
[0038]
图5显示了映射曲线50的一个示例,它是由语言方程或模糊逻辑形成的。x是输入变量,它被转换成输出变量y。确定x和y的最大值和最小值。线性公式(如y=ax b)确定x之
间的y值,x出现在最大值和最小值之间。如果x大于最大x值,y是最大y。如果x小于最小x值,y是最小y。
[0039]
映射曲线也可以是线性曲线以外的另一条曲线。它可以是另一条曲线,更好地匹配处理的特征。图6显示了映射曲线的另外两个可能的示例。实线描述分段线性映射曲线60,虚线描述s曲线映射61。其他曲线也是可能的。因此,参考图3,映射模块可以单独使用任何映射曲线。例如,模块19和19a可以具有相同的映射曲线(如线性曲线),或不同的曲线(如不同的线性曲线,或分段线性曲线和s曲线)。
[0040]
一个或多个输入映射模块19、20、21、19a、20a、21a的一个或多个输出26、27、28、26a、27a、28a在求和模块25中求和。因此,所有的偏差/误差值都被考虑在内。然后,求和输出30被输出缩放模块29缩放,缩放后的和被输出映射模块31归一化,以便提供归一化输出32。设定点调整模块33使用归一化输出来改变设定点值。
[0041]
为了提供本发明的装置,知道所要控制的处理是有用的。正如所说,这个处理经常有许多变量被测量。通常不需要所有的测量用于控制处理的某种特性,因此选择用于特定控制的测量数据。参考图3和图4,为输入映射模块和输出映射模块选择输入和输出缩放(即,加权系数)以及曲线形式。选择了p、i、d参数和其他可能的模块。设定点控制器的所有单元/模块(p、i、d及其组合、加权系数、映射模块、求和模块)和偏差计算模块12、数据预处理模块6、ml模块7和解释值模块8可以作为软件或专用集成电路或作为软硬件组合来执行。具有标准值的模块13是存储器,其自然可以包括软件和硬件。
[0042]
根据本发明的用于控制工业处理的方法利用了本文中描述的控制装置。因此,该方法可以使用该控制装置对该处理中使用的一种或多种化学品进行投药。此外,通过本发明方法控制的处理(类似于工业处理)可以是制纸浆处理、造纸、制板或织造处理、工业水或废水处理处理、原水处理处理、水再利用处理、城市水或废水处理处理、污泥处理处理、采矿处理、油回收处理或任何其他工业处理。
[0043]
如上文所述,本发明提供了一种自动方式向控制处理1的控制器3提供设置输入。处理可以是工业处理,例如纸浆处理、造纸、制板或纸巾制造处理、工业水或废水处理处理、原水处理处理、水再利用处理、市政水或废水处理处理、污泥处理处理、采矿处理、石油回收处理或任何其他工业处理。
[0044]
该处理可以是例如水处理流程或造纸处理。该处理通常是多变量处理,因此需要进行大量的测量。为了理解ml算法是如何到达预测值,形成解释值来评估输入参数。还具有指示处理正常运行的标准解释值,可以形成解释值的偏差/误差值,并且它们可以用于向控制器3提供设定点命令。在实践中,可以有几个不同的致动器2和控制器3以驱动该处理。因此,本发明装置可以包括多于一个的控制器和设定点控制器,以及偏差计算模块。如以上示例所示,本发明实施例可以利用解释值的偏差、ml值的偏差和/或测量数据的偏差。
[0045]
本发明的装置可以位于与所遵照执行的处理相同的位置。然而,也有可能它部分地位于另一个地方,这使得远程控制处理成为可能。例如,测量数据4通过一个或多个通信网络发送到根据本发明的进一步处理,在该进一步处理中,测量数据被处理并且设定点调整被发送到控制器3。
[0046]
从上面可以明显看出,本发明不限于本文中描述的实施方式,而是可以利用独立权利要求书范围内的许多其他不同实施方式来实现。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。