1.本发明涉及语音识别技术领域,具体涉及一种结合瞬时频率的多通道语音识别方法。
背景技术:
2.近年来,基于深度神经网络(deep neural network,dnn)的声学模型建模方法已经在语音识别领域取得了突出的成果。长短时记忆模型(long shortterm memory,lstm)等复杂神经网络的提出进一步提升了声学模型的能力。然而,由于背景噪声,混响以及人声干扰等因素,远场语音识别任务仍然充满挑战。
3.与单麦克风采集语音信号相比,多麦克风录制的数据可以提供额外的空间信息。因此,通常采用麦克风阵列提升对远场语音信号的识别准确率。然而,现有技术中,对于语音信号的特征提取不充分,影响语音识别的准确度。
技术实现要素:
4.本发明的目的就在于解决上述背景技术的问题,而提出一种结合瞬时频率的多通道语音识别方法,丰富语音信号的特征,提升语音识别的准确度。
5.本发明的目的可以通过以下技术方案实现:
6.本发明提供了一种结合瞬时频率的多通道语音识别方法,该方法包括:
7.获取麦克风阵列中的每个单通道的原始频域语音信号作为目标语音信号;
8.估计每个单通道的目标语音信号的瞬时频率,根据所述瞬时频率提取瞬时频率特征;
9.根据每个单通道的目标语音信号提取mel特征;
10.组合所述mel特征和所述瞬时频率特征,得到目标特征;
11.将所述目标特征输入预设的声学模型,获得语音识别结果。
12.可选地,在获取麦克风阵列中的每个单通道的原始频域语音信号作为目标语音信号之前,所述方法还包括:
13.获取麦克风阵列中的每个单通道时域的语音信号,作为原始时域语音信号;
14.对所述原始时域语音信号进行预加重处理和分帧,对分帧后的每帧语音信号加窗,对加窗后的每帧语音信号进行快速傅里叶变换,得到每个单通道频域的原始语音信号,作为原始频域语音信号。
15.可选地,估计每个单通道的目标语音信号的瞬时频率,根据所述瞬时频率提取瞬时频率特征,包括:
16.针对每个单通道,计算该单通道和其他单通道之间的交叉teager能量算子;
17.将期望最小的交叉teager能量算子作为gabor滤波器的滤波系数对该单通道的目标语音信号进行解调,得到该单通道的目标语音信号的瞬时频率;
18.根据该单通道的瞬时频率提取该单通道的瞬时频率特征。
19.可选地,每个单通道的目标语音信号包括多个子信号;
20.针对每个单通道,计算该单通道和其他单通道之间的交叉teager能量算子,包括:
21.针对每个单通道,根据能量算子公式计算该单通道的能量算子;其中,x(t)为目标语音信号的任意子信号,为x(t)的一阶导数,为x(t)的二阶导数;
22.根据该单通道的能量算子、其他任意单通道的能量算子和交叉teager 能量算子公式计算该单通道和各个其他单通道之间的交叉teager能量算子。
23.可选地,根据每个单通道的目标语音信号提取mel特征,包括:
24.针对每个单通道的目标语音信号,使用mel滤波器对该单通道的目标语音信号进行滤波,得到mel域频谱;
25.对mel域频谱取log对数,然后进行离散余弦变换得到该单通道的mel 特征。
26.可选地,组合所述mel特征和所述瞬时频率特征,得到目标特征,包括:
27.将所述麦克风阵列中各个通道提取的mel特征并联,得到规整的多通道 mel特征;
28.将所述多通道mel特征与各个单通道的瞬时频率特征并联,得到目标特征。
29.基于本发明的一种结合瞬时频率的多通道语音识别方法,获取麦克风阵列中的每个单通道频域的离散语音信号作为目标语音信号;估计每个单通道的目标语音信号的瞬时频率,根据瞬时频率提取瞬时频率特征;根据每个单通道的目标语音信号提取mel特征;组合mel特征和瞬时频率特征,得到目标特征;将目标特征输入预设的声学模型,获得语音识别结果。通过瞬时频率提取瞬时频率特征,并将瞬时频率特征和mel特征组合进行语音识别,丰富了语音信号的特征,提升了语音识别的准确度。
附图说明
30.下面结合附图对本发明作进一步的说明。
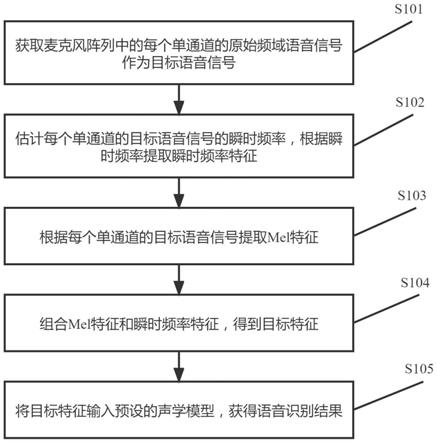
31.图1为本发明实施例提供的一种结合瞬时频率的多通道语音识别方法的流程图;
32.图2为本发明实施例提供的另一种结合瞬时频率的多通道语音识别方法的流程图。
具体实施方式
33.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
34.本发明实施例提供了一种结合瞬时频率的多通道语音识别方法。参见图 1,图1为本发明实施例提供的一种结合瞬时频率的多通道语音识别方法的流程图。该方法包括以下步骤:
35.s101,获取麦克风阵列中的每个单通道的原始频域语音信号作为目标语音信号。
36.s102,估计每个单通道的目标语音信号的瞬时频率,根据瞬时频率提取瞬时频率
特征。
37.s103,根据每个单通道的目标语音信号提取mel特征。
38.s104,组合mel特征和瞬时频率特征,得到目标特征。
39.s105,将目标特征输入预设的声学模型,获得语音识别结果。
40.基于本发明实施例的多通道语音识别方法,可以通过瞬时频率提取瞬时频率特征,并将瞬时频率特征和mel特征组合进行语音识别,丰富语音信号的特征,提升语音识别的准确度。
41.一种实现方式中,麦克风阵列获取到的是连续的原始时域语音信号,进过预处理后可以得到离散的原始频域语音信号。
42.一种实现方式中,目标语音信号可以建模为叠加带限am-fm信号的组合,根据能量分离算法可以从目标语音信号中估计瞬时频率。
43.一种实现方式中,通过提取mfcc(mel frequency cepstral coefficient,梅尔倒谱系数特征)可以得到目标语音信号的音频特征。
44.一种实现方式中,预设的声学模型可以根据实际情况进行选择,在此不作限定。例如,预设的声学模型可以是lstm(long short term memory,长短时记忆模型)。
45.在一个实施例中,在步骤s101之前,该方法还包括以下步骤:
46.步骤一,获取麦克风阵列中的每个单通道时域的语音信号,作为原始时域语音信号。
47.步骤二,对原始时域语音信号进行预加重处理和分帧,对分帧后的每帧语音信号加窗,对加窗后的每帧语音信号进行快速傅里叶变换,得到每个单通道频域的语音信号,作为原始频域语音信号。
48.一种实现方式中,预加重的目的是对语音信号的高频部分进行加重,去除口唇辐射的影响,增加语音信号的高频分辨率,保持从低频到高频的整个频带中,能用同样的信噪比求频谱,提高信号传输质量。预加重处理可以将语音信号通过一个高通滤波器:x
p
(n)=x(n)-k(n-1),k可以取0-1之间的任何数字,语音处理通常使用0.9-0.97。
49.分帧的时间间隔可以为20ms-40ms之间,可以由技术人员根据经验进行设置。
50.将分帧后的每帧语音信号与一个平滑的窗函数相乘,可以使每帧两端平滑地衰减到零,降低傅里叶变换后旁瓣的强度,获得更高质量的频谱。常用的窗函数有矩形窗、汉明窗、汉宁窗、高斯窗等。例如,汉明窗为其中α=0.53836,β=0.46164。
51.在一个实施例中,参见图2,在图1的基础上步骤s102包括:
52.s1021,针对每个单通道,计算该单通道和其他单通道之间的交叉teager 能量算子。
53.s1022,将期望最小的交叉teager能量算子作为gabor滤波器的滤波系数对该单通道的目标语音信号进行解调,得到该单通道的目标语音信号的瞬时频率。
54.s1023,根据瞬时频率提取该单通道的瞬时频率特征。
55.一种实现方式中,交叉teager能量算子可以用于表示两个单通道的目标语音信号之间的相互作用。通过使用期望最小的交叉teager能量算子对目标语音信号进行解调,可
以减小由于噪声引起的解调误差,提高瞬时频率特征的鲁棒性。
56.在一个实施例中,每个单通道的目标语音信号包括多个子信号,步骤 s1021包括:
57.步骤一,针对每个单通道,根据能量算子公式计算该单通道的能量算子。
58.步骤二,根据该单通道的能量算子、其他任意单通道的能量算子和交叉 teager能量算子公式计算该单通道和其他单通道之间的交叉teager能量算子。
59.其中,x(t)为目标语音信号的任意子信号,为x(t)的一阶导数,为 x(t)的二阶导数。
60.一种实现方式中,每个单通道的目标语音信号为包括多个子信号的离散信号,根据能量算子公式可以计算出该单通道的子信号的teager能量算子。目标语音信号的能量算子即为所有子信号的teager能量算子的组合。
61.一种实现方式中,对于任意两个单通道,目标语音信号的多个子信号是一一对应的。例如,第一单通道的目标语音信号依次包括子信号1、子信号2、子信号3和子信号4,第二单通道的目标语音信号依次包括子信号5、子信号 6、子信号7和子信号8,则子信号1和子信号5对应、子信号2和子信号6 对应、子信号3和子信号7对应以及子信号4和子信号8对应。
62.对于任意一对子信号,通过对比该一对子信号的teager能量算子, teager能量算子小的作为x1(t),另一个作为x2(t)。使用上述交叉teager能量算子公式即可求得该一对子信号的交叉teager能量算子。任意两个单通道的目标语音信号的交叉teager能量算子,即为所有子信号对的交叉teager 能量算子的组合。
63.在一个实施例中,步骤s103包括:
64.步骤一,针对每个单通道的目标语音信号,使用mel滤波器对该单通道的目标语音信号进行滤波,得到mel域频谱。
65.步骤二,对mel域频谱取log对数,然后进行离散余弦变换得到该单通道的mel特征。
66.一种实现方式中,由于人类听觉系统是一个特殊的非线性系统,可以以不同灵敏度响应不同频率信号,mel滤波器可以将目标语音信号从线性频谱映射到基于听觉感知的mel非线性频谱中。将普通频率转化到mel频率的公式是:
67.一种实现方式中,对mel域频谱取对数可以增强声音信号中的低频信号,进而从低频信号中提取更多隐藏的特征。离散余弦变换(discrete cosinetransform,dct)为快速傅里叶逆变换,通过dct可以得到一些系数向量,即为倒谱系数。
68.在一个实施例中,步骤s104包括:
69.步骤一,将麦克风阵列中各个通道提取的mel特征并联,得到规整的多通道mel特征;
70.步骤二,将多通道mel特征与各个单通道的瞬时频率特征并联,得到目标特征。
71.一种实现方式中,将瞬时频率特征和mel特征组合进行语音识别,可以丰富语音信号的特征,进而提高语音识别的准确度。
72.以上对本发明的一个实施例进行了详细说明,但所述内容仅为本发明的较佳实施例,不能被认为用于限定本发明的实施范围。凡依本发明申请范围所作的均等变化与改进等,均应仍归属于本发明的专利涵盖范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。