1.本发明涉及了无人车与机器人视觉导航技术领域的一种基于激光雷达的目标检测方法,特别是涉及了一种基于点云跨视图特征转换的实时三维目标检测方法。
背景技术:
2.目标检测是指在可感知环境中找到存在的物体并回归出其位置与尺寸信息,是保障无人驾驶、自主机器人等复杂系统能够安全运行的关键技术。卷积神经网络在基于图像的二维目标检测领域中取得了很大的进步,这些深度网络使用2d卷积等操作,提取图片中的高层语义信息,来理解图片的信息,相对于传统方法效果提升显著,迅速成为了目标检测领域的主流方法。但是基于图像的二维目标检测缺乏深度信息,无法直接用于真实场景下的三维感知与导航。为了能够给自主车辆与机器人提供精确的感知信息,三维目标检测应运而生。在三维目标检测中,激光雷达作为常见的距离传感器,采集得到的点云提供了精确的三维信息,为精确的三维目标检测提供了基础。
3.三维目标检测根据输入点云的表示形式和特征提取手段可以分为基于点、基于体素和基于视图的方法。
4.基于点的方法直接以3d点云中的点作为最小单位进行特征提取,通过点云采样,在没有任何量化损失的前提下,充分提取点云本身的3d几何信息特征,并基于点来回归所在的三维框,是最基础的点云3d目标检测算法。比如pointnet和pointnet 设计了点云的基础网络来提取全局和局部的特征。随后point rcnn提出了一套端到端的两阶段点云检测模型,方法首先利用pointnet 对全局点云进行前背景分割,得到所有的前景点云,然后对每一个点的局部特征回归一个三维框,最后通过非极大值抑制得到最后的检测结果。但是由于pointnet 中的特征传递模块需要计算点云中任意两点之间相互的距离,复杂度为o(n2),因此大多数这类算法的实时性比较差,无法得到很好地应用。
5.基于体素的方法通过将点云采样为规则的3d空间,随后像处理2d图像一样利用卷积等操作对其进行特征提取,最后在体素化特征回归三维框。voxelnet提出了一个简洁的框架,主要思路在于将点云量化到一个均匀的3d体素化网格,随后在鸟瞰视图上回归得到三维框。second在此基础上提出了3d稀疏卷积的操作,大大加速了网络的实时性。pv rcnn提出了一个点和体素同时提取特征的两分支骨架网络,利用体素特征和点特征的渐进性融合来得到更加精细化的特征。这些基于体素的三维目标检测算法得益于体素划分算法和3d稀疏卷积,可以高效并且高速地进行准确的三维区域框。但是3d稀疏卷积的落地部署和加速都比较麻烦,对系统的要求较高,应用场景比较受限。
6.基于视图的方法将点云投影到某一个视图(如环视图、鸟瞰图等)上,然后像二维目标检测一样直接利用2d卷积来完成三维框的回归。pixor将激光雷达的三维点云投影成鸟瞰图,并完成鸟瞰图视角下的检测。pointpillars做为体素化方法的延续,利用一个pointnet在每一个体素柱内进行特征提取,将点云表示成为一个鸟瞰视图,并直接在伪鸟瞰特征图上直接进行三维框的回归。基于视图的方法仅利用1d和2d卷积来完成三维目标的
检测,具有很强的实时性优势,但是由于直接将三维点云投影到某一个视图上会丢失压缩维度的信息,因此相对来说精度较低。
技术实现要素:
7.为了解决背景技术中存在的问题,本发明的目的在于通过点云跨视图的特征转换,充分利用多个视图之间的优势,实现场景的三维目标检测,适用于实时采集实时处理的高效感知系统。
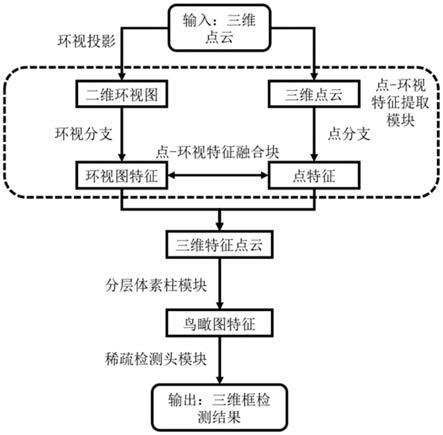
8.本发明提供了一种基于点云跨视图特征转换的实时三维目标检测方法,充分提升了基于视图的方法的检测精度,达到了精度和实时性的完美平衡。首先设计了一个点-环视特征提取模块同时对三维点云和二维环视图进行特征提取并融合,然后提出了一个分层体素柱模块在保留充分的3d信息的条件下将3d特征点云逐步压缩为鸟瞰图特征,最后提出了一个稀疏检测头模块对鸟瞰图特征中有点的有效网格进行分类与回归。本方法搭配结构简单、实时性强的网络结构,在基于视图的方法中达到了最佳水平,完成实时高效的三维目标检测的任务。
9.本发明能有效克服三维目标检测中网络复杂、实时性低、效率低下的问题,利用纯1d和2d卷积组成的骨架网络,对点云进行跨视图的特征提取。使用的网络特征丰富、结构精简、计算代价小、实时性强。
10.本发明采用的技术方案的步骤如下:
11.1)通过激光雷达采集场景的三维点云,对三维点云进行环视投影获得对应的二维环视图;
12.2)建立神经网络结构,利用已知数据集及对应的二维环视图对神经网络结构进行训练,设置总损失函数对神经网络结构进行监督,获得训练好的神经网络结构;
13.3)将待测场景的三维点云和对应的二维环视图输入到训练好的神经网络结构,输出神经网络结构的回归残差和当前待测场景的分类图,基于当前待测场景的分类图和回归残差进行预测三维框的计算,获得最后的预测三维框。
14.所述步骤1)中,建立以俯仰角和朝向角为坐标轴的二维环视图,计算三维点云中各个点与激光雷达坐标系原点的俯仰角和朝向角投影至以俯仰角和朝向角为坐标轴的二维环视图中,获得对应的二维环视图。
15.所述步骤2)中,神经网络结构包括点-环视特征提取模块、分层体素柱模块和稀疏检测头模块;神经网络结构的输入输入到点-环视特征提取模块中,点-环视特征提取模块经分层体素柱模块后与稀疏检测头模块相连,稀疏检测头模块的输出作为神经网络结构的输出。
16.所述点-环视特征提取模块包括环视图分支、点分支和三个点-环视特征融合块,环视图分支通过三个点-环视特征融合块与点分支相连;环视图分支包括六个编码模块和四个解码模块,点分支包括3个1d卷积层;
17.三维点云输入到第一1d卷积层,二维环视图输入到第一编码模块,第一1d卷积层输出的第一点云特征p1和第一编码模块输出的第一环视图特征e1均输入到第一点-环视特征融合块中,第一点-环视特征融合块分别输出更新后的第一点云特征和第一环视图特征,更新后的第一点云特征输入到第二1d卷积层中,更新后的第一环视图特征输入到第二编码
模块,第二编码模块依次经第三编码模块、第四编码模块和第五编码模块后与第六编码模块相连,第二1d卷积层输出的第二点云特征p2和第六编码模块输出的第六环视图特征e6均输入到第二点-环视特征融合块中,第二点-环视特征融合块分别输出更新后的第二点云特征和第六环视图特征,更新后的第二点云特征输入到第三1d卷积层中,更新后的第六环视图特征输入到第一解码模块,第一解码模块依次经第二解码模块和第三解码模块后与第四解码模块相连,第三1d卷积层输出的第三点云特征p3和第四解码模块输出的第十环视图特征d4均输入到第三点-环视特征融合块中,第三点-环视特征融合块分别输出更新后的第三点云特征和第十环视图特征,将更新后的第三点云特征记为3d特征点云并作为点-环视特征提取模块的输出;
18.所述点-环视特征融合块中首先根据点云特征对应的二维环视图,利用双线性插值方法对点云特征各个点进行采样,获得点的2d特征,将输入的环视图特征作为点的3d特征,将点的2d特征和点的3d特征进行级联后输入到依次相连的3个1d卷积层中,最后一个1d卷积层的输出作为更新后的点云特征,将最后一个1d卷积层的输出进行环形反投影后获得更新后的环视图特征。
19.每个编码模块由一个致密残差块和若干个卷积层依次相连构成,每个编码模块的输入输入到当前致密残差块中,最后一个卷积层的输出作为当前编码模块的输出,解码模块由一个致密残差块和若干个反卷积层依次相连构成,每个解码模块的输入输入到当前致密残差块中,最后一个反卷积层的输出作为当前解码模块的输出。
20.所述分层体素柱模块中首先对点-环视特征提取模块输入的3d特征点云进行体素化处理,获得三维点云网格特征;
21.接着将三维点云网格特征依次输入1d和2d卷积层中依次进行高度维提取特征和长宽维提取特征以及通道重整后,获得鸟瞰图特征并输出。
22.稀疏检测头模块包括基于锚框的分类头和回归头;
23.稀疏检测头模块中首先对分层体素柱模块输出的鸟瞰图特征中各个有点网格进行三维锚框铺设,三维锚框的参数由三维锚框所在位置(x,y,z)、检测目标的平均尺寸(w
mean
,l
mean
,h
mean
)以及朝向角组成,每个有点网格有两个朝向角不同的三维锚框;接着根据三维锚框和真实框之间的交并比大小将三维锚框划分为正、负样本;
24.然后基于锚框的分类头中对鸟瞰图特征中各个划分为正、负样本的有点网格是否为前景的可能性进行预测,获得各个有点网格的预测分类概率,基于各个有点网格的预测分类概率获得预测分类概率集合,基于预测分类概率集合获得当前场景的分类图并输出;
25.最后基于锚框的回归头中首先设置三维锚框的预设残差,对当前鸟瞰图特征的前景网格中划分为正、负样本的三维锚框进行锚框参数回归,获得预测框,计算预测框与真实框之间的回归残差并输出。
26.所述的总损失函数包括三维框分类损失函数、三维框回归损失函数和角度分类损失函数,计算公式如下:
[0027][0028]
其中,l表示总损失函数值,l
cls
表示三维框分类损失函数,l
loc
表示三维框回归损
失函数值,l
dir
表示角度分类损失函数值,n
pos
是所有三维锚框中正样本的数量,λ
loc、
λ
cls
、λ
dir
分别为第一、第二、第三损失权重。
[0029]
所述三维框分类损失函数根据预测分类概率集合计算获得,所述三维框回归损失函数基于预设残差和回归残差计算获得,所述角度分类损失函数通过根据回归头输出的预测框的朝向角进行朝向的分类,获得检测目标的前后朝向,基于检测目标的前后朝向计算获得。
[0030]
所述的三维锚框的预设残差由真实框的7个参数与三维锚框对应的7个参数计算获得,具体公式如下:
[0031][0032][0033]
δθ=sin(θ
gt-θa)
[0034]
其中,δx为预设横坐标残差,x
gt
和x
a分
别为真实框和三维锚框的横坐标,δy为预设纵坐标残差,y
gt
和ya分别为真实框和三维锚框的纵坐标,δz为预设竖坐标残差,z
gt
和za分别为真实框和三维锚框的竖坐标,δw为预设框宽残差,w
gt
和wa分别为真实框和三维锚框的框宽,δl为预设框长残差,l
gt
和la分别为真实框和三维锚框的框长,δh为预设框高残差,h
gt
和ha分别为真实框和三维锚框的框高,δθ为预设角度残差,θ
gt
和θa分别为真实框和三维锚框的朝向角,d代表三维锚框的对角长度,满足
[0035]
所述步骤3)中,提取所述当前待测场景的分类图中所有目标置信度大于目标判别阈值的网格并作为检测目标所处位置,根据神经网络结构的回归残差计算检测目标所处位置的预测三维框的参数,计算公式如下:
[0036]
x=xa daδx
′
,y=ya daδy′
,z=za daδz
′
[0037]
w=wae
δw
′
,l=lae
δl
′
,h=hae
δh
′
[0038]
θ=arcsin(θa δθ
′
)
[0039]
其中,δx
′
,δy
′
,δz
′
,δw
′
,δl
′
,δh
′
,δθ
′
分别为回归横坐标残差、回归纵坐标残差、回归竖坐标残差、回归框宽残差、回归框长残差、回归框高残差、回归角度残差;x表示预测三维框的横坐标,xa表示三维锚框的横坐标,y表示预测三维框的纵坐标,ya表示三维锚框的纵坐标,z表示预测三维框的竖坐标,za表示三维锚框的竖坐标,w表示预测三维框的框宽,wa表示三维锚框的框宽,l表示预测三维框的框长,la表示三维锚框的框长,h表示预测三维框的框高,ha表示三维锚框的框高,θ表示预测三维框的朝向角,θa表示三维锚框的朝向角,d代表三维锚框的对角长度,满足
[0040]
本发明对输入的激光雷达点云首先投影得到二维环视图形式,利用点-环视特征提取模块从三维点云形式和二维环视图形式提取特征并融合;然后利用分层体素柱模块将点云特征压缩成为鸟瞰图视图上的特征;最后利用稀疏检测头模块对存在点的有效网格进行三维框的分类与回归,输出当前场景的三维框的位置与姿态。
[0041]
本发明通过探究点云不同视图的优势,从致密的二维环视图视角提取特征,利用
点云视图进行特征传递与压缩,最后在无遮挡且尺度一致的鸟瞰视图下进行检测。特征的表现形式随着点云的视图而不断转换,充分利用点云的不同视图在网络的不同阶段发挥相应的优势,构建了一个跨视图特征提取并转换的框架。
[0042]
本发明的骨架网络均由1d和2d卷积组成,摒弃了复杂的3d卷积。为了学习点云的3d信息获得3d特征,利用分层体素柱的方式在点云特征转换时保留了充分的3d信息。同时在网络的特征提取、稀疏检测头上加速了整体网络。整个方法达到了精度与实时性的平衡与统一,具有很高的应用价值。
[0043]
本发明构建了一种基于点云跨视图特征转换的实时三维目标检测方法。输入激光雷达点云,将三维点云投影得到二维环视图,利用点-环视特征提取模块同时对三维点云和二维环视图提取特征,并利用点-环视特征融合块对两路特征在网络前期、中期、后期进行融合,输出三维特征点云;随后利用分层体素柱模块对三维特征点云进行特征维度的压缩,得到鸟瞰图特征;最后在稀疏检测头模块对有点的网格进行分类与回归,输出场景中的三维框位置与姿态。针对网络结构中参数的学习,设置总损失函数对分类头与回归头进行监督训练。
[0044]
与背景技术相比,本发明具有的有益效果是:
[0045]
(1)本发明能够有效地利用点云在不同视图上的优势,进行了环视图-点云视图-鸟瞰视图的特征转换,设计了一套跨视图特征提取转换的框架,充分提升了基于视图的三维目标检测的精度。
[0046]
(2)本发明设计了一个分层体素化模块,利用2d卷积逐步将3d点云特征转换到鸟瞰图特征。在转换过程中,先在高度维度上提取特征,再在长宽维度进行特征提取。这种渐进式的特征提取方式能够更好的保留了点云的3d位置信息,提升在鸟瞰图下检测的精度。
[0047]
(3)本发明设计了一个稀疏检测头,仅对存在点的有效网格进行分类与回归,可以大大减少检测头的负担。同时可以筛去大部分作为负样本的无点区域,平衡分类头的正负样本比例。
[0048]
(4)本发明均由简单的1d卷积和2d卷积组成来完成三维目标检测,摈弃了繁重的3d卷积,减小了网络模型的容量,提升了方法的效率,达到了领先的实时性水平。
[0049]
综合来说,本发明网络结构实时性强,精度高。网络的所有模块都可以容纳在端到端的卷及网络中,结构简介;点-环视特征提取模块可以有效提取点云的三维位置信息和二维纹理信息,充分挖掘点云的3d信息;分层体素化模块利用1d和2d卷积来完成点云视图到鸟瞰视图的转换,保留了点云的3d信息;稀疏检测头模块仅针对有点区域的有效网格进行分类和回归,减小了网络负担,提升了网络的实时性。本方案适用于室外各类场景,鲁棒性强,精度和实时性都达到了领先水平。
附图说明
[0050]
图1是本发明方法的流程图;
[0051]
图2是本发明方法的神经网络结构;
[0052]
图3是本发明方法的点-环视特征融合块的结构图;
[0053]
图4是本发明方法的分层体素柱模块;
[0054]
图5是本发明方法在kitti 3d object detection数据集验证集上的可视化输出;
[0055]
图6是kitti 3d object detection数据集id=000798的点云鸟瞰图示例。
具体实施方式
[0056]
下面结合附图和实施例对本发明作进一步说明。
[0057]
如图1的流程图所示,按照本发明完整方法实施的实施例及其实施过程如下:
[0058]
以kitti 3d object detection数据集作为已知数据集和三维目标检测为例,来表述基于点云跨视图特征转换的实时三维目标检测方法的思想和具体实施步骤。
[0059]
实施例的激光雷达点云,用于监督的真值三维框均来自kitti 3d object detection已知数据集。
[0060]
利用kitti 3d object detection已知数据集的划分,提供的包含真值三维框的数据共7481例,其中训练集3712例,验证集3769例。训练集、验证集分属于不同场景和序列,相互之间没有交集。训练集和验证集均有真值三维框。对训练集提供的激光雷达点云,执行步骤一到步骤二;
[0061]
本发明包括以下步骤:
[0062]
1)通过激光雷达采集场景的三维点云,对三维点云进行环视投影获得对应的二维环视图;
[0063]
步骤1)中,建立以俯仰角和朝向角为坐标轴的二维环视图,计算三维点云中各个点与激光雷达坐标系原点的俯仰角和朝向角,并投影至以俯仰角和朝向角为像素坐标轴的二维环视图中,获得对应的二维环视图。其中,三维点云中每个点的通道数为5个,包括点云原始坐标(x,y,z)、环视距离r和反射强度i。
[0064]
俯仰角和朝向角的计算公式如下:
[0065][0066]
其中(x,y,z)为激光雷达点云的坐标,(u,v)为点在二维环视图上的像素坐标,h和w是二维环视图的高和宽,在kitti数据集中默认为64线机械式激光雷达,因此俯仰角即竖直方向上有64个通道,并用2048个通道来代表360
°
的朝向角范围,即h=64,w=2048。fov和fov
up
是机械式激光雷达的俯仰视野角和高于水平线的上俯仰角,在kitti数据集中设为fov=28
°
,fov
up
=3
°
。r是每个点距离激光雷达中心的距离。当多个点投影到同一个像素坐标上时,保留更近的那个点。
[0067]
同时,由于kitti数据集中仅标注前视图90
°
范围内的三维框,因此将二维环视图经过裁剪,只保留前视图的范围中512个通道的内容,最后生成64
×
512
×
5的二维环视图。
[0068]
2)建立神经网络结构,利用已知数据集中n
×
4的三维点云及对应的64
×
512
×
5二维环视图对神经网络结构进行训练,设置总损失函数对神经网络结构进行监督,获得训练好的神经网络结构;
[0069]
步骤2)中,神经网络结构包括点-环视特征提取模块、分层体素柱模块和稀疏检测头模块;神经网络结构的输入输入到点-环视特征提取模块中,点-环视特征提取模块经分层体素柱模块后与稀疏检测头模块相连,稀疏检测头模块的输出作为神经网络结构的输
出。
[0070]
如图2所示,点-环视特征提取模块包括环视图分支、点分支和三个点-环视特征融合块,环视图分支通过三个点-环视特征融合块与点分支相连;环视图分支通过由致密残差块组成的2d卷积基础网络对二维环视图进行特征提取;点分支通过简单的1d卷积网络进行特征提取;同时在两个分支之间设立3个点-环视特征融合块在网络的初期、中期、后期进行特征交互,最终输出3d特征点云。
[0071]
环视图分支包括六个编码模块和四个解码模块,由六个编码模块构成环视图分支的编码器,由四个解码模块构成环视图分支的解码器。点分支包括3个1d卷积层;
[0072]
三维点云输入到第一1d卷积层,二维环视图输入到第一编码模块,第一1d卷积层输出的第一点云特征p1和第一编码模块输出的第一环视图特征e1均输入到第一点-环视特征融合块中,第一点-环视特征融合块分别输出更新后的第一点云特征和第一环视图特征,更新后的第一点云特征输入到第二1d卷积层中,更新后的第一环视图特征输入到第二编码模块,第二编码模块依次经第三编码模块、第四编码模块和第五编码模块后与第六编码模块相连,第二1d卷积层输出的第二点云特征p2和第六编码模块输出的第六环视图特征e6均输入到第二点-环视特征融合块中,第二点-环视特征融合块分别输出更新后的第二点云特征和第六环视图特征,更新后的第二点云特征输入到第三1d卷积层中,更新后的第六环视图特征输入到第一解码模块,第一解码模块依次经第二解码模块和第三解码模块后与第四解码模块相连,第三1d卷积层输出的第三点云特征p3和第四解码模块输出的第十环视图特征d4均输入到第三点-环视特征融合块中,第三点-环视特征融合块分别输出更新后的第三点云特征和第十环视图特征,将更新后的第三点云特征记为3d特征点云并作为点-环视特征提取模块的输出。
[0073]
每个编码模块由一个致密残差块和若干个卷积层依次相连构成,每个编码模块的输入输入到当前致密残差块中,最后一个卷积层的输出作为当前编码模块的输出,解码模块由一个致密残差块和若干个反卷积层依次相连构成,每个解码模块的输入输入到当前致密残差块中,最后一个反卷积层的输出作为当前解码模块的输出。
[0074]
如图3所示,点-环视特征融合块中首先根据点云特征对应的二维环视图,利用双线性插值方法对点云特征各个点进行采样,获得点的2d特征,将输入的环视图特征作为点的3d特征,将点的2d特征和点的3d特征进行级联后输入到依次相连的3个1d卷积层中,最后一个1d卷积层的输出作为更新后的点云特征,将最后一个1d卷积层的输出进行环形反投影后获得更新后的环视图特征。环形反投影为步骤1)中环形投影的反过程。
[0075]
编码器首先将输入的二维环视图通过两个步长为1的致密残差块和若干卷积充分提取低维特征得到第一环视图特征e1和第二环视图特征e2,然后通过步长为2的致密残差块和若干卷积逐步下采样到2倍e3、4倍e4、8倍e5、16倍e6的大小,随后解码器用步长为1的致密残差块和双线性插值的方式上采样逐步恢复到原始大小,其特征分别表示为8倍d1、4倍d2、2倍d3和1倍d4。
[0076]
点分支采用简单的1d卷积网络提取点云位置的三维特征。为了更好地进行两者之间的特征融合,设计了3个点-环视特征融合块在网络的前期、中期、后期进行特征交互,分别发生在环视图原始尺寸特征e1、16倍降采样特征e6和解码器原始尺寸特征d4上。
[0077]
点-环视特征提取模块的具体处理过程为:
[0078]
环视图分支:输入五通道的尺寸为h
×w×
5的二维环视图,环视图分支为一个编码器-解码器的结构。编码器部分包括6个致密残差块,其步长分别为(1,1,2,2,2,2)。每个致密残差块后会加入若干个普通卷积来充分提取该尺寸下的特征,数量分别为{3,3,5,5,5,5}前2个致密残差块与对应卷积主要是为了充分提取原始尺寸下的低维特征e1和e2,后4个致密残差块与对应卷积主要用来逐步下采样得到尺度的e3-e6特征图。解码器包括4个致密残差块,其步长分别为(1,1,1,1)。每个致密残差块有一个基于双线性插值的上采样操作,依次将特征提取到h
×
w的特征图。
[0079]
点分支:输入4通道的n
×
4的三维点云,点分支由3个1d卷积的基本网络构成,共使用3次,分别得到不同通道数的p1、p2、p3特征。
[0080]
表1:环视图分支和点分支的网络结构表
[0081][0082]
点-环视特征融合块:输入一张环视图分支中的环视图特征与点分支的一个点云特征,以e1和p1为例。首先对点云特征p1中的每一个点,根据其在环视图上的像素位置,通过双线性插值的方法采样得到其对应的点的2d特征pe1。然后将e1与pe1两者级联,通过3个1d卷积得到更新后的特征。最后将更新后的特征输入到下一个模块中,以及进行投影后输入到下一模块中。更新后的特征在各自的分支中继续进行特征提取。点-环视特征融合块分别在e1和p1、e6和p2、d4和p3之间进行,共使用3次。
[0083]
输出:经过上述环视图分支和点分支,以及其中穿插的点-环视特征融合块,点-环视特征提取模块最后输出n
×
64更新后的第三点云特征。
[0084]
如图4所示,分层体素柱模块中首先通过1d和2d卷积对输入的3d特征点云进行体素化处理,获得三维点云网格特征h
×w×d×
c,具体实施中,根据检测空间的范围,设定体素化的分辨率,将空间分割为h
×w×
d的三维网格;对于3d特征点云中的每一个点,根据空间范围和分辨率计算其的网格化坐标,填充到网格中,得到一个三维点云网格特征h
×w×d×
c。
[0085]
接着将三维点云网格特征h
×w×d×
c依次输入1d和2d卷积层中依次进行高度维提取特征和长宽维提取特征,将3d特征通过1d和2d卷积逐渐压缩为鸟瞰图特征,从而,再经
过通道重整后,获得鸟瞰图特征并输出。
[0086]
高度维特征提取:高度维特征提取由1d卷积组成。对输入的三维点云网格特征h
×w×d×
c,首先进行重排操作,将后面2个维度整合到一起,得到h
×w×
(d
×
c)的特征,然后在最后1个维度上采用1d卷积,输入通道数为(d
×
c),输出通道数为c,得到h
×w×
c的第一鸟瞰图特征。
[0087]
长宽维特征提取:第一鸟瞰图特征输入到2d卷积层中,长宽维特征提取由2d卷积组成,对h
×w×
c的鸟瞰图特征,采用3个步长为1的2d卷积进行特征提取,仍然输出h
×w×
c的第二鸟瞰图特征并作为最终的鸟瞰图特征。具体实施中,在kitti数据集中预设场景范围为x∈[0,69.12],y∈[-39.68,39.68],z∈[-3,1],单位为m,同时预设三个维度的体素分辨率为(0.16,0.16,0.2)。因此三维点云网格特征尺寸为h=496,w=432,d=32,c=64。最后通过分层体素柱模块输出496
×
432
×
64大小的鸟瞰图特征。
[0088]
稀疏检测头模块对鸟瞰图特征中所有网格进行筛选,提取出所有有点的网格,再利用2d卷积以网格为单位分别进行检测框的分类与回归。由于点云的稀疏性,鸟瞰图下大部分网格并无点云存在,因此为了节省计算资源,可以直接对鸟瞰图特征中稀疏的有点网格进行分类与回归。
[0089]
稀疏检测头模块包括基于锚框的分类头和回归头;稀疏检测头模块中首先对鸟瞰图特征中各个有点网格进行三维锚框铺设,三维锚框的参数由三维锚框所在位置(x,y,z)、检测目标的平均尺寸(w
mean
,l
mean
,h
mean
)以及朝向角为0
°
或90
°
组成,由朝向角的个数决定每个网格的三维锚框数,即本实施例中,每个前景网格有两个朝向角不同的三维锚框;接着根据三维锚框和真实框之间的交并比(intersection over union,iou)大小将三维锚框划分为正、负样本;具体实施中,位置中心即网格中心、尺寸为kitti数据集中遍历真值三维框后得到的平均尺寸,对car类来说为w=1.60,l=3.90,h=1.56、朝向角设为0
°
和90
°
,对于车辆这类目标物体,交并比大于0.6为正样本,小于0.45为负样本。分类头执行锚框的置信度分类任务,回归头执行锚框相对于真值框的参数估计任务、利用总损失函数对数据集中每帧激光雷达点云输出的预测三维框计算总损失,训练神经网络结构中的各个参数以最小化总损失达到监督学习的效果。
[0090]
然后基于锚框的分类头中通过3个依次连接的2d卷积层对鸟瞰图特征中各个划分为正、负样本的有点网格是否为前景的可能性进行预测,获得各个有点网格的预测分类概率,基于各个有点网格的预测分类概率获得预测分类概率集合,基于预测分类概率集合获得当前场景的带有三维锚框的分类图并输出;
[0091]
最后基于锚框的回归头中首先设置三维锚框的预设残差,通过3个依次相连的2d卷积层对当前鸟瞰图特征的前景网格中划分为正、负样本的三维锚框进行锚框参数回归,获得预测框,计算预测框与真实框之间的回归残差并输出;即真实框的7个参数与预测框对应的7个参数计算获得,与预设残差的计算公式相似。前景网格是鸟瞰图特征中包含检测目标的有点网格。本实施例中,检测目标为车辆。
[0092]
总损失函数包括三维框分类损失函数、三维框回归损失函数和角度分类损失函数,计算公式如下:
[0093][0094]
其中,l表示总损失函数值,l
cls
表示三维框分类损失函数,l
loc
表示三维框回归损失函数值,l
dir
表示角度分类损失函数值,n
pos
是所有三维锚框中正样本的数量,λ
loc
、λ
cts
、λ
dir
分别为第一、第二、第三损失权重。具体实施中,三个损失权重分别为λ
loc
=2,λ
cls
=1,λ
dir
=0.2。
[0095]
三维框分类损失函数根据预测分类概率集合计算获得,具体实施中,三维框分类损失函数为focal loss损失函数,计算公式如下:
[0096]
l
cls
=-α(1-p)
γ
log(p)
[0097]
其中,l
cls
为有点网格的分类损失函数值,p为当前有点网格的三维锚框的预测分类概率,α为第一超参数,γ为第二超参数,第一超参数α=0.25,第二超参数γ=2。
[0098]
三维框回归损失函数基于预设残差和回归残差计算获得,具体实施中,回归损失函数使用smooth l1 loss损失函数,计算公式为:
[0099][0100]
此外,由于角度θ的回归损失无法分辨车辆的前后朝向,因此加入一个交叉熵分类损失l
dir
来判断角度θ的朝向,帮助网络学习车辆的前后朝向。
[0101]
角度分类损失函数通过根据回归头输出的预测框的朝向角进行朝向的分类,获得检测目标的前后朝向,基于检测目标的前后朝向计算获得,具体实施中,角度分类损失函数使用交叉熵分类损失。
[0102]
通过总损失函数对神经网络结构进行监督,获得训练好的神经网络结构;训练好的神经网络结构的回归残差为回归头输出的回归残差,是唯一确定;而当前待测场景的分类图为分类头输出的分类图,随输入的三维点云和对应的二维环视图而变。
[0103]
三维锚框的预设残差由真实框的7个参数与三维锚框对应的7个参数计算获得,即三维锚框的预设残差包括7个参数的残差,具体公式如下:
[0104][0105][0106]
δθ=sin(θ
gt-θa)
[0107]
其中,δx为预设横坐标残差,x
gt
和xa分别为真实框和三维锚框的横坐标,δy为预设纵坐标残差,y
gt
和ya分别为真实框和三维锚框的纵坐标,δz为预设竖坐标残差,z
gt
和za分别为真实框和三维锚框的竖坐标,δw为预设框宽残差,w
gt
和wa分别为真实框和三维锚框的框宽,δl为预设框长残差,l
gt
和la分别为真实框和三维锚框的框长,δh为预设框高残差,h
gt
和ha分别为真实框和三维锚框的框高,δθ为预设角度残差,θ
gt
和θa分别为真实框和三维锚框的朝向角,d代表三维锚框的对角长度,满足
[0108]
训练过程具体为:用两块nvidia rtx2080ti gpu进行训练,使用adam优化器,动量
为0.85到0.95之间,批大小为12。设置初始学习率为0.001,变化规律符合cyclic策略,训练初期逐渐上升到0.01,然后逐渐下降到0.001
×
10-4
。训练80个轮次后,整个网络已经收敛。
[0109]
3)将验证集中三维点云和对应的二维环视图输入到训练好的神经网络结构,输出神经网络结构的回归残差和当前待测场景的分类图,基于当前待测场景的分类图和回归残差进行预测三维框的计算,获得最后的预测三维框。
[0110]
步骤3)中,提取当前待测场景的分类图中所有目标置信度大于目标判别阈值threshold的网格并作为检测目标所处位置,根据神经网络结构的回归残差计算检测目标所处位置的预测三维框的参数,计算公式如下:
[0111]
x=xa daδx
′
,y=ya daδy
′
,z=za daδz
′
[0112]
w=wae
δw
′
,l=lae
δl
′
,h=hae
δh
′
[0113]
θ=arcsin(θa δθ
′
)
[0114]
其中,δx
′
,δy
′
,δz
′
,δw
′
,δl
′
,δh
′
,δθ
′
分别为回归横坐标残差、回归纵坐标残差、回归竖坐标残差、回归框宽残差、回归框长残差、回归框高残差、回归角度残差;x表示预测三维框的横坐标,xa表示三维锚框的横坐标,y表示预测三维框的纵坐标,ya表示三维锚框的纵坐标,z表示预测三维框的竖坐标,za表示三维锚框的竖坐标,w表示预测三维框的框宽,wa表示三维锚框的框宽,l表示预测三维框的框长,la表示三维锚框的框长,h表示预测三维框的框高,ha表示三维锚框的框高,θ表示预测三维框的朝向角,θa表示三维锚框的朝向角,d代表三维锚框的对角长度,满足
[0115]
在验证集中,测试网络不同模块所带来的精度增益,评价指标为car类检测的平均精度ap,评价依据为三维框交并比3d iou的大小。若预测框与真值框之间的3d iou大于0.7,则认为检测正确。kitti3d目标检测数据集根据真值框样本的检测难度划分为简单easy、中等moderate和困难hard三种程度,并有相应的标注。部分场景的检测结果见图5,可以显示该场景激光雷达点云的三维框检测结果。统计验证集共3769例激光雷达点云的3d检测的平均精度如表2所示。本发明相较于简单的网络结构基线,各个模块加入后都有1%-3%左右的性能提升,最后可以在基准算法的基础上在3d ap指标在easy/moderate/hard难度上分别提升2.36%/3.81%/3.46%的检测精度。
[0116]
表2不同模块对于网络的检测精度3d ap和bev ap的统计实验
[0117][0118]
此外,为了探究点-环视融合模块中环视分支和点分支各自的特征贡献,对两路分支及其特征进行了对比实验,结果如表3所示。可以发现仅使用环视分支特征会比仅使用点分支特征效果更好。主要原因在于环视分支特征不仅包括了点云的3d位置信息,也包括了致密2d纹理信息。当将两个分支的特征同时加入到网络中后,可以发现性能有更进一步的
提升,这也证明了本发明提出的点-环视特征融合块的有效性。
[0119]
表3点-环视特征提取模块的对比实验
[0120][0121]
为了对分层体素柱模块的有效性进行对比实验,将其与传统的体素柱模块进行对比实验,其实验结果如表4所示。可以发现当点0环视特征提取模块中环视分支骨架网络由深度残差块组成时,使用分层体素柱可以在传统体素柱的基础上在moderate困难程度上提升1.30%。当将残差网络块替换为更为强劲的致密残差块时,原始的体素柱方法无法完成相应的精度提升。这说明虽然通过增强骨架网络的方式得到了更具有显著性的特征,但是其无法通过体素柱的方式完成充分的特征传递。而当使用本发明提出的分层体素柱模块时,精度较原始基准情况有明显的3.41%的精度提升。这说明本发明提出的分层体素柱模块更适合作为特征传递和压缩的中间模块,可以更好的保留3d特征,减少由于维度压缩而造成的精度损失。
[0122]
表4分层体素柱模块的对比实验
[0123][0124]
为了对稀疏检测头的有效性进行对比实验,对稀疏检测头的相关情况进行了分析与实验。以kitti 3d object detection数据集中id为
‘
000798’帧激光雷达点云的鸟瞰图为例,其示意图见图6。原始锚框密集铺设的检测头中正负样本为155和321408个,其比例为悬殊的1:2074。而本发明提出的稀疏检测头将其中的无点无效网格筛去后,正负样本变为143和53403个,其比例为1:374。其大大缓解了正负样本不平衡的情况,具体的实验结果见表4所示。如表4所示,稀疏检测头在moderate困难程度的3d ap平均精度上有1.70%的提升,充分展示了稀疏检测头模块的优越性。
[0125]
本发明方法采用两块nvidia rtx2080ti gpu进行训练和测试,利用神经网络结构对输入的激光雷达点云进行三维框的检测,每次检测仅耗时28.1ms,帧率达到36.5hz。所以本发明的计算代价很小,实时性高。
[0126]
可以看出,采用本发明方法能够有效地利用点-环视特征提取模块对三维点云和二维环视图进行特征提取和融合;利用分层体素柱模块将3d特征点云压缩到鸟瞰图特征;利用稀疏检测头对有效网格进行分类与回归。整体网络结构为端到端的结构,利用点云视图的转换来带动特征的转换,充分挖掘点云不同视图的优势,完成高精度三维目标检测的
任务。本发明具有精度高、计算代价小、实时性强等特点,相比于普通的网络结构框架,在精度和实时性都达到了领先水平,在三维目标检测的平均检测上有显著提升,同时保持36.5hz的快速帧率,可以高效地应用于实时的自动驾驶感知系统中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
