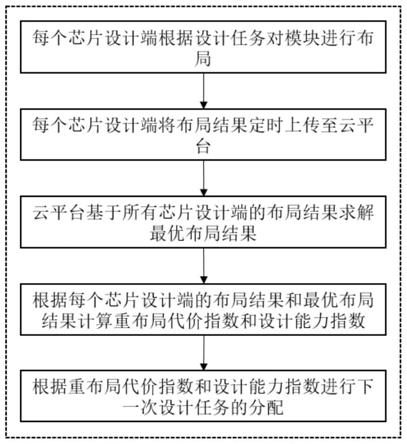
1.本发明属于计算机技术领域,具体涉及一种半监督人脸情绪识别方法。
背景技术:
2.对人类情感的精确识别可以帮助人工智能实现人机交互。目前,情绪识别主流的方法包括基于特征的方法和基于深度学习的方法。特征提取的方法主要基于定向梯度直方图和局部二进制模式,但这些特征不适用于数据的非线性结构,准确率不高。利用深度学习技术,基于面部表情的情感识别得到了显著提高。深度学习技术需要大量标签数据对神经网络进行训练,而这会导致训练过程中需要耗费大量人力物力。目前常见的数据集包括离散域数据集和连续域数据集,其中,离散域数据集包含的数据有限,难以表达丰富的人类情感,而获取连续域数据集标签的成本高昂,训练难度大。
技术实现要素:
3.本发明的目的在于提供一种半监督人脸情绪识别方法(semi-supervised emotion recognition,简称为semi emotion),本方法能够简单高效地识别丰富的人脸情绪。
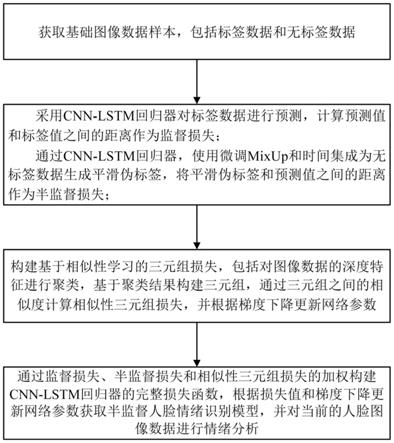
4.本发明提供的这种半监督人脸情绪识别方法,包括如下步骤:
5.s1.获取基础图像数据样本,包括标签数据和无标签数据;
6.s2.采用cnn-lstm(卷积神经网络-长短期记忆网络)回归器对标签数据进行预测,计算预测值和标签值之间的距离作为监督损失;
7.通过cnn-lstm回归器,使用微调mixup和时间集成为无标签数据生成平滑伪标签,将平滑伪标签和预测值之间的距离作为半监督损失;
8.s3.构建基于相似性学习的三元组损失,包括对图像数据的深度特征进行聚类,基于聚类结果构建三元组,通过三元组之间的相似度计算相似性三元组损失,并根据梯度下降更新网络参数;
9.s4.通过监督损失、半监督损失和相似性三元组损失的加权构建cnn-lstm回归器的完整损失函数,根据损失值和梯度下降更新网络参数获取半监督人脸情绪识别模型,并对当前的人脸图像数据进行情绪分析。
10.所述的cnn-lstm回归器,包括在每一帧中,使用s3d人脸检测算法对图像的人脸区域进行检测;利用基于resnet的cnn编码器提取深度特征;在引入lstm之前,通过全连接层将提取的特征长度调整为2048;在引入lstm之后,分别由两个不同的全连接层输出激励和效价;lstm包括遗忘门、输入门和输出门。
11.所述的步骤s2包括,对无标签数据进行数据扩充,然后对扩充数据的预测取均值;使用微调mixup对标签数据与无标签数据混合后得到目标数据;网络对目标数据进行预测并计算损失函数。
12.所述的步骤s3,包括如下步骤:
13.a1.对图像的深度特征进行聚类:
14.a2.通过一次迭代后cnn提取的样本特征计算加权项,将加权项加入聚类中心中进行更新;
15.a3.给定一个批处理的样本,对批处理的样本中的数据构建三元组,得到聚类空间的数据的激活矩阵,并计算数据间的相似性与差异性损失;通过数据间的相似性和差异性损失获取最终的相似性三元组损失。
16.所述的步骤a1,包括对于给定的基础图像数据样本,对初始的标签数据的深度特征进行聚类后得到初始聚类中心;在训练过程中,将无标签数据和标签数据同时输入到cnn-lstm回归器中,计算与基础图像数据样本距离最小的聚类中心,同时基础图像数据样本的聚类类别由与其距离最小的聚类中心决定。
17.所述的步骤a2包括,根据一次迭代后cnn提取的样本特征计算加权项包括通过初始聚类深度特征之和和基础图像数据样本距离最小的聚类中心的倒数的积,与经过一次迭代后cnn提取的样本特征与经过一次迭代后与基础图像数据样本距离最小的聚类中心的倒数的积求和,一直迭代到预定迭代终止次数;迭代后聚类空间中样本间的距离为两个不同的基础图像数据样本的特征向量的欧几里得范数。
18.所述的步骤a3,包括给定一个批处理的样本,构建三元组,三元组包括每个批处理中标签数据、聚类空间中与每个批处理中标签数据同类中距离最远的数据和聚类空间中与每个批处理中标签数据异类中距离最近的数据;每个批处理中标签数据对激活图的激活模式进行的编码为,每个批处理中标签数据在cnn中的激活通道的重塑矩阵及其转置的积;对每个批处理中标签数据对激活图的激活模式进行的编码进行逐行归一化求得每个批处理中标签数据的激活矩阵;同时求解聚类空间中与每个批处理中标签数据同类中距离最远的数据的激活矩阵,和聚类空间中与每个批处理中标签数据异类中距离最近的数据的激活矩阵;
19.定义数据间的相似性为激活矩阵之间的差值,求解激活矩阵之间的差值,包括:求解每个批处理中标签数据的激活矩阵,和聚类空间中与每个批处理中标签数据同类中距离最远的数据的激活矩阵之间的差值;
20.计算差异性损失,包括:求解每个批处理中标签数据的激活矩阵,和聚类空间中与每个批处理中标签数据异类中距离最近的数据的激活矩阵的差异性损失;
21.求得相似性三元组损失为:每个批处理中标签数据的激活矩阵,和聚类空间中与每个批处理中标签数据同类中距离最远的数据的激活矩阵之间的差值,减去每个批处理中标签数据的激活矩阵,和聚类空间中与每个批处理中标签数据异类中距离最近的数据的激活矩阵的差异性损失。
22.所述的步骤s2,包括:
23.对于未标签数据,使cnn-lstm回归器从平滑的标签学习,第一次对无标签数据进行数据扩充:u表示无标签数据;augment(
·
)表示扩充操作;表示扩充后的无标签数据;k表示数据扩充的次数;对扩充后的无标签数据取均值;
24.25.其中,q表示取均值后的预测分布;k表示数据扩充的次数;i表示给定的基础图像数据样本的计数变量;p
model
表示深度网络模型;ui表示某一张图片;θ表示网络参数;
26.将标签数据(x1,p)和无标签数据(u1,q)混合,x1表示标签图像,p表示标签图像的标签,u1表示无标签图像,q表示对无标签图像数据扩充后取均值得到的预测分布,输出目标数据x
′
表示标签图像与无标签图像混合得到的数据;表示标签图像的标签与标签图像数据扩充后取均值得到的预测分布混合后的分布;将目标数据作为学习目标:
27.x
′
=λ
′
x1 (1-λ
′
)u1[0028][0029]
其中,α表示超参数;λ
′
=max(λ,1-λ),λ~bata(α,α),λ表示从beta分布中随机取出的值,λ
′
表示λ与1-λ间的最大值;max(
·
)表示取其中的最大值;beta(
·
)表示beta分布;
[0030]
对目标数据进行预测得到预测值p
′
,为了从不同角度获取信息,采用不同训练时段的cnn-lstm回归器对伪标签进行投票:
[0031][0032]
其中,p表示最终得到的伪标签;p
n-model
(y|x
′
;θ)表示n个迭代前的cnn-lstm回归器;采用预测值p
′
和最终得到的伪标签p之间的均方误差计算半监督损失lu:
[0033]
lu=||p
′‑
p||2[0034]
其中,||
·
||2表示均方误差;
[0035]
采用交叉熵计算监督损失l
x
:
[0036][0037]
其中,p
nodel
(y|x;θ)表示cnn-lstm回归器对标签数据的预测;h(
·
)表示交叉熵损失函数。
[0038]
所述的步骤a1,聚类过程包括对于给定的第i个基础图像数据样本yi,特征向量为xi={x1,x2,...,x
2048
};对初始的n个标签数据的深度特征进行聚类后得到k个初始聚类中心c={c1,c2,...,ck,...,ck};其中,ck的特征向量的长度为2048,在训练过程中,将无标签数据和标签数据同时输入到cnn-lstm回归器中,计算第i个基础图像数据样本yi同时与其距离最小的聚类中心ck的距离d
ik
,同时第i个基础图像数据样本yi的聚类类别由与其距离最小的聚类中心ck决定:
[0039][0040]ck
=arg min
k∈{1,2,...,k}dik
[0041]
其中,ck表示与第i个基础图像数据样本yi距离最小的聚类中心;arg min(
·
)表示距离的最小值;k表示初始聚类中心的个数;d
ik
表示第i个基础图像数据样本yi的特征向量xi与第k个聚类中心的距离;表示欧几里得范数;
[0042]
所述的步骤a2,包括:根据一次迭代后cnn提取的样本特征计算加权项:
[0043][0044]
其中,表示经过一次迭代后与第i个基础图像数据样本yi距离最小的聚类中心;x表示初始聚类深度特征;x
(1)
表示经过一次迭代后cnn提取的样本特征,一直迭代到预定迭代终止次数;ck表示与第i个基础图像数据样本yi距离最小的聚类中心;
[0045]
计算迭代后聚类空间中样本间的距离;
[0046][0047]
其中,表示经过一次迭代后第i个基础图像数据样本yi与其距离最小的聚类中心ck的距离;xi表示第i个基础图像数据样本yi的特征向量;xj表示第j个基础图像数据样本yj的特征向量;表示欧几里得范数;
[0048]
所述的步骤a3,包括给定一个批处理的样本n,构建三元组(n1,n2,n3),其中,n1表示每个批处理中标签数据;n2表示聚类空间中与每个批处理中标签数据n1同类中距离最远的数据;n3表示聚类空间中与每个批处理中标签数据n1异类中距离最近的数据;设为每个批处理中标签数据n1在cnn中第l层的激活通道;r表示张量空间;c表示通道数;h表示高;w表示宽;设作为每个批处理中标签数据n1在cnn中第l层的激活通道的重塑矩阵,求得:
[0049][0050]
其中,其中,表示每个批处理中标签数据n1第i行第j列对激活图的激活模式进行的编码;对每个批处理中标签数据n1第i行第j列对激活图的激活模式进行的编码进行逐行归一化求得每个批处理中标签数据n1的激活矩阵求解聚类空间中与每个批处理中标签数据n1同类中距离最远的数据n2的激活矩阵和聚类空间中与每个批处理中标签数据n1异类中距离最近的数据n3的激活矩阵
[0051]
设为聚类空间中与每个批处理中标签数据n1同类中距离最远的数据n2在cnn中第l层的激活通道;r表示张量空间;c表示通道数;h表示高;w表示宽;设作为聚类空间中与每个批处理中标签数据n1同类中距离最远的数据n2在cnn中第l层的激活通道的重塑矩阵,求得:
[0052][0053]
其中,其中,表示聚类空间中与每个批处理中标签数据n1同类中距离最远的数据n2第i行第j列对激活图的激活模式进行的编码;对聚类空间中与每个批处理中标签数据n1同类中距离最远的数据n2第i行第j列对激活图的激活模式进行的编码进行逐行归一化求得聚类空间中与每个批处理中标签数据n1同类中距离最远的数据n2的激活矩阵
[0054]
设为聚类空间中与每个批处理中标签数据n1异类中距离最近的数据n3在cnn中第l层的激活通道;r表示张量空间;c表示通道数;h表示高;w表示宽;设作为聚类空间中与每个批处理中标签数据n1异类中距离最近的数据n3在cnn中第l层的激活通道的重塑矩阵,求得:
[0055][0056]
其中,其中,表示聚类空间中与每个批处理中标签数据n1异类中距离最近的数据n3第i行第j列对激活图的激活模式进行的编码;对聚类空间中与每个批处理中标签数据n1异类中距离最近的数据n3第i行第j列对激活图的激活模式进行的编码进行逐行归一化求得聚类空间中与每个批处理中标签数据n1异类中距离最近的数据n3的激活矩阵
[0057]
定义数据间的相似性为激活矩阵之间的差值,求解激活矩阵之间的差值,包括:求解每个批处理中标签数据n1的激活矩阵和聚类空间中与每个批处理中标签数据n1同类中距离最远的数据n2的激活矩阵之间的差值l
si
(n1,n2):
[0058][0059]
其中,b表示三元组;n1表示每个批处理中标签数据;n2表示聚类空间中与每个批处理中标签数据n1同类中距离最远的数据;表示frobenius范数;
[0060]
计算差异性损失,包括:求解每个批处理中标签数据n1的激活矩阵和聚类空间中与每个批处理中标签数据n1异类中距离最近的数据n3的激活矩阵的差异性损失:
[0061][0062]
其中,b表示三元组;n1表示每个批处理中标签数据;n3表示聚类空间中与每个批处
理中标签数据n1异类中距离最近的数据;表示frobenius范数;
[0063]
求得相似性三元组损失为:
[0064]
l
cs
=l
si
(n1,n2)-l
di
(n1,n3)
[0065]
其中,l
cs
表示相似性三元组损失;l
si
(n1,n2)表示每个批处理中标签数据n1的激活矩阵和聚类空间中与每个批处理中标签数据n1同类中距离最远的数据n2的激活矩阵之间的差值;l
di
(n1,n3)表示每个批处理中标签数据n1的激活矩阵和聚类空间中与每个批处理中标签数据n1异类中距离最近的数据n3的激活矩阵的差异性损失。
[0066]
所述的步骤s4包括,cnn-lstm回归器损失函数为l=l
x
lu ωul
cs
,其中,l
x
表示监督损失;lu表示半监督损失;ωu表示超参数;l
cs
表示相似性三元组损失。
[0067]
本发明提供的这种半监督人脸情绪识别方法,在连续域数据集中识别准确高效,同时通过调整末端在离散域数据集中取得了优异的识别率;本发明通过基于相似性学习的三元组损失函数,能够学习人脸图像间的相似性,提高了情绪变化的识别率;本发明为无标签数据生成了可靠的伪标签,并利用伪标签数据训练网络,缓解了由于标记数据不足带来的性能损失。
附图说明
[0068]
图1为本发明方法的流程示意图。
[0069]
图2为本发明方法的cnn-lstm回归器检测流程示意图。
[0070]
图3为本发明方法的卷积神经网络流程示意图。
具体实施方式
[0071]
如图1为本发明方法的流程示意图:本发明提供的这种半监督人脸情绪识别方法,包括如下步骤:
[0072]
s1.获取基础图像数据样本,包括标签数据和无标签数据;
[0073]
s2.采用cnn-lstm回归器(卷积神经网络-长短期记忆网络)对标签数据进行预测,计算预测值和标签值之间的距离作为监督损失;
[0074]
通过cnn-lstm回归器,使用微调mixup和时间集成为无标签数据生成平滑伪标签,将平滑伪标签和预测值之间的距离作为半监督损失;
[0075]
s3.构建基于相似性学习的三元组损失,包括对图像数据的深度特征进行聚类,基于聚类结果构建三元组,通过三元组之间的相似度计算相似性三元组损失,并根据梯度下降更新网络参数;
[0076]
s4.通过监督损失、半监督损失和相似性三元组损失的加权构建cnn-lstm回归器的完整损失函数,根据损失值和梯度下降更新网络参数获取半监督人脸情绪识别模型,并对当前的人脸图像数据进行情绪分析。
[0077]
如图2为本发明方法的cnn-lstm回归器检测流程示意图。所述的cnn-lstm回归器,包括在每一帧中,使用s3d人脸检测算法对图像的人脸区域进行检测;利用基于resnet的cnn编码器提取深度特征;resnet结合了几个卷积层的特性,产生了密集的连接,同时,
resnet可以保留图像的底层特征,同时防止梯度消失。在引入lstm之前,通过全连接层将提取的特征长度调整为2048。在引入lstm之后,分别由两个全连接层输出激励和效价。lstm包括遗忘门、输入门和输出门;遗忘门用来丢弃无用的信息,输入门可以有选择地保存信息,输出门用来确定输出信息。这种结构允许lstm使用前一个节点的知识来预测当前节点。选用lstm是因为虽然情绪只由单个图像输出,但考虑到情绪在连续域中的变化,连续时间信号就成为了关键信息。
[0078]
因为afew-va数据集是从有限的对象中提取情感信息,所以难以从afew-va数据集中学习到足够的特征多样性。为了避免过拟合,选择imagenet数据集对网络进行预训练。此外,在fer2013数据集上对预训练的网络进行微调,获得适合于人脸的情感识别的参数。在微调过程中,前半段卷积层的参数被冻结,后半段卷积层的参数通过反向传播来学习。
[0079]
如图3为本发明方法的卷积神经网络流程示意图。所述的步骤s2,包括:
[0080]
对于未标签数据,使cnn-lstm回归器从平滑的标签学习,第一次对无标签数据进行数据扩充:u表示无标签数据;augment(
·
)表示扩充操作;表示扩充后的无标签数据;k表示数据扩充的次数;为了修正预测,对扩充后的无标签数据取均值;
[0081][0082]
其中,q表示取均值后的预测分布;k表示数据扩充的次数;i表示给定的基础图像数据样本的计数变量;p
model
表示深度网络模型;ui表示某一张图片;θ表示网络参数;
[0083]
将标签数据(x1,p)和无标签数据(u1,q)混合,x1表示标签图像,p表示标签图像的标签,u1表示无标签图像,g表示对无标签图像数据扩充后取均值得到的预测分布,输出目标数据x
′
表示标签图像与无标签图像混合得到的数据;表示标签图像的标签与标签图像数据扩充后取均值得到的预测分布混合后的分布;将目标数据作为学习目标:
[0084]
x
′
=λ
′
x1 (1-λ
′
)u1[0085][0086]
其中,α表示超参数;λ
′
=max(λ,1-λ),λ~bata(α,α);λ表示从beta分布中随机取出的值,λ
′
表示λ与1-λ间的最大值,作为平衡系数;max(
·
)表示取其中的最大值;beta(
·
)表示beta分布;
[0087]
对目标数据进行预测得到预测值p
′
,为了从不同角度获取信息,采用不同训练时段的cnn-lstm回归器对伪标签进行投票:
[0088][0089]
其中,p表示最终得到的伪标签;p
n-model
(y|x
′
;θ)表示n个迭代前的cnn-lstm回归器;采用预测值p
′
和最终得到的伪标签p之间的均方误差计算半监督损失lu:
[0090]
lu=||p
′‑
p||2[0091]
其中,||
·
||2表示均方误差;
[0092]
采用交叉熵计算监督损失l
x
:
[0093][0094]
其中,p
model
(y|x;θ)表示cnn-lstm回归器对标签数据的预测;h(
·
)表示交叉熵损失函数。
[0095]
所述的步骤s3,包括如下步骤:
[0096]
a1.对图像的深度特征进行聚类:
[0097]
所述的步骤a1,聚类过程包括为了选取更好的三元组进行相似性学习,本方法使用了调整后的聚类方法对深度特征进行聚类。对于给定的第i个基础图像数据样本yi,特征向量为xi={x1,x2,...,x
2048
};对初始的n个标签数据的深度特征进行聚类后得到k个初始聚类中心c={c1,c2,...,ck,...,ck};其中,ck的特征向量的长度为2048,在训练过程中,将无标签数据和标签数据同时输入到cnn-lstm回归器中,计算第i个基础图像数据样本yi同时与其距离最小的聚类中心ck的距离d
ik
,同时第i个基础图像数据样本yi的聚类类别由与其距离最小的聚类中心ck决定:
[0098][0099]ck
=arg min
k∈{1,2,...,k}dik
[0100]
其中,ck表示与第i个基础图像数据样本yi距离最小的聚类中心;arg min(
·
)表示距离的最小值;k表示初始聚类中心的个数;d
ik
表示第i个基础图像数据样本yi的特征向量xi与第k个聚类中心的距离;表示欧几里得范数;
[0101]
a2.通过一次迭代后cnn提取的样本特征计算加权项,将加权项加入聚类中心中进行更新;根据一次迭代后cnn提取的样本特征计算加权项:
[0102][0103]
其中,表示经过一次迭代后与第i个基础图像数据样本yi距离最小的聚类中心;x表示初始聚类深度特征;x
(1)
表示经过一次迭代后cnn提取的样本特征,一直迭代到预定迭代终止次数,在本实施例中迭代一次表示深度神经网络训练一轮,迭代次数在网络训练开始前设定;ck表示与第i个基础图像数据样本yi距离最小的聚类中心;
[0104]
计算迭代后聚类空间中样本间的距离;
[0105][0106]
其中,表示经过一次迭代后第i个基础图像数据样本yi与其距离最小的聚类中心ck的距离;xi表示第i个基础图像数据样本yi的特征向量;xj表示第j个基础图像数据样本yj的特征向量;表示欧几里得范数;
[0107]
a3.给定一个批处理(batch)的样本,对批处理的样本中的数据构建三元组,得到聚类空间的数据的激活矩阵,并计算数据间的相似性与差异性损失;通过数据间的相似性
和差异性损失获取最终的相似性三元组损失;
[0108]
所述的步骤a3,包括给定一个批处理的样本n,构建三元组(n1,n2,n3),其中,n1表示每个批处理中标签数据;n2表示聚类空间中与每个批处理中标签数据n1同类中距离最远的数据;n3表示聚类空间中与每个批处理中标签数据n1异类中距离最近的数据;设为每个批处理中标签数据n1在cnn中第l层的激活通道;r表示张量空间;c表示通道数;h表示高;w表示宽;设作为每个批处理中标签数据n1在cnn中第l层的激活通道的重塑矩阵,求得:
[0109][0110]
其中,其中,表示每个批处理中标签数据n1第i行第j列对激活图的激活模式进行的编码;对每个批处理中标签数据n1第i行第j列对激活图的激活模式进行的编码进行逐行归一化求得每个批处理中标签数据n1的激活矩阵类似的,可以求解聚类空间中与每个批处理中标签数据n1同类中距离最远的数据n2的激活矩阵和聚类空间中与每个批处理中标签数据n1异类中距离最近的数据n3的激活矩阵即:
[0111]
设为聚类空间中与每个批处理中标签数据n1同类中距离最远的数据n2在cnn中第l层的激活通道;r表示张量空间;c表示通道数;h表示高;w表示宽;设作为聚类空间中与每个批处理中标签数据n1同类中距离最远的数据n2在cnn中第l层的激活通道的重塑矩阵,求得:
[0112][0113]
其中,其中,表示聚类空间中与每个批处理中标签数据n1同类中距离最远的数据n2第i行第j列对激活图的激活模式进行的编码;对聚类空间中与每个批处理中标签数据n1同类中距离最远的数据n2第i行第j列对激活图的激活模式进行的编码进行逐行归一化求得聚类空间中与每个批处理中标签数据n1同类中距离最远的数据n2的激活矩阵
[0114]
设为聚类空间中与每个批处理中标签数据n1异类中距离最近的数据n3在cnn中第l层的激活通道;r表示张量空间;c表示通道数;h表示高;w表示宽;设作为聚类空间中与每个批处理中标签数据n1异类中距离最近的数据n3在cnn中第l层的激活通道的重塑矩阵,求得:
[0115]
[0116]
其中,其中,表示聚类空间中与每个批处理中标签数据n1异类中距离最近的数据n3第i行第j列对激活图的激活模式进行的编码;对聚类空间中与每个批处理中标签数据n1异类中距离最近的数据n3第i行第j列对激活图的激活模式进行的编码进行逐行归一化求得聚类空间中与每个批处理中标签数据n1异类中距离最近的数据n3的激活矩阵
[0117]
定义数据间的相似性为激活矩阵之间的差值,求解激活矩阵之间的差值,包括:求解每个批处理中标签数据n1的激活矩阵和聚类空间中与每个批处理中标签数据n1同类中距离最远的数据n2的激活矩阵之间的差值l
si
(n1,n2):
[0118][0119]
其中,b表示三元组;n1表示每个批处理中标签数据;n2表示聚类空间中与每个批处理中标签数据n1同类中距离最远的数据;表示frobenius范数;
[0120]
计算差异性损失,包括:求解每个批处理中标签数据n1的激活矩阵和聚类空间中与每个批处理中标签数据n1异类中距离最近的数据n3的激活矩阵的差异性损失l
di
(n1,n3):
[0121][0122]
其中,b表示三元组;n1表示每个批处理中标签数据;n3表示聚类空间中与每个批处理中标签数据n1异类中距离最近的数据;表示frobenius范数;
[0123]
求得相似性三元组损失为:
[0124]
l
cs
=l
si
(n1,n2)-l
di
(n1,n3)
[0125]
其中,l
cs
表示相似性三元组损失;l
si
(n1,n2)表示每个批处理中标签数据n1的激活矩阵和聚类空间中与每个批处理中标签数据n1同类中距离最远的数据n2的激活矩阵之间的差值;l
di
(n1,n3)表示每个批处理中标签数据n1的激活矩阵和聚类空间中与每个批处理中标签数据n1异类中距离最近的数据n3的激活矩阵的差异性损失。
[0126]
所述的步骤s4包括,cnn-lstm回归器损失函数为l=l
x
lu ωul
cs
,其中,l
x
表示监督损失;lu表示半监督损失;ωu表示超参数,作为平衡系数;l
cs
表示相似性三元组损失。
[0127]
在本实施例中,本方法(semi emotion)在afew-va连续域情感数据集上进行了实验。afew-va数据集是由电影和电视剧中选取的600个视频,且每一帧都注释一个标签构成的。valence和arousal作为连续域数据集的标签,其大小在[-10,10]范围内。为了便于实验,我们将afew-va数据集的标签值大小调整为[-1,1]。使用k-fold交叉验证方法来评估semi emotion的性能,首先,将整个数据集随机划分为5个子集。然后,一个子集用作测试集,其余的子集用作训练集。5对测试集和训练集是通过不同的子集生成的。最后,使用5个
实验的平均值作为最终结果,均方根误差作为实验评估的指标。实验使用tensorflow框架实现semi emotion,并采用了sgd优化器。数据扩充次数k设置为5,超参数α设置为0.5,ωu初始设定为1,50个迭代后衰减为0.5。学习率设置为0.001,每20个迭代后减少1/8,最大迭代数设置为200。为了避免过拟合,获得多样性较好的网络参数,首先使用大规模数据集imagenet对网络进行预训练,然后为了让参数适用于人脸图像,在离散域情绪数据集fer2013上再对预训练的网络进行微调(冻结前一半网络层数的参数,则后一半网络层的参数通过反向传播来学习,微调仅在fer2013数据集上迭代50轮)。微调后正式开始网络迭代。最后将实验结果与choi的方法进行对比。表1为afew-va数据集上结果对比,表2为afew-va数据集上交叉验证结果对比。
[0128]
表1
[0129][0130]
表2
[0131][0132]
如表1和表2所示,实验结果证明了本方法,即semi emotion对于连续域情感识别具有较好的识别效果,而且在多次实验中的波动更小,在情绪识别过程中更加稳定。通过引入一个新的三元组损失函数来帮助模型学习数据的相似性。通过增强对中间层特征的感知,这种新的三元组损失函数能够帮助模型更好地编码面部图像以进行情绪识别。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。