1.本发明属于机器学习技术领域,涉及一种基于随机森林分类模型通过分析运动员身体、训练数据选拔出优秀运动员并且为每个个体提出针对性训练建议从而提高整体水平的系统。
背景技术:
2.在现实生活中,选拔优秀的足球运动员是一个综合考虑球员多方面指标因素的过程。能否成为一名优秀的足球运动员,不仅依赖于球员自身的踢球技巧如带球、射门、传球、视野、团队协作能力等,还会受到身高、体重、耐力、年龄等生理因素的影响。随着中国足球迈向职业化,青训俱乐部或足球学校等都是采用传统的多场次比赛的方式来筛选有潜力的出色球员。世界足球强国都高度重视天才运动员的早期选拔,德国、西班牙、意大利等足球强国都有一套适合本国运动员特点的、包括身体素质、足球技术、战术意识、心理素质、团队精神在内的综合选材系统,由专业人员负责实施。首先是球探广泛收集信息,定期到学校、足球俱乐部等观看儿童少年踢球、训练和比赛,从中发现具有天赋的苗子;然后进行身体素质、足球技术、战术意识、心理能力等测试,并长期追踪考察,对某些运动员的选拔与考察可能长达几个月、甚至几年。
3.现有技术的缺点:
4.传统的足球运动员选拔方法不仅依赖于选拔人员的专家经验,受主观因素影响较大,而且耗时耗力,在相对不发达的地区难以实施。随着数据挖掘技术的兴起,有不少学者开始采用基于分类的机器学习、神经网络等方法进行人员筛选,但这些都无法有效解决足球运动员选拔的问题。具体来说包括以下几点:首先,对于只包含优秀、良好、及格或者通过、不通过等这一类离散性的标签的训练数据来说,不管是传统的机器学习分类器还是当下流行的神经网络分类器都只能得到离散型结果,无法用连续性的值表示出运动员的真实水平;其次,对于中等、低等水平的运动员而言,仅仅将其做归类是不够的,我们更希望明白他们每个个体与高水平的运动员之间的差距在哪,即显式的表现出每个足球运动员的优势与劣势,要能够为后续训练提供可参考的建议;最后,不管是传统的运动员选拔方法还是基于分类的机器学习方法,都缺少对足球运动员潜力的分析与挖掘。
技术实现要素:
5.本发明针对现有的球员选拔方法的不足,提供了一种基于随机森林分类模型连续化离散指标选拔优秀球员以及对每个个体提出适应性的训练建议的系统。本发明从特征筛选角度来说,采用了融合多种特征提取的方法对特征的重要性进行排序,减少了单一方法带来的偶然性与偏差;从训练数据上来说,本发明采用了五折交叉验证,均衡了每个样本做训练和测试的可能性,优化了训练样本的构成;从输出结果来看,本发明为每个运动员提供了一个连续型评测结果,不仅能对运动员群体做更细致的分类,还能为所有运动员的潜力进行评估,为中等水平的运动员分析优势与劣势并提供训练建议,挖掘出低水平运动员的
潜力。
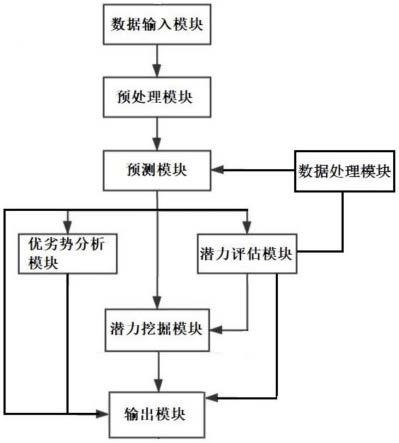
6.本发明技术方案为一种选拔和训练足球运动员的系统,该系统包括:数据输入模块、预处理模块、预测模块、潜力评估模块、优劣势分析模块、潜力挖掘模块、输出模块;该选拔系统根据模型是否经过训练可分为两阶段:训练阶段和预测阶段;初始时系统为训练阶段,此时要求输入数据为经过量化的运动员的身高、体重、力量、传球、射门数据以及最终的专家评估结果,其中所有的输入数据除专家评估结果外既为连续的分数值或离散值,评估结果要求为离散值;在训练完成后系统可进入预测阶段,此时输入数据为除评估结果以外的其他所有项;数据输入模块接收上述输入并将数据传输给预处理模块;
7.所述预处理模块采用0-1归一化的方法对除标签以外的数据进行归一化处理;预处理模块将预处理后的数据传输给预测模块;
8.所述预测模块为一个随机森林分类模型;在系统训练阶段,随机森林分类模型接收来自预处理模块输出的带标签数据,系统内部设置了随机种子并采用五折交叉验证配合网格搜索参数的训练形式,对模型进行多分类的训练;其中,预测模块中的随机森林分类模型对应于不同的输入会有不同的结构参数,模型会在训练阶段自动保存下最高准确率的参数组合,在训练阶段此模块不作输出;在预测阶段,预测模块接收来自预处理模块输出的不带标签的数据以及用户输入的阈值k1,k2,通过计算每名运动的优秀概率p并根据阈值将运动员进行四分类,若p≥k2划分为足够优秀,若0.5≤p<k2划分为优秀但有待提高,若k1≤p<0.5则划分为不优秀但可提高,p<k1分类为不优秀;预测模块在预测阶段将分类为足够优秀的运动员数据直接输入给输出模块,分类为优秀但有待提高的运动员对应的数据输入给优劣势分析模块,将分类为不优秀但可提高的运动员对应的数据输入给潜力评估模块,将分类为不优秀的运动员对应的数据输入给潜力挖掘模块;
9.所述潜力评估模块在获得预测模块输出的数据后,设置参数n1,0≤n1<n,其中n1表示用户最大可容忍运动员表现不佳的项目数,n代表运动员的测试项目总数;通过计算出该运动员最需要提高的前n1个项目,然后将该运动员在这n1个项目上的真实值替换为优秀运动员的平均水平值,再次采用预测模块对该运动员进行预测,如果预测为足够优秀,则变更该运动员为优秀但有待提高的一类,并将该结果传输给优劣势分析模块,否则,将该运动员归为不优秀一类,然后将该运动员数据传输给潜力挖掘模块;
10.所述优劣势分析模块获得数据后,设置参数n2,0≤n2≤n,其中n2表示用户想要得到的相对重要但运动员表现不佳的项目数,采用潜力评估模块相同的方法为运动员计算出最需要提高的前n2个项目,将结果传输给输出模块,方便后续针对性训练;
11.所述潜力挖掘模块收到数据后,根据数据计算分析出该运动员的特长项目,方便该运动员球场位置分配,若没有特长,则直接淘汰,并将该结果传输给输出模块,所述特长项目为该运动员该项目的水平高于优秀运动员的平均水平。
12.进一步的,所述预处理模块中所述归一化处理的具体过程为:
13.为了对各项指标进行统计和分析,需要将数据预处理成预测模块可接收的格式。首先将优秀、良好、及格等中文离散值转换成1,2,3,4等阿拉伯数字,要求数字的大小与真实值存在相关性。为了使不同量纲的特征处于同一数量级,减少方差对特征的影响,使用0-1归一化进行特征缩放。
14.进一步的,所述预处理模块中再计算每个特征的权重系数,计算方法为:
15.首先分别使用多种方法进行特征选择,用卡方检验进行特征与标签的独立性检验,按独立性由小到大进行排序;用信息增益法计算每个特征的信息增益,按信息增益由大到小进行排序;lasso方法将此过程视为多元线性回归,每个特征都有对应的权重系数coef,它的正负值代表特征与目标值是正相关还是负相关,按照coef的绝对值从大到小进行排序;pearson相关系数法计算每个特征与目标值的相关系数,按照相关系数的绝对值从大到小进行排序;最后按照排序结果为每个特征赋予1到n的权重值,将四个排序结果的权重值进行加和再取倒数,得到每个特征的权重系数,越大代表越重要。
16.进一步的,预测模块中所述计算运动员优秀概率的具体过程:
17.采用的决策树预测结果为优秀或不优秀,采用多个决策树进行预测,p的值为优秀的决策树数目在所有决策树总数中的占比。
18.进一步的,在潜力评估以及优劣势分析模块中计算运动员最需要提高的前n个项目的具体过程:
19.首先读取预处理模块在系统训练阶段计算得到的优秀运动员平均水平向量,然后计算优秀水平向量与样本特征向量的差值,将差值向量与特征权重值组成的特征权重向量做点积,得到结果向量;结果向量中值越大的项代表样本该运动员在此项目上表现差且该项目对最终的评判结果影响大,取前n个值最大的项目作为最需要提高的前n个项目。
20.进一步的,在潜力挖掘模块中计算运动员的特长的具体过程:
21.首先读取预处理模块在系统训练阶段计算得到的优秀运动员平均水平向量,然后计算优秀水平向量与样本对应的特征向量的差值向量,将差值向量中所有大于0的项作为该样本的特长,即代表了此运动员整体水平不达标,但在这些特长项目上已经达到了优秀水平。
22.和现有的技术相比,本发明有益效果为:
23.1.本发明是采用多种特征选择方法融合的形式计算出每个特征的权重系数,在避免了单一特征选择方法带来的偏差和偶然性。经验证,使用不同的特征选择方法单独排序出的结果是有较大差异的。较之前的技术而言,本发明的特征排序结果更具有普适性与说服力。
24.2.本发明使用只带离散标签的数据,但能够为每个样本预测出一个连续型的标签值。在步骤3中用分类为1的决策树数目在决策树总数的占比代表了样本的优秀概率,假设所使用的随机森林分类模型共有100棵决策树,那么分类为1的决策树数目就是0-100之间的连续值。一个连续型的标签值更能够细化分级出样本的类别,能够解决类似同为优秀的运动员到底谁更优秀的问题。不同于传统的机器学习或者深度学习分类方法,本发明既能提供离散型的分类结果,也能得到连续型的结果,输出形式更加有效和多样。
25.3.本发明在计算运动员最需要提高的项目时,不仅考虑到运动员在此项目上的表现情况,还额外考虑到此项目的相对重要性,即对最后总评的影响程度,而传统基于经验的运动员选拔方法往往只能关注到其中某一项,也缺少一套科学具体的评价方法。为每个运动员寻找出最需要提高的项目是具有极大现实意义的,依此可以为每名运动员制定出一套个性化的训练方案,提高球队的整体水平。
26.4.本发明相较于传统的选拔方法能够挖掘出具有特长的球员。在传统选拔过程中,一名运动员被评为不优秀往往代表对他的全盘否定,但有些运动员可能在某些项目如
射门、传球等方面极具天赋,本发明可以从标签为不优秀的运动员中找出那些具有特长的运动员,依此进行强化训练或者弱项补齐可提升球队的核心竞争力;另一方面,全能型球员必然是少之又少的,通过潜力挖掘找出具有潜力的特色型球员具有很大的现实意义。
附图说明
27.图1为本发明提出的足球运动员选拔系统框图。
28.图2为融合多方法进行特征排序的方法流程示意图。
29.图3为预测结果时细化再分级的方法流程图。
30.图4为计算每个运动员最需要提高的项目的方法流程图。
具体实施方案
31.为了使本发明的选拔流程、创新点更加清楚,以下结合附图对本发明进一步详细介绍。
32.图2直观地展示了本发明融合多种特征选择方法做特征排序以及计算得到特征权重的过程,具体的算法流程如下:
33.①
分别用卡方检验、pearson相关系数法、lasso、信息增益法做特征选择,按照特征重要性由大到小进行排序,得到表t1,t2,t3,t4。其中ti={f1,f2,f3…fn
};
34.②
设特征fi在四张表中的rank值分别为r1,r2,r3,r4那么第i个特征的综合排名为si=∑ri,依照综合排名由小到大进行排序得到特征综合排名表t0={f1,f2,f3…fn
},对应的综合分数为s0={s1,s2,s3…
sn};
35.③
特征i的权重计算方式为wi=1/si,依此求得特征综合排名表对应的特征权重表w0={w1,w2,w3…
wn}
36.图3展示了用离散型标签数据训练随机森林分类模型,做连续型的标签预测,再做细化分级的过程。
37.图4详细地展示了计算每个运动员最需要提高的项目的过程,具体算法流程如下:
38.①
设运动员i的测试训练原始数据为vi={f1,f2,f3…fn
},取出所有标签为优秀的球员,计算优秀球员在各个项目上的平均水平,得v0={f1’
,f2’
,f3’
…fn’}
39.②
计算差值向量vg=v
0-vi,即vg={f
1-f1’
,f
2-f2’
,f
3-f3’fn
…fn’};
40.③
计算结果向量vr=vg·
w0;
41.④
将结果向量的元素由大到小排序,得到最终结果,元素值越大的特征对应项目越需要得到提高。
42.以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形都应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
