使用基于注意力的融合网络的多媒体数据语义分析系统和方法
1.交叉引用
2.在本公开的描述中引用和讨论了一些参考文献,其可能包括专利、专利申请和各种出版物。提供此类参考文献的引用和/或讨论仅用于阐明本公开的描述,并不承认任何此类参考文献相对于本公开是已有的。在本说明书中引用的或讨论的所有参考文献通过引用整体并入本文,并且与每篇参考文献通过引用单独并入的程度相同。
技术领域
3.本公开总体上涉及对目标对象属性的提取和推断,具体地,涉及具有基于注意力的融合机制的端到端神经网络,以从多媒体数据中获得信息。
背景技术:
4.在此提供的背景描述是为了概括地呈现本公开的上下文。在本背景部分描述的范围内,发明人的工作以及在提交申请时可能不符合已有的描述方面,既不明确也不隐含地承认为相对于本公开是已有的。
5.互联网上的大量目标对象通过多媒体数据表示。例如,在社交网络应用中,很大比例的帖子包括文本和图像;在线上零售平台中,商品也可以通过图像和文本进行描述。对于目标帖子或目标商品的文本问题,可以根据这些文本和图像使用各种语义分析来预测目标对象的属性。有些方法通过关注目标文本来回答文本问题,有些方法通过关注目标图像来回答文本问题。然而,没有一种方法有效地即使用文本信息又使用图像信息。
6.因此,本领域存在解决上述缺陷和不足的需要。
技术实现要素:
7.在一些方面,本公开涉及一种多媒体数据分析系统。在一些实施例中,所述系统包括计算设备,所述计算设备包括处理器和存储计算机可执行代码的存储设备。所述计算机可执行代码在所述处理器处执行时被配置为:接收包含任务描述和任务元信息的任务,其中,所述任务描述为文本格式,所述任务元信息包括任务的来源、类型和索引;提供与所述任务相关的多媒体上下文,其中,所述多媒体上下文包含上下文文本、上下文图像和上下文元信息,所述上下文元信息包含上下文的来源、类型和索引;将所述任务描述的序列词嵌入至任务描述嵌入中,对所述任务描述嵌入执行第一神经网络以获得任务特征向量,将所述任务元信息编码为任务嵌入向量,并将所述任务特征向量和所述任务嵌入向量拼接为拼接任务向量;当所述上下文包含所述上下文文本时,将所述上下文文本的序列词嵌入至上下文文本嵌入中,对所述上下文文本嵌入执行第二神经网络以获得上下文特征向量,将所述上下文元信息编码为上下文嵌入向量,并将所述上下文特征向量和所述上下文嵌入向量拼接为拼接上下文向量;当所述上下文包含所述上下文图像时,对所述上下文图像执行第三神经网络以获得上下文图像嵌入,对所述上下文图像嵌入执行第四神经网络以获得上下文
特征向量,将所述上下文元信息编码为所述上下文嵌入向量,并将所述上下文特征向量和所述上下文嵌入向量拼接为拼接上下文向量;对所述任务特征向量、所述拼接任务向量、所述上下文特征向量和所述拼接上下文向量执行双重协同注意力,以获得被注意的任务向量和被注意的上下文向量;对所述被注意的任务向量和所述被注意的上下文向量执行第五神经网络,以获得任务编码和上下文编码;以及对所述任务编码和所述上下文编码进行解码,以获得对所述任务的回答。
8.在一些实施例中,所述计算机可执行代码被配置为通过以下步骤将所述任务元信息编码为任务嵌入向量:将所述任务元信息转换为任务独热向量;以及将所述任务独热向量与任务矩阵相乘,以形成所述任务嵌入向量,其中,所述任务矩阵包括表示所述任务的来源的源矩阵、表示所述任务的类型的类型矩阵和表示所述任务的索引的索引矩阵。
9.在一些实施例中,所述计算机可执行代码被配置为通过以下步骤将所述上下文元信息编码为上下文嵌入向量:将所述上下文元信息转换为上下文独热向量;以及将所述上下文独热向量与所述任务矩阵相乘,以形成所述上下文嵌入向量。
10.在一些实施例中,所述第一神经网络、所述第二神经网络、所述第四神经网络和所述第五神经网络中的每一者是双向长短期记忆网络(bilstm),所述第三神经网络是卷积神经网络(cnn)。
11.在一些实施例中,所述计算机可执行代码被配置为通过以下步骤对所述上下文图像执行cnn以获得上下文图像嵌入:将所述上下文图像划分为多个区域;对每个区域执行cnn;以及将所述cnn的隐藏层作为所述上下文图像嵌入。在一些实施例中,所述上下文图像被划分为4个至6400个区域。在一些实施例中,通过所述cnn针对所述上下文图像中的若干区域进行学习。
12.在一些实施例中,所述计算机可执行代码被配置为通过以下步骤对所述任务编码和所述上下文编码进行解码以获得对所述任务的回答:嵌入在之前的时间步处的所述回答中一部分回答的词,以获得嵌入的部分回答;将单向lstm应用至所述嵌入的部分回答,以获得中间解码器状态;将所述中间解码器状态与所述任务编码结合,以获得所述任务编码中任务词向量的分布;将所述中间解码器状态与所述上下文编码结合,以获得所述上下文编码中上下文词向量的分布;将所述中间解码器状态与所述上下文编码和上下文注意力结合以获得组合,并将全连接层应用至所述组合以获得词汇分布;基于所述任务词向量的分布、所述上下文词向量的分布和所述词汇分布生成输出分布;以及从所述输出分布中选择针对所述回答中该部分回答的下一个词。
13.在一些实施例中,所述全连接层是前馈网络(ffn)。
14.在一些实施例中,通过以下步骤生成所述输出分布:学习词汇指针切换,所述词汇指针切换调节从外部词汇生成所述回答相比于从所述上下文或所述任务生成所述回答的概率;学习上下文-任务切换,所述上下文-任务切换调节从所述上下文生成所述回答相比于从所述任务描述生成所述回答的概率;以及将所述词汇指针切换和所述上下文-任务切换用作权重,以对所述任务词向量的所述分布、所述上下文词向量的分布和所述词汇分布进行平均化,从而获得所述输出分布。
15.在一些实施例中,在所有时间步处使用分词级别负对数似然损失训练所述计算机可执行代码中的模型:
[0016][0017]
在一些方面,本公开涉及一种多媒体数据分析方法。在一些实施例中,所述方法包括:通过计算设备接收包含任务描述和任务元信息的任务,其中,所述任务描述为文本格式,所述任务元信息包括任务的来源、类型和索引;通过所述计算设备提供与所述任务相关的多媒体上下文,其中,所述多媒体上下文包含上下文文本、上下文图像和上下文元信息,所述上下文元信息包含上下文的来源、类型和索引;通过所述计算设备将所述任务描述的序列词嵌入至任务描述嵌入中,对所述任务描述嵌入执行第一神经网络以获得任务特征向量,将所述任务元信息编码为任务嵌入向量,并将所述任务特征向量和所述任务嵌入向量拼接为拼接任务向量;当所述上下文包含所述上下文文本时,通过所述计算设备将所述上下文文本的序列词嵌入至上下文文本嵌入中,对所述上下文文本嵌入执行第二神经网络以获得上下文特征向量,将所述上下文元信息编码为上下文嵌入向量,并将所述上下文特征向量和所述上下文嵌入向量拼接为拼接上下文向量;当所述上下文包含所述上下文图像时,通过所述计算设备对所述上下文图像执行第三神经网络以获得上下文图像嵌入,对所述上下文图像嵌入执行第四神经网络以获得上下文特征向量,将所述上下文元信息编码为所述上下文嵌入向量,并将所述上下文特征向量和所述上下文嵌入向量拼接为拼接上下文向量;通过所述计算设备对所述任务特征向量、所述拼接任务向量、所述上下文特征向量和所述拼接上下文向量执行双重协同注意力,以获得被注意的任务向量和被注意的上下文向量;通过所述计算设备对所述被注意的任务向量和所述被注意的上下文向量执行第五神经网络,以获得任务编码和上下文编码;以及通过所述计算设备对所述任务编码和所述上下文编码进行解码,以获得对所述任务的回答。
[0018]
在一些实施例中,将所述任务元信息编码为任务嵌入向量的步骤包括:将所述任务元信息转换为任务独热向量;以及将所述任务独热向量与任务矩阵相乘,以形成所述任务嵌入向量,其中,所述任务矩阵包括表示所述任务的来源的源矩阵、表示所述任务的类型的类型矩阵和表示所述任务的索引的索引矩阵。
[0019]
在一些实施例中,将所述上下文元信息编码为上下文嵌入向量的步骤包括:将所述上下文元信息转换为上下文独热向量;以及将所述上下文独热向量与所述任务矩阵相乘,以形成所述上下文嵌入向量。
[0020]
在一些实施例中,所述第一神经网络、所述第二神经网络、所述第四神经网络和所述第五神经网络中的每一者是双向长短期记忆网络(bilstm),所述第三神经网络是卷积神经网络(cnn)。
[0021]
在一些实施例中,对所述上下文图像执行cnn以获得上下文图像嵌入的步骤包括:将所述上下文图像划分为多个区域;对每个区域执行cnn;以及将所述cnn的隐藏层作为所述上下文图像嵌入。
[0022]
在一些实施例中,所述计算机可执行代码被配置为通过以下步骤对所述任务编码和所述上下文编码进行解码以获得对所述任务的回答:嵌入在之前的时间步处的所述回答中一部分回答的词,以获得嵌入的部分回答;将单向lstm应用至所述嵌入的部分回答,以获得中间解码器状态;将所述中间解码器状态与所述任务编码结合,以获得所述任务编码中任务词向量的分布;将所述中间解码器状态与所述上下文编码结合,以获得所述上下文编
码中上下文词向量的分布;将所述中间解码器状态与所述上下文编码和上下文注意力结合以获得组合,并将全连接层应用至所述组合以获得词汇分布;基于所述任务词向量的分布、所述上下文词向量的分布和所述词汇分布生成输出分布;以及从所述输出分布中选择针对所述回答中该部分回答的下一个词。
[0023]
在一些实施例中,所述全连接层是前馈网络(ffn)。
[0024]
在一些实施例中,通过以下步骤生成所述输出分布:学习词汇指针切换,所述词汇指针切换调节从外部词汇生成所述回答相比于从所述上下文或所述任务生成所述回答的概率;学习上下文-任务切换,所述上下文-任务切换调节从所述上下文生成所述回答相比于从所述任务描述生成所述回答的概率;以及将所述词汇指针切换和所述上下文-任务切换用作权重,以对所述任务词向量的分布、所述上下文词向量的分布和所述词汇分布进行平均化,以获得所述输出分布。
[0025]
在一些方面,本公开涉及一种存储有计算机可执行代码的非暂时性计算机可读介质。所述计算机可执行代码在计算设备的处理器处执行时被配置为执行上述方法。
[0026]
本公开的这些和其他方面将从以下结合以下附图及其说明的优选实施方案的描述中变得清楚,尽管其中的变体和修改可能会受到影响,但不会偏离本公开的新颖概念的精神和范围。
附图说明
[0027]
附图示出了本公开的一个或多个实施例,并与其书面描述一起用于解释本公开的原理。在可能的情况下,在整个附图中使用相同的附图标记来指示实施例的相同或相似元件。
[0028]
图1示意性地描绘了根据本公开的一些实施例的使用基于注意力的融合网络进行多媒体数据语义分析的计算系统。
[0029]
图2a示意性地描绘了根据本公开的一些实施例的任务描述编码器。
[0030]
图2b示意性地描绘了根据本公开的一些实施例的多媒体上下文编码器。
[0031]
图2c示意性地描绘了根据本公开的一些实施例的解码器。
[0032]
图3a示意性地描绘了根据本公开的一些实施例的多媒体数据分析过程。
[0033]
图3b示意性地描绘了根据本公开的一些实施例的将任务描述转换为任务特征向量的过程。
[0034]
图3c示意性地描绘了根据本公开的一些实施例的将上下文转换为上下文特征向量的过程。
[0035]
图3d示意性地描绘了根据本公开的一些实施例的将任务编码和上下文编码进行解码以获得对任务的回答的过程。
[0036]
图4a示意性地描绘了根据本公开的一些实施例的用于多媒体数据语义分析的基于注意力的融合网络的编码器部分。
[0037]
图4b示意性地描绘了根据本公开的一些实施例的用于多媒体数据语义分析的基于注意力的融合网络的解码器部分。
[0038]
图5a示意性地描绘了根据本公开的一些实施例的使用多媒体编码器对文本上下文进行编码的过程。
[0039]
图5b示意性地描绘了根据本公开的一些实施例的使用多媒体编码器对图像上下文进行编码的过程。
具体实施方式
[0040]
在以下示例中更具体地描述本公开,这些示例仅旨在作为说明,因为其中的许多修改和变化对于本领域技术人员来说将是清楚的。现在详细描述本公开的各种实施例。参考附图,贯穿整个附图,相同的数字指示相同的部件。除非上下文另有明确规定,否则本文的描述中和整个权利要求中使用的“一个”、“一”和“所述”的含义包括复数。此外,如在本公开的描述和权利要求书中所使用的,除非上下文另有明确规定,“在”的含义包括“在
……
中”和“在
……
上”。并且,说明书中为了方便读者可以使用标题或副标题,这不会影响本公开的范围。此外,本说明书中使用的一些术语在下文有更具体的定义。
[0041]
本说明书中使用的术语在本领域中、在本公开的上下文中以及在使用每个术语的特定上下文中通常具有它们的普通含义。用于描述本公开的一些术语在下文或说明书中的其他地方讨论,以向从业者提供关于本公开的描述的额外指导。可以理解,同样的事情可以用不止一种方式表达出来。因此,替代语言和同义词可用于本文讨论的任何一个或多个术语,并且对于本文是否详细阐述或讨论术语没有任何特殊意义。本公开提供了一些术语的同义词。一个或多个同义词的使用不排除其他同义词的使用。本说明书中任何地方的示例的使用,包括本文讨论的任何术语的示例,仅是说明性的,决不限制本公开内容或任何示例性术语的范围和含义。同样,本公开不限于本说明书中给出的各种实施例。
[0042]
可以理解的是,当一个元件被称为位于另一元件“上”时,该元件可以直接位于该另一元件上,或者可以存在中间元件。而当一个元件被称为“直接”位于另一元件“上”时,不存在中间元件。如本文所述,术语“和/或”包括一个或多个相关列出项目的任何和所有组合。
[0043]
可以理解的是,虽然术语“第一”、“第二”、“第三”等可以在本文中用于描述各种元件、部件、区域、层和/或部分,但是这些元件、部件、区域、层和/或部分不应受到这些术语限制。这些术语仅用于将一个元件、部件、区域、层或部分与另一个元件、部件、区域、层或部分相区分。因而,下面讨论的第一元件、第一部件、第一区域、第一层或第一部分可以被称为第二元件、第二部件、第二区域、第二层或第二部分,而不背离本公开的教导。
[0044]
另外,本文中可以使用诸如“下方”、“底部”、“上方”、“顶部”之类的相对性术语,从而描述如图中所示的一个元件与另一元件的关系。可以理解的是,除了图中描绘的方位之外,相对性术语还意图包含设备的不同方位。例如,如果图中的设备被翻转,则被描述为在其它元件“下方”的元件将随后被定位为在所述其它元件“上方”。因此,示例性术语“下方”可以包含“下方”和“上方”两种方位,这取决于图的具体朝向。同样,如果图中的设备被翻转,则被描述为在其它元件“之下”或“下面”的元件将取向为在所述其它元件“之上”或“上面”。因此,示例性术语“之下”或“下面”可以包含“之上”和“之下”两种方位。
[0045]
除非另有定义,本公开使用的所有术语(包括技术术语和科学术语)具有与本公开内容所属领域的普通技术人员通常理解的相同的含义。还应理解,诸如在常用词典中定义的术语应被解释为具有与其在相关技术和本公开的上下文中一致的含义,并且,除非在本文中明确限定,否则不会被解释为理想化的或过于形式化的意义。
[0046]
如本文所述,“大约”、“大致”、“基本上”或“近似”应通常表示给定值或范围的20%以内,优选10%以内,更优选5%以内。本文给出的数值是近似的,这意味着如果没有明确说明,可以推断出术语“大约”、“大致”、“基本上”或“近似”。
[0047]
如本文所述,“多个”是指两个或更多个。
[0048]
如本文所述,术语“包括”、“包含”、“携带”、“具有”、“含有”、“涉及”等应理解为开放式的,即意味着包括但不限于。
[0049]
如本文所述,短语“a、b和c中的至少一个”应解释为表示逻辑(a或b或c),使用非排他性逻辑或(or)。应当理解,在不改变本公开的原理的情况下,方法内的一个或多个步骤可以以不同的顺序(或同时)执行。
[0050]
如本文所述,术语“模块”可以指示例如在片上系统中的属于或包括专用集成电路(application specific integrated circuit,asic);电子电路;组合逻辑电路;现场可编程门阵列(field programmable gate array,fpga);执行代码的(共享的、专用的或组)处理器;提供所描述功能的其他合适的硬件组件;或以上部分或全部的组合。术语“模块”可以包括存储由处理器执行的代码的(共享的、专用的或组)存储器。
[0051]
本文使用的术语“代码”可以包括软件、固件和/或微代码,并且可以指代程序、例程、函数、类和/或对象。上面使用的术语“共享”意味着可以使用单个(共享)处理器执行来自多个模块的一些代码或所有代码。此外,来自多个模块的一些代码或所有代码可以存储在单个(共享)存储器中。上面使用的术语“组”意味着可以使用处理器组执行来自单个模块的一些代码或所有代码。此外,可以使用存储器组来存储来自单个模块的一些代码或所有代码。
[0052]
如本文所述,术语“接口”通常是指在部件之间的交互点处用于执行部件之间的数据通信的通信工具或装置。一般而言,接口可以既适用在硬件层面又适用在软件层面,且接口可以是单向接口或双向接口。物理硬件接口的示例可以包括电连接器、总线、端口、电缆、端子和其他i/o设备或部件。与接口通信的部件可以是例如计算机系统的多个部件或外围设备。
[0053]
本公开涉及计算机系统。如附图所示,计算机部件可以包括物理硬件部件,其示出为实线框,以及虚拟软件部件,其示出为虚线框。本领域普通技术人员将理解,除非另有说明,否则这些计算机部件可以以软件、固件或硬件部件或其组合的形式来实现,但不限于这些形式。
[0054]
本文描述的装置、系统和方法可以通过由一个或多个处理器执行的一个或多个计算机程序来实现。计算机程序包括存储在非暂时性有形计算机可读介质上的处理器可执行指令。计算机程序还可包括存储的数据。非暂时性有形计算机可读介质的非限制性示例是非易失性存储器、磁存储和光存储。
[0055]
在下文中参考附图更全面地描述本公开,其中示出了本公开的实施例。然而,本公开可以以许多不同的形式体现并且不应被解释为限于这里阐述的实施例;相反,提供这些实施例是为了使本公开彻底和完整,并将本公开的范围充分传达给本领域技术人员。
[0056]
在一些方面,本公开旨在推断或提取目标对象的属性,其中目标对象通过广泛存在于互联网上的多媒体数据来表示。
[0057]
在一些实施例中,本公开提供了一种通过从目标对象的文本参考文档中提取相关
信息来对自然语言或文本问题进行回答的方法。该方法使用端到端神经网络,通过语义对问题和参考文档进行编码,然后根据参考文档预测回答。然而,该方法仅使用目标对象的文本信息,而未使用图像中的相关信息。
[0058]
在一些实施例中,本公开提供了一种通过从目标对象的相应视觉图像中提取相关信息来对文本问题进行回答的方法。该方法使用卷积神经网络(convolutional neural network,cnn)学习高级语义以生成与问题相关的概念以作为语义注意力,然后通过循环神经网络(recurrent neural network,rnn)将来自cnn的基于区域的中级输出编码为空间嵌入表示,并通过多层感知器精确定位与回答相关的区域以作为视觉注意力。然而,该方法仅使用目标对象的图像信息。
[0059]
在一些实施例中,本公开可以集成上述基于图像的方法和基于文本的方法。但是,由于缺乏来自异构数据的组成表示,该集成系统仍然缺乏准确性。
[0060]
在一些实施例中,本公开提供了一种多模态推理和匹配方法,以捕获视觉和语言之间的相互作用,从而构成来自文本数据和视觉数据的统一表示。该方法通过多个步骤将注意力机制用于图像中的特定区域和文本中的词,并在这两种模式下收集基本信息。具体来说,这些网络使用联合记忆来协同地执行视觉注意力和文本注意力,该联合记忆将之前的注意力结果进行组合并指导下一注意力。尽管该方法捕获视觉和语言之间的相互作用,但无法对问题中的需求和来自参考文档的信息进行区分。
[0061]
在一些方面,为了提高问答效率和准确性,本公开提供了一种根据问题和根据目标对象上下文的文本和图像进行推断的方法。具体来说,本公开基于端到端神经网络结合基于注意力的融合机制来解决该问题。对于给定任务,输入数据包含任务描述文本数据q和目标多媒体上下文数据集c。每个输入数据项可以利用元组(s,t,i,c)来描述,其中,s是指示数据是任务描述还是上下文数据的二维独热向量,t是指示数据类型是文本还是图像的二维独热向量,i是表示输入数据项的索引的二维独热向量,而索引是任务或上下文的标识,c表示给定数据的内容。
[0062]
在一些实施例中,基于注意力的融合网络包括以下四个主要部件:神经网络集;任务编码层;融合层;以及解码器神经网络。
[0063]
1)神经网络集对不同类型的数据进行编码,并生成针对每个输入数据的表示。
[0064]
在根据本公开的一些实施例的查询-回答问题中,输入数据包含任务描述和目标多媒体数据。任务描述为文本格式,目标多媒体数据包括文本和一个或多个图像。
[0065]
对于文本数据,本公开使用长短期记忆(long short-term memory,lstm)生成针对文本的表示。给定t个输入词{w1,w2,...,wi…
,w
t
}的独热编码,利用词嵌入层,本公开可以将源文本s转换为词嵌入序列e={e1,e2,...,ei,...,e
t
},此处ei是表示文本文档中第i个词的d维词嵌入的向量。为了获得词嵌入表示e,本公开首先查找嵌入矩阵d维词嵌入的向量。为了获得词嵌入表示e,本公开首先查找嵌入矩阵其中v是固定大小的词汇,d
emb
是词嵌入的大小。矩阵w
wrd
是利用本公开的模型来学习的参数,d
emb
是用户选择的模型的超参数。本公开使用矩阵-向量乘积将词wi变换为其词嵌入ei:ei=w
wrd
vi,其中vi是v中的词wi的索引的向量。然后,本公开将向量馈送到双向lstm(bi-directional long short-term memory,bilstm):memory,bilstm):
其中知分别表示前向lstm和后向lstm在时间t的隐藏状态,x
t
为第t个分词。通过拼接每个时间步处的两个隐藏状态,本公开构建了特征向量集{u1,u2,...,ui,...,u
t
},其中ui对给定参考文档中的第i个词的语义进行编码。
[0066]
对于图像数据,本公开利用基于卷积神经网络(cnn)的模型并从隐藏层中提取视觉特征。该模块将图像分割为小的局部区域,并将每个区域视为等同于针对文本数据的输入模块中的词。对于每个区域,本公开使用cnn来提取特征。为了获得针对不同区域的特征向量,本公开采用最后一个池化层。因此,输入图像可以表示为{r1,r2,...,ri,...,rn},其中n是图像区域的数量,ri是与第i个区域对应的特征向量。最后,本公开将特征向量列表馈送到bilstm以捕获这些区域之间的交互,该bilstm的隐藏状态{z1,z2,...,zi,...,zn}用于表示图像的语义。
[0067]
2)任务编码层对数据来源和数据类型进行编码。
[0068]
任务编码层包括三个嵌入层(ms,m
t
,mi),以对源信息、类型信息和索引信息进行编码。本公开可以使用矩阵-向量乘积将源独热向量si变换为其嵌入esi:esi=mssi,使用矩阵-向量乘积将独热向量ti转换为其嵌入eti:eti=m
t
si,使用矩阵-向量乘积将独热向量ii转换为其嵌入eii:eii=miii。通过拼接esi、eti和eii,本公开可以得到其任务信息的嵌入ki。然后,对于每个数据项,本公开将上述步骤1中构建的特征向量与其在本步骤2中的任务嵌入拼接起来。
[0069]
3)融合层捕获任务描述和输入目标数据之间的交互,并构建针对任务的统一表示。
[0070]
利用前两个部件,对于每个分析任务,本公开可以将任务描述q表示为{q
proj
,q
enc
},将目标上下文多媒体数据集c表示为{c
proj
,c
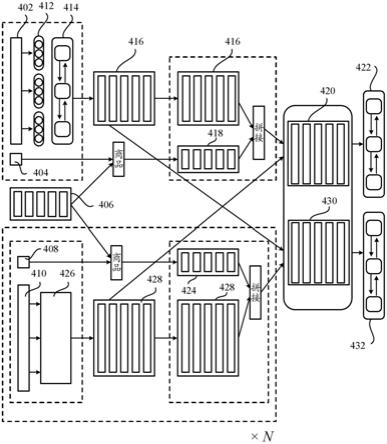
enc
}。q
proj
为任务描述的词嵌入表示,即任务特征向量,q
enc
为文本编码器输出和任务编码器输出的拼接,c
proj
为所有目标上下文数据项的文本嵌入层和图像池化层的拼接,c
enc
为所有目标上下文数据项的bilstm编码器输出和任务编码器输出的拼接。
[0071]
为了获得任务描述和目标上下文数据集的融合表示,本公开通过将一个表示与其他表示之间的点积相似度分数进行归一化来将q和c的编码的表示进行对齐:
[0072][0073][0074]
然后对一个序列中与其他序列中单个特征相关的信息加权总和:
[0075]
融合表示使用相同的权重将从对齐获得的信息传输回原始序列:
[0076]
为了将信息从双重融合表示压缩回更易于管理的维度d,本公开将针对每个序列的所有四个先前表示沿最后维度拼接起来并馈送到单独的bilstm中:
[0077]
[0078][0079]
这些矩阵被提供给解码器以生成预测。
[0080]
4)解码器神经网络处理融合信息以根据不同任务做出预测。
[0081]
本公开的模型可以生成不在上下文或任务描述中的分词,并且本公开使模型可以访问v个附加的词汇分词。本公开获得在上下文多媒体数据、任务描述和该外部词汇中分词的分布,分别为:
[0082][0083][0084][0085]
通过将每个分布中的缺失项设置为0,可以将这些分布扩展为涵盖上下文、任务描述和外部词汇中分词的联合,从而每个分布都在中。两个标量切换调节每个分布在确定最终输出分布上的重要性。
[0086][0087][0088][0089]
在一些实施例中,在所有时间步处使用分词级别负对数似然损失来训练模型:应当注意此处的λ对应下面图4b中示出的β。
[0090]
因此,本公开利用端到端神经网络执行不同类型的语义分析任务,可以接受不同类型的数据并构建针对目标对象的面向任务的表示。此外,可以通过基于注意力的融合机制来有效地处理针对不同任务的相关表示。
[0091]
图1示意性地描绘了根据本公开的一些实施例的使用基于注意力的融合网络进行多媒体数据语义分析的计算系统。如图1所示,系统100包括计算设备110。在一些实施例中,图1中所示的计算设备110可以是服务器计算机、集群、云计算机、通用计算机、无头计算机或专用计算机,以提供多媒体数据分析。计算设备110可以包括但不限于处理器112、存储器114和存储设备116,以及(可选地)数据库190。在一些实施例中,计算设备110可以包括其他硬件部件和软件部件(未示出)以执行其对应的任务。这些硬件部件和软件部件的示例可以包括但不限于其他所需的存储器、接口、总线、输入/输出(input/output,i/o)模块或设备、网络接口和外围设备。
[0092]
处理器112可以是中央处理单元(central processing unit,cpu),其用于控制计算设备110的操作。处理器112可以执行计算设备110的操作系统(operating system,os)或其他应用。在一些实施例中,计算设备110可以具有一个以上cpu作为处理器,例如两个cpu、四个cpu、八个cpu或任何合适数量的cpu。
[0093]
存储器114可以是易失性存储器,例如随机存取存储器(random-access memory,
ram),以用于在计算设备110的运行期间存储数据和信息。在一些实施例中,存储器114可以是易失性存储器阵列。在一些实施例中,计算设备110可以在一个以上存储器114上运行。
[0094]
存储设备116是用于存储计算设备110的os(未示出)和其他应用的非易失性数据存储介质。存储设备116的示例可以包括例如闪存、存储卡、usb驱动器、硬盘驱动器、软盘、光驱或任何其他类型的数据存储设备。在一些实施例中,计算设备110可以具有多个存储设备116,这些存储设备116可以是相同的存储设备或不同类型的存储设备,计算设备110的应用可以存储在计算设备110的一个或多个存储设备116中。存储设备116还包括多媒体数据分析应用118等。多媒体数据分析应用118包括任务描述编码器120、任务编码器130、多媒体上下文编码器140、双重注意力融合模块150、最终编码模块160、解码器170和用户接口180。在一些实施例中,存储设备116可以包括多媒体数据分析应用118运行所需的其他应用或模块。应当注意,模块120至180各自通过计算机可执行代码或指令、或数据表或数据库来实现,这些模块共同形成一个应用。在一些实施例中,每个模块还可以包括子模块。或者,一些模块可以组合为一个堆栈。在其他实施例中,一些模块可以实现为电路而非可执行代码。
[0095]
在本实施例中,处理器112、存储器114、存储设备116是计算设备(例如服务器计算设备110)的部件。在其他实施例中,计算设备110可以是分布式计算设备,处理器112、存储器114和存储设备116是来自预定义区域中的多台计算机的共享资源。
[0096]
任务描述编码器120用于检索或接收任务描述,将任务描述编码为任务特征向量,将任务元信息和任务编码矩阵编码为任务嵌入向量或矩阵,将任务的任务特征向量和任务嵌入向量拼接为拼接任务向量,并将拼接任务向量发送到双重注意力融合模块150。如图2a所示,任务描述编码器120包括文本独热编码器121、词嵌入模块122、bilstm模块123、任务元信息模块124和任务拼接模块125。在一些实施例中,任务是文本问题或查询,任务描述是该问题或查询的文本。
[0097]
文本独热编码器121用于在接收到任务描述的文本时,将文本任务描述中的每个词转换为独热向量,并将文本的独热向量发送到词嵌入模块122。在一些实施例中,文本独热编码器121通过过滤掉标点符号、将词的大小写改为小写、用空格对词进行分割等对文本进行处理,以获得t个词{w1,w2,
…
,wi…
,w
t
},并使用固定大小的词汇将t个词转换为其对应的独热向量{v1,v2,
…
,vi…
,v
t
}。独热向量vi具有固定大小的维度,独热向量vi的第i个维度设置为1,独热向量vi的所有其他维度设置为0。应当注意,将文本转换为独热表示是按顺序执行的,因此保持了文本的序列信息。
[0098]
词嵌入模块122用于在接收到任务描述中的词的序列独热向量{v1,v2,...,vi…
,v
t
}时,将独热向量嵌入嵌入向量{e1,e2,...,ei,...,e
t
},并将嵌入向量发送到bilstm模块123。嵌入向量的维度d可以通过本公开限定或通过词嵌入模块122学习,并且维度d远小于独热向量的维度。在一些实施例中,词嵌入模块122是多媒体数据分析应用118的嵌入层,在多媒体数据分析应用118的训练期间学习嵌入层的参数。通过词嵌入,词的独热向量的维度被大幅度降低至嵌入向量的维度。
[0099]
bilstm模块123用于在接收到序列嵌入向量{e1,e2,...,ei,...,e
t
}时,将嵌入向量馈送到bilstm,对嵌入向量执行bilstm以获得任务特征向量{u1,u2,...,ui,...,u
t
},并将任务特征向量发送到任务拼接模块125和双重注意力融合模块150。特征向量ui对任务的文本描述中第i个词的语义进行编码。在bilstm中,前向lstm和后向lstm在时间t的隐藏状
态分别是和通过拼接每个时间步处的两个隐藏状态来获得特征向量。
[0100]
任务元信息模块124用于在检索或接收到任务的元信息时,获得表示任务元信息的独热向量si、ti和ii,计算独热向量si、ti、ii和任务编码矩阵(ms,m
t
,mi)的乘积以获得各自的嵌入esi=mssi、eti=m
t
si和eii=miii,拼接esi、eti和eii以获得任务嵌入矩阵或任务嵌入向量ki,并将任务嵌入向量ki发送到任务拼接模块125。独热向量si表示任务的来源(此处来源是任务或问题),独热向量ti表示任务的类型(此处类型是文本),向量ii表示任务的索引(任务的标识)。
[0101]
任务拼接模块125用于在接收到来自bilstm模块123的任务特征向量{u1,u2,...,ui,...,u
t
}(任务描述的编码)和来自任务元信息模块124的任务嵌入向量时,对任务特征向量和任务嵌入向量进行拼接以获得拼接任务向量,并将该拼接任务向量发送至双重注意力融合模块150。
[0102]
任务编码器130用于检索或接收任务的信息,将任务的来源、类型和索引编码为任务编码矩阵(ms,m
t
,mi),并将任务编码矩阵提供给任务元信息模块124和上下文元信息模块146(如下所述)。在一些实施例中,任务编码器130是任务编码层,任务编码层包括三个嵌入层(ms,m
t
,mi),以分别对任务的来源、类型和索引进行编码。在一些实施例中,在模型训练期间学习任务编码矩阵(ms,m
t
,mi)。
[0103]
多媒体上下文编码器140用于检索或接收与任务相关的上下文,将上下文编码为上下文特征向量,将上下文元信息和任务编码矩阵编码为上下文嵌入矩阵或上下文嵌入向量,对上下文特征向量和上下文嵌入向量进行拼接以获得拼接上下文向量,并将该拼接上下文向量发送到双重注意力融合模块150。如图2b所示,多媒体上下文编码器140包括上下文类型模块141、cnn模块142、文本独热编码器143、词嵌入模块144、bilstm模块145、上下文元信息模块146和上下文拼接模块147。在一些实施例中,上下文包括多媒体上下文,例如文本和图像。
[0104]
上下文类型模块141用于在接收到与任务相关的上下文(或目标)时,确定该上下文是文本上下文还是图像上下文。如果该上下文是图像,则将图像上下文发送到cnn模块142,如果该上下文是文本,则将文本上下文发送到文本独热编码器143。
[0105]
cnn模块142用于在接收到图像上下文时,对图像执行cnn以获得图像的区域特征向量(上下文图像嵌入),并将区域特征向量发送到bilstm模块145。在一些实施例中,cnn模块142将图像分割为小的局部区域,并使用cnn从cnn的隐藏层中提取每个区域的视觉特征。因此,每个局部区域由对应的区域特征向量来表示,并且区域特征向量的列表用作bilstm模块145的输入。在一些实施例中,cnn模块142将图像分割为四个局部区域:左上、右上、左下和右下。在一些实施例中,cnn模块142将图像分割为大量区域,例如,将图像水平分割为20个部分并垂直分割为80个部分,从而获得1600个局部区域。
[0106]
文本独热编码器143用于在接收到文本上下文时,将文本上下文中的每个词转换为独热向量,并将独热向量发送到词嵌入模块144。在一些实施例中,文本独热编码器143与文本独热编码器121相同或相似。需要注意,将文本转换为独热表示是按顺序执行的,因此保持了文本的序列信息。
[0107]
词嵌入模块144用于在接收到上下文中的词的序列独热向量时,将独热向量嵌入上下文嵌入向量(或上下文文本嵌入),并将上下文嵌入向量发送到bilstm模块145。在一些实施例中,词嵌入模块144是多媒体数据分析应用118的嵌入层,在多媒体数据分析应用118的训练期间学习嵌入层的参数。通过词嵌入,独热向量的维度被大幅度降低至嵌入向量的维度。在一些实施例中,词嵌入模块144与词嵌入模块122相同或相似。
[0108]
bilstm模块145用于在接收到来自cnn模块142的区域特征向量(上下文图像嵌入)或来自词嵌入模块144的序列词嵌入向量(上下文文本嵌入)时,对区域特征向量或词嵌入向量执行bilstm以获得上下文特征向量,并将上下文特征向量发送到上下文拼接模块147和双重注意力融合模块150。
[0109]
上下文元信息模块146用于在检索或接收到上下文元信息时,获得表示上下文元信息的独热向量,计算上下文元信息的独热向量和任务编码矩阵的乘积以获得各自的嵌入,将嵌入进行拼接以获得上下文嵌入矩阵或上下文嵌入向量,并将上下文嵌入向量发送到上下文拼接模块147。
[0110]
上下文拼接模块147用于在接收到来自bilstm模块145的上下文特征向量和来自上下文元信息模块146的上下文嵌入向量时,对上下文特征向量和上下文嵌入向量进行拼接以获得拼接上下文向量,并将拼接上下文向量发送到双重注意力融合模块150。在一些实施例中,由于与任务相关的上下文包括多个上下文集,每个上下文可以是文本格式或图像格式,因此存在与多个上下文集对应的多个拼接上下文向量集。
[0111]
双重注意力融合模块150用于在接收到来自bilstm模块123的任务特征向量、来自任务拼接模块125的拼接任务向量、来自bilstm模块145的上下文特征向量和来自上下文拼接模块147的拼接上下文向量时,注意来自任务描述的向量和来自相关上下文的向量,以获得融合表示,并将融合表示发送到最终编码模块160。来自bilstm模块123的任务特征向量表示为q
proj
;来自任务拼接模块125的拼接任务向量表示为q
enj
;来自bilstm模块145的上下文特征向量表示为c
proj
,其对应所有目标上下文数据项;来自上下文拼接模块147的拼接上下文向量表示为c
enc
,其也对应于所有目标上下文数据项。任务描述q表示为{q
proj
,q
enc
},目标上下文多媒体数据集c表示为{c
proj
,c
enc
}。为了获得任务描述和目标上下文数据集的融合表示,双重注意力融合模块150通过将一个表示与其他表示之间的点积相似度分数进行归一化来将q和c的编码表示进行对齐:
[0112]
知
[0113]
此处s
cq
和s
qc
是softmax函数的相似度分数,知分别是任务描述的编码和上下文的编码。
[0114]
然后对一个序列中与其他序列中的单个特征相关的信息加权总和:其中是针对任务描述向量的协同注意力权重,是针对上下文向量的协同注意力权重。融合表示使用相同的权重将对齐获得的信息传输回原始序列:输回原始序列:其中c
fus
对应下面图4a中432的输出,q
fus
对应下面图4a中422的输出。
[0115]
最终编码模块160用于在接收到任务描述和上下文的融合表示后,将融合表示馈送到bilstm,并在执行bilstm之后,将bilstm矩阵发送到解码器170。在一些实施例中,为了将来自双重融合表示的信息压缩回更易于管理的维度d,最终编码模块160将针对每个序列的所有四个先前表示沿最后维度拼接起来并馈送到单独的bilstm:
[0116]
和
[0117][0118]
其中c
com
是上下文的最终表示,q
com
是任务描述的最终表示。然后,最终编码模块160将这些矩阵发送到解码器170以生成预测。
[0119]
解码器170用于在从最终编码模块160接收到矩阵后,生成对任务的回答。在一些实施例中,本公开需要生成不在上下文或问题中的分词。作为回应,本公开提供了对v个附加的词汇分词的访问权限。本公开分别获得上下文、问题和该外部词汇中分词的分布。在每一步骤中,解码器网络在三个选项之间做出决定:根据词汇生成、指向任务描述和指向上下文。模型可以学习在三个选项之间进行切换。在一些实施例中,这些分布被扩展为涵盖上下文、问题和外部词汇中的分词的联合。两个标量切换调节每个分布在确定最终输出分布上的重要性。如图2c所示,解码器170包括回答独热编码器171、回答嵌入模块172、回答lstm模块173、指针分布模块174、切换模块175和回答选择模块176。
[0120]
回答独热编码器171用于针对生成回答过程中的任何时间步t,将直到前一时间步t-1已经生成的回答作为文本转换为其独热编码表示,并将独热编码表示发送到回答嵌入模块172。在一些实施例中,不需要执行回答独热编码器171来生成回答中的第一个词。
[0121]
回答嵌入模块172在接收到在时间步t-1处已经生成的回答的独热编码表示后,将文档的这些独热编码表示应用到词嵌入层以提取每个词的嵌入作为其分布向量表示,并将词嵌入发送到lstm模块173。需要注意,词嵌入层的大小为v
×
d,v表示回答词汇的大小,d表示每个词的嵌入大小。
[0122]
回答lstm模块173用于在接收到嵌入词后,将每个词的嵌入馈送到单向lstm中以捕获序列中词之间的依赖关系,将直到前一时间步t-1生成的所有隐藏状态拼接为中间解码器状态,并将中间解码器状态发送到指针分布模块174。
[0123]
指针分布模块174用于在接收到中间解码器状态后,将中间解码器状态与问题描述(任务描述)的最终编码相结合,从而针对任务描述中的每个词向量生成注意力,即任务描述指针分布;将中间解码器状态与上下文的最终编码相结合,从而针对上下文(如果是文本格式)中的每个词生成注意力,即上下文指针分布;将中间解码器状态与上下文的最终编码以及上下文注意力相结合以作为全连接层的输入,从而生成词汇分布;并将这些分布发送到切换模块175。
[0124]
切换模块175用于在接收到上述分布时学习两个标量(对应下面图4b中的标量β和γ)。第一标量称为词汇指针切换,该词汇指针切换调节从外部词汇生成回答相比于(versus)从上下文或任务描述生成回答的概率,第二标量称为上下文-任务描述切换,该上下文-任务描述切换调节从上下文生成回答相比于从任务描述生成回答的概率。在一些实施例中,通过将当前中间解码器状态、上下文最终编码输出以及已经生成的回答词的嵌入进行结合来学习词汇指针切换;通过将当前中间解码器状态、任务描述最终编码输出以及
已经生成的回答词的嵌入进行结合来学习上下文-任务描述切换。在学习这些切换之后,切换模块175被进一步用于将学习到的切换提供给回答选择模块176。
[0125]
回答选择模块176用于在获得这两个切换后,将其用作对上下文指针分布、任务描述指针分布以及词汇分布进行平均化的权重,以获得最终回答分布。在一些实施例中,通过选择词汇中概率最高的词,回答选择模块176一次一词的生成预测的最终回答序列。
[0126]
在一个示例中,任务为询问“顾客对商品是正面评价还是负面评价”的问题,任务相关的上下文是“商品很好!”解码器170能够根据任务和上下文两者生成回答,而回答中的“正面”来自任务。
[0127]
返回参考图1,多媒体数据分析应用118还可以包括用户接口180。用户接口180用于在计算设备110中提供使用接口或图形用户界面。在一些实施例中,管理者能够配置用于训练多媒体数据分析应用118的参数。在一些实施例中,用户能够经由接口180输入任务(或问题或查询),以从多媒体数据分析应用118获得回答。
[0128]
多媒体数据分析应用118还可以包括数据库190,以存储训练问题和与问题相关的上下文。上下文可以包括顾客评论、商品评价、商品的问题-答案对、商品规格以及非特定于商品的广泛上下文。存储在数据库190中的一些数据用于训练,而存储在数据库190中的其他数据或所有数据可用于响应任务。在一些实施例中,数据库190存储在计算设备110以外的计算设备中或存储在其他计算服务器中,多媒体数据分析应用118在运行时能够从远程数据库190检索或接收数据。
[0129]
在一些实施例中,任务描述编码器120的模块、任务编码器130的模块、多媒体上下文编码器140的模块、双重注意力融合模块150、最终编码模块160和解码器170的模块被设计为一个集成网络的不同层,每一层对应特定功能。
[0130]
在一些方面,本公开涉及一种训练多媒体数据分析应用118的方法。在一些实施例中,该应用的训练由计算设备(例如图1中所示的计算设备110)执行。在一些实施例中,使用被标记的问题和相应的回答以及相关的数据上下文来执行训练。
[0131]
在一些方面,本公开涉及一种应用多媒体数据分析应用118的方法。图3a示意性地描绘了根据本公开的一些实施例的多媒体数据分析过程。在一些实施例中,该过程由计算设备(例如图1中所示的计算设备110)执行,具体地由多媒体数据分析应用118执行。应当特别注意的是,除非在本公开中另有说明,否则预测过程或方法的步骤可以以不同的顺序排列,因此不限于如图3a所示的顺序。
[0132]
在训练好多媒体数据分析应用118之后,准备将其用于数据分析,例如,基于相关多媒体数据对问题进行回答。
[0133]
在步骤310中,当用户查询任务时,任务描述编码器120检索或接收该任务的描述,并将任务描述转换为任务特征向量。在一些实施例中,任务是问题,描述是文本格式。
[0134]
在步骤320中,当任务可用时,任务编码器130将任务编码为任务矩阵。在一些实施例中,任务矩阵包括源矩阵、类型矩阵和索引矩阵。
[0135]
在步骤330中,任务编码器130检索任务元信息,将任务元信息转换为独热向量,并生成任务嵌入矩阵或任务嵌入向量,该任务嵌入矩阵或任务嵌入向量是任务元信息独热向量和任务矩阵的乘积。
[0136]
在步骤340中,任务编码器130检索上下文元信息,将上下文元信息转换为独热向
量,并生成上下文嵌入矩阵或上下文嵌入向量,该上下文嵌入矩阵或上下文嵌入向量是上下文元信息向量和上下文矩阵的乘积。上下文与任务相关,例如,如果任务是关于商品的问题,则上下文可以包括来自商品数据库的商品规格、商品的评论和评价、引用该商品的网络发布、以及与该商品同一类别的其他商品相关的信息。上下文可以是文本、图像、视频的形式。当视频可用时,可以将视频作为多个图像进行处理。
[0137]
在步骤350中,当任务可用时,多媒体上下文编码器140检索与任务相关的上下文,并将上下文转换为上下文特征向量。在一些实施例中,上下文包括文本和图像,每个文本或图像信息集都被转换为一个上下文特征向量集。
[0138]
在步骤360中,任务描述编码器120对任务特征向量和任务嵌入向量进行拼接以获得拼接任务向量,并将拼接任务向量发送到双重注意力融合模块150,多媒体上下文编码器140对上下文特征向量和上下文嵌入向量进行拼接以获得拼接上下文向量,并将拼接上下文向量发送到双重注意力融合模块150。
[0139]
在步骤370中,双重注意力融合模块150利用任务和上下文之间的注意力,根据拼接任务向量和拼接上下文向量生成融合表示,并将融合表示发送到最终编码模块160。
[0140]
在步骤380中,响应于接收到任务和上下文的融合表示,最终编码模块160使用融合表示执行bilstm,以获得任务编码和上下文编码,并将编码(bilstm矩阵)发送到解码器170。
[0141]
在步骤390中,响应于接收到任务编码和上下文编码,解码器170对编码进行解码以获得对任务的回答。
[0142]
通过上述操作,多媒体数据分析应用118能够对用户查询的任务作出回答,该回答来自任务数据、上下文数据和外部数据。通过结合这些数据,尤其是来自任务的信息,生成的回答更加准确。
[0143]
图3b示意性地描绘了根据本公开的一些实施例的步骤310。应当特别注意的是,除非在本公开中另有说明,否则步骤310所包括的步骤可以以不同的顺序排列,因此不限于图3b所示的顺序。
[0144]
在步骤311中,在接收到任务,特别是任务的描述时,文本独热编码器121使用固定大小的词汇将文本任务描述,即序列词{w1,w2,
…
,wi...,w
t
},转换为独热向量{v1,v2,...,vi...,v
t
},并将独热向量发送到词嵌入模块122。
[0145]
在步骤312中,在接收到独热向量{v1,v2,
…
,vi...,v
t
}后,词嵌入模块122将独热向量嵌入至任务描述的嵌入向量{e1,e2,...,ei,...,e
t
}中,并将该嵌入向量发送到bilstm模块123。在一些实施例中,词嵌入模块122是嵌入层。
[0146]
在步骤313中,在接收到嵌入向量后,bilstm模块123对嵌入向量执行bilstm以获得任务特征向量{u1,u2,...,ui,...,u
t
},并将任务特征向量发送到任务拼接模块125和双重注意力融合模块150。
[0147]
任务拼接模块125将会在步骤360处对任务特征向量{u1,u2,...,ui,...,u
t
}和任务嵌入向量(拼接的esi、eti和eii)进行拼接,以获得拼接任务向量。双重注意力融合模块150将会在步骤370处使用拼接任务向量和任务特征向量{u1,u2,...,ui,...,u
t
}执行双重协同注意力。
[0148]
图3c示意性地描绘了根据本公开的一些实施例的步骤350。应当特别注意的是,除
非在本公开中另有说明,否则步骤320所包括的步骤可以以不同的顺序排列,因此不限于如图3c所示的顺序。
[0149]
在步骤351中,在检索与任务相关的上下文时,上下文类型模块141确定上下文是文本上下文还是图像上下文,并将图像上下文发送到cnn模块142,将文本上下文发送到文本独热编码器143。在一些实施例中,上下文包括多个文本上下文和多个图像上下文,多个上下文中的每一个上下文都被相应地处理。
[0150]
在步骤352中,在接收到一个图像上下文时,cnn模块142对图像执行cnn以获得嵌入图像向量(区域特征向量),并将嵌入图像向量发送到bilstm模块145。在一些实施例中,将图像划分为n个区域,对每个区域执行cnn以提取特征从而获得特征向量{r1,r2,...,ri,...,rn},其中ri是表示图像的第i个区域的特征向量。
[0151]
在步骤353中,在接收到一个文本上下文时,文本独热编码器143将文本上下文描述转换为独热向量,并将独热向量发送到词嵌入模块144。
[0152]
在步骤354中,在接收到独热向量后,词嵌入模块144将独热向量嵌入至文本上下文的嵌入文本向量中,并将嵌入文本向量发送到bilstm模块145。在一些实施例中,词嵌入模块144是嵌入层。
[0153]
在步骤355中,在接收到来自cnn模块142的嵌入图像向量或来自词嵌入模块144的嵌入文本向量时,bilstm模块145对嵌入向量执行bilstm以获得上下文特征向量,并将该上下文特征向量发送到上下文拼接模块147和双重注意力融合模块150。
[0154]
上下文拼接模块147将会针对图像上下文或文本上下文,在步骤360处对上下文特征向量和上下文嵌入矩阵进行拼接,以获得拼接上下文向量。双重注意力融合模块150将在步骤370处使用拼接上下文向量和上下文特征向量执行双重协同注意力。
[0155]
图3d示意性地描绘了根据本公开的一些实施例的步骤390。应当特别注意的是,除非在本公开中另有说明,否则步骤390所包括的步骤可以以不同的顺序排列,因此不限于如图3d所示的顺序。
[0156]
当解码器170接收到任务的bilstm矩阵和上下文的bilstm矩阵时,解码器170对这些矩阵进行处理以生成回答。在一些实施例中,解码器170逐词生成回答。因此,在时间步t-1之后,部分回答包括t-1个词。在一些实施例中,句尾分词(例如</end>)位于解码器模型的词汇中。一旦解码器模型生成句尾分词,回答生成过程就结束了。此外,为了生成回答的第一个词,不需要运行lstm 434。
[0157]
在步骤391中,在时间步t处,回答独热编码器171将部分回答的t-1个词转换为序列独热向量,并将独热向量发送到嵌入模块172。
[0158]
在步骤392中,在接收到独热向量后,嵌入模块172将独热向量嵌入部分回答的嵌入向量,并将嵌入向量发送到lstm模块173。
[0159]
在步骤393中,在从嵌入模块172接收到部分回答的嵌入向量后,lstm模块173对嵌入向量执行单向lstm以捕获部分回答中的词之间的依赖关系,拼接lstm中所有的隐藏状态以获得中间解码器状态,并将中间解码器状态发送到指针分布模块174。
[0160]
在步骤394中,在接收到中间解码器状态时,指针分布模块174将中间解码器状态与任务描述的最终编码相结合,以针对任务描述中的每个词向量生成注意力,即任务描述指针分布;将中间解码器状态与上下文的最终编码相结合,以针对上下文(如果是文本格
式)中的每个词生成注意力,即上下文指针分布;将中间解码器状态与上下文(如果是图像格式)的最终编码以及上下文注意力相结合以作为全连接层的输入,以生成词汇分布;并将分布发送到切换模块175。
[0161]
在步骤395中,在接收到分布后,切换模块175学习词汇指针切换和上下文-任务切换,并将切换发送到回答选择模块176。词汇指针切换调节从外部词汇生成回答相比于从上下文或任务描述生成回答的概率,切换模块175通过结合当前中间解码器状态、上下文最终编码输出以及已经生成的回答词的嵌入来学习词汇指针切换。上下文-任务描述切换调节从上下文生成回答相比于从任务描述生成回答的概率,切换模块175通过结合当前中间解码器状态、任务描述最终编码输出以及已经生成的回答词的嵌入来学习上下文-任务描述切换。
[0162]
在步骤396中,在接收到词汇指针切换和上下文-任务切换后,回答选择模块176将其用作权重对上下文指针分布、任务描述指针分布以及词汇分布进行平均化,以获得最终回答分布,从而确定时间步t处的词。通过重复上述步骤,可以逐个选择回答中的词,并将最终完整的回答提供给分配任务或提出问题的用户。
[0163]
需要注意,上述方法不限于图3a-3d中所示的实施例,其他合理变体也可适用。
[0164]
图4a和图4b示意性地描绘了根据本公开的一些实施例的用于多媒体数据语义分析的基于注意力的融合网络,其中图4a示出了编码器部分,图4b示出了解码器部分。
[0165]
如图4a所示,当任务可用时,该任务可以是文本问题,通过多媒体数据分析应用118对该任务进行分析。任务的描述包括文本402和任务元信息或任务元数据404。文本402包括任务的序列文本描述,例如文本格式的问题。任务元信息404是任务的信息,例如任务的来源、类型和索引。任务编码器406包括在多媒体数据分析应用118中,任务编码器406包括用于对任务特定信息进行编码的三个嵌入层。三个嵌入层是列出不同任务来源的源矩阵ms、列出不同任务类型的类型矩阵m
t
和列出不同任务索引的索引矩阵mi。多媒体数据分析应用118能够检索与任务相关的数据,即与任务相关的上下文。上下文包括上下文元信息408和多媒体数据410。上下文元信息408是上下文的信息,例如上下文的来源、类型和索引。上下文的多媒体数据410包括文本数据和图像数据。
[0166]
在接收或检索文本402时,多媒体数据分析应用118将文本402中的每个词转换为独热向量,然后将文本402的序列独热向量输入到词嵌入层中以形成序列嵌入向量412。bilstm 414对序列嵌入向量412执行bilstm分析,以获得任务特征向量416。
[0167]
多媒体数据分析应用118还将任务元信息404转换为独热向量,独热向量包括指示来源(此处来源是任务)的独热向量si、指示任务类型(此处类型是文本)的独热向量ti和指示任务索引(此处是任务的标识)的独热向量ii。任务编码器406包括三个嵌入层ms、m
t
和mi,以用于对任务特定信息进行编码。在多媒体数据分析应用118的训练期间可以学习任务编码器406的参数。多媒体数据分析应用118将任务元信息404的独热向量和任务编码器406的矩阵相乘以形成乘积esi、eti和eii,然后将乘积拼接为任务嵌入向量(或任务嵌入矩阵)418,即ki。
[0168]
当任务特征向量416和任务嵌入向量418可用时,多媒体数据分析应用118将任务特征向量416和任务嵌入向量418拼接为拼接任务特征向量。
[0169]
为了得到对任务的回答,多媒体数据分析应用118检索上下文。在一些实施例中,
多媒体数据分析应用118将上下文元信息408转换为表示上下文的来源、类型和索引的独热向量,将独热向量与任务编码器406的矩阵相乘以获得乘积,并将乘积拼接为上下文嵌入向量(或上下文嵌入矩阵)424。
[0170]
对于多媒体数据410,多媒体数据分析应用418使用多媒体编码器426来获得上下文特征向量428。当上下文嵌入向量424和上下文特征向量428可用时,多媒体数据分析应用118将上下文嵌入向量424和上下文特征向量426拼接为拼接上下文向量。
[0171]
如图4a所示,上下文可以包括多个不同的上下文,例如n个上下文,n个上下文中的每一个上下文都可以此方式进行处理以形成相应的拼接上下文向量,此处n是正整数。此外,由于n个上下文中的每一个上下文都可以是文本、图像或其组合,因此产生上下文特征向量426的过程可以是不同的。
[0172]
图5a示意性地示出了使用多媒体编码器426处理文本上下文的过程。文本上下文包括序列词502,多媒体编码器426包括词嵌入模块504和bilstm模块506。如图5a所示,将序列词502转换为独热向量,将独热向量应用于词嵌入模块504以提取每个词的嵌入并作为其分布向量表示。词嵌入层的大小为v
×
d,其中v表示词汇的大小,d表示每个词的嵌入大小。在一些实施例中,任务文本输入嵌入和上下文文本输入嵌入共享同一词汇。每个词嵌入被输入到lstm模块506的一个bilstm rnn单元,以捕获序列中词之间的依赖关系。通过拼接bilstm模块506的所有隐藏状态输出,获得上下文特征向量428。在一些实施例中,由图5a中所示的嵌入模块510和bilstm模块520执行的过程与由图4a中所示的嵌入模块412和bilstm模块414执行的过程相同或相似。
[0173]
图5b示意性地示出了使用多媒体编码器426处理图像上下文的过程。如图5b所示,多媒体编码器426还包括cnn模块514和bilstm模块518。在一些实施例中,bilstm模块518独立于bilstm模块506。当图像512被输入到cnn模块514时,cnn模块514将图像512划分为小的局部区域并将每个区域视为等同于词。由cnn514对每个区域进行卷积神经网络分析,隐藏层(例如最后一个池化层的输出)作为针对该区域的向量表示。从上面提取的局部区域向量516还不具备可供其使用的全局信息,在不具备全局信息时,其代表能力非常有限,会出现诸如对象缩放或位置差异等简单问题从而导致准确性问题。为解决该问题,多媒体数据分析应用118进一步将这些cnn向量516馈送到bilstm518,使得信息可以从相邻的图像块传播,捕获空间信息并保持全局特征。与局部区域对应的每个特征向量被视为等同于一个词并被输入到bilstm模块518的一个bilstm rnn单元。通过拼接bilstm模块518的所有隐藏状态输出,获得上下文特征向量428。
[0174]
返回参考图4a,当任务特征向量416、拼接任务向量、上下文特征向量428和拼接上下文向量可用时,多媒体数据分析应用118使用这些数据进一步执行双重协同注意力融合。
[0175]
在一些实施例中,在步骤1中,多媒体应用118使用协同注意力机制,该机制既注意任务描述又注意上下文并最终融合这两种注意力上下文。应用首先计算亲和矩阵,亲和矩阵包含与所有成对的上下文嵌入向量和任务描述向量对应的亲和分数。对亲和矩阵按行进行归一化以针对任务描述中的每个向量生成整个文档的注意力权重aq,并按列进行归一化以针对上下文中的每个嵌入向量生成整个任务描述的注意力权重ad。接下来,在步骤2中,应用通过计算aq和上下文向量d的乘积,根据任务描述的每个词向量来计算上下文的概要或注意力上下文cq。在步骤3中,应用同样根据上下文的每个嵌入向量计算任务描述的概要
q乘以aq。应用还根据上下文的每个词计算先前注意力上下文的概要c
qad
。这两种运算可以并行进行。针对c
qad
运算的一种可能解释是将任务描述编码映射到上下文编码的空间中。应用将cd(即任务描述和上下文的相互依赖表示)定义为协同注意力上下文。应用重复上述相同的步骤1至3以获得协同注意力问题ac。
[0176]
最后的步骤是通过双向lstm 422和432将时间信息融合到协同注意力上下文中。通过拼接初始嵌入向量416和428、协同注意的向量420和430、以及bilstm 422和432的最终隐藏状态向量,应用获得问题描述和上下文的深度且通用的表示。
[0177]
然后将任务描述和上下文的编码的表示应用到图4b所示的解码器,以根据上下文生成对任务的回答。在一些实施例中,本公开的模型能够生成不在上下文或问题(任务)中的分词。为了达到该目标,模型可以访问v个附加的词汇分词,并且在一些实施例中,编码器和解码器共享同一词汇。因此,本公开可以分别获得上下文、问题和该外部词汇中分词的分布。
[0178]
在各步骤中,解码器网络在三个选项之间做决定:根据词汇生成、指向任务描述和指向上下文。模型可以学习在三个选项之间进行切换。这些分布被扩展为涵盖上下文、问题和外部词汇中分词的联合。两个标量切换调节每个分布在确定最终输出分布上的重要性。在以下步骤中对指针解码器的过程进行详细说明。
[0179]
在步骤1中,对于生成回答过程中的任何时间步t,将直到前一时间步t-1已经生成的回答作为文本转换为其独热编码表示。解码器将文档的这些独热编码表示应用至词嵌入层,以便提取每个词的嵌入以作为其分布向量表示。需要注意,词嵌入层的大小为v
×
d,v表示回答词汇的大小,d表示每个词的嵌入大小。
[0180]
在步骤2中,解码器将每个词的嵌入馈送到单向lstm 434中,以捕获序列中词之间的依赖关系。在直到前一时间步t-1生成的所有隐藏状态将被拼接在一起以作为中间解码器状态。
[0181]
在步骤3中,将中间解码器状态与问题描述的最终编码相结合,以针对任务描述中的每个词向量生成注意力,即任务描述指针分布436。将中间解码器状态与上下文的最终编码相结合,以针对上下文(如果是文本格式)中的每个词生成注意力,即上下文指针分布438。将中间解码器状态与上下文的最终编码以及上下文注意力结合以作为全连接层440的输入,以生成词汇分布442。在一些实施例中,基于上下文(文本或图像)生成词汇分布442。
[0182]
在步骤4中,学习两个标量,第一个标量称为词汇指针切换,其调节从外部词汇生成的回答相比于从上下文或问题描述生成的回答的概率,第二个标量称为上下文-任务描述切换,其调节从上下文生成的回答相比于从任务描述生成的回答的概率。词汇指针切换是通过组合当前中间解码器状态、上下文最终编码输出以及已经生成的回答词的嵌入来进行学习的,上下文-任务描述切换是通过组合当前中间解码器状态、任务描述最终编码输出以及已经生成的回答词的嵌入来进行学习的。
[0183]
在步骤5中,在获得这两个切换之后,解码器将其用作权重对上下文指针分布438、任务描述指针分布436以及词汇分布442进行平均化,以获得最终回答分布444。然后可以从最终回答分布444中选择时间步t处的词。
[0184]
在步骤6中,通过选择词汇中概率最高的词,本公开一次一词的生成预测的最终回答序列。
classification with deep convolutional neural networks,nips,2012.
[0198]
7.antonio rubio,longlong yu,edgar simo-serra,francesc moreno-noguer,multi-modal embedding for main product detection in fashion,the ieee international conference on computer vision(iccv),2017,pp.2236-2242.
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。