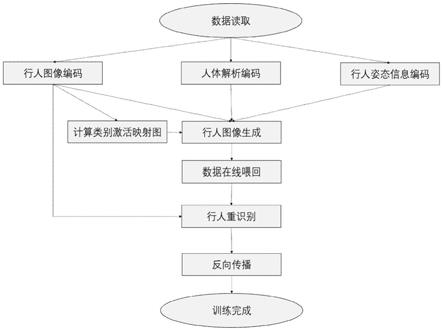
技术特征:
1.一种基于类别激活映射的行人重识别生成学习方法,其特征在于,包括:(1)建立行人重识别生成学习深度网络模型:1a)建立依次由3个卷积层和2个残差块级联组成的姿态编码器e
p
,随机初始化姿态编码器的网络参数;1b)对resnet50神经网络进行改进,建立全局外观编码器e
ag
,即去掉resnet50神经网络最后的池化层和softmax层,构成全局外观编码器e
ag
,初始化全局外观编码器e
ag
的网络参数;1c)对resnet50神经网络进行改进,建立局部外观编码器e
al
,即去掉resnet50神经网络最后的池化层和softmax层,并增加一个卷积层,构成局部外观编码器e
al
,初始化局部外观编码器e
al
的网络参数;1d)建立依次由2个残差块和3个卷积层级联组成的解码器g,随机初始化网络参数;1e)分别建立依次3个卷积层和3个残差块级联组成的姿态判别器d
p
和外观判别器d
t
,分别随机初始化姿态判别器d
p
和外观判别器d
t
的网络参数;1f)建立由两层全连接层级联和一个softmax函数组成的行人重识别分类器,随机初始化网络参数;(2)从行人重识别基准数据集中任意读取一张图像x
i
作为源图像,并在与x
i
同一类别下和不同类别下分别随机读取一张图像x
j
和x
t
作为两个目标图像;(3)对行人姿态信息编码,获得姿态特征信息:3a)对目标图像x
j
和x
t
的行姿态关键点进行提取,得到目标姿态关键点p
j
和p
t
;3b)将目标姿态关键点p
j
和p
t
输入到1a)的姿态编码器中进行行人姿态信息编码,得到两张目标图像的姿态特征信息和f
tp
;(4)获取全局的外观特征信息和局部的外观特征信息:4a)将源图像x
i
输入到全局外观编码器e
ag
中进行行人图像编码,得到行人全局的外观特征信息f
ig
;4b)利用已有的人体解析网络,将输入的源图像x
i
分割为8个区域掩模m
i
,用源图像x
i
与这8个区域掩模分别相乘,得到源图像x
i
的8个局部区域其中k∈[1,8];4c)将源图像x
i
的8个局部区域输入到局部外观编码器e
al
中进行人体解析编码,输出源图像x
i
的8个局部区域的外观特征f
ik
,将该8个局部区域的外观特征级联,得到行人解析编码后的局部外观特征信息f
il
;(5)行人重识别:即将源图像x
i
的全局外观特征f
ig
输入到行人重识别分类器中,得到源图像x
i
的分类结果,并计算分类结果的交叉熵损失l
i
;(6)行人图像生成并计算类别激活映射损失:6a)将源图像x
i
的全局外观特征信息f
ig
和局部外观特征信息f
il
进行级联,得到整体外观特征信息(f
il
,f
ig
);6b)将整体外观特征信息(f
il
,f
ig
)和第一张目标图像的姿态特征信息同时输入到解码器g中,得到目标图像x
j
的重建图像x
i,j
;6c)将整体外观特征信息(f
il
,f
ig
)和第二张目标图像的姿态特征信息f
tp
同时输入到解
码器g中,得到具有目标姿态的生成图像x
i,t
;6d)将重建图像x
i,j
分别输入到姿态判别器d
p
和外观判别器d
t
中,得到姿态判别器d
p
对重建图像x
i,j
姿态真实度的判别结果和外观判别器d
t
对重建图像x
i,j
外观真实度的判别结果,分别计算这两个判别器对重建图像判别结果的生成对抗损失l
p
和l
t
;6e)将生成图像x
i,t
分别输入到姿态判别器d
p
和外观判别器d
t
中,得到姿态判别器d
p
对生成图像x
i,t
姿态真实度的判别结果和外观判别器d
t
对生成图像x
i,t
外观真实度的判别结果,分别计算这两个判别器对生成图像判别结果的生成对抗损失l
p
'和l
t
';6f)将目标图像x
j
和x
t
输入到1b)的全局外观编码器e
ag
中,得到对应的全局外观信息和f
tg
,将该全局外观信息和f
tg
输入到1f)中的分类器中,得到目标图像x
j
和x
t
的分类结果;6g)基于6f)的分类结果,通过grad-cam方法,分别计算出目标图像x
j
和x
t
对应的类别激活映射图的像素值,得到类别激活映射图h
j
和h
t
;6h)利用与6f)和6g)相同的方式,得到重建图像x
i,j
和生成图像x
i,t
的类别激活映射图h
i,j
和h
i,t
,并计算类别激活映射损失l
g
;(7)将生成图像x
i,t
重新输入1b)的全局外观编码器e
ag
中,得到生成图像x
i,t
的全局外观特征信息再将该信息输入到1f)的行人重识别分类器中,得到生成图像x
i,t
的分类结果,计算该分类结果的交叉熵损失l
i
';(8)对(5)、6d)、6e)、6h)和(7)中得到的损失进行反向传播,分别更新姿态编码器e
p
、全局外观编码器e
ag
、局部外观编码器e
al
、解码器g、姿态判别器d
p
、外观判别器d
t
中的参数,使得这些损失函数值尽量趋近于零;(9)重复步骤(2)-(8)直到损失函数值趋于稳定,生成高质量的行人图像,完成行人重识别生成学习。2.根据权利要求1所述的方法,其中1a)中建立的姿态编码器e
p
,其各层参数均从均值为0,方差为0.02的正态分布中随机采样得到,分别设置如下:第一卷积层的输入维度18,输出维度64,卷积核尺寸为7*7;第二卷积层的输入维度64,输出维度128,卷积核尺寸为4*4;第三卷积层的输入维度128,输出维度256,卷积核尺寸为4*4;第一残差块的输入维度均为256,输出维度均为256,卷积核尺寸均为3*3;第二残差块参数与第一残差块相同。3.根据权利要求1所述的方法,其中1b)构建的全局外观编码器e
ag
和局部外观编码器e
al
,其参数分别如下:所述全局外观编码器e
ag
,其参数与在大规模自然图像数据集imagenet上预训练的resnet50模型除去掉池化层和全连接层以外的其它网络参数相同;所述局部外观编码器e
al
,其参数与在大规模自然图像数据集imagenet上预训练的resnet50模型除去掉池化层和全连接层以外的其它网络参数相同;其所增加的卷积层输入维度为2048,输出维度为128,卷积核尺寸为1*1,这些参数从均值为0,方差为0.02的正态分布中随机采样得到。4.根据权利要求1所述的方法,其中1d)建立的解码器g,其各层参数均从均值为0,方差
为0.02的正态分布中随机采样得到,分别设置如下第1残差块的输入维度256,输出维度256,卷积核尺寸为3*3;第2残差块的参数与第一残差块相同;第1卷积层的输入维度256,输出维度128,卷积核尺寸为5*5;第2卷积层的输入维度128,输出维度64,卷积核尺寸为5*5;第3卷积层的输入维度64,输出维度3,卷积核尺寸为7*7。5.根据权利要求1所述的方法,其中1e)中建立的姿态判别器d
p
和外观判别器d
t
,其结构参数如下:姿态判别器d
p
的结构参数:第一卷积层的输入维度为21,输出维度64,卷积核尺寸为7*7;第二卷积层的输入维度为64,输出维度为128,卷积核尺寸为3*3;第三卷积层的输入维度为128,输出维度为256,卷积核尺寸为3*3;第一残差块的输入维度为256,输出维度为256,卷积核尺寸为3*3;第二残差块的输入维度为256,输出维度为256,卷积核尺寸为3*3;第三残差块的输入维度为256,输出维度为256,卷积核尺寸为3*3;外观判别器d
t
的结构参数:第1卷积层的输入维度为6,输出维度为64,卷积核尺寸为7*7;第2卷积层的输入维度为64,输出维度为128,卷积核尺寸为3*3;第3卷积层的输入维度为128,输出维度为256,卷积核尺寸为3*3;第1残差块的输入维度为256,输出维度为256,卷积核尺寸为3*3;第2残差块的输入维度为256,输出维度为256,卷积核尺寸为3*3;第3残差块的输入维度为256,输出维度为256,卷积核尺寸为3*3;上述卷积层和残差块中的参数采用kaiming初始化方法,均从均值为0,方差为的正态分布中随机采样得到,其中n为每一层输入参数的个数。6.根据权利要求1所述的方法,其中1f)建立的行人重识别分类器,其结构参数设置如下:第一全连接层的输入均为2048维,输出为512维,第二全连接层的输入为512维,输出为751维;这两个全连接层的参数均从均值为0,方差为0.02的正态分布中随机采样得到;所述softmax函数,用于将分类器第二全连接层的输出映射为隶属于每一个类别的概率,所有类别的概率之和为1,其计算公式如下:其中,z表示第二全连接层输出为751维的向量,z
i
为z的第i个元素,n代表总类别数量,z
c
代表z中第c个元素,c∈[1,n]。7.根据权利要求1所述的方法,其中,所述(5)中计算源图像x
i
分类结果的交叉熵损失l
i
,和所述(7)中计算生成图像x
i,t
分类结果的交叉熵损失l
i
',公式如下:l
i
=-log(p(y
i
|x
i
))
l
i
'=-log(p(y
i
|x
i,t
))其中,y
i
表示源图像x
i
对应的类别,p(y
i
|x
i
)表示分类器对源图像x
i
的类别的预测结果,p(y
i
|x
i,t
)表示分类器对生成图像x
i,t
的类别的预测结果,交叉熵损失值l
i
和l
i’表示分类器预测结果与真实结果的差距。8.根据权利要求1所述的方法,其中所述6d)和6e)中分别计算姿态判别器d
p
和外观判别器d
t
对重建图像x
i,j
判别结果的生成对抗损失l
p
和l
t
,及对生成图像x
i,t
判别结果的生成对抗损失l
p’和l
t’,实现如下:对于重建图像x
i,j
,通过下式计算两判别器d
p
和d
t
对其判别结果的生成对抗损失l
p
和l
t
:l
p
=logd
p
(p
j
,x
j
) log(1-d
p
(p
j
,x
i,j
))l
t
=logd
t
(x
j
,x
i
) log(1-d
t
(x
i,j
,x
i
))其中,生成对抗损失l
p
是将第一目标图像x
j
与目标姿态p
j
作为正样本对,将重建图像x
i,j
与目标姿态p
j
作为负样本对,输入到姿态编码器d
p
计算得到;生成对抗损失l
t
是将第一目标图像x
j
与源图像x
i
作为正样本对,将重建图像x
i,j
与源图像x
i
作为负样本对,输入到外观编码器d
t
计算得到;对于生成图像x
i,t
,通过下式计算两个判别器对其判别结果的生成对抗损失l
p’和l
t’;l
p
'=logd
p
(p
t
,x
t
) log(1-d
p
(p
t
,x
i,t
))l
t
'=logd
t
(x
j
,x
i
) log(1-d
t
(x
i,t
,x
i
))其中,生成对抗损失l
p’是将第二目标图像x
t
与目标姿态p
t
作为正样本对,生成图像x
i,t
与目标姿态p
t
作为负样本对,输入到姿态编码器d
p
计算得到;生成对抗损失l
t’是将第一目标图像x
j
与源图像x
i
作为正样本对,将生成图像x
i,t
与源图像x
i
作为负样本对,输入到外观编码器d
t
计算得到。9.根据权利要求1所述的方法,其中,所述6g)分别计算出两个目标图像x
j
和x
t
对应的类别激活映射图的像素值,是将两个目标图像x
j
和x
t
分别输入带全局外观编码器e
ag
中,分别计算其类别激活映射图h
j
和h
t
::其中,a
j
代表输入第一目标图像x
j
时全局外观编码器e
ag
的最后一层残差块的输出,其为一个3d矩阵,a
jk
代表通道k上的元素;a
t
代表输入第二目标图像x
t
时全局外观编码器e
ag
的最后一层残差块的输出,其为一个3d矩阵,a
tk
代表通道k上的元素;和计算公式如下:计算公式如下:式中,y
j
代表输入第一目标图像x
j
时分类器第二全连接层输出结果,是一个1d向量,代表y
j
中第c个元素,代表a
j
中索引为(k,m,n)的元素;y
t
代表输入第二目标图像x
t
时
分类器第二全连接层输出结果,其是一个1d向量;y
ct
代表y
t
中第c个元素,代表a
t
中索引为(k,m,n)的元素。10.根据权利要求1所述的方法,其中,所述6h)中计算重建图像x
i,j
和生成图像x
i,t
的类别激活映射图h
i,j
和h
i,t
,及计算类别激活映射损失l
g
,实现如下:6h1)将重建图像x
i,j
和生成图像x
i,t
分别输入带全局外观编码器e
ag
,分别计算重建图像x
i,j
的激活映射图h
i,j
和生成图像x
i,t
的激活映射图h
i,t
::其中,a
i,j
代表输入重建图像x
i,j
时全局外观编码器e
ag
的最后一层残差块的输出,其为一个3d矩阵,a
i,jk
代表通道k上的元素;a
i,t
代表输入生成图像x
i,t
时全局外观编码器e
ag
的最后一层残差块的输出,其为一个3d矩阵,a
i,tk
代表通道k上的元素;和计算公式如下:式中,y
i,j
代表输入重建图像x
i,j
时分类器第二全连接层输出结果,其是一个1d向量;y
ci,j
代表y
i,j
中第c个元素,代表a
i,j
中索引为(k,m,n)的元素;y
i,t
代表输入生成图像x
i,t
时分类器第二全连接层输出结果,其是一个1d向量;y
ci,t
代表y
i,t
中第c个元素,代表a
i,t
中索引为(k,m,n)的元素;6h2),计算类别激活映射损失l
g
:计算类别激活映射图h
j
与h
i,j
之间的类别激活映射损失l
r
:l
r
=||x
j
·
h
j-x
i,j
·
h
i,j
||1计算类别激活映射图h
t
与h
i,t
之间的类别激活映射损失l
d
:其中f
tg
和分别是x
t
和x
i,t
的全局外观特征;根据l
r
和l
d
得到l
g
:l
g
=l
r
l
d
。
技术总结
本发明公开一种基于类别激活映射的行人重识别生成学习方法,主要解决现有技术收集的数据集不平衡导致行人重识别模型性能差的问题。其方案为:建立行人重识别生成学习深度网络模型;1)从行人重识别基准数据集中读取行人图像;2)获取行人姿态特征信息;3)获取行人外观特征信息;4)通过3)进行行人重识别;5)通过2)和3)生成行人图像并计算类别激活映射损失;6)对生成图像在线进行行人重识别分类,并计算分类损失;7)对各损失进行反向传播;8)重复1)-7)更新深度网络模型参数,直到损失函数值趋于稳定,完成行人重识别生成学习。本发明能生成高质量的行人图像,增强行人重识别网络的性能,可用于智能安保、智能行人追踪。智能行人追踪。智能行人追踪。
技术研发人员:毛莎莎 李昂泽 齐梦男 缑水平 焦昶哲 焦李成 何婧洁
受保护的技术使用者:西安电子科技大学
技术研发日:2022.01.13
技术公布日:2022/5/17
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。