技术特征:
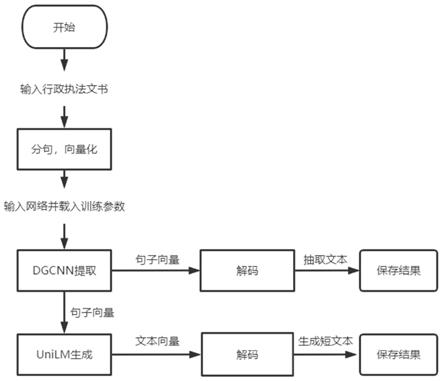
1.一种智能行政执法案例信息抽取和案由认定方法,其特征在于,包括步骤如下:a、数据集的构建:爬取行政处罚决定书,提取其中的文本内容,对文本内容中的短文本进行标注;b、语料转换:将行政执法文书中所有长句按照标点符号分割为短句;将步骤a数据集中标注的短文本根据标点符号进行分句;在短文本中找到最长的短句,把这个最长的短句作为标准,从行政处罚文书中找出与这个最长的短句相似的句子,提取并保存,递归执行直到短文本中所有的语句都被执行过一次;c、抽取数据预处理及向量化:步骤b在行政执法文书中抽出了与标签即短文本相似的语句;对抽取出的文本进行过滤,将文本转换成以空格分割的句子序列;将句子序列编码索引;对得到的文本数据进行全局平均池化之后再引入全词mask的bert预训练中文模型,补充平均池化,把分割的句子序列转换为句子向量;d、基于dgcnn的抽取模型的训练:将步骤b中在行政执法文书中抽出的与标签即短文本的句子向量当作标签,将行政执法文书整个文本生成的句子向量作为输入,训练抽取模型;e、基于unilm的短文本生成:将通过训练后的抽取模型抽取出来的行政执法文书的关键语句作为输入,人工标注的短文本作为标签,训练生成模型;f、输入执法文书文本进行预测:将需要转化的行政执法文书通过步骤a至步骤c处理后,将得到的处理结果输入训练后的抽取模型,生成抽取结果并保存,抽取结果进一步输入训练后的生成模型,得到适合下游其他任务分析的短文本,最终得到抽取结果和适合下游其他任务分析的短文本。2.根据权利要求1所述的一种智能行政执法案例信息抽取和案由认定方法,其特征在于,步骤a中,对文本内容进行标注,是指:从行政执法文书中提取所有需要的关键字段,并根据语义重新组合成新的一段仅包括关键目的信息的短文本;在行政处罚文书中对这些短文本进行标注。3.根据权利要求1所述的一种智能行政执法案例信息抽取和案由认定方法,其特征在于,步骤b中,将行政执法文书中所有长句按照标点符号分割为短句,具体是指:采用jieba分词将行政执法文书文本根据标点符号分割成句子格式,并保存为列表中的元素;将步骤a数据集中标注的短文本根据标点符号进行分句,具体是指:采用jieba分词将标注的短文本分割成短句格式,并保存为数组格式;提取数组中的最长的短句,在列表中的行政执法文书中进行匹配,提取列表中的行政执法文书中和最长的短句最相似的句子并保存,递归地执行此步骤,直到将数组中所有的句子都匹配一遍。4.根据权利要求3所述的一种智能行政执法案例信息抽取和案由认定方法,其特征在
于,提取列表中的行政执法文书中和最长的短句最相似的句子,具体实现过程如下:假设x1是标注短文本序列x=[x1,x2,...x
n
]中的一个句子,y
m
是行政执法文书序列y=[y1,y2,...y
m
]中的一个句子,则flcs如式(1)所示:式(1)中,r
lcs
是指召回率,是抽取出的文本与短文本中相同字的个数,与人工标签即短文本中字的个数的比值;p
lcs
是指准确率,是指抽取出的文本与短文本中相同字的个数,与抽取出字的总个数的比值;f
lcs
就是rouge-l;针对将标注短文本序列x中的一个句子x
n
与行政执法文书序列中的所有句子y
j
,j=1,2...m;计算f
lcs
,取使得f
lcs
分数最高的行政执法文书序列中的句子y
k
作为最相似语句并保存,递归地进行此步骤,直到标注短文本序列x中所有句子都匹配完成,将抽取结果保存为r,即为最相似的句子。5.根据权利要求1所述的一种智能行政执法案例信息抽取和案由认定方法,其特征在于,步骤c的具体实现过程如下:首先,利用tensorflow中的tokenizer工具包去除文本中的标点符号、换行符号进行文本预处理;然后,利用tokenizer工具包的fit_on_texts方法学习出文本的字典,word_index就是对应的单词和数字的映射关系dict,通过这个dict将每个句子中的每个词转成数字,即texts_to_sequences;再次,通过padding的方法补成同样长度;在用keras中自带的embedding层进行一个向量化;最后,引入全词mask的bert预训练中文模型即chinese_roberta_wwm_ext_l-12_h-768_a-12预训练模型来补充平均池化。6.根据权利要求1所述的一种智能行政执法案例信息抽取和案由认定方法,其特征在于,步骤d的具体实现过程如下:将步骤c得到的行政执法文书文本对应的句子向量当作抽取模型的输入,通过一层的dgcnn提取特征,将提取的特征输入attention层来完成对序列信息的整合,包括将行政执法文书的句子向量序列编码为一个总的行政执法文书文本向量,将标注短文本的句子向量编码为一个总的标注短文本向量,attention层如式(2)所示:式(2)中,α,w都为可训练参数,而act()为激活函数,取tanch;x
i
是编码前的序列,x是编码完成后的向量,λ
i
是计算时的权重,softmax
i
()是激活函数函数,又称归一化指数函数;之后,把步骤c得到的总的行政执法文书文本对应的句子向量x作为输入,将抽取出的
最相似句子向量y作为对应的标签,输入5层dgcnn,之后连接一层全连接层;采用sigmoid激活函数激活之后,与指定的阈值进行比较,大于阈值的句子向量保存为列表,小于阈值的向量丢弃,之后将句子向量解码为原文本最终得到信息抽取结果。7.根据权利要求6所述的一种智能行政执法案例信息抽取和案由认定方法,其特征在于,dgcnn是膨胀门卷积神经网络,其搭建方式如下:首先,给普通的一维卷积加个门,公式表示如式(3)所示:式(3)中,其中,x表示输入序列,y表示输出序列,conv1d1和conv1d2是两个一维卷积;接下来,使用膨胀卷积;具体是指:先将输入x通过一层全连接层提取特征后输入扩张率为1的膨胀门卷积层,再将输出输入到扩张率为2的膨胀门卷积层;之后再连接一层扩张率为4的膨胀门卷积层和一层扩张率为8的膨胀门卷积层;最后连接两层扩张率为1的膨胀门卷积层后,通过sigmoid激活的全连接层后输出结果y。8.根据权利要求1-7任一所述的一种智能行政执法案例信息抽取和案由认定方法,其特征在于,步骤e的具体实现过程如下:a、将步骤b中行政执法文书数据y和对应的标注短文本x分组成n条,分组的标准是:n-1条数据作为训练集给步骤d中的抽取模型训练,在预测阶段使用那条没有被训练的数据作为输入来预测生成短文本,把这个步骤重复进行n次,直到所有数据都被训练到和作为预测的输入时停止,这样就得到全部行政执法文书文本的抽取短文本,记为c;b、将分组后得到的数据输入unilm网络进行训练:首先,把读取到的一段抽取短文本序列c进行打包,结果为p0=[x1,x2,...x
x
];然后,将上述打包结果p0输入一个k层的transformer,即p
k
=transformer
k
(p
k-1
),k∈[1,k];这样,p通过k层transformer,将p0编码成在不同抽象层面p
k
=[x
1k
,x
2k
,...x
xk
]上的上下文向量表征;对于第k层transformer,其自注意头a
k
的输出计算方式如式(4)所示:式(4)中,q,k,v为三个向量,是训练出来的权重矩阵,k∈[1,k];m是掩码矩阵,m
ij
是掩码矩阵的元素,表示是否被关注,0表示受到关注,负无穷表示被掩码;d
k
表示矩阵k的维数,a
k
和v
k
的下标k表示第k层。9.一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现智能行政执法案例信息抽取和案由认定方法的步骤。10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现智能行政执法案例信息抽取和案由认定方法的步骤。
技术总结
本发明涉及一种智能行政执法案例信息抽取和案由认定方法,包括:A、数据集的构建;B、语料转换:C、抽取数据预处理及向量化:D、基于DGCNN的抽取模型的训练:E、基于UniLM的短文本生成,训练生成模型;F、输入执法文书文本进行预测:将需要转化的行政执法文书通过步骤A至步骤C处理后,将得到的处理结果输入训练后的抽取模型,生成抽取结果并保存,抽取结果进一步输入训练后的生成模型,得到适合下游其他任务分析的短文本。本发明通过采用DGCNN作为抽取模型,利用其非序列化的神经网络结构特点进行文本数据的信息抽取,大大减少了所耗费的时间资源和计算资源,提升了抽取的准确性。提升了抽取的准确性。提升了抽取的准确性。
技术研发人员:贲晛烨 冯晓炜 李玉军 周莹 孙浩 谢霆轩
受保护的技术使用者:山东大学
技术研发日:2022.02.24
技术公布日:2022/5/31
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。