1.本发明关于卷积神经网络加速器,特别是一种在平铺式处理的卷积运算中切割数据进行传递及合并数据的方法。
背景技术:
2.卷积神经网络(convolution neural network,cnn)是目前被认为在电脑视觉及影像处理上最广泛被使用的机器学习技术之一。卷积神经网络的主要运算是卷积核(kernel)与特征图(feature map)之间的卷积,其通过乘积累加(multiply accumulate,mac)运算而消耗大量功率。
3.比起冗余运算的能源浪费,如何提升数据存取能力以及减少数据传输频宽在未来的加速器设计中更加重要。一则因为存储器频宽成长速度慢于处理单元的运算速度,意味着相同的演算法可能受限于存储器及其架构;二则因为目前的神经网络多采用小卷积核配合更深的网络,这样减少了mac运算但增加了存储器用量。据统计,随着神经网络的模型演进,在动态随机存取存储器(dynamic random access memory,dram)上存取特征图所消耗的功率比起其他运算消耗的功率更加可观。
4.目前的cnn通常采用平铺式处理(tiled processing),也就是处理单元每次从外部储存器载入一个区块进行运算。例如:外部储存器dram储存的数据区块未经压缩而直接被载入至靠近处理单元的静态随机存取存储器(static random access memory,sram)作为快取。然而,这种方式在每次切换处理区块时而存取dram时,需要消耗大量的功率并占用大量的存储器频宽。例如:将dram储存的数据切割成多个相同大小的子张量并且压缩,再将压缩后的各个子张量传送至sram解压缩,处理单元从sram提取所需的区块数据进行运算。虽然压缩区块数据可以节省数据传输时消耗的功率及占用的频宽,然而,若子张量切割大小设置过大,可能导致sram储存本次处理时不会使用的数据,造成sram空间的浪费。或者为了取得完整的区块数据,而花费时间解压缩大文件,但其中只有少量数据可用。另一方面,若子张量切割大小设置过小,为了以正确的顺序解压缩还原出完整的区块数据,需要额外占用频宽载入大量的指标以获取每一个压缩文件所属的位置。
技术实现要素:
5.有鉴于此,本发明提出一种有效率且硬件导向的数据存取方案,适用于cnn的特征图。本发明将数据分割为不同大小的子张量(subtensor),并且使用少量的指标,在已压缩但是随机存取的格式下储存这些子张量。这种设计使目前的cnn加速器能够以平铺式处理的方式即时获取和解压缩子张量。本发明适用于需要对齐、合并的数据存取架构,并且只需要对现有架构进行小幅度的修改即可适用于本发明。
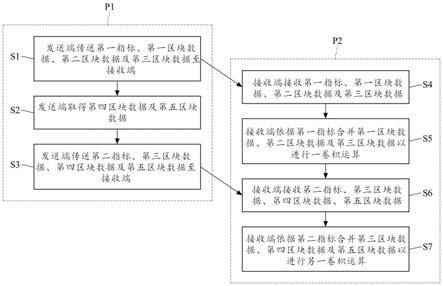
6.依据本发明一实施例的一种数据传递及合并的方法,适用于彼此通讯连接的发送端及接收端,所述方法包括:发送端阶段以及接收端阶段。发送端阶段包含:传送第一区块数据、第二区块数据及第三区块数据至接收端,取得第四区块数据及第五区块数据及传送
第三区块数据、第四区块数据及第五区块数据至接收端。接收端阶段包含接收第一区块数据、第二区块数据及第三区块数据,合并第一区块数据、第二区块数据及第三区块数据以进行一卷积运算,接收第四区块数据、第五区块数据,及合并第三区块数据、第四区块数据及第五区块数据以进行另一卷积运算。
7.综上所述,本发明提出了一种用于输入特征图的有效储存方案,可减少外部储存器的频宽,并且符合现有的cnn加速器架构中的储存器存取模式。给定特定的cnn层和加速器配置,本发明可将张量数据切割为特定大小的多个子张量。现有的cnn加速器可在少量的硬件修改之下整合本发明。以提升整体效能。
8.以上的关于本发明说明书内容的说明及以下的实施方式的说明用以示范与解释本发明的精神与原理,并且提供本发明的专利申请范围更进一步的解释。
附图说明
9.图1是本发明一实施例的数据传递及合并的方法的流程图;
10.图2是特征图在水平方向被切割为多个数据区块的示意图;
11.图3是第一实施例的示意图;
12.图4是输入数据的切割示意图;
13.图5展示了一般卷积采用本发明的一种配置方式的范例;
14.图6展示了扩张卷积采用本发明的另一种配置方式的范例;以及
15.图7示出了在本发明中子张量及指标储存的一种范例。
16.其中,附图标记:
17.p1发送端阶段
18.p2接收端阶段
19.s1~s7步骤
20.a1子张量1的起始地址
21.a5子张量5的起始地址
22.sz1~sz8子张量1~8的数据大小
具体实施方式
23.以下在实施方式中详细叙述本发明的详细特征以及特点,其内容足以使本领域技术人员了解本发明的技术内容并据以实施,且根据本说明书所公开的内容、权利要求书及说明书附图,本领域技术人员可轻易地理解本发明相关的构想及特点。以下的实施例进一步详细说明本发明的观点,但非以任何观点限制本发明的范畴。
24.本发明适用于任何具有卷积运算的领域。在本发明中,提出一种数据传递集合并的方法,其中包含一种输入特征图分割方式,借此避免存取到部分压缩的子张量(subtensor),且最小化子张量的数量以避免数据破碎(data fragmentation)。
25.图1是本发明一实施例的数据传递及合并的方法的流程图。所述的方法适用于通讯连接的发送端及接收端。发送端例如包含外部储存器dram及处理区块数据分割的控制电路,接收端例如为包含运算单元及快取sram的cnn加速器。
26.图2是输入特征图在水平方向被切割为多个数据区块的示意图。假设cnn加速器每
次的运算处理一个输入特征图f,则在第i-1次处理输入特征图f
i-1
,在第i次处理输入特征图fi,且在第i 1次处理输入特征图f
i 1
27.如图1所示,本发明一实施例的数据传递及合并的方法分为发送端阶段p1及接收端阶段p2。发送端阶段p1包含步骤s1、s2及s3。接收端阶段p2包含步骤s4、s5、s6及s7。
28.步骤s1是“发送端传送第一指标、第一区块数据b1、第二区块数据b2及第三区块数据b3至接收端”。步骤s1对应于前述的“在第i次处理输入特征图f
i”。实务上,在发送端传送第一区块数据b1、第二区块数据b2及第三区块数据b3之前,进一步包括以压缩器对第一区块数据b1、第二区块数据b2及第三区块数据b3各自进行压缩,借此减少传输到接收端时占用的频宽。所述的第一指标用于指示第一区块数据b1的起始地址、第一区块数据b1的数据大小、第二区块数据b2的数据大小以及第三区块数据的数据大小。
29.步骤s2是“发送端取得第四区块数据b4及第五区块数据b5”。详言之,发送端的控制电路可按下文述及的配置方式对空间上相邻的连续三个输入特征图f
i-1
、fi及f
i 1
进行分割而得到第一至第五区块数据b1~b5。
30.步骤s3是“发送端传送第二指标、第三区块数据b3、第四区块数据b4及第五区块数据b5至接收端”。步骤s3对应于前述的“在第i 1次处理输入特征图f
i 1”。实务上,在发送端传送第三区块数据b3、第四区块数据b4及第五区块数据b5之前,进一步包括以压缩器对第三区块数据b3、第四区块数据b4及第五区块数据b5各自进行压缩,借此减少传输到接收端时占用的频宽。所述的第二指标用于指示第三区块数据b3的起始地址、第三区块数据b3的数据大小、第四区块数据b4的数据大小以及第五区块数据b5的数据大小。
31.步骤s4是“接收端接收第一指标、第一区块数据、第二区块数据及第三区块数据”。如图1所示,步骤s4在步骤s1完成后执行。
32.步骤s5是“接收端依据第一指标合并第一区块数据、第二区块数据及第三区块数据以进行一卷积运算”。实务上,在进行卷积运算之前,进一步包括以解压缩器解压缩第一区块数据b1、第二区块数据b2及第三区块数据b3。这三个区块数据b1~b3被解压缩完成后被储存在sram,处理单元可依据第一指标取得第一区块数据b1在sram中的第一起始地址,并依据第一起始地址及第一区块数据b1的数据大小计算出第二区块数据b2在sram中的第二起始地址,再依据第二起始地址及第二区块b2的数据大小计算出第三区块数据b3在sram中的第三起始地址。
33.步骤s6是“接收端接收第二指标、第三区块数据、第四区块数据、第五区块数据”。如图1所示,步骤s6在步骤s3完成后执行。
34.步骤s7是“接收端依据第二指标合并第三区块数据、第四区块数据及第五区块数据以进行另一卷积运算”。实务上,在进行卷积运算之前,进一步包括以解压缩器解压缩第三区块数据b3、第四区块数据b4及第五区块数据b5。这三个区块数据b3~b5被解压缩完成后被储存在sram,处理单元可依据第二指标取得第三区块数据b3在sram中的第三起始地址,并依据第三起始地址及第三区块数据b3的数据大小计算出第四区块数据b4在sram中的第四起始地址,再依据第四起始地址及第四区块b4的数据大小计算出第五区块数据b5在sram中的第五起始地址。
35.如图2所示,本发明提出一种切割输入特征图f
i-1
、fi及f
i 1
的方式,以下通过两个实施例进一步详述切割配置的实现方式。第一实施例以实际数字说明本发明的运作方式,
并在第二实施例以代数形式说明本发明一般化的实现方式。
36.图3是第一实施例的示意图。假设cnn架构如下述:卷积核大小为3
×
3且输出特征图大小为8
×
8区块,并采用0填充(zero-padding)以维持输出特征图与输出入特征图大小相同。
37.在第一次处理时,从输入特征图左上角提取10
×
10的输入区块。如图1所示,水平方向的左边界为-1,右边界为9。
38.在第二次处理时,从第一次输入区块右边界的位置向右方步进8个单位以提取下一个输入区块。
39.由于在cnn处理的同一层中,步进长度为常数,因此每次所提取的输入区块的左边界及右边界可组成两个等差数列。左边界以b
l
={-1,7,15,...}表示,右边界以br={9,17,25,...}表示。本发明提出的配置方式即为这两个边界形成的分割。换言之,本发明提出的配置方式为联集g=b
l
∪br,在此范例中,g={1,7}(mod 8)。
40.因为7-1=6(mod 8)且1-7=2(mod8),而且上述的配置方式通用于水平方向及垂直方向的切割,所以每个输入特征图可切分为下列四种形状的子张量:6
×
6、2
×
6、6
×
2及6
×
2。图4是输入数据的切割示意图。
41.10
×
10的输入区块可由一个6
×
6、两个2
×
6、两个6
×
2及四个6
×
2所组成。
42.此外,由于光环(halo)数据的存取只限于二维平面,因此本发明提出的分割配置不需要实现在通道的维度。
43.以下叙述第二实施例。在此实施例中,cnn每一层的运算被一般化,并以下列参数表示:
44.卷积核大小以2k 1表示。因为卷积核大小通常为奇数。
45.跨距以s表示。跨距是各自和两个卷积窗作卷积的两个元素之间的距离。当s>1时,输出特征图大小小于输入特征图大小且计算成本下降。
46.扩张间距以d表示。在扩张卷积(dilated convolution)时,原始卷积核的两个相邻元素按此扩张间距扩张为卷积窗。
47.输出特征图的大小以th×
tw表示。
48.基于上述的参数表示,图5展示了一般卷积采用本发明的一种配置方式(k,s,d,tw)=(1,2,1,6)的范例。
49.当计算输出特征图中最左边的输出元素时,卷积窗从输入特征图最左方开始提取,假设此输入特征图最左方的边界为-k,则最右方的边界为(t
w-1)s k 1。两个相邻子张量之间的偏移量为stw。而本发明定义的配置方式如下:
50.g={-k,(t
w-1)s k 1}(mod stw)
51.={-k,k-s 1} (mod stw)
52.图6展示了扩张卷积采用本发明的另一种配置方式(k,s,d,tw)=(1,1,2,6)的范例。
53.扩张卷积参照上述的运算方式可得出另一配置方式如下:
54.g={-kd,kd-s 1} (mod stw)
55.从本发明上述提出的配置方式中可得知:若n’整除n,则符合(mod n)的配置同样也符合(mod n
′
)。
56.举alexnet conv1为例,其(k,s,tw)=(5,4,8),对应于本发明的一配置g1={27,2} (mod 32)。因此,alexnet conv1也适用于本发明另一配置g2={3,2}(mod 8)。
57.承上所述,在所有的卷积层中选择单一n值可简化硬件实作。在本发明一实施例中,n=8是一个大多数情况适用的设定值。
58.给定本发明的一个切割配置方式所切割出的多个子张量需要被储存在一个数据结构中,并满足存储器对齐的需求,以最大化压缩带来的益处。因为子张量压缩后的大小不同,本发明额外储存用于代表这些子张量的指标。
59.图7展示本发明如何储存子张量以及指标。在设置指标时,对于邻近的子张量,如图7中子张量1、2、3及4,仅使用指标a1指示区块1的起始地址以及使用指标sz1~sz4分别指示这4个子张量各自被压缩后的数据大小。因此,存取这些子张量时分两步骤,首先从指标a1取得起始地址,然后分别从指标sz1~sz8获取每个子张量的大小并累加至起始地址以获得每个子张量的实际偏移量。
60.由于本发明的指标并不需要对应至每一个子张量,因此可以有效地减少指标的总大小。
61.本发明提出的一种硬件导向(hardware-friendly)的数据分割方式,可用于输入特征图的储存、存取和压缩。本发明将输入特征图切割为多个不同大小,借此避免接收端提取到不会用到的子张量而浪费快取空间。本发明只需要少量的指标即可记录每个压缩后的子张量的位置。应用仅需对现有的cnn加速器架构进行微幅修改,因为本发明几乎适用于所有的压缩演算法,并且只需要改变现有的特征图切割方式。本发明可节省大量的存储器传输频宽。
62.综上所述,本发明提出了一种用于稀疏特征图的有效储存方案,可减少外部储存器的频宽,并且符合现代cnn加速器架构中的储存器存取模式。给定特定的cnn层和加速器配置,本发明可将张量数据切割为特定大小的多个子张量。现有的cnn加速器可在少量的硬件修改之下整合本发明。以提升整体效能。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
