1.本发明涉及神经网络、模型融合、神经网络架构搜索领域,特别涉及一种基于可微分架构搜索自动构建贷款风险模型的方法。
背景技术:
2.随着社会的发展,银行以及其他的互联网金融机构都需要根据个人的基本信息确定对其是否放贷。在此过程中,若能较为精准的对个人的贷款风险进行评估,在一定程度上可降低金融机构的坏账率,保证贷款的回收率,从而达到增加企业收益的效果。在当前的用户贷款风险预测模型中,较为常用的方法为机器学习方法,比如,gbdt(gradient boosting decision tree),xgboost、lightgbm、mlp(多层感知机)、lstm等。为进一步提高模型的预测准确率,常采用特征融合以及模型融合的方法。
3.在特征融合方面,主要根据人工智能的专家经验进行,这在一定程度上,增加了专家在构建特征上所花费的时间。而当专家经验不足的情况下,特征的构建反而有可能造成模型的性能崩溃。而在模型融合方面,当前的主要思路如图1所示。从图1中可知,主要划分了两个步骤,第一是基于专家构建的特征充分训练好的基模型,命名为model1(xgboost、lightgbm、mlp),第二是根据每个基模型得到的预测结果,重新构建model2,得到最后的输出预测。在上述两个步骤中,model2的构建必须在model1已经训练完成的情况下进行,model2的模型优化将会较大程度上受到model1的影响,当model1的性能较差的情况下,model2也难以较大程度的提升模型性能。与此同时,model1的性能又较大程度会受到事先构建的特征的影响,因此,若能将特征融合、model1的优化、模型融合(model2)整合在一起进行,将能更大程度的提升用户贷款风险预测模型的性能,提升企业在贷款业务上的利润率并降低了企业的人力成本;
4.当前用户贷款风险预测模型,主要包括三个步骤,第一是根据经验进行特征构建,第二是在融合特征的基础上构建基模型(model1),第二是根据基模型得到的预测结构再构建融合模型(model2)。这三个步骤相互影响,特征构建会影响到基模型的性能,而融合模型又主要以基模型的预测为基准,因此,上述将三个步骤分离进行优化在一定程度上降低了模型的准确率,不利于模型性能的提升。此外,在特征构建以及模型融合上,需要花费专家大量的时间进行调整,增加了企业人力成本。因此,本专利基于可微分的架构搜索方法实现了特征自动化融合、model1和model2同时进行优化,自动化的进行模型融合,以此来达到更大程度的提升用户贷款风险预测模型的性能的目标。
技术实现要素:
5.本发明要解决的技术问题是克服现有技术的缺陷,提供一种基于可微分架构搜索自动构建贷款风险模型的方法,通过引入特征权重因子和模型权重因子,在可微分架构搜索的框架下,能将原本的用户贷款风险模型的三个步骤整合为一个步骤,联合进行优化,可在降低专家成本的前提下,提升模型准确率。
6.本发明提供了如下的技术方案:
7.本发明提供一种基于可微分架构搜索自动构建贷款风险模型的方法,包括以下步骤:
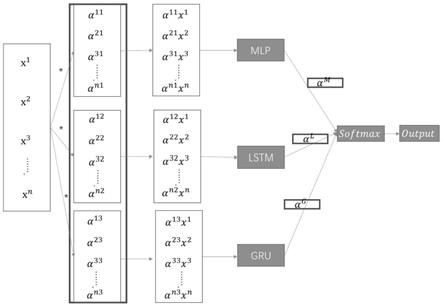
8.一、如图2所示,具体的前向计算流程如下所示:
9.第一,引入特征权重因子,构建基模型新特征;对于用户贷款风险预测模型中,假设有n个特征(x1,x2,x3,
…
xn),为实现针对不同的基模型能相应的进行特征融合,n个特征分别乘以相应的特征权重因子α;例如在mlp的基模型中,将对数据集中原有的n个特征,乘以(α
11
,α
21
,α
31
,
…
α
n1
)得到新的n个特征(x1α
11
,x2α
21
,x3α
31
,
…
xnα
n1
);
10.第二,构建基模型,在每个基模型都得到对应的新特征以后,将会根据新特征构建基模型;
11.第三,引入模型权重因子,进行模型融合;在得到基模型后,将对基模型的输出进行融合,如图2所示,假设得到了三个基模型的输出(output1,output2和output3),三个基模型的模型权重因子分别为αm和α
l
,αg根据可微分架构搜索算法,将对三个权重因子采用softmax函数,限制权重之和为1,最后得到的输出如等式1所示:
[0012][0013]
在以往的模型构建过程中,特征权重因子以及模型权重因子均是人工智能专家根据模型在验证集上的性能逐步进行调整的;因此特征权重因子和模型权重因子主要与模型在验证集上的性能有关;但考虑到验证集的数据是不能参与到模型的训练过程,因此本专利根据基于可微分的架构搜索算法提出将原本的训练集样本按照1:1的比例进行划分,其中一半(train)用于更新三个基模型的权重,另一半(train
′
)用于更新特征权重因子和模型权重因子;根据可微分的架构搜索算法,图2中一次迭代的参数优化过程(反向计算)可如下步骤所示:
[0014]
第一,基模型权重(w)的优化;首先保持特征权重因子和模型权重因子不变,采用事先划分好的一半(train)训练样本训练三个基模型,计算出此时的loss,然后根据此时的loss更新基模型的权重;
[0015]
第二,特征权重因子和模型权重因子的优化,在基模型权重(w)更新完成后,保持基模型的权重不变,将另一半训练样本(train
′
)放入模型中进行计算,得到此时的loss,依据此时的loss更新特征权重因子和模型权重因子;具体更新计算与可微分架构搜索保持一致,如下所示:
[0016]
考虑到原本的特征权重因子和模型权重因子主要依据验证集上的性能进行调整,那么在调整特征权重因子和模型权重因子时,需要假设此时的基模型权重(w)已达到了最优;
[0017]
因此在调整特征权重因子和模型权重因子时,主要满足以下关系式:
[0018]
min
α
l
train
′
(w
*
(α),α);
[0019]
s.t. w
*
(α)=argminwl
train
(w(α),α);
[0020]
由于精准的评估架构梯度计算量较大,因此主要采用以下近似公式来计算梯度:
[0021]
[0022]
根据链式求导法则:
[0023][0024]
其中,在基模型权重(w)优化根据反向传播算法更新基模型的权重w后,即得到了w
′
;
[0025]
由于二阶求导的梯度较为复杂,因此根据导数的定义公式近似计算来进行替换,
[0026][0027]
其中,其中
[0028]
上述两个步骤完成后,模型的迭代完成一次,若设迭代次数为100,则将上述两个步骤迭代进行100次,得到最终的基模型权重、特征权重因子以及模型权重因子。
[0029]
与现有技术相比,本发明的有益效果如下:
[0030]
本发明根据可微分架构搜索方法,引入了特征权重因子和模型权重因子,实现了特征根据基模型自动进行组合以及模型自动融合的功能。将用户贷款风险模型中的三个构建步骤整合为一个步骤,实现了联合优化,这在一定程度上减少了人工智能专家在特征工程以及模型融合调参方面所花费的时间,并能进一步提高模型的准确率,进而提高企业在贷款业务上的利润率。
附图说明
[0031]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
[0032]
图1是本发明的模型融合的基本思路图;
[0033]
图2是本发明的基于可微分架构搜索的多模型自动融合的预测框架图。
具体实施方式
[0034]
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。其中附图中相同的标号全部指的是相同的部件。
[0035]
实施例1
[0036]
如图1-2,本发明提供一种基于可微分架构搜索自动构建贷款风险模型的方法,包括以下步骤:
[0037]
一、如图2所示,具体的前向计算流程如下所示:
[0038]
第一,引入特征权重因子,构建基模型新特征;对于用户贷款风险预测模型中,假设有n个特征(x1,x2,x3,
…
xn),为实现针对不同的基模型能相应的进行特征融合,n个特征
分别乘以相应的特征权重因子α;例如在mlp的基模型中,将对数据集中原有的n个特征,乘以(α
11
,α
21
,α
31
,
…
α
n1
)得到新的n个特征(x1α
11
,x2α
21
,x3α
31
,
…
xnα
n1
);
[0039]
第二,构建基模型,在每个基模型都得到对应的新特征以后,将会根据新特征构建基模型;
[0040]
第三,引入模型权重因子,进行模型融合;在得到基模型后,将对基模型的输出进行融合,如图2所示,假设得到了三个基模型的输出(output1,output2和output3),三个基模型的模型权重因子分别为αm和α
l
,αg根据可微分架构搜索算法,将对三个权重因子采用softmax函数,限制权重之和为1,最后得到的输出如等式1所示:
[0041][0042]
在以往的模型构建过程中,特征权重因子以及模型权重因子均是人工智能专家根据模型在验证集上的性能逐步进行调整的;因此特征权重因子和模型权重因子主要与模型在验证集上的性能有关;但考虑到验证集的数据是不能参与到模型的训练过程,因此本专利根据基于可微分的架构搜索算法提出将原本的训练集样本按照1:1的比例进行划分,其中一半(train)用于更新三个基模型的权重,另一半(train
′
)用于更新特征权重因子和模型权重因子;根据可微分的架构搜索算法,图2中一次迭代的参数优化过程(反向计算)可如下步骤所示:
[0043]
第一,基模型权重(w)的优化;首先保持特征权重因子和模型权重因子不变,采用事先划分好的一半(train)训练样本训练三个基模型,计算出此时的loss,然后根据此时的loss更新基模型的权重;
[0044]
第二,特征权重因子和模型权重因子的优化,在基模型权重(w)更新完成后,保持基模型的权重不变,将另一半训练样本(train
′
)放入模型中进行计算,得到此时的loss,依据此时的loss更新特征权重因子和模型权重因子;具体更新计算与可微分架构搜索保持一致,如下所示:
[0045]
考虑到原本的特征权重因子和模型权重因子主要依据验证集上的性能进行调整,那么在调整特征权重因子和模型权重因子时,需要假设此时的基模型权重(w)已达到了最优;
[0046]
因此在调整特征权重因子和模型权重因子时,主要满足以下关系式:
[0047]
min
α
l
train
′
(w
*
(α),α);
[0048]
s.t.w
*
(α)=argminwl
train
(w(α),α);
[0049]
由于精准的评估架构梯度计算量较大,因此主要采用以下近似公式来计算梯度:
[0050][0051]
根据链式求导法则:
[0052]
[0053]
其中,在基模型权重(w)优化根据反向传播算法更新基模型的权重w后,即得到了w
′
;
[0054]
由于二阶求导的梯度较为复杂,因此根据导数的定义公式近似计算来进行替换,
[0055][0056]
其中,其中
[0057]
上述两个步骤完成后,模型的迭代完成一次,若设迭代次数为100,则将上述两个步骤迭代进行100次,得到最终的基模型权重、特征权重因子以及模型权重因子。
[0058]
进一步的,示例如下:
[0059]
1.确定原始特征数量,比如在用户贷款风险预测模型中,原始存在有15个特征,分别为性别、职业、教育程度、婚姻状态、流水时间戳、交易类型、交易金额、浏览行为数据、账单时间戳、上期账单金额、上期还款金额、本期账单余额、可用余额、预借现金额度、还款状态。标签为是否逾期;
[0060]
2.确定基模型,设置基模型为3,分别为mlp、lstm、gru;
[0061]
3.设置特征权重因子个数和模型权重因子个数,设置特征权重因子参数α个数为45(15*3,其中15为特征个数、3为基模型个数)。设置模型权重因子α参数个数为3,与基模型个数保持一致;
[0062]
4.确定模型训练的相关参数,损失函数采用均方误差,在模型训练时,迭代次数设为100,学习率为0.001,batchsize设置为64。在训练过程中,基模型的权重(w)、特征权重因子和模型权重因子(α)相继交替更新。在模型训练过程中,保留最佳模型;
[0063]
5.测试集最终模型,采用步骤4得到的最佳模型,在测试数据上进行测试。
[0064]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
