1.本发明涉及图像文字识别领域,尤其涉及一种超大图像的结构化信息提取方法及装置。
背景技术:
2.目前的ocr技术已经能够顺利的将图像的文字内容提取出来。但是对特定的一些图像,比如说广告设计图纸,图像大小是正常文本图像的几十倍。使用常规的ocr技术,几乎不能检测到文字的位置,更不能进行后续的识别了。
3.为了更加清晰的描述这一现象,我们定义rate = 图像最长边/单字符高度。对于常规的文档,rate大约在50-200的范围。而对于类似于广告的设计图纸,rate可以在800
–
2000的范围,现有技术中在rate值超过1000的图像中就很难识别出文字。
4.另一方面,目前的文字识别技术,只是简单的把文字信息进行逐行的识别,并没有对识别出的信息进行结构化提取。特别是对一些排版复杂和多样的文档,对结构化的信息提取更增加了难度。
5.所以本发明提供了一种超大图像的结构化信息提取方法发解决上述问题。
技术实现要素:
6.本发明所要解决的技术问题在于现有的文字提取技术存在以下缺点:1)不能检测出rate值高的图像中的文字的位置;2)目前的文字识别技术,只是简单的把文字信息进行逐行的识别,并没有对识别出的信息进行结构化提取。
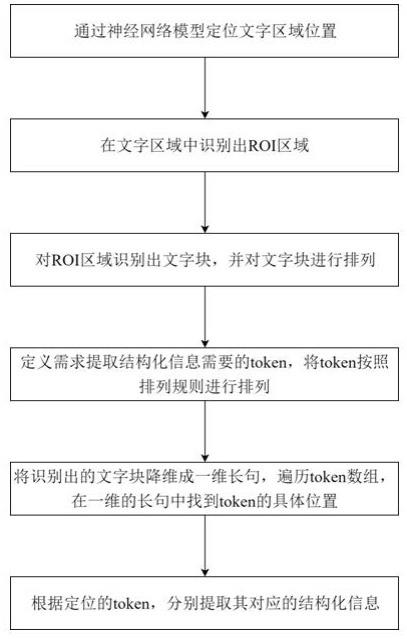
7.提供一种超大图像的结构化信息提取方法,所述超大图像的结构化信息提取方法包括:通过神经网络模型定位文字区域位置;在文字区域中识别出roi区域;对roi区域识别出文字块,并对文字块进行排列;定义需求提取结构化信息需要的token,将token按照排列规则进行排列;将识别出的文字块降维成一维长句,遍历token数组,在一维的长句中找到token的具体位置;根据定位的token,分别提取其对应的结构化信息。
8.进一步地,所述通过神经网络模型定位文字区域位置包括:训练神经网络模型,学习超大图像的文字区域的特征;定位文字区域位置,对文字区域位置进行偏差调整形成识别区域。
9.进一步地,所述定位文字区域位置,对文字区域位置进行偏差调整形成识别区域包括:定位文字区域位置;
将文字区域的上下方向上分别扩展检测区域高度的25%;将文字区域的左右方向上分别扩展检测区域的宽度的25%;形成识别区域。
10.进一步地,所述超大图像为rate值大于1000的图像。
11.进一步地,所述rate值为图像最长边与单字符高度的比值。
12.进一步地,所述对roi区域识别出文字块,并对文字块进行排列包括:检测出每一行文字的位置;对每行的文字进行识别;按照从上到下,从左到右的顺序,依次对识别的文字进行排版和输出。
13.进一步地,所述排列规则为:将token按照母token排列在前,子token排列在后。
14.进一步地,所述子token为在母token中能找到的相同字段。
15.进一步地,所述将识别出的文字块降维成一维长句,遍历token数组,在一维的长句中找到token的具体位置包括:将识别出的文字块降维成一维长句,不同行之间采用在行首添加标识符进行标识;遍历token数组,在一维的长句中找到token的具体位置;遍历token数组,正对换行的特殊位置,找到隐藏的token位置;如果找到token,去除行首的标识符,同时同步更新后续的已经定位的token位置。
16.另一方面,本发明还提供一种超大图像的结构化信息提取装置,所述超大图像的结构化信息提取装置包括:文字区域定位模块,用于通过神经网络模型定位文字区域位置;目标区域定位模块,用于在文字区域中识别出roi区域;文字块排序模块,用于对roi区域识别出文字块,并对文字块进行排列;整理模块,用于定义需求提取结构化信息需要的token,将token按照排列规则进行排列;token定位模块,用于将识别出的文字块降维成一维长句,遍历token数组,在一维的长句中找到token的具体位置;结构化信息提取模块,用于根据定位的token,分别提取其对应的结构化信息。
17.实施本发明,具有如下有益效果:本发明扩大识别区域,能够对超大的图像进行文字识别,利用token,能够实现对排版复杂多样的文档进行结构化信息的提取。
附图说明
18.图1是本发明的流程图;图2是本发明定位文字区域的流程图;图3是本发明识别文字块的流程图;图4是本发明提取结构化信息的流程图。
具体实施方式
19.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
20.实施例1本实施例中,参考说明书附图1至附图4,本实施例所要解决的技术问题在于:1)不能检测出rate值高的图像中的文字的位置;2)目前的文字识别技术,只是简单的把文字信息进行逐行的识别,并没有对识别出的信息进行结构化提取。
21.提供一种超大图像的结构化信息提取方法,所述超大图像的结构化信息提取方法包括:通过神经网络模型定位文字区域位置;在文字区域中识别出roi区域;对roi区域识别出文字块,并对文字块进行排列;定义需求提取结构化信息需要的token,将token按照排列规则进行排列;将识别出的文字块降维成一维长句,遍历token数组,在一维的长句中找到token的具体位置;根据定位的token,分别提取其对应的结构化信息。
22.在一个具体的实施方式中,所述通过神经网络模型定位文字区域位置包括:训练神经网络模型,学习超大图像的文字区域的特征;定位文字区域位置,对文字区域位置进行偏差调整形成识别区域。
23.在一个具体的实施方式中,所述定位文字区域位置,对文字区域位置进行偏差调整形成识别区域包括:定位文字区域位置;将文字区域的上下方向上分别扩展检测区域高度的25%;将文字区域的左右方向上分别扩展检测区域的宽度的25%;形成识别区域。
24.在一个具体的实施方式中,所述超大图像为rate值大于1000的图像。
25.在一个具体的实施方式中,所述rate值为图像最长边与单字符高度的比值。
26.在一个具体的实施方式中,所述对roi区域识别出文字块,并对文字块进行排列包括:检测出每一行文字的位置;对每行的文字进行识别;按照从上到下,从左到右的顺序,依次对识别的文字进行排版和输出。
27.在一个具体的实施方式中,所述排列规则为:将token按照母token排列在前,子token排列在后。
28.在一个具体的实施方式中,所述子token为在母token中能找到的相同字段。
29.在一个具体的实施方式中,所述将识别出的文字块降维成一维长句,遍历token数
组,在一维的长句中找到token的具体位置包括:将识别出的文字块降维成一维长句,不同行之间采用在行首添加标识符进行标识;遍历token数组,在一维的长句中找到token的具体位置;遍历token数组,正对换行的特殊位置,找到隐藏的token位置;如果找到token,去除行首的标识符,同时同步更新后续的已经定位的token位置。
30.实施本实施例的原理描述:如图2所示, 首先训练一个对文字区域检测的模型,将图像送入到模型中,获取目标文字区域的大致位置。为了保证不漏检,将检测的文字区域进行外扩,并将扩大后的区域扣取出来,作为下一阶段的图像输入如图3所示,为文字区域的ocr识别的具体流程。首先定位出文字行的位置,并对文字行进行识别。最后再根据文字的坐标信息,对识别出的文字进行从左到右,从上到下的顺序排列如图4所示,为从识别出来的文字中,抽取出结构化信息。首先,识别出来的文字一般是个二维的矩阵,先将二维降为一维。根据需要提取的结构化信息,准备好对应的token list。该token list是按照优先级排列。母token排在前,子token排在后。
31.遍历token list,在一维的文字区域中,找出匹配的token位置。其次,针对含有连接符的字段,也遍历寻找隐藏的token。最终,在一维的字符向量中,能够准确定位出token的位置和其之间的相对关系。
32.最终,根据token,提取token对应的value值,完成对结构化信息的提取。
33.实施本发明,具有如下有益效果:1.本发明扩大识别区域,能够对超大的图像进行文字识别,利用token,能够实现对排版复杂多样的文档进行结构化信息的提取。
34.实施例2本实施例中,参考说明书附图1至附图4,本实施例所要解决的技术问题在于:1)不能检测出rate值高的图像中的文字的位置;2)目前的文字识别技术,只是简单的把文字信息进行逐行的识别,并没有对识别出的信息进行结构化提取。
35.提供一种超大图像的结构化信息提取方法,所述超大图像的结构化信息提取方法包括:通过神经网络模型定位文字区域位置;在文字区域中识别出roi区域;对roi区域识别出文字块,并对文字块进行排列;定义需求提取结构化信息需要的token,将token按照排列规则进行排列;将识别出的文字块降维成一维长句,遍历token数组,在一维的长句中找到token的具体位置;根据定位的token,分别提取其对应的结构化信息。
36.在一个具体的实施方式中,所述通过神经网络模型定位文字区域位置包括:训练神经网络模型,学习超大图像的文字区域的特征;
定位文字区域位置,对文字区域位置进行偏差调整形成识别区域。
37.在一个具体的实施方式中,所述定位文字区域位置,对文字区域位置进行偏差调整形成识别区域包括:定位文字区域位置;将文字区域的上下方向上分别扩展检测区域高度的25%;将文字区域的左右方向上分别扩展检测区域的宽度的25%;形成识别区域。
38.在一个具体的实施方式中,所述超大图像为rate值大于1000的图像。
39.在一个具体的实施方式中,所述rate值为图像最长边与单字符高度的比值。
40.在一个具体的实施方式中,所述对roi区域识别出文字块,并对文字块进行排列包括:检测出每一行文字的位置;对每行的文字进行识别;按照从上到下,从左到右的顺序,依次对识别的文字进行排版和输出。
41.在一个具体的实施方式中,所述排列规则为:将token按照母token排列在前,子token排列在后。
42.在一个具体的实施方式中,所述子token为在母token中能找到的相同字段。
43.在一个具体的实施方式中,所述将识别出的文字块降维成一维长句,遍历token数组,在一维的长句中找到token的具体位置包括:将识别出的文字块降维成一维长句,不同行之间采用在行首添加标识符进行标识;遍历token数组,在一维的长句中找到token的具体位置;遍历token数组,正对换行的特殊位置,找到隐藏的token位置;如果找到token,去除行首的标识符,同时同步更新后续的已经定位的token位置。
44.另一方面,本实施例还提供一种超大图像的结构化信息提取装置,所述超大图像的结构化信息提取装置包括:文字区域定位模块,用于通过神经网络模型定位文字区域位置;目标区域定位模块,用于在文字区域中识别出roi区域;文字块排序模块,用于对roi区域识别出文字块,并对文字块进行排列;整理模块,用于定义需求提取结构化信息需要的token,将token按照排列规则进行排列;token定位模块,用于将识别出的文字块降维成一维长句,遍历token数组,在一维的长句中找到token的具体位置;结构化信息提取模块,用于根据定位的token,分别提取其对应的结构化信息。
45.实施本实施例的原理描述:如图2所示, 首先训练一个对文字区域检测的模型,将图像送入到模型中,获取目标文字区域的大致位置。为了保证不漏检,将检测的文字区域进行外扩,并将扩大后的区域扣取出来,作为下一阶段的图像输入如图3所示,为文字区域的ocr识别的具体流程。首先定位出文字行的位置,并对文
字行进行识别。最后再根据文字的坐标信息,对识别出的文字进行从左到右,从上到下的顺序排列如图4所示,为从识别出来的文字中,抽取出结构化信息。首先,识别出来的文字一般是个二维的矩阵,先将二维降为一维。根据需要提取的结构化信息,准备好对应的token list。该token list是按照优先级排列。母token排在前,子token排在后。
46.遍历token list,在一维的文字区域中,找出匹配的token位置。其次,针对含有连接符的字段,也遍历寻找隐藏的token。最终,在一维的字符向量中,能够准确定位出token的位置和其之间的相对关系。
47.最终,根据token,提取token对应的value值,完成对结构化信息的提取。
48.本实施例相较于上一个实施例还提供一种装置,用于实现上述方法。
49.实施本发明,具有如下有益效果:本发明扩大识别区域,能够对超大的图像进行文字识别,利用token,能够实现对排版复杂多样的文档进行结构化信息的提取。
50.本发明未详述之处,均为本领域技术人员的公知技术。
51.最后所要说明的是:以上具体实施方式仅用以说明本发明的技术方案而非限制,尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改和等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。