1.本发明属于工业互联网技术领域,涉及大型设备故障预测方法,具体涉及一种工业互联网中因果与注意力并重的大型设备故障预测方法。
背景技术:
2.工业互联网中大型设备的长期稳定运行对于安全生产具有重要意义。出于对大型设备的全天候监测需求而部署的传感器节点将会导致海量数据,基于故障样本的特征提取,面向全生命周期监测数据的实时分析可准确把控大型设备的运行状态,并预测可能出现的故障,进而启动设备故障应急预案,对设备进行及时检修,避免工安事故的发生。因此,面向工业互联网大型设备的运行状态监测与故障预测亟待研究。另一方面,传统的数字化、网络化、智能化大型设备故障分析技术不足,无法满足海量监测大数据实时处理与分析的需求,构建面向工业互联网的大数据分析框架势在必行,面向工业互联网的高水平数据模型与大数据分析能力迫在眉睫。
3.目前,已相继提出了多种设备故障预测方法:
4.(a)信号分析方法:根据大型设备所部署传感器所监测到的信号变化,进行数值变换分析,基于专业领域的知识与经验,进行设备状态的检测与故障预测。
5.(b)基于线性判别器的方法:统计故障状态下传感器所监测到的信号特征,利用主成分分析法提取故障特征,将提取的重要特征输入给线性判别器进行分类。
6.(c)基于卷积神经网络的方法:统计一段时间内的信息,利用卷积层将提取的时域信号转换为频域信号,再利用全连接层训练得到故障结果。
7.(d)基于数据融合的方法:利用各传感器数据进行合成,通过融合算法,对设备故障进行预测。
8.上述方法均可在特定情况下实现对大型设备的运行状态监测与故障预测。然而,传统信号分析方法需要有较深的专业知识储备,线性判别器与数据融合则依赖传感器数据的个数与特征维度,深度学习虽然可以直接进行端对端学习的高维特征计算特性,使得直接使用设备的传感器数据成为可能。但深度学习的内部是一个黑盒过程,学习算法选取的特征对实验结果有何影响,依旧是一个有待解决的问题。
技术实现要素:
9.针对现有技术存在的不足,本发明的目的在于,提供一种工业互联网中因果与注意力并重的大型设备故障预测方法,以解决现有技术中预测方法的准确性有待进一步提升的技术问题。
10.为了解决上述技术问题,本发明采用如下技术方案予以实现:
11.一种工业互联网中因果与注意力并重的大型设备故障预测方法,其特征在于,该方法包括以下步骤:
12.步骤1,收集大型设备的故障数据,将其作为训练样本;
13.步骤2,对步骤1中整理分类后的大型设备故障的训练样本的数据进行预处理,使用信号时域分析方法得到样本的时域特征,将所述时域特征进行编码处理,数值特征进行归一化处理,得到预处理后的大型设备传感器的样本数据序列;
14.步骤3,对步骤2中得到的大型设备传感器的样本数据序列进行因果分析,基于设置的因果分析目标函数,量化每个特征对预测结果的影响程度;
15.步骤4,结合时间信息与步骤3的结果,基于时间注意力机制的模型,得到大型设备的隐藏层数据和注意力分数;
16.步骤5,利用步骤4得到的隐藏层数据和注意力分数对大型设备的故障进行预测。
17.本发明与现有技术相比,具有如下技术效果:
18.(ⅰ)本发明的预测方法基于因果分析,探究特征与故障预测准确度之间的潜在关系,为面向大型设备故障预测模型的特征选取提供一个可行方法,进而为故障的主因特征分配较大权重,为次因特征分配较小权重。
19.(ⅱ)本发明的预测方法基于注意力机制,剖析大型设备故障样本在时间维度上的细粒度变化,寻找关键时间点,提高故障预测的准确度,以期及时启动设备故障应急预案,对设备进行及时检修,避免工安事故的发生。
附图说明
20.图1为信号早期平稳阶段与信号中期故障阶段选取图。
21.图2为选取特征序列图。
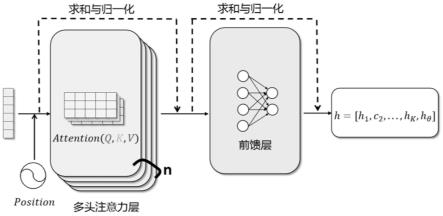
22.图3为transformer内部结构图。
23.以下结合实施例对本发明的具体内容作进一步详细解释说明。
具体实施方式
24.近年来,研究者们对因果关系分析进行了各种尝试与扩展,并在图神经网络方面取得了一些研究成果。注意力机制被广泛应用于翻译任务,医疗等等的任务中,注意力机制能通过序列化建模,从而捕捉时间维度上数值的变化情况。近年的研究证明了注意力机制的有效性,但在工业互联网领域还没有过多的关注,这是因为注意力机制通常是对离散型数据进行高维度的特征学习,捕捉数据与任务之间的关系。因此,本发明基于因果分析与时间注意力机制,探索面向工业互联网的大型设备监测与故障预测方法。
25.本发明给出一种工业互联网中因果与注意力并重的大型设备故障预测方法,即工业互联网中基于注意力机制的因果感知大型设备运行状态监测与故障预测方法,该方法基于大型设备的故障样本,通过分析传感器数据与故障之间存在的潜在因果关系来构建因果分析模型,结合因果分析与时间注意力机制预测大型设备的故障。
26.本发明的预测方法采取一种有监督的学习方式,收集故障样本,提取故障特征,通过分析特征与故障之间存在的潜在因果关系来构建因果分析模型,结合因果分析与时间注意力机制,实现设备故障的预测。
27.需要说明的是,本发明中的所有的算法,如无特殊说明,全部均采用现有技术中已知的算法。
28.需要说明的是,本发明中:
29.svm算法指的是支持向量机算法。
30.rf算法指的是随机森林算法。
31.lr算法指的是逻辑回归算法。
32.lstm算法指的是长短期记忆网络算法。
33.gru算法指的是门控循环单元算法。
34.dfc-cnn算法指的是深度全卷积神经网络(英文:deep fully convolutional neural network)。
35.da-rnn算法指的是双阶段注意力循环神经网络算法算法(英文:dual-stage attention-based recurrent neural network)。
36.dw-ae算法指的是深度小波自动编码器算法(英文:deep wavelet auto-encoder)。
37.transformer指的是深度自注意力网络。
38.auc指的是受试者操作特征曲线。
39.softmax函数指的是归一化函数。
40.遵从上述技术方案,以下给出本发明的具体实施例,需要说明的是本发明并不局限于以下具体实施例,凡在本技术技术方案基础上做的等同变换均落入本发明的保护范围。
41.实施例:
42.本实施例给出一种工业互联网中因果与注意力并重的大型设备故障预测方法,该方法包括以下步骤:
43.步骤1,收集大型设备的故障数据,将其作为训练样本;
44.步骤1包括如下子步骤:
45.步骤1.1,基于收集到的大型设备故障样本,对故障数据进行分类,并对每一类故障数据进行标记;
46.具体到本实施例中,实验数据来源于西安交通大学与昇阳科技加工制造全寿命周期振动信号轴承数据集。该实验平台由转速控制电动机,转轴、支撑轴承、液压加载系统和测试轴承等组成。该数据集共有3种工况,每种工况共5个轴承。一共15个轴承全寿命周期信号样本。试验中设置采样频率为25.6khz,采样间隔为1min,每次采样时长为1.28s。每分钟每个传感器采集信号数量为32769个。鉴于该数据集的工况类型较少,首先对数据做预处理。先进行数据增强,即增加数据集的尺寸大小,其本质是在合理的操作下增加数据集的大小以得到学习结果,每收集2000个数据所需要的时间作为单位时间τ,这里一共有同类型设备15个,每个设备有两台加速度传感器记录轴承的数据变化。
47.步骤1.2,对标记后的每类大型设备故障数据进行大量采样,并记录采样过程中每个采样点的时间,采集到的信号片段按照其所在的大型设备标号进行整理,得到训练样本;
48.所述的整理的具体过程为:大型设备的数量为g个,每个大型设备配备i个监测传感器;大型设备的故障种类为q;定义单位时间τ,大型设备每经历τ所采集的数据制成一个数据切片;大型设备从启动到发生故障所用的时间为t;第k个数据切片的时间为τ
×
k;大型设备每经历t所采集的数据包含k个数据切片,按时间顺序排列。
49.具体到本实施例中,通过采样。以每个设备为例,2000个数据可以作为一个切片,
可以得到全周期信号的切片。在故障发生后,信号特征已经很明显,此时再对设备做故障预测已失去意义,要尽可能选择在故障早期就及时预测出故障,在故障早期或未发生故障时,由于信号的周期性,此时大量的数据所蕴含的信息是极少的,应尽可能少的考虑这段时期的信号情况,而在故障发生前信号产生异常时,应尽可能多的关注这段时期的信号变化情况,这符合设备一般检测过程的流程。所以采集数据集时,考虑到真实的工业设备检查,每次采集进行序列分析时以及序列的大小,如图1,在早期信号稳定的阶段随机采集20个切片,在故障中期随机采集40个切片合成为一个切片序列,k=60,按照此种方法每种工况采集1000个切片序列。
50.本发明步骤1的优点:通过本步骤得到了带有特征信息与时间信息的序列数据集,满足了模型数据量的需求。得到增强的数据集完全取自原始数据集,并没有额外的信息引入。
51.本实施例中有3种故障类型,以用于新方法的实验论证。
52.步骤2,对步骤1中整理分类后的大型设备故障的训练样本的数据进行预处理,使用信号时域分析方法得到样本的时域特征,将所述时域特征进行编码处理,数值特征进行归一化处理,得到预处理后的大型设备传感器的样本数据序列;
53.步骤2包括如下子步骤:
54.步骤2.1,对整理好的数据切片使用信号时域分析方法得到数据切片的时域特征,并做成对应样本的时域特征切片;
55.将每个时域特征切片的数据采用信号时域分析方法能得到唯一的时域特征参数,时域特征参数又分为有量纲特征参数和无量纲特征参数。例如方差、均方根值、平均值等参数。
56.步骤2.2,将提取的时域特征切片进行标准化,生成统一的特征码,定义标准化的公式为:
[0057][0058]
式中:
[0059]fijk
为第i个传感器第j个特征的第k个序列的时域特征切片;
[0060]sijk
为第i个传感器第j个特征的第k个序列的特征码;
[0061]
max(f
ijk
)为第i个传感器第j个特征的最大值;
[0062]
min(f
ijk
)为第i个传感器第j个特征的最小值;
[0063]
γ为控制特征码空间大小的系数;
[0064]
j为传感器的特征个数;
[0065]
i为第i个传感器;
[0066]
j为传感器的第j个特征;
[0067]
k为第k个序列;
[0068]
这一步的目的是将所有的时域特征标准化并转化为特征码。
[0069]
步骤2.3,将步骤2.2得到的特征码转换为二进制输入:
[0070]
nk=[b
11k
,b
12k
,b
13k
,...,b
ijk
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式2;
[0071]
得到大型设备传感器的样本数据序列n=[n1,n2,n3,...,nk];
[0072]
每一个特征码s
ijk
都可以转换为一个二进制输入b
ijk
,用{0,1}o表示,o=γ
×i×
j,特征码s
ijk
中小数向下取整。
[0073]
式中:
[0074]bijk
为特征码s
ijk
的二进制输入;
[0075]
n为大型设备传感器的样本数据序列;
[0076]
nk为第k个序列的特征码f
ijk
的二进制输入;
[0077]
nk为第k个序列的特征码f
ijk
的二进制输入。
[0078]
具体到本实施例中,在对信号的数值分析过程中,统计每2000个数据点的时域特征,时域信号本身所含有巨大的信息量,选择合适的时域分析指标来进行轴承状态分析至关重要。选取方差,均方根值,平均值,峭度,偏度,峰值因子,裕度因子7个特征描述切片时域特征值。在信号数字特征的体系下,由于各特征性质不同,所代表的数值也不同。要考虑其特征在输入模型空间上的含义,在进行故障检测之前,需要对样本数据进行标准化处理。再将数据映射到一个特定区间,这样的好处是消除数据特征之间因性质导致值差别的影响。既可以加快模型的收敛速度,也可以提升模型的精度。先使用归一化的方法将各个特征数值区间统一,再将其编码。具体的,将所有轴承的序列点进行归一化。,在现有数据集上,分别对每个特征采用离差标准化法。为每个特征分配的空间大小系数为1400。所有特征都映射在总大小为9800的稀疏空间上去。如图2所示,我们把输入序列的每个样本定义为7
×1×
60大小的嵌入向量,其中7是序列特征的行数,1是序列特征的列数,60为切片的个数。
[0079]
如图3所示,本发明步骤2的优点:通过分析数值分析的特征信号,选择尽可能对检测结果有用的特征维度,有利于后面因果分析对这些特征的影响进行直观的判断。增加对特征影响的理解。
[0080]
步骤3,对步骤2中得到的大型设备传感器的样本数据序列进行因果分析,基于设置的因果分析目标函数,量化每个特征对预测结果的影响程度;
[0081]
步骤3包括如下子步骤:
[0082]
步骤3.1,使用步骤2得到的预处理后的大型设备传感器的样本数据序列进行因果分析;
[0083]
一个大型设备的传感器的样本中,有i个传感器,传感器有j个特征;在进行所有特征计算时,量化特征对预测结果的目标函数定义为:
[0084][0085]
式中:
[0086]
δε,f
ij
为特征f
ij
对故障预测的影响;
[0087]fij
为第i个传感器的第j个特征;
[0088]
为不含有特征f
ij
故障预测的误差;
[0089]
εf为故障预测的误差;
[0090]
步骤3.2,根据式3,衡量一个特征对预测结果的影响需要计算完整特征的模型误差εf与不含有特征f
ij
的模型误差使用基于注意力机制的一层transformer作为计算误差的模型;基于大型设备传感器的样本数据序列n由式4生成transformer的嵌入序列m和不含特征f
ij
的嵌入序列m\{f
ij
},
[0091]
m=[m1,m2,m3,...,mk],m\{f
ij
}=[m`1,m`2,m`3,...,m`k];
[0092]
mk=wmnk bmꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式4;
[0093][0094][0095]
式中:
[0096]
tf(
·
)为transformer;
[0097]
为预测结果的标签;
[0098]
m为transformer的嵌入序列;
[0099]
m\{f
ij
}为transformer的不含特征f
ij
的嵌入序列;
[0100]
mk为嵌入序列m的第k个序列的嵌入数据;
[0101]
nk为第k个序列的特征码f
ijk
的二进制输入
[0102]
m`k为嵌入序列m\{f
ij
}的第k个序列的嵌入数据;
[0103]
wm为嵌入序列的初始化权重矩阵,
[0104]bm
为嵌入序列的初始化偏差矩阵,
[0105]
v为wm和bm的维度;
[0106]
o为nk的空间维度,o=γ
×i×
j;
[0107]
为实数集;
[0108]
步骤3.3,用e表示真实标签,使用交叉熵函数损失函数来表示transformer学习后预测结果的误差,式3的故障预测误差可表示为:
[0109][0110][0111]
特征的因果贡献能够通过式3、式4、式5、式6、式7和式8计算模型与不含有特征f
ij
故障预测的误差之间的损失函数的差来衡量;
[0112]
步骤3.4,利用式7和式8计算输入的各个特征的模型误差,得到特征对模型造成的因果影响;根据因果影响为每个输入特征分配权重,权重分配式9所示:
[0113][0114]
得到因果影响权重
[0115]
式中:
[0116]
为第i个传感器的第j个输入特征的权重;
[0117]
wf为因果影响权重。
[0118]
具体的到本实施例中,对于步骤3.1,由于数据集的限制,选择加速度传感器信号进行数值分析,我们从时域信号分析中选取了与故障信号尽可能相关的7个特征,即i=1,j=7。在预训练的过程中分别将某个特征去除,进入transformer学习,得到不含有某个特征的损失值与包含全部特征的损失值,两者的差反映了特征对结果的影响程度。并以此为基
准为每个特征分配权重,再将权重与特征值相积作为transformer的正式输入。
[0119]
对于步骤3.2、步骤3.3和步骤3.4,利用式3至式8计算出因果分析模块中各个特征对最终结果产生的影响,并利用该结果生成关于因果的权重值分别附加于各特征值用于感知机的输入,在使用的大型设备数据集中,利用数值分析分析出7个重要特征。分别对其进行因果计算,计算出哪些特征对故障检测具有较大影响。
[0120]
本发明步骤3的优点:通过因果分析模块对特征进行分析,抑制不重要的特征,已有的算法会将所有特征同等对待,但实际上在设备的不同阶段,不同的信号特征会有不同的含义,在故障早期筛选出影响重要的特征对最终的检测结果会有较大的影响。
[0121]
步骤4,结合时间信息与步骤3的结果,基于时间注意力机制的模型,得到大型设备的隐藏层数据和注意力分数。
[0122]
步骤4包括如下子步骤:
[0123]
步骤4.1,使用步骤3.4所得到的因果影响权重结合式1重新计算特征码,公式如式10所示:
[0124][0125]
式中:
[0126]
为重新计算得到的第i个传感器第j个特征的第k个序列的特征码;
[0127]
基于式10采用与步骤2.3相同的操作,得到结合因果影响权重的样本数据序列
[0128]
式中:
[0129]nw
为结合因果影响权重的样本数据序列;
[0130]
为结合因果影响权重的第k个序列的特征码f
ijk
的二进制输入;
[0131]
为同一类型大型设备故障状态时结合因果影响权重的特征表示;预测一种故障时,所有样本数据后的都是相同的;
[0132]
步骤4.2,将时间信息进行处理与特征嵌入统一维度的序列,公式如下:
[0133][0134]
式中:
[0135]
zk为时间信息嵌入序列;
[0136]
tanh为双曲正切函数;
[0137]
t为大型设备从启动到发生故障的所用的时间;
[0138]
pk为故障发生到采集切片的时间差,pk=t-t
×
k;
[0139]
wz为时间信息嵌入序列的初始化权重矩阵,
[0140]bz
为时间信息嵌入序列的初始化偏差矩阵,
[0141]
v为wz和bz的维度;
[0142]
如上所述,将时间信息初始化成与特征嵌入统一维度的向量,切片的时间越接近故障,说明数据越可能发生异常,应给予更高的关注。
[0143]
步骤4.3,将时间信息与结合因果影响权重后的样本数据生成结合后的嵌入数据:
[0144][0145]
根据式12能够得到结合后的嵌入序列c=[c1,c2,c3,...,ck,c
t
];
[0146]
式中:
[0147]ck
为结合后的第k个序列的嵌入数据;
[0148]ck
为结合后的第k个序列的嵌入数据;
[0149]
为结合后的第k个序列的特征码f
ijk
的二进制输入;
[0150]
wc与bc为结合后的嵌入序列的初始化权重矩阵和偏差矩阵,其中为结合后的嵌入序列的初始化权重矩阵和偏差矩阵,其中
[0151]
c为结合后的嵌入序列;
[0152]ct
为同一类型大型设备故障状态时结合因果影响权重的嵌入数据;预测一种故障时,所有样本数据后的c
t
都是相同的;
[0153]
步骤4.4,根据结合后的嵌入序列,使用单层结构的transformer来学习每次包含有时间信息的嵌入序列与大型设备故障之间的关系:
[0154]
[h1,h2,h3,...,hk,h
t
]=tf([c1,c2,c3,...,ck,c
t
])
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式13;
[0155]
式中:
[0156]
tf(
·
)为transformer;
[0157]hk
为ck通过transformer学习到的隐藏层数据;
[0158]ht
为c
t
通过transformer学习到的隐藏层数据,即故障状态隐藏层表示;
[0159]
步骤4.5,计算结合后的嵌入序列的局部分数,获得注意力得分后,生成局部特征注意力权重;
[0160][0161]
式中:
[0162]
uk为结合后的嵌入序列的第k个序列的局部分数;
[0163]hk
为通过transformer学习到的隐藏层数据;
[0164]
为局部注意力的初始化权重矩阵,
[0165]bu
为局部注意力的初始化偏差矩阵,
[0166]
l为隐藏层数据hk的维度;
[0167]
p为wu和bu的维度;
[0168]
在获得局部注意力分数后,使用softmax函数生成局部特征注意力权重,即:
[0169]wlocal
=softmax([u1,u2,u3,...,uk])=[l1,l2,l3,...,lk]
ꢀꢀꢀꢀꢀꢀꢀꢀ
式15;
[0170]
式中:
[0171]wlocal
为局部特征注意力权重;
[0172]
uk为结合后的嵌入序列的第k个序列的局部特征分数;
[0173]
lk为结合后的嵌入序列的第k个序列的局部特征分数权重值;
[0174]
步骤4.6,使用注意力机制来判断样本时间对故障预测的影响,首先将步骤4.4得到的故障状态隐藏层表示h
t
转换为注意力机制中的查询向量;
[0175]
x=relu(w
xht
b
x
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式16;
[0176]
式中:
[0177]
x为注意力机制中的查询向量;
[0178]
relu()为修正线性单元激活函数;
[0179]ht
为故障状态隐藏层表示;
[0180]wx
为查询向量的初始化权重矩阵,
[0181]bx
为查询向量的初始化偏差矩阵,
[0182]
l为隐藏层数据hk的维度;
[0183]
q为w
x
和b
x
的维度;
[0184]
步骤4.7,将故障发生到采集数据切片的时间差pk作为注意力机制的key向量,如式17所示:
[0185][0186]
得到e=[e1,e2,e3,...,ek];
[0187]
式中:
[0188]ek
为第k个序列的key向量;
[0189]ek
为第k个序列的key向量;
[0190]
e为注意力机制的时间key向量集合;
[0191]
we为时间key向量的初始化权重矩阵,
[0192]be
为时间key向量的初始化偏差矩阵,
[0193]
q为we和be的维度;
[0194]
步骤4.8,基于步骤4.6与步骤4.7中得到的查询向量x与key向量ek,使用注意力机制能够得到全局时间注意力分数,如式18和式19所示:
[0195][0196]
式中:
[0197]rk
为第k个序列的全局时间注意力分数;
[0198]
x
t
为查询向量x的转置;
[0199]
δ为时间key向量的维度;
[0200]
应用softmax层对注意力得分进行归一化,全局时间注意力权重能够表示为:
[0201]wglobal
=softmax([r1,r2,r3,...,rk])=[g1,g2,g3,...,gk]
ꢀꢀꢀꢀꢀꢀꢀ
式19;
[0202]
式中:
[0203]wglobal
为全局时间注意力权重;
[0204]rk
为第k个序列的全局时间注意力分数;
[0205]gk
为第k个序列的全局时间注意力权重;
[0206]
步骤4.9,将步骤4.5的局部特征得分与步骤4.8的全局时间得分结合起来;
[0207]
首先使用h
t
嵌入为局部特征与时间信息分配权重,用softmax将其规格化,如式20所示:
[0208]
v=softmax(w
vht
bv)=[a
loacl
,a
global
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
式20;
[0209]
式中:
[0210]ht
为故障状态隐藏层表示;
[0211]
wv为综合信息分配的初始化权重矩阵,
[0212]bv
为综合信息分配的初始化偏差矩阵,
[0213]
l为隐藏层数据hk的维度;
[0214]
根据局部特征注意力权重和全局时间注意力权重,得到融合的注意力权重,如式21所示;
[0215][0216]
式中:
[0217]
为融合的注意力权重;
[0218]aloacl
为由故障表示h
t
分配到w
local
的权重;
[0219]
lk为结合后的嵌入序列的第k个序列的局部特征权重值;
[0220]aglobal
为由故障表示h
t
分配到w
global
的权重;
[0221]gk
为第k个序列的全局时间注意力权重;
[0222]
步骤4.10,将融合的注意力权重归一化,得到嵌入序列的注意力分数如式22所示:
[0223][0224]
具体到本实施例中,从步骤4.1到4.5是一个局部信息注意力模块,作用是分析每次收集信号的特征信息,对于步骤4.1,利用之前因果分析与预处理的特征做成符合transformer要求的嵌入序列,并在步骤4.2与步骤4.3将时间信息也整合嵌入序列中,步骤4.4与步骤4.5学习嵌入序列信息之间的依赖关系并得到隐藏向量,得到由嵌入序列转换为隐藏向量的局部注意力分数。步骤4.6到4.8是一个全局时间注意力模块,通过对整体时间信号的分析时间信息的重要性。步骤4.6由局部注意力模块得到一个对于设备整体情况分析的隐变量h
θ
利用注意力机制转换成查询向量。步骤4.7将时间信息前面两个模块侧重于从不同角度来判断设备目前的状态,需要将两者结合起来考虑。步骤4.9到4.10为此设计了一种注意力融合机制,以捕获不同情况下的信号表征和时间表征的相关信息,在融合了局部特征注意力得分与全局时间信息注意力得分后给出一个综合得分。
[0225]
本发明步骤4的优点:分别从两个方面进行分析,特征通过对数据集全周期信号进行数值分析得到,时间信息则来自于原数据集。该研究最重要的是大型设备的健康状况检测,因此我们引入了周期信号时间信息,将信号特征和时间信息融合在一起,利用收集的信息序列之间时间间隔境分析长时间段信号的变化情况。同时采用融合可以更好的分配特征对检测结果的的贡献度。
[0226]
步骤5,利用步骤4得到的隐藏层数据和注意力分数对大型设备的故障进行预测。
[0227]
步骤5包括如下子步骤:
[0228]
步骤5.1,根据步骤4.4的隐藏层数据和步骤4.10的注意力分数,可以得到大型设备的故障预测得分:
[0229]
[0230]
式中:
[0231]
为大型设备的故障预测得分;
[0232]
为嵌入序列的注意力分数;
[0233]hk
为ck通过transformer学习到的隐藏层数据;
[0234]
步骤5.2,对步骤5.1得到的大型设备的故障预测得分,使用softmax函数得到对大型设备的故障预测的概率;
[0235][0236]
式中:
[0237]
wd为故障预测概率初始化的权重矩阵,
[0238]bd
为故障预测概率初始化的偏差矩阵,
[0239]
l为隐藏层数据hk的维度;
[0240]
根据对大型设备的故障预测的概率来判断大型设备将要出现某种故障类型的可能。
[0241]
具体到本实施例中,对于步骤5.1,利用步骤4.10得到的综合注意力得分与步骤4.4得到的故障预测得分。对于步骤5.2,对步骤5.1中得到的故障检测得分进行检测,通过softmax函数等到最终检测对应故障的概率。
[0242]
本实施例中,使用所训练的模型,基于测试样本,验证该模型的精度。具体的,设模型中参数为ψ,使用交叉熵损失函数作为预测值与实际值d的损失函数,目标是最小化平均损失函数,如式25所示:
[0243][0244]
式中:
[0245]
为最小化平均损失函数;
[0246]
d为实际值;
[0247]
为预测值;
[0248]
g为大型设备的总数。
[0249]
本发明方法的性能分析:
[0250]
下面将本方法将西安交通大学与昇阳科技加工制造全寿命周期振动信号轴承数据集作为数据集,以证明本发明所提方法的有效性。
[0251]
该数据集共有3种工况,每种工况共5个轴承。一共15个轴承全寿命周期信号样本。试验中设置采样频率为25.6khz,采样间隔为1min,每次采样时长为1.28s。每分钟每个传感器采集信号数量为32769个。
[0252]
当机械装备出现故障时,可能会在时域、频域和时频域都有不同程度的体现。以轴承1_1为例,该轴承在试验结束时外圈出现了故障,因载荷施加在水平方向,该方向的振动信号能够包含更多的退化信息。轴承1_1水平方向收集到的数据如图1所示。
[0253]
使用全寿命周期的数据可以获得最佳效果,但在实际场景中,轴承的使用寿命可能达到上万小时。传感器收集大量的数据信息价值极低。往往重要的数据分布在轴承的后半段生命周期。所以在轴承正常运行期间我们不应收集大量的数据,而是选取几个时间点
的传感器信息组成的信号序列作为轴承正常状态的表示。
[0254]
为了验证本章算法的有效性,选取转速2100r/min,径向力为12kn工况下轴承故障为外圈裂损的三个样本数据。为了保证模型训练的有效性,将每个轴承的信号分为一段序列,每2000个数据通过数值分析得到其特征值。得到全周期信号的序列点。在故障后期,信号特征已经很明显,此时再对轴承做故障检测已失去意义,所以要选择在故障早期就及时检验出故障,如图2所示,在故障早期或未发生故障时,由于信号的周期性,此时大量的数据所蕴含的信息是极少的,此时应尽可能少的考虑这段时期的信号情况,而在故障发生早期或者中期信号产生异常时,应尽可能多的关注这段时期的信号变化情况,这符合设备一般检测过程的流程。所以采集数据集时,考虑到真实的工业设备检查,每次采集在早期平稳信号阶段随机采集20个序列点在故障中期随机采集40个信号点合成为一个信号特征序列,每种工况采集1000个信号特征序列。相应的数据集描述如表1所示。
[0255]
表1数据集描述
[0256]
轴承轴承1_1轴承1_4轴承1_5轴承2_1轴承2_5训练集600600600600600验证集200200200200200测试集200200200200200
[0257]
由于数据存在一定层次的缺失,分别混合轴承数据集来检测对不同类型故障的准确性。如表2和表3所示,在轴承1_1与1_4数据集中,1_1为待检测故障。在轴承1_1与1_5数据集中,1_1为待检测故障。在轴承2_1与2_5数据集中,2_1为待检测故障。
[0258]
表2混合轴承检测准确度结果
[0259][0260]
表3轴承2_1与2_5数据集实验效果对比
[0261][0262]
如表2和表3所示,在轴承1_1和1_4混合数据在所有算法上都取得了全识别。这是因为两种故障类型的数据特征信息相差极大导致。但在不同故障类型的识别检测上。算法达到了不错的结果。比基准算法都有提高。
[0263]
实验还验证了所提出的模型和其他基线模型在数据集上的平均性能。接下来还需要分析因果目标是如何影响模型结果的,如表4所示,允许模型学习与检测目标具有最高相关性的特征。无量纲参数对轴承的轴承载荷和速度不敏感,不需要考虑相对标准值和以前的数据比较,对故障的早期更敏感,但严重的抗干扰故障差,容易造成误判。虽然峰值、波峰因数、峰度等参数对冲击故障较为敏感,但当故障进入严重发展阶段时,峰值因数、峰度等参数处于饱和状态,丧失诊断能力。但是,不同类型的故障会导致不同因素的不同趋势。这也会导致因果分析关注不同的特征。注意机制可以强制模型关注包含重要风险因素的信号特征,而减轻其他特征对检测结果的影响。通过因果分析可以清楚地知道模型的每个特征对最终性能的贡献,这也可以拓展到其他模型上去。
[0264]
表4轴承2_1与2_5数据集因果分析结果
[0265]
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。