1.本发明属于网络应用技术领域,更进一步涉及一种行人重识别生成学习方法,可用于智能安保、智能行人追踪。
背景技术:
2.行人重识别技术在智能安保、智能行人追踪等方面具有广泛的应用。行人重识别常常被认为是图像检索下的子问题,其目的是寻找同一id下的行人在不同摄像头下的一致性信息。在给定一个行人图像输入后,要求在数据库中找到该行人不同摄像头下的图像。由于摄像角度,光照,复杂背景环境等问题,来自于不同摄像头下的行人数据往往具有很大的类内差异性,因此提取出鲁棒于这些类内差异的特征表示是行人重识别的挑战之一。
3.卷积神经网络具有很强的特征提取能力,能够学习到目标在不同摄像头下的深度不变特征。kaiming he等人在其发表的“deep residual learning for image recognition”(2016ieee conference on computer vision and pattern recognition;770-778,2016)论文中提出了残差网络,作为一种通用的卷积神经网络,残差网络的快捷连接分支在线性转换和非线性转换之间寻求到一种平衡,使网络性能远远优于其他网络模型,因此被广泛应用在行人重识别分类中。该方法的实施步骤是:根据数据集包含的行人类别数量修改网络结构的全连接层;初始化网络参数,并对训练集数据进行预测;根据预测结果计算损失函数进行反向传播,更新网络参数,直到训练完毕;在测试阶段,将网络在分类层前所提取的特征作为行人数据的特征表示;根据某种距离度量方法在数据库中进行特征匹配,并返回前几个最相似的行人数据作为结果。该方法所使用模型是数据驱动模型,当训练集中不同类别下数据数量不平衡时,模型学到的特征会带有偏见,从而降低数据较少的类别分类性能,无法满足现实应用需求。
4.yixiao ge等人在其发表的“fd-gan:pose-guided feature distilling gan for robust person re-identification”(proceedings of the 32nd international conference on neural information processing systems;1230-1241,2018)论文中提出了一种基于姿态特征提取的行人重识别生成模型,该方法的实施步骤是:从输入图像中提取图像特征信息和姿态特征信息;生成新的行人数据;将生成数据和原始数据输入到判别器中计算损失函数;使用图像特征信息进行行人重识别。该方法由于对图像特征的提取是通过特征提取器直接从整张图像中提取图像特征,因而生成的效果比较模糊和真实图像有较大的差距。
5.zhedong zheng等人在其发表的“joint discriminative and generative learning for person re-identification”(2019ieee/cvf conference on computer vision and pattern recognition;2133-2142,2019)论文中提出了一种联合生成与判别模型的行人重识别方法,该方法的实施步骤是:从输入图像中提取服装特征信息和结构特诊信息;利用外观特征进行分类;生成新的行人数据;将新生成数据输入到分类器中进行分类。该方法提取的结构特征包含该人物的体态、发型、首饰等类别强相关特征,而服装特征
则只包含服装信息本身。在生成新数据时,通过简单的组合不同行人的服装与结构特征,生成图像的视觉效果更倾向于同一个行人变成了其他人的体态,即保留了其他行人的发型,首饰,身材等不随服装变换的身份特征,而非保留同一个行人的身份特征的同时变换不同服装。这一生成效果是反直觉的,也不是实际期望的,且简单的使用服装特征进行分类也损失了很多类别强相关特征,使得其生成结果难以推广应用到其他行人重识别网络中。
技术实现要素:
6.本发明的目的在于克服上述已有技术的不足,提出一种基于类别激活映射的行人重识别生成学习方法,以生成高质量的预期图像,增强行人重识别网络的性能。
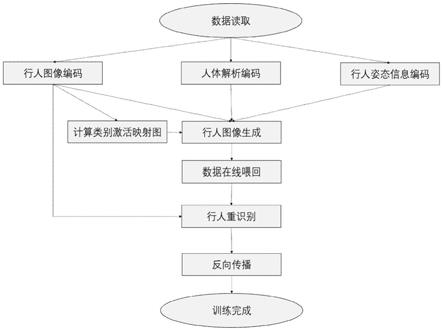
7.本发明的技术思路是:在联合生成与判别学习的框架下,通过将行人特征信息解耦为姿态信息、局部外观信息和全局外观信息,进行行人重识别分类,生成行人在任意姿态下的新图像;通过将新数据在线输入到行人重识别分类网络中,使得行人重识别的数据集达到平衡;通过共享外观信息将生成网络与重识别分类网络联合在一起,保证生成数据更好的支持分类任务;根据分类结果计算类别激活映射图反映出行人图像的判别性信息分布,根据行人图像的判别性信息分布设计损失函数,保证生成数据具有类内多样性,且与其他类别下的行人数据存在类间差异性。
8.根据上述思路,本发明的实现方案包括如下:
9.(1)建立行人重识别生成学习深度网络模型:
10.1a)建立依次由3个卷积层和2个残差块级联组成的姿态编码器e
p
,随机初始化姿态编码器的网络参数;
11.1b)对resnet50神经网络进行改进,建立全局外观编码器e
ag
,即去掉resnet50神经网络最后的池化层和softmax层,构成全局外观编码器e
ag
,分别初始化全局外观编码器e
ag
12.1c)对resnet50神经网络进行改进,建立局部外观编码器e
al
,即去掉resnet50神经网络最后的池化层和softmax层,并增加一个卷积层,构成局部外观编码器e
al
,初始化局部外观编码器e
al
的网络参数;
13.1d)建立依次由2个残差块和3个卷积层级联组成的解码器g,随机初始化网络参数;
14.1e)分别建立依次3个卷积层和3个残差块级联组成的姿态判别器d
p
和外观判别器d
t
,分别随机初始化姿态判别器d
p
和外观判别器d
t
的网络参数;
15.1f)建立由两层全连接层级联和一个softmax函数组成的行人重识别分类器,随机初始化网络参数;
16.(2)从行人重识别基准数据集中任意读取一张图像xi作为源图像,并在与xi同一类别下和不同类别下分别随机读取一张图像xj和x
t
作为两个目标图像;
17.(3)对行人姿态信息编码,获得姿态特征信息:
18.3a)对目标图像xj和x
t
的行姿态关键点进行提取,得到目标姿态关键点pj和p
t
;
19.3b)将目标姿态关键点pj和p
t
输入到1a)的姿态编码器中进行行人姿态信息编码,得到两张目标图像的姿态特征信息和
20.(4)获取全局的外观特征信息和局部的外观特征信息:
21.4a)将源图像xi输入到全局外观编码器e
ag
中进行行人图像编码,得到行人全局的
外观特征信息
22.4b)利用已有的人体解析网络,将输入的源图像xi分割为8个区域掩模mi,用源图像xi与这8个区域掩模分别相乘,得到源图像xi的8个局部区域其中k∈[1,8];
[0023]
4c)将源图像xi的8个局部区域输入到局部外观编码器e
al
中进行人体解析编码,输出源图像xi的8个局部区域的外观特征将该8个局部区域的外观特征级联,得到行人解析编码后的局部外观特征信息
[0024]
(5)行人重识别:即将源图像xi的全局外观特征输入到行人重识别分类器中,得到源图像xi的分类结果,并计算分类结果的交叉熵损失li;
[0025]
(6)行人图像生成:
[0026]
6a)将源图像xi的全局外观特征信息和局部外观特征信息进行级联,得到整体外观特征信息
[0027]
6b)将整体外观特征信息和第一张目标图像的姿态特征信息同时输入到解码器g中,得到目标图像xj的重建图像x
i,j
;
[0028]
6c)将整体外观特征信息和第二张目标图像的姿态特征信息同时输入到解码器g中,得到具有目标姿态的生成图像x
i,t
;
[0029]
6d)将重建图像x
i,j
分别输入到姿态判别器d
p
和外观判别器d
t
中,得到姿态判别器d
p
对重建图像x
i,j
姿态真实度的判别结果和外观判别器d
t
对重建图像x
i,j
外观真实度的判别结果,分别计算这两个判别器对重建图像判别结果的生成对抗损失l
p
和l
t
;
[0030]
6e)将生成图像x
i,t
分别输入到姿态判别器d
p
和外观判别器d
t
中,得到姿态判别器d
p
对生成图像x
i,t
姿态真实度的判别结果和外观判别器d
t
对生成图像x
i,t
外观真实度的判别结果,分别计算这两个判别器对生成图像判别结果的生成对抗损失l
p
'和l
t
';
[0031]
6f)将目标图像xj和x
t
输入到1b)的全局外观编码器e
ag
中,得到对应的全局外观信息和将该全局外观信息和输入到1f)中的分类器中,得到目标图像xj和x
t
的分类结果;
[0032]
6g)基于6f)的分类结果,通过grad-cam方法,分别计算出目标图像xj和x
t
对应的类别激活映射图的像素值,得到类别激活映射图hj和h
t
;
[0033]
6h)利用与6f)和6g)相同的方式,计算重建图像x
i,j
和生成图像x
i,t
的类别激活映射图h
i,j
和h
i,t
,并计算类别激活映射损失lg;
[0034]
(7)将生成图像x
i,t
重新输入1b)的全局外观编码器e
ag
中,得到生成图像x
i,t
的全局外观特征信息再将该信息输入到1f)的行人重识别分类器中,得到生成图像x
i,t
的分类结果,计算该分类结果的交叉熵损失li';
[0035]
(8)对(5)、6d)、6e)、6h)和(7)中得到的损失进行反向传播,分别更新姿态编码器e
p
、全局外观编码器e
ag
、局部外观编码器e
al
、解码器g、姿态判别器d
p
、外观判别器d
t
中的参数,使得这些损失函数值尽量趋近于零;
[0036]
(9)重复步骤(2)-(8)直到损失函数值趋于稳定,生成高质量的行人图像,完成行人重识别生成学习。
[0037]
本发明与现有技术相比具有以下优点:
[0038]
第一,本发明通过生成同一行人在任意姿态下的图像,大大增加了数据集的多样性,保证行人重识别网络能更好的提取鲁棒于行人的姿态、视角等信息的特征。克服了现有深度学习技术在应用到现实世界中不可避免的数据集不平衡问题,使得本发明能更好的支持行人重识别网络落地应用。
[0039]
第二,本发明通过分别提取全局外观特征信息和局部外观特征信息,使得生成网络中目标行人图像对应的外观特征信息更加丰富,即使得生成器可以生成细节更加真实的行人图像,使得生成图像更容易增强分类网络的准确度,克服了现有技术中难以生成更为逼真的行人数据的问题,使得本发明能够更好的提升网络性能。
[0040]
第二,由于本发明中在行人重识别分类时计算了类别激活特征图,很好的量化了分类网络对图像中行人不同部位的关注程度,因此在设计类别激活映射损失时,能够根据已有分类结果,利用类别激活映射图对生成图像和重建图像加权,即增加关注程度高的部位特征信息对应的权重,降低关注程度低的部分特征信息对应的权重,更具有合理性,克服了现有技术中只使用服装特征信息进行生成和分类,损失了部分类别强相关信息,难以生成预期效果的行人图像的问题,使得本发明具有更好的推广性。
附图说明
[0041]
图1为本发明的实现流程图;
[0042]
图2为本发明的整体网络框架图;
[0043]
图3为用本发明方法进行重建图像的仿真实验效果图;
[0044]
图4为用本发明方法进行生成图像的仿真实验效果图。
具体实施方式
[0045]
下面结合附图对本发明的实施例和效果做进一步描述:
[0046]
参照图1,本实例的实现步骤如下:
[0047]
步骤1,建立行人重识别生成学习深度网络模型。
[0048]
参照图2,本步骤的具体实现如下:
[0049]
1.1)建立姿态编码器e
p
:
[0050]
该姿态编码器依次由3个卷积层和2个残差块级联组成的,随机初始化姿态编码器的网络参数,各层参数均从均值为0,方差为0.02的正态分布中随机采样得到,其中:
[0051]
第一卷积层的输入维度18,输出维度64,卷积核尺寸为7*7;
[0052]
第二卷积层的输入维度64,输出维度128,卷积核尺寸为4*4;
[0053]
第三卷积层的输入维度128,输出维度256,卷积核尺寸为4*4;
[0054]
第一残差块的输入维度均为256,输出维度均为256,卷积核尺寸均为3*3;
[0055]
第二残差块输入维度均为256,输出维度均为256,卷积核尺寸均为3*3。
[0056]
1.2)建立全局外观编码器e
ag
:
[0057]
该全局外观编码器通过对现有resnet50神经网络的改进得到,即去掉resnet50神经网络最后的池化层和softmax层,构成全局外观编码器,分别初始化全局外观编码器,其参数与在大规模自然图像数据集imagenet上预训练的resnet50模型除去掉池化层和全连
接层以外的其它网络参数相同。
[0058]
1.3)建立局部外观编码器e
al
:
[0059]
局部外观编码器e
al
也是通过对现有resnet50神经网络的改进得到,即去掉resnet50神经网络最后的池化层和softmax层,并在其后增加一个卷积层,构成局部外观编码器e
al
,其参数与在大规模自然图像数据集imagenet上预训练的resnet50模型除去掉池化层和全连接层以外的其它网络参数相同,其所增加的卷积层参数从均值为0,方差为0.02的正态分布中随机采样得到,该卷积层输入维度为2048,输出维度为128,卷积核尺寸为1*1。
[0060]
1.4)建立解码器g:
[0061]
该解码器依次由2个残差块和3个卷积层级联组成,随机初始化网络参数,即各层参数均从均值为0,方差为0.02的正态分布中随机采样得到,其中:
[0062]
第1残差块的输入维度256,输出维度256,卷积核尺寸为3*3;
[0063]
第2残差块的参数与第一残差块相同;
[0064]
第1卷积层的输入维度256,输出维度128,卷积核尺寸为5*5;
[0065]
第2卷积层的输入维度128,输出维度64,卷积核尺寸为5*5;
[0066]
第3卷积层的输入维度64,输出维度3,卷积核尺寸为7*7。
[0067]
1.5)建立姿态判别器d
p
和外观判别器d
t
:
[0068]
这两个判别器均由3个卷积层和3个残差块依次级联组成,其网络参数采用kaiming初始化方法,均从均值为0,方差为的正态分布中随机采样得到,n为每一层输入参数的个数,其中:
[0069]
姿态判别器d
p
的结构参数设置如下:
[0070]
第一卷积层的输入维度为21,输出维度64,卷积核尺寸为7*7;
[0071]
第二卷积层的输入维度为64,输出维度为128,卷积核尺寸为3*3;
[0072]
第三卷积层的输入维度为128,输出维度为256,卷积核尺寸为3*3;
[0073]
第一残差块的输入维度为256,输出维度为256,卷积核尺寸为3*3;
[0074]
第二残差块的输入维度为256,输出维度为256,卷积核尺寸为3*3;
[0075]
第三残差块的输入维度为256,输出维度为256,卷积核尺寸为3*3;
[0076]
外观判别器d
t
的结构参数设置如下:
[0077]
第1卷积层的输入维度为6,输出维度为64,卷积核尺寸为7*7;
[0078]
第2卷积层的输入维度为64,输出维度为128,卷积核尺寸为3*3;
[0079]
第3卷积层的输入维度为128,输出维度为256,卷积核尺寸为3*3;
[0080]
第1残差块的输入维度为256,输出维度为256,卷积核尺寸为3*3;
[0081]
第2残差块的输入维度为256,输出维度为256,卷积核尺寸为3*3;
[0082]
第3残差块的输入维度为256,输出维度为256,卷积核尺寸为3*3。
[0083]
1.6)建立行人重识别分类器
[0084]
该行人重识别分类器由两层全连接层级联和一个softmax函数组成,随机初始化网络参数从均值为0,方差为0.02的正态分布中随机采样得到,其中:
[0085]
第一全连接层的输入均为2048维,输出为512维,
[0086]
第二全连接层的输入为512维,输出为751维;
[0087]
所述softmax函数,用于将分类器第二全连接层的输出映射为隶属于每一个类别
的概率,所有类别的概率之和为1,其计算公式如下:
[0088][0089]
其中,z表示第二全连接层输出为751维的向量,zi为z的第i个元素,n代表总类别数量,zc代表z中第c个元素,c∈[1,n]。
[0090]
步骤2,获取目标图像
[0091]
从行人重识别基准数据集中任意读取一张图像xi作为源图像,并在与xi同一类别下和不同类别下分别随机读取一张图像xj和x
t
作为两个目标图像。
[0092]
步骤3,对行人姿态信息编码,获得姿态特征信息。
[0093]
3.1)对两个目标图像xj和x
t
进行姿态关键点提取,得到两个目标姿态关键点pj和p
t
;
[0094]
3.2)将两个目标姿态关键点pj和p
t
分别输入到1.1)构建的姿态编码器中进行行人姿态信息编码,得到两张目标图像的姿态特征信息和f
tp
:
[0095][0096][0097]
其中,e
p
代表姿态编码器。
[0098]
步骤4,获取全局的外观特征信息和局部的外观特征信息。
[0099]
4.1)将源图像xi输入到1.2)建立的全局外观编码器中进行行人图像编码,得到行人全局的外观特征信息
[0100][0101]
其中,e
ag
代表全局外观编码器。
[0102]
4.2)利用已有的人体解析网络,将输入的源图像xi分割为8个区域掩模mi,用源图像xi与这8个区域掩模分别相乘,得到源图像xi的8个局部区域其中k∈[1,8];
[0103]
4.3)将源图像xi的8个局部区域输入到1.3)建立的局部外观编码器e
al
中进行人体解析编码,输出源图像xi的8个局部区域的外观特征其中k∈[1,8]:
[0104][0105]
4.4)将该8个局部区域的外观特征级联,得到行人解析编码后的局部外观特征信息
[0106]
步骤5,对行人重识别。
[0107]
5.1)将源图像xi的全局外观特征输入到1.6)建立的行人重识别分类器中,得到源图像xi的分类结果;
[0108]
5.2)计算源图像xi的分类结果的交叉熵损失li:
[0109]
li=-log(p(yi|xi))
[0110]
其中yi表示源图像xi对应的类别,p(yi|xi)表示分类器对源图像xi的类别的预测结果,交叉熵损失值li表示分类器预测结果与真实结果的差距。
[0111]
步骤6,生成行人图像并计算类别激活映射损失。
[0112]
6.1)将源图像xi的全局外观特征信息和局部外观特征信息进行级联,得到整体外观特征信息
[0113]
6.2)将整体外观特征信息和第一张目标图像的姿态特征信息同时输入到步骤1.4)建立的解码器g中,得到目标图像xj的重建图像x
i,j
:
[0114][0115]
其中g代表解码器;
[0116]
6.3)将整体外观特征信息和第二张目标图像的姿态特征信息同时输入到解码器g中,得到具有目标姿态的生成图像x
i,t
:
[0117][0118]
6.4)将重建图像x
i,j
分别输入到1.5)建立的姿态判别器d
p
和外观判别器d
t
中,分别得到姿态判别器d
p
对重建图像x
i,j
姿态真实度的判别结果,和外观判别器d
t
对重建图像x
i,j
外观真实度的判别结果,计算这两个判别器分别对重建图像判别结果的生成对抗损失l
p
和l
t
:
[0119]
l
p
=logd
p
(pj,xj) log(1-d
p
(pj,x
i,j
))
[0120]
l
t
=logd
t
(xj,xi) log(1-d
t
(x
i,j
,xi))
[0121]
其中:生成对抗损失l
p
是将第一目标图像xj与目标姿态pj作为正样本对,将重建图像x
i,j
与目标姿态pj作为负样本对,输入到姿态编码器d
p
计算得到;
[0122]
生成对抗损失l
t
是将第一目标图像xj与源图像xi作为正样本对,将重建图像x
i,j
与源图像xi作为负样本对,输入到外观编码器d
t
计算得到;
[0123]
6.5)将生成图像x
i,t
分别输入到姿态判别器d
p
和外观判别器d
t
中,得到姿态判别器d
p
对生成图像x
i,t
姿态真实度的判别结果,及外观判别器d
t
对生成图像x
i,t
外观真实度的判别结果,分别计算这两个判别器对生成图像判别结果的生成对抗损失l
p
'和l
t
':
[0124]
l
p
'=logd
p
(p
t
,x
t
) log(1-d
p
(p
t
,x
i,t
))
[0125]
l
t
'=logd
t
(xj,xi) log(1-d
t
(x
i,t
,xi))
[0126]
其中:生成对抗损失l
p’是将第二目标图像x
t
与目标姿态p
t
作为正样本对,生成图像x
i,t
与目标姿态p
t
作为负样本对,输入到姿态编码器d
p
计算得到;
[0127]
生成对抗损失l
t’是将第一目标图像xj与源图像xi作为正样本对,将生成图像x
i,t
与源图像xi作为负样本对,输入到外观编码器d
t
计算得到;
[0128]
6.6)将两个目标图像xj和x
t
输入到1.2)建立的全局外观编码器e
ag
中,得到对应的全局外观信息和将该全局外观信息和输入到1.6)建立的行人重识别分类器中,得到目标图像xj和x
t
的分类结果;
[0129]
6.7)基于6.6)的分类结果,通过grad-cam方法,分别计算出目标图像xj和x
t
对应的类别激活映射图的像素值,得到类别激活映射图hj和h
t
:
[0130]
[0131][0132]
其中,aj代表输入第一目标图像xj时全局外观编码器e
ag
的最后一层残差块的输出,其为一个3d矩阵,代表通道k上的元素;a
t
代表输入第二目标图像x
t
时全局外观编码器e
ag
的最后一层残差块的输出,其为一个3d矩阵,代表通道k上的元素;和计算公式如下:
[0133][0134][0135]
式中,yj代表输入第一目标图像xj时分类器第二全连接层输出结果,是一个1d向量,y
cj
代表yj中第c个元素,代表aj中索引为(k,m,n)的元素;y
t
代表输入第二目标图像x
t
时分类器第二全连接层输出结果,其是一个1d向量;y
ct
代表y
t
中第c个元素,代表a
t
中索引为(k,m,n)的元素;
[0136]
6.8),利用与6.6)和6.7)相同的方式,得到重建图像x
i,j
和生成图像x
i,t
的类别激活映射图h
i,j
和h
i,t
:
[0137][0138][0139]
其中,aj代表输入第一目标图像xj时全局外观编码器e
ag
的最后一层残差块的输出,其为一个3d矩阵,代表通道k上的元素;a
t
代表输入第二目标图像x
t
时全局外观编码器e
ag
的最后一层残差块的输出,其为一个3d矩阵,代表通道k上的元素;和计算公式如下:
[0140][0141][0142]
式中,yj代表输入第一目标图像xj时分类器第二全连接层输出结果,是一个1d向量,y
cj
代表yj中第c个元素,代表aj中索引为(k,m,n)的元素;y
t
代表输入第二目标图像x
t
时分类器第二全连接层输出结果,其是一个1d向量;y
ct
代表y
t
中第c个元素,代表a
t
中索引为(k,m,n)的元素;
[0143]
上述类别激活映射图可以反映出输入图像中对于分类起到重要作用的区域,使用类别激活映射图进行损失函数设计,可以增加关注程度高的部位特征信息对应的权重,降低关注程度低的部分特征信息对应的权重;
[0144]
6.9)计算类别激活映射损失lg:
[0145]
首先,计算类别激活映射图hj与h
i,j
之间的类别激活映射损失lr:
[0146]
lr=||xj·hj-x
i,j
·hi,j
||1;
[0147]
其次,计算类别激活映射图h
t
与h
i,t
之间的类别激活映射损失ld:
[0148][0149]
其中,和分别是x
t
和x
i,t
的全局外观特征;
[0150]
最后,根据上述计算的lr和ld得到类别激活映射损失l
g lg:
[0151]
lg=lr ld。
[0152]
步骤7,对生成图像x
i,t
进行分类,并计算分类结果的交叉熵损失li'。
[0153]
7.1)将生成图像x
i,t
重新输入到1.2)建立的全局外观编码器e
ag
中,得到生成图像x
i,t
的全局外观特征信息再将该信息输入到1.6)构建的行人重识别分类器中,得到生成图像x
i,t
的分类结果;
[0154]
7.2)计算7.1)分类结果的交叉熵损失li':
[0155]
li'=-log(p(yi|x
i,t
))
[0156]
其中,yi表示源图像xi对应的类别,p(yi|x
i,t
)表示分类器对生成图像x
i,t
的类别的预测结果,该交叉熵损失值l
i’表示分类器预测结果与真实结果的差距。
[0157]
步骤8,更新网络参数。
[0158]
8.1)对步骤5得到源图像xi分类结果的交叉熵损失li进行反向传播,使其损失函数值尽量趋近于零,以更新全局外观编码器e
ag
和行人重识别分类器中参数;
[0159]
8.2)将步骤6.4)得到两个判别器分别对重建图像判别结果的生成对抗损失l
p
和l
t
进行反向传播,使其损失函数值尽量趋近于零,以更新局部外观编码器e
al
,全局外观编码器e
ag
,姿态编码器e
p
、解码器g、姿态判别器d
p
及外观判别器d
t
中的参数;
[0160]
8.3)将步骤6.5)得到的两个判别器分别对生成图像判别结果的对抗损失l
p
'和l
t
'进行反向传播,使其损失函数值尽量趋近于零,以更新局部外观编码器e
al
,全局外观编码器e
ag
,姿态编码器e
p
,解码器g,姿态判别器d
p
、外观判别器d
t
中参数;
[0161]
8.4)将步骤6.9)得到类别激活映射损失lg进行反向传播,使其损失函数值尽量趋近于零,以更新全局外观编码器e
ag
中的参数;
[0162]
8.5)将步骤7中得到的交叉损失进行反向传播,使其损失函数值尽量趋近于零,以更新局部外观编码器e
al
、全局外观编码器e
ag
、姿态编码器e
p
及解码器g中的参数。
[0163]
步骤9,重复步骤2到步骤8,直到损失函数值趋于稳定,生成高质量的行人图像,完成行人重识别生成学习。
[0164]
本发明的效果可通过以下仿真实验进一步说明:
[0165]
一、仿真条件
[0166]
本实验所使用的数据集为market-1501行人重识别数据集,它包括由6个摄像头拍摄到的1501个行人,32668个检测到的行人矩形框,每个行人至少由2个摄像头捕获到,并且在一个摄像头中可能具有多张图像。训练集有751人,包含12,936张图像,平均每个人有17.2张训练数据;测试集有750人,包含19,732张图像,平均每个人有26.3张测试数据。
[0167]
本实验通过深度学习库pytorch进行仿真实现,输入的行人图像尺寸为256*128,通过openpose方法进行姿态关键点提取,使用humanparser方法进行人体解析,使用随机梯
度下降方法和adam方法进行参数优化,设置迭代次数为70轮。
[0168]
二、仿真实验内容与结果
[0169]
仿真实验1,在上述条件下用本发明方法对行人图像外观特征与姿态特征解耦,利用同一类别下行人的外观特征信息和姿态特征信息,进行重建图像x
i,j
仿真,结果如图3。其中图3(a)、图3(b)、图3(c)、图3(d)是数据集中四个不同类别下行人重建图像仿真结果。每幅图有5列,以3(a)为例,其第一列代表源图像xi,第二列代表源图像xi的姿态关键点,第三列代表目标图像xj,第四列为目标姿态关键点,第五列为基于源图像xi的外观特征信息和目标图像xj的姿态特征信息得到的重建图像x
i,j
。
[0170]
从图3可以看出,重建图像与目标图像xj在姿态和外观上都与目标图像保持一致。
[0171]
仿真实验2,在上述条件下用本发明方法对行人图像外观特征与姿态特征解耦,利用不同类别下行人的外观特征信息和姿态特征信息,仿真生成图像x
i,t
,结果如图4。其中,图4(a)、4(b)、4(c)、4(d)是数据集中四个不同类别下行人生成图像仿真结果。每幅图有5列,以4(a)为例,其中第一列代表源图像xi,第二列代表源图像xi的姿态关键点,第三列代表目标图像x
t
,第四列为目标姿态关键点,第五列为基于源图像xi的外观特征信息和目标图像xj的姿态特征信息得到的生成图像x
i,t
。
[0172]
由图4可以看出,生成图像x
i,t
与目标图像xj在姿态与目标图像保持一致,与源图像xi在外观上保持一致。
[0173]
仿真实验3,在上述条件下,评估本发明方法中不同模块对于行人重识别分类性能的影响,结果如表1所示。
[0174]
表1本发明方法中使用不同模块的行人重识别性能
[0175][0176]
从表1实验编号1和2可见,在不使用类别激活映射损失的前提下,本发明同时使用局部外观特征信息和全局外观特征信息的策略对行人重识别分类平均分类精度有所提升,此外,从表1实验编号2和3可见,在同时使用局部外观特征信息和全局外观特征信息的前提下,本发明方法所提出的类别激活映射损失同样对行人重识别分类精度有所提升。
[0177]
综上,本发明基于类别激活映射的行人重识别生成学习方法,可以同时完成行人生成和行人重识别分类两个任务,即通过对行人图像的外观和姿态的解耦,可以基于源图像的外观特征信息和目标图像的姿态特征信息,重建数据集中的图像或者生成数据集中原
本不存在的图像,且通过同时使用局部外观特征信息和全局外观特征信息的策略及类别激活映射损失,提升了对行人重识别分类的精度。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。