1.本发明涉及一种基于音频智能识别搜索节目的方法,属于机顶盒视频技术领域。
背景技术:
2.随着信息化的高速发展,各终端设备均已智能化,衍生的应用、终端设备大部分都支持语音识别功能;在视频应用或网站中,传统的搜索节目是通过键盘、语音(片名、明星名、关键词)搜索;若不知任何节目信息,而通过某一细节却无法直接找到对应的节目,如听到某段音乐、经典台词,或看到某一精彩剪辑片段,想看其对应的节目视频,但不知道是某节目、某集次、某时间段,此情景下,传统的搜索节目方式已无法满足此需求,往往是在网站中进行搜索查找,看其对应的是某节目、集次、时间段,再去观看,整个过程比较繁琐;然而身边高速化运转的一切事物让用户越来越难以接受与“慢”相关的现象,越来越追求及时反馈。
技术实现要素:
3.本发明目的是提供了一种基于音频智能识别搜索节目的方法,不仅结构牢固不易分离,而且施工方便。
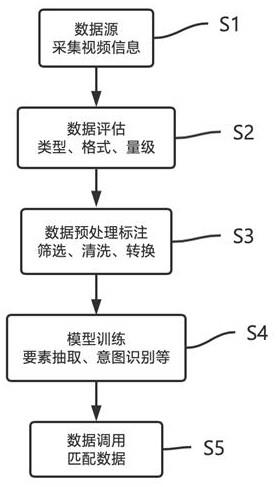
4.本发明为实现上述目的,通过以下技术方案实现:一种基于音频智能识别搜索节目的方法,其特征在于,包括以下步骤:1)将节目视频文件中存在诸多不同纬度的数据特征,通过深度采集视频数据信息,包含图像、音频、文本;2)对基础数据的类型及格式进行数据结构化预加工处理:清洗、筛选、转换、排序等;3)根据多模态特征融合理解结果对视频文件进行智能打标,输出多维度视频标签信息:音频指纹、视频片段关键词、对应时间戳的字幕,根据对文本的标记,并对相应视频进行自动标签、归类,形成媒资标签体系库;4)基于语音识别、语义理解技术,训练模型,构建语法,指定使用语法;5)唤醒设备,对终端设备说出指令词或音频数据,进行指令解析,提取关键词,识别其意图;进行识别检索,基于标签体系,识别结果只在指令信息列表中匹配;6)反馈识别结果,包含该指令信息中的所有节目或直接定位到对应台词、画面所在时间位置,以供用户选择或直接观看。
5.优选的,所述步骤2中基础数据的类型及格式进行数据结构化预加工处理具体步骤如下:2-1)对视频图像以cnn的网络结构实现vlad算法,netvlad可以通过聚类中心将视频序列特征转化为多个视频镜头特征,图像特征序列用lstm建模时序关系,输出是序列预测,activity recognition输出该段视频对应的标签;image description输出对图像的描述;video description输出对视频的描述,然后通过可以学习的权重对多个视频镜头加权
求和获得全局特征向量;2-2)对于音频信息,从视频中分离音频信号,使用vggish提取音频特征序列,使用netvlad提取不同镜头对应的音频特征,输出音频分类,语音转文本和歌曲音频指纹等;识别标点预测和智能断句,多语言及方言素材的语音信息提取,然后通过可学习的权重融合生成音频模态的全局特征向量;2-3)对于文本信息,将视频文字信息提取算法以ocr为基础模型,通过自然语言处理nlp算法模型进行预处理和后处理,智能识别视频中核心的文字内容信息,过滤其他干扰文字内容,并输出标题、人物和字幕三类文本内容和文本类别。
6.本发明的优点在于:对比现有搜索方式,增加了歌曲原声与哼唱、经典台词、行为画面等指令形式,结合视频标签体系,对媒资进行快速准确检索,提升视频检索的效率。
附图说明
7.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
8.图1为本发明流程结构示意图。
9.图2为本发明数据处理结构示意图。
具体实施方式
10.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
11.1)节目视频文件中存在诸多不同纬度的数据特征,通过深度采集视频数据信息,包含但不仅限于图像(人物、场景、行为)、音频(片头/片尾/插曲音乐、歌曲旋律、歌名、台词配音)、文本(字幕);2)对基础数据的类型及格式进行数据结构化预加工处理:清洗、筛选、转换、排序等;2-1)视频图像:以cnn的网络结构实现vlad算法,netvlad可以通过聚类中心将视频序列特征转化为多个视频镜头特征,图像特征序列用lstm建模时序关系,输出是序列预测,activity recognition输出该段视频对应的标签;image description输出对图像的描述;video description输出对视频的描述,然后通过可以学习的权重对多个视频镜头加权求和获得全局特征向量;2-2)音频信息:从视频中分离音频信号,使用vggish提取音频特征序列,使用netvlad提取不同镜头对应的音频特征,输出音频分类,语音转文本和歌曲音频指纹等;识别标点预测和智能断句,多语言及方言素材的语音信息提取,然后通过可学习的权重融合生成音频模态的全局特征向量;2-3)文本信息:视频文字信息提取算法以ocr为基础模型,通过自然语言处理nlp算法模型进行预处理和后处理,智能识别视频中核心的文字内容信息,过滤其他干扰文字内容,并输出标题、人物和字幕三类文本内容和文本类别;
3)根据多模态特征融合理解结果对视频文件进行智能打标,输出多维度视频标签信息:音频指纹、视频片段关键词、对应时间戳的字幕,根据对文本的标记,并对相应视频进行自动标签、归类,形成媒资标签体系库;4)基于语音识别、语义理解等技术,训练模型,构建语法,指定使用语法;5)唤醒设备,对终端设备说出指令词或音频数据,进行指令解析,提取关键词,识别其意图;如哼唱:“一段音乐节奏”,说出:打开“臣妾做不到啊”台词位置、我想看“长津湖中冰雕连”画面等;6)进行识别检索,基于标签体系,识别结果只在指令信息列表中匹配;7)反馈识别结果,包含该指令信息中的所有节目或直接定位到对应台词、画面所在时间位置,以供用户选择或直接观看。
技术特征:
1.一种基于音频智能识别搜索节目的方法,其特征在于,包括以下步骤:1)将节目视频文件中存在诸多不同纬度的数据特征,通过深度采集视频数据信息,包含图像、音频、文本;2)对基础数据的类型及格式进行数据结构化预加工处理:清洗、筛选、转换、排序等;3)根据多模态特征融合理解结果对视频文件进行智能打标,输出多维度视频标签信息:音频指纹、视频片段关键词、对应时间戳的字幕,根据对文本的标记,并对相应视频进行自动标签、归类,形成媒资标签体系库;4)基于语音识别、语义理解技术,训练模型,构建语法,指定使用语法;5)唤醒设备,对终端设备说出指令词或音频数据,进行指令解析,提取关键词,识别其意图;进行识别检索,基于标签体系,识别结果只在指令信息列表中匹配;6)反馈识别结果,包含该指令信息中的所有节目或直接定位到对应台词、画面所在时间位置,以供用户选择或直接观看。2.根据权利要求1所述的基于音频智能识别搜索节目的方法,其特征在于,所述步骤2中基础数据的类型及格式进行数据结构化预加工处理具体步骤如下:2-1)对视频图像以cnn的网络结构实现vlad算法,netvlad可以通过聚类中心将视频序列特征转化为多个视频镜头特征,图像特征序列用lstm建模时序关系,输出是序列预测,activity recognition输出该段视频对应的标签;image description输出对图像的描述;video description输出对视频的描述,然后通过可以学习的权重对多个视频镜头加权求和获得全局特征向量;2-2)对于音频信息,从视频中分离音频信号,使用vggish提取音频特征序列,使用netvlad提取不同镜头对应的音频特征,输出音频分类,语音转文本和歌曲音频指纹等;识别标点预测和智能断句,多语言及方言素材的语音信息提取,然后通过可学习的权重融合生成音频模态的全局特征向量;2-3)对于文本信息,将视频文字信息提取算法以ocr为基础模型,通过自然语言处理nlp算法模型进行预处理和后处理,智能识别视频中核心的文字内容信息,过滤其他干扰文字内容,并输出标题、人物和字幕三类文本内容和文本类别。
技术总结
本发明提供了一种基于音频智能识别搜索节目的方法,其特征在于,包括:获取节目视频资源;采集提取视频中不同类型的基础数据信息;经过模型训练,输出多维度视频标签,形成标签库;通过指令词或音频数据,进行识别检索,匹配出结果。本发明对比现有搜索方式,增加了歌曲原声与哼唱、经典台词、行为画面等指令形式,结合视频标签体系,对媒资进行快速准确检索,提升视频检索的效率。升视频检索的效率。升视频检索的效率。
技术研发人员:陶文文 杜丽娜 刘喆 胡中涛 谢恩鹏 修志远 韩昭瑞
受保护的技术使用者:山东浪潮超高清视频产业有限公司
技术研发日:2022.02.21
技术公布日:2022/5/31
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。