1.本发明涉及不动产交易预测技术领域,特别涉及一种基于大数据知识追踪的不动产交易预测方法。
背景技术:
2.随着大数据时代的到来,信息呈现爆炸式增长,加上计算机科学技术的普及化,信息公开透明化,让获得大量研究数据的途径越来越多,越来越便利。而且随着人工智能技术的不断发展,已经产业化很多产品,如在智能家居,智能交通,智能教育等方面,可以说我们正在步入人工智能时代。而人工智能技术的快速发展离不开大数据的支撑,数据信息载体最常见的形式包括图像,视频,语音和文字等,基于不同的数据形式,产生了不同的研究方向,如计算机视觉,自然语言处理,机器翻译等,而且在很多领域人工智能都已取得了显著的成效,正因如此,未来各行业人工智能化将成为产业的发展趋势。
3.不动产作为一种最常见又极其重要的经济载体,在人民的生活中扮演着重要的角色。中国经济开始突飞猛进式增长,目前已成为世界第二大经济体。伴随着国家经济水平的快速发展,城市化进程也得到了迅速发展,从而推动不动产交易随着时间发生巨大的改变。其中房地产作为不动产的表现形式之一,在社会中扮演着重要的角色。因此,如果可以智能预测房地产交易,对于政府,市场调控,人民交易都有巨大好处。但由于其不确定因素较多,因此目前鲜有方法从事该方面的研究,大多是基于总结规律得出的。而该方法由于太直观,很难挖掘到深层的有用信息,因此在预测性能方面较差。
技术实现要素:
4.本发明为了弥补现有技术的不足,提供了一种操作可行、预测准确、性能较好的基于大数据知识追踪的不动产交易预测方法。
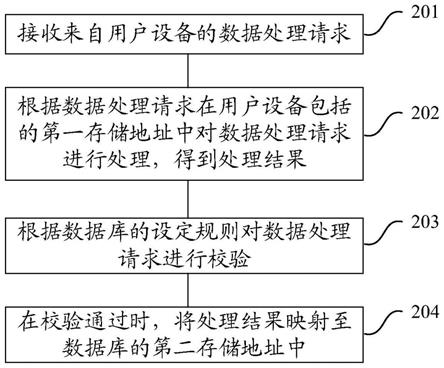
5.本发明是通过如下技术方案实现的:一种基于大数据知识追踪的不动产交易预测方法,包括如下步骤:(1)从公开网站爬取需要的信息数据;(2)对获得的原始数据进行格式标准化处理,同时过滤掉噪声数据,并将其整理成文本数据;(3)对文本数据使用bert库,获取其对应的向量表示;(4)利用循环神经网络lstm对数据进行学习,获得隐状态表示,即纵向表示学习;(5)根据数据的向量表示,计算数据间的相似度,匹配相似的地区特征表示,得到相似数据后,作为外部辅助信息,加入到自己信息中,即横向表示学习;(6)将纵向表示学习和横向表示学习按照权重融合,获得当前时刻的特征表示,将该特征表示经过非线性变化后,进行趋势预测,判断下一时间段交易的趋势。
6.由于城市间的发展模式有着某些共性,例如城市生产总值、城市常住人口规模、城市人口密度以及公共设施、公共服务等软标准,往往发展水平相似的城市,在这些方面也相
似,这些因素都对不动产交易有着重要的影响,而这些因素是随着时间动态变化的,也就导致不动产交易随着时间动态变化。通过对包含这些因素的海量数据进行挖掘、不断追踪,就可以预测出下一阶段的交易情况。
7.为此,本发明采用基于大数据知识追踪方法,动态掌握不动产的交易情况,从而实现交易预测,线束描述均已房地产交易微粒进行研究。具体来说,本发明的预测方法分为两个方向,一个是纵向,另一个是横向。纵向是固定空间范围,动态追踪时间维度的变化;横向是固定时间维度,对比匹配空间特征,挖掘协同信息,从而提升模型的预测性能。数据原始输入均为包含空间范围内影响房地产交易的因素,可以认为设定n个因素,例如人口规模、人口密度、经济总量、软服务等,然后将其按时间先后排序组成一个序列数据,通过对序列数据进行建模,来预测下一阶段交易趋势变化。
8.进一步优选的,步骤(1)中,信息数据包括房地产交易数据和所在区域的公共参数,公共参数包括人工规模变化、经济水平变化。
9.进一步优选的,步骤(2)中,文本数据的表现形式为一篇文章表述;由于原始数据中大部分属性值为连续性,为此可分为两种处理方式,第一种对连续值进行分段评级,处理成离散值;另一种方式是保留原数据。
10.进一步优选的,步骤(3)中,将文本按照时间先后排列组成序列数据,然后使用bert库分别获得对应的向量表示,组成二维数据表示。
11.本发明基于深度学习方法进行时序建模,采用最基础的循环神经网络lstm对特征进行学习,获得高层特征表示。
12.由于只考虑自身因素在时间维度上的变化进行建模,性能不好,而且泛化性能较差,为此,本发明加入了协同信息,辅助追踪建模,进一步优选的,步骤(5)中,数据间的相似度分两种,一种是保证时间维度相同,匹配相似的地区特征表示,另一种是不保证时间维度相同,匹配相似的地区特征表示,即包含在相同时间段,较为相似的地区,以及在不同时间段,相似的地区,将这两部分信息加入到自身信息中,共同完成预测,通过该方式可以更好的提升模型性能。
13.进一步优选的,步骤(6)中,权重设置为一个超参,融合方式使用简单求和,获得当前时刻的特征表示。利用当前时刻的表示经过非线性变化,来判断下一时间段交易的趋势,该趋势是相对于前一时间段,这样可以递推获得整个房地产的交易趋势。
14.与现有技术相比,本发明的有益效果是:本发明基于大数据知识追踪的不动产交易预测,对大数据进行挖掘,获取有用信息,利用知识追踪原理,建模房地产交易随时间变化的动态趋势,同时加入协同信息,利用相似地区在相同时间维度和不同时间维度的交易信息,增强自身的信息表示,从而提升模型的预测性能。
15.此外,本发明所涉及到的研究数据可以方便的在网上获得,因此研究成本交底,提供了一种可行的、性能较好的房地产交易预测方法。
附图说明
16.下面结合附图对本发明作进一步的说明。
17.图1为本发明预测方法的流程示意图;
图2为本发明的模型框架示意图。
具体实施方式
18.下面结合附图与实施例对本发明做进一步说明。在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
19.应该指出,以下详细说明都是示例性的,旨在对本发明提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同含义。
20.如图1所示,本发明实施例中的基于大数据知识追踪的不动产交易预测方法,包括如下步骤:s1:获取数据从网上公开网站爬取需要信息数据,包含房地产交易数据,以及所在区域的公共参数,本发明实施例中主要使用了包含人口规模,经济总量,区域面积,小区位置,小区周边公共服务设施,交通状况以及居民评价信息。
21.s2:数据预处理对获得的原始数据进行格式标准化处理,具体为将每种公共参数都作为一种特征属性,以字典的数据结构存储,其key为属性名,如“人口规模”,value为属性描述,如“人口规模为500万”,其它属性类似进行操作。同时过滤掉噪声数据,主要指属性值缺乏的数据。
22.最后根据属性数据生成一篇文章表述:,其中,n为特征个数,si表示为第i个属性的文本描述。那么每条输入数据可表示为:,t为时间长度。
23.由于房地产交易价格是一个连续值,为此本发明以统计数据中的最低房价为区间最低值,然后每1000递增,定义为一个子区间,每个区间对应一个等级,并根据实际数据设置最大上限,若超过最大上限,则统一归为一个最高等级,若低于最小下限,则统一归为一个最低等级,从而将回归问题转化为等级分类问题,区间大小1000,是一个参数,可以调整。根据交易价格所在区间为数据进行真实值标注。
24.s3:数据向量化本发明对文本数据使用bert库,获取其对应的向量表示;具体为将原始输入数据,经过bert模型表示,得到,,d为向量表示的维度。
25.s4:特征表示学习本发明将处理的数据按照时间先后排列组成序列数据,并根据数据层次结构划分为两级,第一级为每个时间段的数据表示,第二级为所有时间段的数据表示。本发明利用层级注意力网络(hierarchical attention network, han)对上述数据进行学习。首先通过第一级网络获得每个属性描述的隐状态表示,那么对每个时间段的整篇描述可得到的表示
为,,n为属性个数,对每个属性利用注意力机制获得对应权重α,然后根据相应权重加权获得整篇文章的表示,h为表示维度,如式(1):
ꢀꢀꢀꢀ
(1)然后将所有时间段得到的表示作为下一层级网络的输入,经过网络学习可获得,,t为时间长度。类似地对该层级网络的隐层表示利用注意力机制获得相应的权重α',然后根据权重计算获得最终的表示,o为表示维度,如式(2):
ꢀꢀꢀ
(2)值得注意的是计算该表示时,要保证看不到未来信息,即利用过去的信息来表示未来,所以需要利用一个mask变量,从而保证未来信息不会被泄露。
26.由于该模块的特征学习表示只利用到自己的历史数据,即根据建模历史信息来预测未来,这是一个从0到t的过程,本发明将其称为纵向表示学习。
27.s5:加入协同信息本发明为了丰富特征表示,提升模型的准确率,加入了协同信息。具体过程是根据数据的向量表示,计算数据间的相似度。主要分为两种,其一是保证时间维度相同,匹配相似的地区特征表示,其二是不保证时间维度相同,匹配相似的地区特征表示。在计算相似度时,本发明利用内积的方式,分别根据上述两种情况对特征进行计算,获得特征间的相似度值。保证时间维度相同,匹配相似地区的特征表示的启发是基于在属性相似的地区,他们在相同的时间段内应该有着相似的房地产交易表现;不保证时间维度相同,匹配相似地区的特征表示的启发式基于在城市发展程度不同的地区,在错位时间段上有着相似的交易表现,例如一个较为发达的地区,可能在十年前的交易数据与一个不太发达的地区当前的交易数据相近。基于这两种启发,本发明分别计算特征间的相似度,并融合topk个数据作为辅助信息,k为超参。其计算公式如式(3-4):
ꢀꢀꢀꢀ
(3)
ꢀꢀꢀꢀꢀꢀꢀ
(4)其中为待计算特征。由于该特征是通过计算与不同数据的相似度,来获得相似特征作为辅助信息,本发明将其称为横向表示学习。
28.s6:预测s4和s5分别获得了纵向和横向信息表示,把这两部分按照权重融合,权重可以设置为一个可学习的超参β,根据式(5)计算得到最后的特征表示。
29.ꢀꢀꢀꢀ
(5)将该表示经过非线性变化后,进行价格等级预测。
30.以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。