一种基于risc-v和神经形态计算的异构架构处理系统
技术领域
1.本发明属于集成电路技术与神经网络技术领域,具体涉及一种基于risc-v和神经形态计算的异构架构处理系统。
背景技术:
2.近年来物联网设备保持快速增长,在现有的应用场景中,物联网设备多数采取连接网络的方式以获得智能,这对接入网络和主干网络施加了极大的压力,延迟通常也难以接受,因此边缘计算需要承担更多功能,如图像处理、语音识别等。但边缘计算通常受到机器尺寸和电池容量的限制,计算性能较弱,选择较少。
3.神经网络尤其是神经形态计算作为一种非冯诺依曼计算体系,具有与cpu完全不同的架构,在实现ai性能方面具有面积、功耗优势的同时却通常作为分立芯片存在,同时也无法取代通用cpu在通用计算、外设控制、可编程性上的生态优势,因此如何高效集成神经形态架构与通用cpu架构成为制约边缘ai进一步发展的重要因素。
4.通过消除不必要的指令,具有较少数量晶体管的risc-v处理器消耗的功率通常很低,因此risc-v处理器更适合小型边缘计算设备。此外,选择轻量化神经网络模型以减小硬件开销也能极大的降低功耗。近年来对以生物神经元为理论基础的snn(spiking neural network,脉冲神经网络)的研究引起了广泛关注。现已有将神经网络二值化(即将输入图像或权重参数转化为0或1)的同时实现了高准确率识别的案例。神经形态计算通过模拟人脑的运行方式,基于脉冲传递信息,从而规避了复杂且功耗较高的乘法运算,且硬件设计难度更低。
技术实现要素:
5.针对上述问题,本发明提出了一种基于risc-v和神经形态计算的异构架构处理系统,用于解决神经形态加速器和通用cpu之间的集成难题,同时满足性能与功耗的要求,可以兼容多种不同结构和深度的神经网络的快速部署,可用于边缘设备的语音识别、图像识别和安防监控等领域。本发明要解决的主要问题,在于如何高效集成神经形态架构与通用cpu架构。
6.本发明的异构系统的技术方案为:
7.一种基于risc-v和神经形态计算的异构架构处理系统,所述神经形态协处理器包含由一组神经形态计算单元组成的计算单元阵列和负责根据自定义指令驱动网络与数据流的调度组件。所述调度组件接收来自risc-v处理器的自定义指令,并根据指令译码确定指令功能,分配功能到各单元和计算单元阵列。计算单元阵列按照指令配置的连接关系和逻辑连接顺序执行神经形态计算,同时调度组件按照架构配置定义的顺序,计算出计算单元编号,从存储器中取出相应的权重等数据,计算完成后按照指令将计算结果返回给risc-v处理器。
8.进一步的,所述计算单元阵列为若干个基于lif神经元模型的脉冲计算单元组成
的规模化网络,并且任意两个计算单元之间的都可以进行数据交互,在部署特定网络时可以配置计算单元之间的连接关系,从而映射不同结构的网络。
9.进一步的,所述调度组件包括了用于解析risc-v自定义指令的指令解析单元、读取外部数据的存储器控制单元、传递数据到每个计算单元的数据分发单元、缓存外部数据的缓存单元,调度组件接受来自risc-v处理器的自定义指令,并根据指令使能各功能单元,同时启用和调度计算单元阵列,管理数据的传输,当计算完成后将结果返回给risc-v处理器。
10.所述存储器特征为常见存储器,存储有训练好的智能网络算法的配置和权重数据,以及在执行推理计算时的输入数据。
11.进一步的,所述指令解析单元包含了指令接收单元、指令返回单元、指令译码单元和网络调度单元;指令解析单元接受来自risc-v的自定义指令,并根据指定功能相应使能存储器控制单元,数据分发单元和计算单元阵列。指令接收单元直接接收来自risc-v处理器的指令数据。指令译码单元将指令转化为各单元的使能信号,并将指令信息转发到相应单元。指令返回单元根据指令功能、计算状态、计算结果返回指令结果到risc-v处理器。网络调度单元连接调度组件和计算单元阵列,读取指定核心的计算结果。
12.进一步的,所述存储器控制单元包含了地址生成单元、协议控制单元和包处理单元。存储控制器单元根据当前计算单元阵列的状态和自定义指令功能,由地址生成单元计算出计算单元所需数据的地址计算出来,协议控制单元将特定编号的计算单元所需的数据从相应地址中读出,经包处理单元解包后,通过缓存单元交由数据分发单元派发给相应计算单元。
13.所述数据分发单元包含了核心编号生成单元和包校验单元。数据分发单元从缓存单元中接收来自外部的参数、权重和输入数据,依据核心编号生成单元得出的计算单元编号,将数据送入计算单元阵列,同时包校验单元监控数据包的数据和长度是否正确。
14.所述缓存单元为一个具有ping-pong缓存能力的缓存器,接收来自存储器控制器单元的数据,完成数据的缓冲及时钟域的过渡后转交给数据分发单元。
15.所述指令接收单元直接接收来自risc-v处理器的指令数据。
16.所述指令译码单元将指令转化为各单元的使能信号,并将指令信息转发到相应单元。
17.所述指令返回单元根据指令功能、计算状态、计算结果返回指令结果到risc-v处理器。
18.所述网络调度单元连接调度组件和计算单元阵列,根据返回结果指令的要求读取指定核心的计算结果。
19.所述地址生成单元根据计算单元阵列的计算规则推导出神经元编号,并计算生成存储器读取地址。
20.所述协议控制单元根据接口协议读写生成地址中的数据。
21.所述包处理单元负责数据包的重组,根据所需的数据类型和数据存储位宽拼接相应数据。
22.所述核心编号生成单元计算得出当前数据包所指向的计算单元阵列核心编号。
23.所述包校验单元负责校验数据和包长度,并根据计算出的核心编号发送到指定计
算单元。
24.进一步的,拓展指令包括用于复位网络的复位指令、用于初始化网络的初始化指令、用于启动计算单元阵列的计算指令和结果返回指令。
25.所述复位指令,包括复位指定的计算单元和调度网络。
26.所述初始化指令,包括设定计算单元连接关系;配置每个计算单元的神经元参数;配置每个计算单元的聚类和权重值;使能相应计算单元。
27.所述计算指令,包括设定输入数据;启动计算计算单元阵列进行计算。
28.所述结果返回指令,包括返回特定计算单元结果。
29.上述异构架构处理系统的工作流程主要步骤包括:
30.risc-v处理器需要执行神经形态加速计算;
31.发送初始化指令;
32.发送计算指令;
33.发送结果返回指令;
34.risc-v处理器加速计算完成。
35.本发明的有益效果为,本发明实现了一种基于risc-v和神经形态协处理器的异构架构,具有低功耗、可配置、高通用的特点。其特征在于,risc-v处理器可以进行软件编程,并且可以通过自定义指令接口,调用所述可重构的神经形态协处理器,从而实现低功耗、可配置、高通用的异构系统。
附图说明
36.图1为本发明实施例中异构系统的整体结构框图
37.图2为本发明实施例中集成的计算单元阵列架构示意图
38.图3为本发明实施例中神经形态协处理器的结构框图
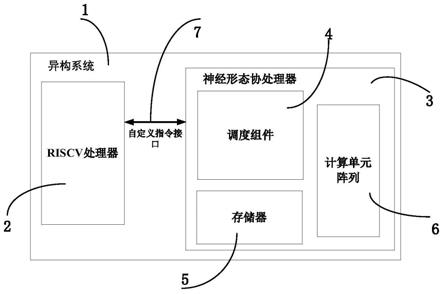
39.图4为本发明实施例中指令解析单元结构框图
40.图5为本发明实施例中数据分发单元结构框图
41.图6为本发明实施例中存储器控制单元结构框图
42.图7为本发明实施例中神经形态协处理器的工作流程图
43.具体实现方式
44.本发明的具体实现方法如下:
45.本发明要实现的主要内容,在于实现一种基于risc-v和神经形态协处理器的低功耗、可配置、高通用的异构系统。其特征在于,risc-v处理器2可以进行软件编程,并且可以通过自定义指令接口7,调用所述可重构的神经形态协处理器3,从而实现了低功耗、可配置、高通用的异构系统1。
46.本发明的异构系统的技术方案为:
47.一种基于risc-v及其扩展指令和神经形态协处理器的可配置异构系统,如图1所示,其特征在于,包含一个可供risc-v指令集的处理器2调用的神经形态协处理器3。risc-v处理器2执行通用计算和指令,可以进行软件编程实现功能灵活变化,并可以通过自定义拓展汇编指令控制神经形态协处理器3。当执行需要调用神经形态协处理器3执行神经网络运算的代码时,risc-v处理器2将启用自定义指令,将命令、数据发送到神经形态协处理器3,
启动内核执行智能网络算法,并将网络运算结果返回risc-v处理器2。
48.所述神经形态协处理器3其特征在于,包括调度组件4、存储器5和计算单元阵列6。当risc-v处理器2需要启用神经形态协处理器3时,将执行用于调度神经形态协处理器的自定义指令,通过自定义指令接口7发送相关指令和数据到调度组件,调度组件4将解析并调度计算单元阵列6,同时在计算的过程控制从存储器5中读入参数数据并输入到计算单元阵列6,待计算完成后将计算结果直接返回给risc-v处理器2。
49.所述计算单元阵列6为若干个基于lif(leaky integrate and fire)神经元模型的脉冲计算单元11组成的规模化网络,如图2所示,并且任意两个计算单元之间的都可以通过片上网络8进行数据交互,在部署特定网络时可以配置计算单元之间的连接关系,从而映射不同结构的网络。
50.所述调度组件4其特征在于,包括了用于解析risc-v自定义指令的指令解析单元12、读取外部数据的存储器控制单元15、传递数据到每个计算单元的数据分发单元13、缓存外部数据的缓存单元14,如图3所示。调度组件4接受来自risc-v处理器2的自定义指令,并根据指令使能各功能单元,同时启用和调度计算单元阵列3,管理数据的传输,当计算完成后将结果返回给risc-v处理器2。
51.所述存储器5特征为任意普通存储器,存储有训练好的智能网络算法的配置和权重数据,以及在执行推理计算时的输入数据,调度组件通过地址访问相应参数。
52.所述指令解析单元12特征在于,包含了指令接收单元、指令返回单元、指令译码单元和网络调度单元,如图4所示。指令解析单元通过自定义指令接口7接受来自risc-v的自定义指令,并根据指定功能通过控制信号23使能存储器控制单元15,通过控制信号18使能数据分发单元13;同时通过数据总线17调度并读取计算单元阵列6。
53.所述存储器控制单元15特征在于,包含了地址生成单元、协议控制单元和包处理单元,如图5所示。存储控制器单元接收来自控制信号23的使能信号和来自数据信号21的校验信息,根据当前计算单元阵列的状态,将特定编号的计算单元所需的数据通过数据总线24从相应地址中读出,并通过数据总线22转发到缓冲单元14,之后交由数据分发单元13派发给相应计算单元。
54.所述数据分发单元13特征在于,包含了核心编号生成单元和包校验单元,如图6所示。数据分发单元通过控制信号18与指令解析单元12交互,同时通过数据总线20接受来自外部的参数、权重和输入数据,若校验出错通过数据信号21送出相应信息,数据呜呜时通过数据总线19,在特定时间派发给相应计算单元。
55.所述缓存单元14其特征为一个具有ping-pong缓存能力的缓存器,负责从存储控制器单元中完成数据的缓冲及时钟域的过渡,并转发给数据分发单元13。
56.表1自定义指令表
[0057][0058]
进一步的,本发明实施例中采用的拓展指令如表1所示,包括用于复位网络的复位指令、用于初始化网络的初始化指令、用于启动计算单元阵列的计算指令和结果返回指令。
[0059]
所述复位指令,包括复位指定计算单元和调度网络,定义为reet指令。
[0060]
所述初始化指令,包括设定计算单元连接关系,定义为coct指令;配置每个计算单元的神经元参数,定义为paer指令;配置每个计算单元的聚类后权重值,定义为weht指令;使能相应计算单元,定义为enle指令。
[0061]
所述计算指令,包括设定输入数据,定义为acty指令;启动计算单元阵列进行计算,定义为cote指令。
[0062]
所述结果返回指令,包括返回特定计算单元结果,定义为rern。
[0063]
进一步的,cote指令的操作数r1为相连的前计算单元编号,操作数r2为后计算单元编号,操作数rd保留。
[0064]
paer指令的操作数r1为计算单元编号标志,操作数r2为对应的参数起始地址,操作数rd保留。
[0065]
weht指令的操作数r1为计算单元编号标志,操作数r2为权重起始地址,操作数rd保留。
[0066]
enle指令的操作数r1为计算单元使能标志,每一位代表相应编号的计算单元,操作数r2保留,操作数rd保留。
[0067]
acty指令的操作数r1为输入计算单元编号,操作数r2为输入数据起始地址,操作数rd保留。
[0068]
cote指令的操作数r1为突触类型数据起始地址,操作数r2保留,操作数rd保留。
[0069]
rern指令的操作数r1为要读取的计算单元编号,操作数r2保留,操作数rd为读取到的结果。
[0070]
所述计算单元使能标志,均采用独热码标识对应序号计算单元,即操作数n位为1,说明编号n的计算单元参与此次自定义指令。
[0071]
进一步的,如图7所示,本发明还提供了一种神经形态协处理器的工作流程,应用于所述异构系统。主要步骤及实现为:
[0072]
步骤25:risc-v处理器需要执行神经形态加速计算,通过自定义协处理器接口启动神经形态协处理器;
[0073]
步骤26:通过自定义协处理器接口,发送初始化指令;依次发送coct指令,设定计算单元连接关系;发送paer指令,配置每个计算单元的神经元参数;发送weht指令,配置每个计算单元的聚类后权重值;发送enle指令,使能启用的计算单元;
[0074]
步骤27:通过自定义指令接口发送计算指令;依次发送acty指令,设定输入数据;发送cote指令,启动计算单元阵列进行计算;
[0075]
步骤28:通过自定义指令接口发送结果返回指令;发送rern指令,从指定计算单元中读取结果;
[0076]
步骤29:risc-v处理器加速计算完成。
[0077]
本发明具有如下优点:
[0078]
1.本发明实现的异构网络架构通过采用自定义指令实现了神经形态协处理器和risc-v处理器的集成,很好的结合了两种具有功耗优势的计算架构,实现了低功耗的异构神经网络系统。
[0079]
2.本发明实现的异构系统中的神经形态协处理器具有可配置性,并且支持通过自定义指令进行软件编程,可以方便适配不同结构和规模的网络及算法,解决了传统神经网络加速器中电路固定的缺点,具有较高的通用性。
[0080]
3.本发明实现的异构系统通过risc-v的可拓展自定义指令实现了将神经形态协处理器融入到通用指令集中,相较于基于总线外挂的集成方式有更快的处理速度和更低的延时。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
