1.本发明属于计算机视觉、深度学习等领域,涉及视频定位技术,具体来说是一种基于对比学习的弱监督时序动作定位方法。
背景技术:
2.近年来,随着深度学习的发展,视频理解领域取得了极其显著的突破。时序动作定位作为视频理解领域中的研究热点,在多种现实场景下有很大的应用潜力,例如视频监控,异常检测,视频检索等。其主要任务是从持续时间较长的未剪辑视频中精确定位感兴趣动作发生的开始和结束时间,并对该动作正确分类。目前,时序动作定位大多采用全监督方式训练,关键是要收集足量的逐帧标注的未剪辑视频。然而在现实世界中,逐帧标注海量的视频数据需要消耗大量的人力物力;此外由于动作的抽象性,人为标注动作的时间标签容易引入人的主观因素影响,导致标注信息错误。由此衍生出了基于弱监督学习的时序动作定位,在网络训练过程中仅使用视频级的动作类别标签作为监督信息。与精确的动作时间标签相比,动作类别标签更容易获取,并且能有效避免人工标注引入的偏差。
3.现有的弱监督时序动作定位方法可以分为两种:一种受语义分割技术的启发,将弱监督时序动作定位映射为动作分类问题,并引入动作-背景分离机制构建视频级特征,最终通过动作分类器识别视频。另一种将时序动作定位表述为多示例学习任务,将整条未剪辑视频视为同时包含正样本和负样本的多示例包,其中正样本和负样本分别对应视频中的动作片段和背景片段,通过分类器获取时域类激活序列进而描述动作在时间上的概率分布,并采用top-k池化聚合视频级的类别分数,最后对时域类激活序列设置阈值来定位动作。
4.以上两种方法均通过学习有效的分类损失函数解决未剪辑视频中的定位问题,虽然均能取得一定的效果,但与大多数弱监督学习方法类似,由于缺少时间标签,网络难以建模完整的动作发生过程,会过于关注动作中最显著的部分,而忽略一些特征不明显的次要区域。此外,由于视频没有经过人为剪辑,一个完整的动作中经常会存在镜头转换、动作慢放等模糊帧,它们与动作呈语义相关,属于该动作的一部分,但运动特征并不明显,导致这些时间位置上的激活值较低,与同样激活值较低的显著背景片段难以进行区分,会被错误地检测为背景帧。因此,找到并细化视频中的模糊动作特征,使网络捕获更完整的动作片段,对于提高弱监督时序动作定位性能有着重要意义。
技术实现要素:
5.本发明的目的在于克服现有技术的不足之处,提供一种基于对比学习的弱监督时序动作定位方法。将特征提取网络与动作定位网络分开训练,通过多分支注意力模型分别对视频中的显著动作、模糊动作和显著背景进行建模,并引入模糊动作对比损失函数细化视频特征,使网络感知更加精准的时间边界,有效提高了动作定位精度。
6.本发明为解决其技术问题采用如下技术方案:
7.首先采用预训练的i3d网络提取原始视频的rgb特征和光流特征,并进行级联得到视频特征x,之后将视频特征x送入时域卷积搭建的特征嵌入模型,将其映射到弱监督时序动作定位任务的特征空间,以学习更具表征性的嵌入特征x
in
,可用如下公式表示:
8.x
in
=relu(conv(x,θ
emb
))
9.式中:s为特征维度,θ
emb
为可训练的特征嵌入模型参数,relu为激活函数。之后在动作定位网络中设计了两条支路,分别为分类支路和注意力支路。
10.在分类支路中,通过时域卷积构建分类模型,将嵌入视频特征x
in
映射到动作类别特征空间获取原始时域类激活序列表示动作在时间上的概率分布,其中c为动作类别数,第c 1个维度对应背景类别。该过程可以表示为:
11.f=conv(x
in
,θ
cls
)
12.式中,θ
cls
为可训练的分类模型参数。为了使网络能够分离显著背景片段和显著动作片段并检测到视频中的模糊动作片段,本发明基于时域卷积设计了一个具有三条分支的注意力模型分别对显著动作、显著背景和模糊动作进行建模。该模型的输出为注意力权重其中a
act
,a
amb
和a
bkd
分别对应显著动作、模糊动作和显著背景在时间上的概率分布。具体过程如下:
13.att=softmax(conv(x
in
,θ
att
))
14.式中,θ
att
为可训练的注意力模型参数。为了分辨视频特征中的显著动作、模糊动作和显著背景,基于上述三个注意力权重和原始时域类激活序列f,构建了相应的时域类激活序列cas
act
、cas
amb
和cas
bkd
。其中,可用公式表示为:
15.cas
act
=a
act
*f
16.同理,可以分别得到用于描述模糊动作和显著背景的和
17.为了评估每个时域类激活序列的损失,本发明通过top-k池化聚合视频段的类激活值以获取视频级动作类别分数,以f为例,用公式表示为:
[0018][0019]
式中:l∈{1,2,...,t},|l|=k=max(1,t//r),r为预设定参数。最后在类别维度施加softmax函数获取视频级动作类别分数,采用交叉熵函数计算分类损失:
[0020][0021][0022]
式中:j=1,2,...,c 1,为视频包含动作j的概率,为原始时域类激活序列的分类损失函数。同理,基于时域类激活序列cas
act
、cas
amb
和cas
bkd
,可以得到相应的分类损
失函数和
[0023]
其中显著动作时域类激活序列cas
act
的损失函数为:
[0024][0025]
式中:k
act
=max(1,t//r
act
),r
act
为预设定参数;
[0026]
其中模糊动作时域类激活序列cas
amb
的损失函数为:
[0027][0028]
式中:k
′
amb
=max(1,t//r
′
amb
),r
′
amb
为预设定参数;
[0029]
其中显著背景时域类激活序列cas
bkd
的损失函数为:
[0030][0031]
式中:k
bkd
=max(1,t//r
bkd
),r
bkd
为预设定参数。
[0032]
上述过程难以在复杂的未剪辑视频中直接定位模糊动作片段。为此,本发明设计了模糊动作对比损失函数细化视频特征。首先,根据显著动作注意力a
act
,以top-k池化在嵌入特征x
in
上获取显著动作特征
[0033][0034]
式中:k
act
=max(1,t//r
act
)为超参数,r
act
为预设定参数,控制显著动作特征的采样率。topk(k,*)为截取*中k个最大值的时间索引。同理可以获取显著背景特征
[0035][0036]
式中参数与x
act
的参数类似。由于注意力权重a
amb
同时关注显著动作和模糊动作,难以直接获取模糊动作特征,而显著动作权重稍大于模糊动作权重。因此,在a
amb
中首先去除显著动作特征和显著背景特征对应的时间索引。用公式表示如下:
[0037][0038]
之后采用与之前类似的top-k池化获取模糊动作特征
[0039]
[0040]
式中参数与x
act
的参数类似。最后,将infonce损失函数应用于视频段级别上,计算模糊动作对比损失,细化模糊动作特征。假设选取模糊动作特征显著动作特征和显著背景特征引入infonce损失函数中:
[0041][0042]
式中:式中:τ为温度常数,x
act
~x
act
,topk(k,*)为截取*中k个最大值的时间索引;(k,*)为截取*中k个最大值的时间索引;(k,*)为截取*中k个最大值的时间索引;k
amb
=max(1,t//r
amb
),r
amb
为预设定参数,用于控制模糊特征采样率。k
bkd
为超参数,用于控制显著背景特征x
bkd
的时间维度大小,τ=0.07为温度常数。除了上述损失函数,还引入了l1损失函数保证显著动作注意力权重a
act
的稀疏性:
[0043][0044]
最后将各项损失函数结合,计算总损失函数l
total
,并通过优化训练使网络达到收敛
[0045][0046]
其中,α和β为相应的损失系数。
[0047]
在测试阶段cas
act
能够更准确地建模动作分布情况,因此通过cas
act
获取视频级的类别分数p
act
,并设定阈值θ
cls
,在p
act
中筛选出高于θ
cls
的动作类别c
act
。之后对cas
act
,在类别c
act
对应的维度上采用多阈值分割策略获取大量动作提名。对于某个动作提名(ts,te,c
act
),通过如下公式计算其置信分数
[0048][0049][0050][0051]
其中,ts和te分别为动作的开始和结束时间,li=(t
e-ts)/4,μ为预设定参数。最后采用非极大值抑制算法去除冗余提名,以获得最终的动作定位结果。
[0052]
本发明的优点和有益效果如下:
[0053]
1、本发明提出了一种基于对比学习的弱监督时序动作定位方法。训练过程中仅使用视频级别的动作类别标签作为监督信息,不需要人为标注动作的时间标签,大大缓解了人力物力的消耗。
[0054]
2、本发明通过多分支注意力模型分别对视频中的显著动作、模糊动作和显著背景进行建模,能够有效地分离视频中的动作特征和背景特征,使得动作定位精度在不同的数据集上有显著提升。
[0055]
3、本发明设计了模糊动作对比损失函数,能够在显著特征的引导下细化视频特征,使网络感知更加精准的时间边界,避免动作定位结果被截断,有效提高了动作定位精度。
[0056]
4、本发明在动作定位网络中没有引入循环神经网络就可获得与当前主流的动作定位模型相比更好的结果,克服了循环神经网络容易发生梯度消失的缺点,减小了网络的计算量,加快了网络的训练速度。
附图说明
[0057]
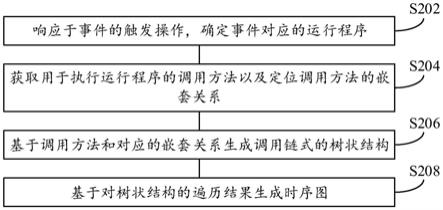
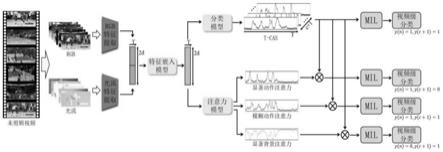
图1为本发明的一种基于对比学习的弱监督时序动作定位方法的网络结构。
[0058]
图2为本发明实施例可视化结果展示图。
具体实施方式
[0059]
下面结合附图并通过具体实施例对本发明作进一步详述,以下实施例只是描述性的,不是限定性的,不能以此限定本发明的保护范围。
[0060]
本发明为基于对比学习的弱监督时序动作定位方法,采用特征提取网络和动作定位网络分阶段的训练方式,通过引入多分支注意力模型对视频中的显著动作、模糊动作和显著背景进行建模,有效地分离视频中的动作特征和背景特征,并引入模糊动作对比损失函数,在显著特征的引导下细化视频特征,使网络感知更加精准的时间边界,避免动作定位结果被截断,有效提高了动作定位精度。
[0061]
图1为本发明基于对比学习的弱监督时序动作定位方法的网络结构。
[0062]
本发明整体架构主要由两个网络组成,包含特征提取网络和动作定位网络。
[0063]
其中特征提取网络采用kinetics数据集上预训练的i3d网络作为主体部分。该网络以3d inception模型为主干,其间穿插了4个时间步长为2的池化层,用于控制网络的参数量,能够在融合时序特征的同时合理地控制感受野的大小,防止细节信息的丢失。动作定位网络由特征嵌入模型、分类模型和多分支注意力模型组成,三个网络均采用时域卷积网络搭建,以便更好地捕捉视频的时序特征。
[0064]
本发明采用的数据集为thumos-14数据集和activitynet-1.2数据集。thumos-14数据集总共包含20类动作,每条视频平均包含15.4个动作片段,所有数据均从youtube网站获取。视频长度从几十秒钟到几十分钟变化不等,对于弱监督时序动作定位任务是挑战性较大的一个数据集。与之前的主流算法划分数据集的方法相同,本发明采用其中具有时间标注的200条验证视频作为训练集,213条测试视频作为测试集。activitynet-1.2为大型时序动作定位数据集。总共包含100类动作,训练集包含4819条视频,测试集包含2382条视频。平均每条视频包含1.5个动作片段和36%的背景,相比于thumos-14数据集,动作片段所占比例明显减少。
[0065]
首先对于未剪辑视频每16帧作为一视频段进行连续分割,得到t个视频块,送入预训练的特征提取网络提取rgb特征和光流特征,进行级联得到视频特征x,特征提取网络不参与后续的弱监督训练。之后将视频特征x送入时域卷积搭建的特征嵌入模型,将其映射到弱监督时序动作定位任务的特征空间,以学习更具表征性的嵌入特征s为特征维度,t为特征维度。
[0066]
接下来,需要利用嵌入特征x
in
获取用于定位动作的时域类激活序列。为此,本发明在动作定位网络中设计了两条支路,分别为分类支路和注意力支路。
[0067]
在分类支路中,通过时域卷积构建分类模型,将嵌入视频特征x
in
映射到动作类别
特征空间获取原始时域类激活序列表示动作在时间上的概率分布,其中c为动作类别数,第c 1个维度对应背景类别。
[0068]
然而,仅仅利用原始时域类激活序列f,网络难以分离视频中的显著动作和显著背景。为了使网络能够分离显著背景片段和显著动作片段并检测到视频中的模糊动作片段,本发明基于时域卷积设计了一个具有三条分支的注意力模型分别对显著动作、显著背景和模糊动作进行建模,获取三者的注意力权重,并采用softmax函数对其输出结果进行归一化处理。该模型的输出为注意力权重处理。该模型的输出为注意力权重其中a
act
,a
amb
和a
bkd
分别对应显著动作、模糊动作和显著背景在时间上的概率分布。具体过程如下:
[0069]
att=softmax(conv(x
in
,θ
att
))
[0070]
式中,θ
att
为可训练的注意力模型参数。为了分辨视频特征中的显著动作、模糊动作和显著背景,基于上述三个注意力权重和原始时域类激活序列f,构建了相应的时域类激活序列cas
act
、cas
amb
和cas
bkd
。其中,可用公式表示为:
[0071]
cas
act
=a
act
*f
[0072]
同理,可以分别得到用于描述模糊动作和显著背景的和其中,cas
act
在视频中显著动作的时间位置上具有较高的激活值,在显著背景的时间位置上受到抑制;cas
bkd
在显著背景的时间位置上具有较高的激活值。因此,基于cas
act
和cas
bkd
,网络能分离视频中的显著动作和显著背景。cas
amb
在显著动作和模糊动作的时间位置上均具有较高的激活值。
[0073]
本发明通过多示例学习机制聚合视频中的显著特征,监督网络的训练过程。将整条未剪辑视频视为一个多示例包,每个视频段作为一个示例,通过之前的方法,每一个视频段都能获取相应的类激活值。为了评估每个时域类激活序列的损失,本发明通过top-k池化聚合视频段的类激活值以获取视频级动作类别分数,以f为例,用公式表示为:
[0074][0075]
式中:l∈{1,2,...,t},|l|=k=max(1,t//r),r为预设定参数。最后在类别维度施加softmax函数获取视频级动作类别分数,采用交叉熵函数计算分类损失:
[0076][0077][0078]
式中:j=1,2,...,c 1,为视频包含动作j的概率,为原始时域类激活序列的分类损失函数。同理,基于时域类激活序列cas
act
、cas
amb
和cas
bkd
,可以得到相应的分类损失函数和本发明将一整条未剪辑视频视为同时包含动作和背景的多示例包,设原始时域类激活序列的类别标签为yj=1,y
c 1
=1。其次,为了保证cas
act
和cas
bkd
对应的注意力a
act
和a
bkd
分别关注视频中的显著动作和显著背景,设定其类别标签分别为yj=1,y
c 1
=0和yj=0,y
c 1
=1。此外,为了定位视频中的模糊动作,本发明设定cas
amb
的类别标签
为yj=1,y
c 1
=1,使a
amb
能够同时关注视频中激活值较高的显著动作和激活值相对较低的模糊动作。
[0079]
虽然上述过程能够利用多分支注意力模型实现动作和背景的分离,但是网络缺少动作时间尺度信息的引导,难以在复杂的未剪辑视频中直接定位模糊动作片段,无法保证定位结果的完整性。而模糊动作片段往往在时间上位于显著动作片段的相邻位置并远离显著背景片段。此外,其注意力权重会稍低于显著动作注意力权重,但明显大于显著背景注意力权重。基于上述思想,本发明提出了一种简单有效的方法定位视频中的模糊动作片段,并设计模糊动作对比损失函数细化视频特征,使网络定位到更加完整的动作。首先,根据显著动作注意力a
act
,以top-k池化在嵌入特征x
in
上获取显著动作特征
[0080][0081]
式中:k
act
=max(1,t//r
act
)为超参数,r
act
为预设定参数,控制显著动作特征的采样率。topk(k,*)为截取*中k个最大值的时间索引。同理可以获取显著背景特征
[0082][0083]
式中参数与x
act
的参数类似。由于注意力权重a
amb
同时关注显著动作和模糊动作,难以直接获取模糊动作特征,而显著动作权重稍大于模糊动作权重。因此,在a
amb
中首先去除显著动作特征和显著背景特征对应的时间索引。用公式表示如下:
[0084][0085]
之后采用与之前类似的top-k池化获取模糊动作特征
[0086][0087]
式中参数与x
act
的参数类似。最后,将infonce损失函数应用于视频段级别上,计算模糊动作对比损失,细化模糊动作特征。利用显著动作特征与模糊动作特征构建正样本对,显著背景特征与模糊动作特征构建负样本对,从而在特征空间中驱使显著动作和模糊动作更加紧凑,显著背景与模糊动作相互远离。假设选取模糊动作特征显著动作特征和显著背景特征引入infonce损失函数中:
[0088][0089]
式中:k
bkd
为超参数,用于控制显著背景特征x
bkd
的时间维度大小,τ=0.07为温度常数。该损失函数可以最大化显著动作片段和模糊动作片段之间的互信息。因此在每一轮迭代训练的过程中,网络不断找到新的模糊动作特征,并与显著特征相对比,使真实动作范围内的特征信息更加丰富,提高特征分布的可鉴别性,从而捕捉动作完整的发生过程。除了上述损失函数,还引入了l1损失函数保证显著动作注意力权重a
act
的稀疏性:
[0090][0091]
最后将各项损失函数结合,计算总损失函数l
total
,并通过adam优化器训练使网络达到收敛:
[0092]
[0093]
其中,α和β为相应的损失系数。
[0094]
在测试阶段cas
act
能够更准确地建模动作分布情况,因此通过cas
act
获取视频级的类别分数p
act
,并设定阈值θ
cls
,在p
act
中筛选出高于θ
cls
的动作类别c
act
。之后对cas
act
,在类别c
act
对应的维度上采用多阈值分割策略获取大量动作提名。对于某个动作提名(ts,te,c
act
),通过如下公式计算其置信分数
[0095][0096][0097][0098]
其中,ts和te分别为动作的开始和结束时间,li=(t
e-ts)/4,μ为预设定参数。最后采用非极大值抑制算法去除冗余提名,以获得最终的动作定位结果。
[0099]
本发明采用pytorch深度学习框架进行实验,具体的参数如下表1所示:
[0100]
表1
[0101][0102][0103]
模型训练至收敛后在thumos-14数据集和activitynet-1.2数据集上进行评估。评估结果分别如表2和表3所示,从中可以看出,本发明方法在两个数据集上的动作定位精度均超过了先前的主流方法。
[0104]
表2
[0105][0106]
表3
[0107][0108]
图2以先前的最佳方法ham-net为基准,展示本发明方法的可视化结果。(a)中的动作对应运动员的举重过程,在运动员“从地上拿起杠铃”(图片[1])和“将杠铃挺举到头顶”(图片[4])的两个阶段,运动的幅度较大,运动特征较明显;并且背景[5]存在明显的场景切换,它们能被基准方法轻松地定位出来。然而在举重过程中,运动员会将杠铃挺举并停顿在胸口位置(图片[2]),而且此过程发生了明显的镜头切换(图片[3])。该过程在没有时间监督信息的情况下难以捕捉,但本发明方法能将之完整地定位出来。(b)视频包含多条打高尔夫动作,第3个动作片段整体进行了慢放,基准方法能够检测出部分打高尔夫球的过程。但在球杆位于最高点和最低点时,运动员往往会进行蓄力停顿(图片[1][3][5]),并且因为进行了慢放,这些时间位置的运动特征更加模糊,难以与静态背景区分。而通过定位结果可以看出,本发明方法能解决该问题,并且在完整定位第3段动作的同时没有影响其他动作的定位结果,充分体现了本发明方法的有效性。
[0109]
以上所述,仅为本发明专利的优选实施方式,但本发明专利的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明专利所公开的范围内,根据本发明专利的
技术方案及其发明专利构思加以等同替换或改变,都属于本发明专利的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。