1.本发明涉及数据采集领域,特别涉及一种行为大数据自动化采集系统。
背景技术:
2.沟通是人们分享信息、思想和情感的一种方式,也是人与人之间增进感情的一种方法,有效的沟通可以使得人们之间快速高效的进行新型的传递和情感的提示,而无效的沟通则会其他反面的效果。在沟通的过程中,一些人在进行沟通的时候,往往会由于说话声音、语气、语速等原因,使得对方在于其沟通的时候产生不悦的感受,甚至是抵抗的情绪,这样不但会使得沟通的效果不好,时间长了,还会造成亲朋好友疏远的结果,而当事人在面临这一结果的时候,多数是不知道自己的问题所在的,因而没有办法进行更正,从而导致人际关系的进一步破裂,从而造成了由于“不好好说话”而导致的人际交往困难。
技术实现要素:
3.本发明的目的是克服上述现有技术中存在的问题,提供一种行为大数据自动化采集系统,录制沟通时候的语音,并将所录制的语音进行解析得到反馈意见,并将意见反馈给用户,从而提示用户在下次沟通的时候注意自己的问题。
4.为此,本发明提供一种行为大数据自动化采集系统,包括:
5.音频采集模块,用于根据指令采集用户沟通时候的音频,并提取出用户的声音作为用户语音;
6.语音分解模块,用于通过语音转文字技术提取出用户语音对应的语音文字,并统计所述语音文字中的字数;
7.语速获取模块,用于获取所述用户语音的时长,结合所述语音分解模块得到的字数,得到每一个字的语音速度;
8.音调获取模块,用于根据所述用户语音得到语音音频;
9.音量获取模块,用于根据所述用户语音得到语音音量;
10.语气获取模块,用于提取所述语音文字中的情感关键词,并根据所述情感关键词的类别得到语音语气;
11.语音评定模块,用于将所述语音速度、所述语音音频、所述语音音量以及所述语音语气同时作为输入送入训练好的模型中,输出得到评定结果;
12.沟通建议模块,用于根据所述评定结果在建议表中查找所述评定结果对应的建议,并将查找到的建议输出给用户;
13.所述建议表,用于通过列表的形式存储评定结果以及对应的建议。
14.进一步,所述模型在训练的时候,包括如下步骤:
15.在互联网上获取心理学家进行沟通示范的音频和视频,并将视频转化为音频;
16.将每一个音频分别分解为演示音频和建议音频;
17.将每一个所述建议音频转化为所述建议的格式在所述建议表中查找对应的评定
结果;
18.将每一个所述演示音频分别通过所述语速获取模块、所述音调获取模块、所述音量获取模块以及所述语气获取模块得到该音频的语音速度、语音音频、语音音量以及语音语气;
19.将每一个音频对应的语音速度、语音音频、语音音量以及语音语气作为输入,其对应的评定结果作为输出,对所述模型进行训练,得到训练好的所述模型。
20.更进一步,所述建议为文字格式,所述建议表中还用于存储建议关键词,所述关键词从所述建议中提取。
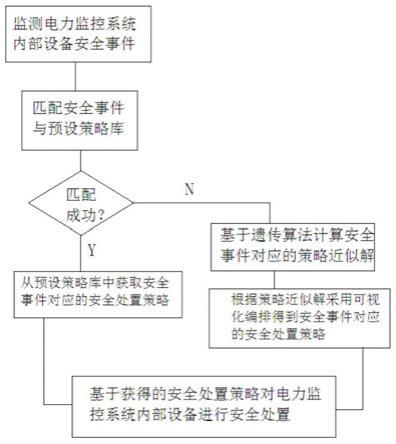
21.更进一步,将每一个所述建议音频转化为所述建议的格式在所述建议表中查找对应的评定结果的时候,包括如下步骤:
22.通过语音文字转化技术将所述建议音频转化为建议文字;
23.提取所述建议文字的内容关键词;
24.计算所述建议文字的内容关键词和所述建议表中每一个建议对应的建议关键词的相似度;
25.将相似度最高的所述建议对应的评定结果输出。
26.进一步,还包括用户提示模块,用于在根据指令采集用户沟通时候的音频之前,通过语音的方式向用户发出提示,所述提示包括前一次的所述建议。
27.更进一步,在提示的时候,包括如下步骤:
28.在所述建议中提取所述建议简要,并将提取的建议简要依次排序;
29.根据建议简要在歌曲库中查找对应的歌曲片段;
30.依次根据顺序将每一个所述建议简要对应的歌曲片段进行拼接,提示歌曲;
31.播放所述提示歌曲。
32.进一步,还包括回放模块,用于将所述用户语音在输出所述建议的时候播放。
33.进一步,所述音频采集模块根据用户的音色提取出用户的声音作为用户语音。
34.本发明提供的一种行为大数据自动化采集系统,具有如下有益效果:
35.本发明通过用户在与他人沟通的时候,将用户的声音进行录制,并从录音中提取出用户声音的音调、语速、语气等参数,并结合这些根据大数据的训练模型进行综合的评定,最后得到评定结果,并给出用户建议,使得用户可以子后续沟通的时候注意,并且经过长时间的练习可以养成习惯,从而提升用户与他人的沟通体验;
36.本发明在与他人沟通之前,通过提示的方式,提示用户注意沟通的语速语气等,在本发明中,通过音乐歌唱的方式对用户进行提示,这样既可以达到提示用户的效果,还不会使得他人产生注意,从而保护用户在训练提升沟通方式的隐私,使得用户在使用的时候感受更加的舒适;
37.本发明还能够将用户沟通时候的声音进行回放,使得用户可以站在他人的角度上感受自己的沟通方式,从而使得用户更加清楚的了解自己的问题。
附图说明
38.图1为本发明的系统连接示意框图;
39.图2为本发明模型在训练时候的流程示意框图;
40.图3为本发明查找对应的评定结果时候的流程示意框图;
41.图4为本发明向用户提示时候的流程示意框图。
具体实施方式
42.下面结合附图,对本发明的一个具体实施方式进行详细描述,但应当理解本发明的保护范围并不受具体实施方式的限制。
43.具体的,如图1-4所示,本发明实施例提供了一种行为大数据自动化采集系统,包括:音频采集模块、语音分解模块、语速获取模块、音调获取模块、音量获取模块、语气获取模块、语音评定模块、沟通建议模块以及建议表。下面是各个功能模块的详细工作介绍。
44.音频采集模块,用于根据指令采集用户沟通时候的音频,并提取出用户的声音作为用户语音;该模块是用户的沟通时候的声音采集的模块,用于提取出用户与他人沟通时候的语音。
45.语音分解模块,用于通过语音转文字技术提取出用户语音对应的语音文字,并统计所述语音文字中的字数;该模块是通过语音转文字的方式得到用户语音中所涉及的文字,通过文本的方式存储,从而为后续的用户沟通时候的特点(语速、音调、音量、语气等)进行铺垫。
46.语速获取模块,用于获取所述用户语音的时长,结合所述语音分解模块得到的字数,得到每一个字的语音速度;该模块是获取用户语音的时长,从而的得到用户的语速,在用户语音的时长越短的时候,用户的语音速度越快。
47.音调获取模块,用于根据所述用户语音得到语音音频;该模块是获取用户语音的音频的,即是俗称的声调的高低,语音音频越高,声调越高。
48.音量获取模块,用于根据所述用户语音得到语音音量;该模块是获取用户语音的语音音量,即是说话声音的大小。
49.语气获取模块,用于提取所述语音文字中的情感关键词,并根据所述情感关键词的类别得到语音语气;该模块通过情感关键词得到用户的说话语气,说话语气是和情感关键词一一对应的。
50.语音评定模块,用于将所述语音速度、所述语音音频、所述语音音量以及所述语音语气同时作为输入送入训练好的模型中,输出得到评定结果;该模块是根据上述已经得到的用户语音的特点对用户的说话方式进行评定,通过学习模型结合正确的经验和方式得到用户说话方式的评定结果,即是所述的评定结果,本发明的评定结果使用编号的方式进行表示。
51.沟通建议模块,用于根据所述评定结果在建议表中查找所述评定结果对应的建议,并将查找到的建议输出给用户;该模块是根据评定结果输出对用户输出建议,建议是文字或者语音或者其他方式的提示方式。
52.所述建议表,用于通过列表的形式存储评定结果以及对应的建议。
53.本发明中,首先对用户与他人通过言语沟通的时候,通过获取用户说话时候的语音,并对用户的用户语音进行读个特点的分析,并根据多个特点结合通过学习模型得到评定的结果,并输出对于用户的建议。
54.本发明通过上述的技术方案,可以使得用户自己得知与他人沟通的时候,他人的
倾听感受,从而对自己的说话方式进行更正,从而达到提升情商的目的。
55.在本发明的实施例中,所述模型在训练的时候,包括如下步骤:
56.(一)在互联网上获取心理学家进行沟通示范的音频和视频,并将视频转化为音频;
57.(二)将每一个音频分别分解为演示音频和建议音频;
58.(三)将每一个所述建议音频转化为所述建议的格式在所述建议表中查找对应的评定结果;
59.(四)将每一个所述演示音频分别通过所述语速获取模块、所述音调获取模块、所述音量获取模块以及所述语气获取模块得到该音频的语音速度、语音音频、语音音量以及语音语气;
60.(五)将每一个音频对应的语音速度、语音音频、语音音量以及语音语气作为输入,其对应的评定结果作为输出,对所述模型进行训练,得到训练好的所述模型。
61.上述步骤(一)至(五)依次进行,通过在互联网上得到专业的音视频的示范以及建议,并分别提取作为输入和输出对本发明的学习模型进行训练,这样就可使得本发明的学习模型具有普适性,后续对于用户的说话的判别非常的准确。
62.本发明结合了互联网大数据,使用多方面的数据对用户的说话进行评估和建议,从而使得评估的时候更加的贴切,给出的建议更加符合用户的实际情况。
63.同时,在本发明的实施例中,所述建议为文字格式,所述建议表中还用于存储建议关键词,所述关键词从所述建议中提取。本发明通过关键词表示建议,这样在查找的时候,只需要扫描关键词,并根据关键词进行匹配,就可以查找到对应的建议,从而提升本发明的运行速度。
64.同时,在本发明的实施例中,将每一个所述建议音频转化为所述建议的格式在所述建议表中查找对应的评定结果的时候,包括如下步骤:
[0065]1·
通过语音文字转化技术将所述建议音频转化为建议文字;
[0066]2·
提取所述建议文字的内容关键词;
[0067]3·
计算所述建议文字的内容关键词和所述建议表中每一个建议对应的建议关键词的相似度;
[0068]4·
将相似度最高的所述建议对应的评定结果输出。
[0069]
上述步骤1至4按照逻辑顺序进行,通过将音频转化为文字,病得到文字的关键字,这样就可以将互联网中的信息根据建议表的格式进行有效的存储,从而使得后续的使用更加的方便。这样的方式也可以使得建议表的数据实施的根据互联网的数据的更新而更新,是一个实时更新的模块。
[0070]
在本发明的实施例中,还包括用户提示模块,用于在根据指令采集用户沟通时候的音频之前,通过语音的方式向用户发出提示,所述提示包括前一次的所述建议。这样就可以使得用户在于其他人沟通交流的时候,通过提示的方式使得用户注意到自己的说话方式,从而进行改变。
[0071]
同时,在本发明的实施例中,在提示的时候,包括如下步骤:
[0072]
1)在所述建议中提取所述建议简要,并将提取的建议简要依次排序;
[0073]
2)根据建议简要在歌曲库中查找对应的歌曲片段;
[0074]
3)依次根据顺序将每一个所述建议简要对应的歌曲片段进行拼接,提示歌曲;
[0075]
4)播放所述提示歌曲。
[0076]
上述步骤1)至4),按照逻辑顺序执行,本发明将建议使用歌曲的方式播放,由于用户对本发明使用,因此知道歌曲的方式表示的含义,以及不同的歌曲片段所表示的提示建议,从而得到对应的建议的提示并在交谈中注意,而对于与用户所交谈的人员,并不知道其表示的含义,只是听了歌曲,从而不会产生对于用户的看法,也不会知道用户的意图。
[0077]
在本发明的实施例中,还包括回放模块,用于将所述用户语音在输出所述建议的时候播放。同时,所述音频采集模块根据用户的音色提取出用户的声音作为用户语音。这样可以使得用户收听自己的在于他人沟通的声音,通过换位思考的方式,反思他人在与自己沟通的时候,他人的感受。
[0078]
以上公开的仅为本发明的几个具体实施例,但是,本发明实施例并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。