1.本发明涉及无人机路径规划领域,特别涉及一种基于电势场和深度强化学习融合的无人机路径规划方法。
背景技术:
2.旋翼无人机可以穿越复杂的环境。在旋翼无人机的导航避障过程中,通常将导航问题分为感知、映射和规划。这会增加处理延迟,现有技术主要存在以下几个方面的问题:
3.1)通常将导航问题分为感知、映射和规划几个步骤顺序处理;即首先需要利用激光雷达深度相机等设备获取周围的环境信息,构建环境地图;在已知地图信息的前提下将点云信息映射为栅格地图;在此基础上计算无碰撞轨迹;这会增加处理延迟,并降低了各个步骤间的关联性。
4.2)面对复杂的三维环境,特别是城市等环境,现有方法需要建立数据量庞大的地图,需要耗费巨大的存储空间;
5.3)强化学习高昂的试错代价,使得在现实环境中进行深度强化学习训练需要大量数据,费时费力,通常在仿真环境下进行训练;
6.4)现实环境结构不确定、光线不稳定、环境动态性高,与仿真环境具有较大差距,路径规划的自适应稳定导航以及从仿真环境到现实环境的迁移是无人机自主导航领域中的难点;
技术实现要素:
7.本发明的目的在于克服现有技术的缺点和不足,提供一种电势场和dqn深度强化学习融合的无人机路径规划方法,能够克服现有技术的缺点和不足,通过端到端的策略直接从激光雷达和和深度相机数据映射到无人机移动,不需要环境地图信息,节约了存储空间,降低了处理延迟,有效解决了无人机路径规划实时性差的问题;并且使数据足够抽象性,使仿真环境到现实环境的具有很高的相似性;
8.为实现上述目的,本发明所采用的技术方案为:
9.一种电势场和深度强化学习融合的无人机路径规划方法,构造dqn深度强化学习算法的状态空间s和动作空间a,建立用于避障的电势场模型,采用电势场模型作为dqn深度强化学习算法中的奖励函数,实现人工势场算法和dqn深度强化学习算法的融合,在仿真环境下进行电势场和dqn深度强化学习融合的无人机路径规划训练,在现实环境下将训练好的权重和参数导入无人机的机载计算机,通过在线训练的方式,输入无人机传感器信息,输出动作指令,机载计算机将动作指令发送给无人机,实现路径规划;具体包括以下步骤:
10.1)构造dqn深度强化学习算法的状态空间s和动作空间a,指定无人机的状态和每个状态下无人机的动作;具体步骤如下:
11.1-1)首先获取无人机飞行时激光雷达的数据,将激光雷达分为n个扇形区间,取每个区间中的距离最小值作为各自区间的最短距离,构成一个n维向量;同时获取深度相机数
据,在竖直平面内均匀获取m个点的深度信息,构成一个m维向量;结合无人机与目标点距离、无人机运动方向与目标点的角度共n m 3维向量,构成状态空间s;
12.1-2)将无人机的动作分为5个,分别是左转、右转、直行、上升和下降,构成动作空间a;
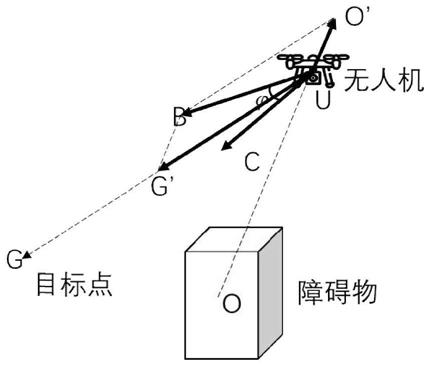
13.2)建立用于避障的电势场模型,以此替代dqn深度强化学习算法的奖励函数,电势场模型设计如下:将无人机在周围环境中的运动,设计成一种在抽象的电场中的运动,将目标点假定为负电荷,无人机和障碍物假定为正电荷,目标点对无人机产生引力,障碍物对无人机产生斥力,最后通过求合力来控制无人机的运动,r1为无人机到目标点的距离,r2为无人机到障碍物的距离,qg为目标点的电荷量,qo为障碍物的电荷量,qu为无人机的电荷量,ka、kb和kc为比例系数,为引力方向与无人机运动方向的夹角,ub为无人机所受到的合力;在实际工作中,目标点对无人机的吸引作用应大于对障碍物的排斥作用,否则有可能会导致无人机为躲避障碍物而无法到达目标点的情况,因此设置qg为qo的两倍,以保证无人机既能避障,又能到达目标点;当无人机向目标点靠近时,引力增大,当无人机靠近障碍物时,斥力增大;
14.根据电势场模型,将dqn深度强化学习算法的奖励函数替换以下三部分:
15.引力奖励函数:
[0016][0017]
其中r
ug'
为引力引起的奖励,ug'为无人机受到的引力,ug为无人机到目标点的向量,|ug|为无人机到目标点的距离,为无人机到目标点方向上的单位向量;
[0018]
斥力奖励函数:
[0019][0020]
其中r
uo'
为斥力引起的奖励,uo'为无人机受到的斥力,uo为无人机到障碍物的向量,|uo|为无人机到障碍物的距离,代表无人机到目标点方向上的单位向量;
[0021]
方向奖励函数:
[0022][0023]
uc为无人机实际受到的力,表示实际运动方向与期望运动方向的夹角;
[0024]
奖励函数即为
[0025][0026]
3)在仿真环境下进行电势场和dqn深度强化学习融合的无人机路径规划训练;具体步骤如下:
[0027]
3-1)构建具有障碍物和目标点的仿真环境,无人机在仿真环境下飞行时,获取步骤2)构建的当前时刻的状态空间s和当前时刻的动作空间a对应的奖励函数r并保存在数据容器中,并且保存在数据容器中的数据能够随着无人机运动而实时更新;
[0028]
3-2)构建深度神经网络,通过上一时刻的状态空间s和动作空间a对应的奖励函数r值,预测当前时刻的状态空间s'和动作空间a'对应的奖励函数r'值,利用预测值与实际值的差值训练深度神经网络,选取奖励函数r值最大的动作空间中的值作为无人机的动作指令;
[0029]
3-3)当无人机靠近障碍物或与障碍物碰撞时,产生的奖励函数r值小,当无人机靠近目标点或到达目标点时,产生的奖励函数r值大,随着训练的进行,无人机的行为将避开障碍物到达目标点,保存此时的深度神经网络的权重和参数;
[0030]
4)在现实环境下将训练好的权重和参数导入无人机的机载计算机,通过在线训练的方式,输入无人机的状态,输出动作指令,机载计算机将动作指令发送给无人机,实现路径规划。
[0031]
在步骤2)中,无人机到障碍物的斥力奖励函数由激光雷达24组数据中均匀采样的8组数值,取平均值得出,方向奖励函数中实际运动方向由无人机惯性测量单元得出,期望运动方向由无人机与目标点的朝向得出。
[0032]
在步骤3-2)中,构建的深度神经网络包含三个全连接层和一个隐藏层,其中输入包含由激光雷达和深度相机数据以及无人机与目标点距离、无人机运动方向与目标点的角度组成的32维向量,输出包含5个动作的奖励函数r值;根据得出的动作值,将速度指令发送给无人机,从而实现无人机的状态更新。
[0033]
在步骤4)中,机载计算机通过串口通信与无人机飞行控制系统连接,实时将深度相机和激光雷达数据作为步骤3-2)中构建的深度神经网络的输入,并通过ros操作系统以固定频率将深度神经网络输出的飞行速度指令发送给无人机飞行控制系统,最终实现无人机实时路径规划。
[0034]
本发明和现有技术相比较,具备如下优点:
[0035]
1、本发明所提出的新型无人机路径规划方法,简化了从感知数据到无人机轨迹的流程,采用深度强化学习的方法,从感知数据直接映射到无人机运动,避免感知、映射、规划的逐步处理过程从而提高了无人机路径规划的稳定性和快速性。
[0036]
2、本发明所提出的新型无人机路径规划方法,不需要获取地图信息,从而大大节省了存储空间。
[0037]
3、本发明获取无人机飞行时激光雷达的数据,将激光雷达分为n个扇形区间,取每个区间中的距离最小值作为各自区间的最短距离,构成一个n维向量。同时获取深度相机数据,在竖直平面内均匀获取m个点的深度信息,构成一个m维向量。结合无人机与目标点距离、无人机运动方向与目标点的角度共n m 3维向量,构成状态空间s。所用数据足够抽象,因此仿真环境和现实环境具有很高的相似性。
[0038]
4、本发明将智能体约束为离散动作,以降低机动性为代价,使算法更易收敛。
[0039]
5、本发明采用电势场与深度强化学习融合的方法,障碍物产生斥力,目标点产生引力,结合进奖励函数,引导无人机无碰撞的到达目标点,使算法快速收敛。
[0040]
6、采用轻量级的网络结构,包含三层全连接层和一层隐藏层,具有很高的实时性。
附图说明
[0041]
图1为本发明实施例所提供的电势场奖励函数原理图。
具体实施方式
[0042]
下面结合附图和具体实施方式,对本发明作进一步详细说明。
[0043]
本发明一种电势场和深度强化学习融合的无人机路径规划方法,构造dqn深度强化学习算法的状态空间s和动作空间a,建立用于避障的电势场模型,采用电势场模型作为dqn深度强化学习算法中的奖励函数,实现人工势场算法和dqn深度强化学习算法的融合,在仿真环境下进行电势场和dqn深度强化学习融合的无人机路径规划训练,在现实环境下将训练好的权重和参数导入无人机的机载计算机,通过在线训练的方式,输入无人机传感器信息,输出动作指令,机载计算机将动作指令发送给无人机,实现路径规划;具体包括以下步骤:
[0044]
1)构造dqn深度强化学习算法的状态空间s和动作空间a,指定无人机的状态和每个状态下无人机的动作;具体步骤如下:
[0045]
1-1)首先获取无人机飞行时激光雷达的数据,将激光雷达分为24个扇形区间,取每个区间中的距离最小值作为各自区间的最短距离,构成一个24维向量;同时获取深度相机数据,在竖直平面内均匀获取5个点的深度信息,构成一个5维向量;结合无人机与目标点距离、无人机运动方向与目标点的角度共32维向量,构成状态空间s;
[0046]
1-2)将无人机的动作分为5个,分别是左转、右转、直行、上升和下降,构成动作空间a;
[0047]
2)建立用于避障的电势场模型,以此替代dqn深度强化学习算法的奖励函数,电势场模型设计如下:将无人机在周围环境中的运动,设计成一种在抽象的电场中的运动,将目标点假定为负电荷,无人机和障碍物假定为正电荷,目标点对无人机产生引力,障碍物对无人机产生斥力,最后通过求合力来控制无人机的运动,如图1所示,u为无人机所在位置,g为目标点所在位置,o为障碍物所在位置,r1为无人机到目标点的距离,r2为无人机到障碍物的距离,qg为目标点的电荷量,qo为障碍物的电荷量,qu为无人机的电荷量,ka、kb和kc为比例系数,为引力方向与无人机运动方向的夹角,ub为无人机所受到的合力;在实际工作中,目标点对无人机的吸引作用应大于对障碍物的排斥作用,否则有可能会导致无人机为躲避障碍物而无法到达目标点的情况,因此设置qg为qo的两倍,以保证无人机既能避障,又能到达目标点;当无人机向目标点靠近时,引力增大,当无人机靠近障碍物时,斥力增大;
[0048]
根据电势场模型,将dqn深度强化学习算法的奖励函数替换以下三部分:
[0049]
引力奖励函数:
[0050][0051]
其中r
ug'
为引力引起的奖励,ug'为无人机受到的引力,ug为无人机到目标点的向量,|ug|为无人机到目标点的距离,为无人机到目标点方向上的单位向量;
[0052]
斥力奖励函数:
[0053][0054]
其中r
uo'
为斥力引起的奖励,uo'为无人机受到的斥力,uo为无人机到障碍物的向量,|uo|为无人机到障碍物的距离,代表无人机到目标点方向上的单位向量,r
uo'
为负值,代表斥力奖励为负;
[0055]
方向奖励函数:
[0056][0057]
uc为无人机实际受到的力,表示实际运动方向与期望运动方向的夹角;
[0058]
奖励函数即为
[0059][0060]
3)在仿真环境下进行电势场和dqn深度强化学习融合的无人机路径规划训练;具体步骤如下:
[0061]
3-1)构建具有障碍物和目标点的仿真环境,无人机在仿真环境下飞行时,获取步骤2)构建的当前时刻的状态空间s和当前时刻的动作空间a对应的奖励函数r并保存在数据容器中,并且保存在数据容器中的数据能够随着无人机运动而实时更新;
[0062]
3-2)构建深度神经网络,通过上一时刻的状态空间s和动作空间a对应的奖励函数r值,预测当前时刻的状态空间s'和动作空间a'对应的奖励函数r'值,利用预测值与实际值的差值训练深度神经网络,选取奖励函数r值最大的动作空间中的值作为无人机的动作指令;
[0063]
3-3)当无人机靠近障碍物或与障碍物碰撞时,产生的奖励函数r值小,当无人机靠近目标点或到达目标点时,产生的奖励函数r值大,随着训练的进行,无人机的行为将避开障碍物到达目标点,保存此时的深度神经网络的权重和参数;
[0064]
4)在现实环境下将训练好的权重和参数导入无人机的机载计算机,通过在线训练的方式,输入无人机的状态,输出动作指令,机载计算机将动作指令发送给无人机,实现路径规划。
[0065]
作为本发明的优选实施方式,在步骤2)中,无人机到障碍物的斥力奖励函数由激光雷达24组数据中均匀采样的8组数值,取平均值得出,方向奖励函数中实际运动方向由无人机惯性测量单元得出,期望运动方向由无人机与目标点的朝向得出。
[0066]
作为本发明的优选实施方式,在步骤3-2)中,构建的深度神经网络包含三个全连接层和一个隐藏层,其中输入包含由激光雷达和深度相机数据以及无人机与目标点距离、无人机运动方向与目标点的角度组成的32维向量,输出包含5个动作的奖励函数r值;根据得出的动作值,将速度指令发送给无人机,从而实现无人机的状态更新。
[0067]
作为本发明的优选实施方式,在步骤4)中,机载计算机通过串口通信与无人机飞行控制系统连接,实时将深度相机和激光雷达数据以及无人机与目标点距离、无人机运动
方向与目标点的角度作为3-2)中所述深度神经网络的输入,并通过ros操作系统以固定频率将深度神经网络输出的飞行速度指令发送给无人机飞行控制系统,最终实现无人机实时路径规划。
[0068]
以上所述实施例只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之流程、原理和深度神经网络结构所作的数量上的变化,均应涵盖在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
