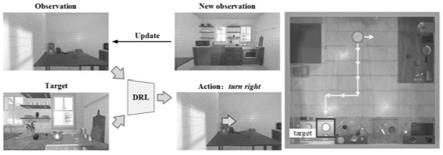
技术特征:
1.服务机器人自适应目标导航方法,其特征是,包括:获取室内若干幅家庭场景图像,确定导航任务目标图像,将服务机器人视为智能体,设置智能体的初始位置为场景中的随机点;获取智能体第一人称视角下的视觉观测图像,基于训练后的卷积神经网络,提取视觉观测图像的语义特征和目标图像的语义特征;基于目标图像的语义特征,和智能体每执行一个动作所采集的视觉观测图像的语义特征,确定目标注意概率分布;基于智能体每执行一个动作所采集的视觉观测图像的语义特征和智能体当前时刻之前的轨迹中所收集到的经验,确定经验注意概率分布;所述智能体当前时刻之前的轨迹中所收集到的经验,包括:历史动作、按照序列观察到的图像和观测-经验联合表征;基于目标注意概率分布和经验注意概率分布,得到融合概率分布;基于融合概率分布、当前时刻视觉观测图像的语义特征、当前时刻目标图像的语义特征和视觉观测图像区域位置空间特征,构建全局注意嵌入向量;将全局注意嵌入向量,输入到深度强化学习网络中,深度强化学习网络输出动作决策,完成目标导航。2.如权利要求1所述的服务机器人自适应目标导航方法,其特征是,基于目标图像的语义特征,和智能体每执行一个动作所采集的视觉观测图像的语义特征,确定目标注意概率分布;具体包括:对于所索引为i,j的区域,计算在t时刻状态下的观测-目标联合表征目标联合表征其中,i的取值范围是1,...,n
p
,j的取值范围是1,...,n
p
;u
g
表示目标图像的语义特征;对来自t时刻智能体视觉观测使用卷积神经网络提取语义信息,输出维度为n
p
×
n
p
×
d
p
,与观测图像的区域映射索引i,j,...,n
p
,(i,j)
t
的位置对应于观察到的图像中的区域语义信息用向量表示;目标图像的语义特征用特征向量表示,u
g
与观测输入特征向量之间的相互作用使用向量的内积运算嵌入到相同的特征空间,令可训练的参数矩阵和参数分别将和u
g
转换到d维空间;对于所索引为i,j={1,...,n
p
}的区域,计算在t时刻状态下的观测-目标联合表征对观测-目标联合表征采用softmax函数运算得到目标注意概率分布3.如权利要求1所述的服务机器人自适应目标导航方法,其特征是,基于智能体每执行一个动作所采集的视觉观测图像的语义特征和智能体当前时刻之前的轨迹中所收集到的经验,确定经验注意概率分布;具体包括:基于观测输入图像学习一个概率分布函数,由t-1时刻的lstm的隐藏状态携带t-1时刻的经验,作为t时刻经验注意模块的输入,其中lstm的输入是状态观测的联合表征;将t-1时刻的lstm隐藏状态表示为使用可训练的参数矩阵将其同
样映射到d维空间,计算在t时刻状态下的观测-经验联合表征经验联合表征对联合表征应用softmax函数运算得到相应的注意概率分布4.如权利要求1所述的服务机器人自适应目标导航方法,其特征是,基于目标注意概率分布和经验注意概率分布,得到融合概率分布;具体包括:将t时刻所有的目标注意概率分布和经验注意概率分布设置权重后,进行点乘并归一化,得到融合概率分布。5.如权利要求1所述的服务机器人自适应目标导航方法,其特征是,将全局注意嵌入向量,输入到深度强化学习网络中,深度强化学习网络输出动作决策,完成目标导航;具体包括:将全局注意嵌入向量按顺序输入到深度强化学习网络sac中,智能体将基于当前模型中的参数在动作空间中决策选出最佳动作,机器人将根据此指令完成相应的控制运动;如果输出动作是done,则目标导航结束,环境将对导航片段进行评估;否则视觉传感器继续检测当前环境状态完成视觉观测输入,循环此过程,直至达到最大运动步数限制,强制结束本次导航任务;深度强化学习网络的动作执行者actor收集导航过程中的轨迹,并将轨迹存放在经验缓冲区中;对经验缓冲区中的成功导航轨迹按照所获收益值的大小由高到低进行序列整理;对整理后的成功导航轨迹,分批优先采样后用于策略优化;深度强化学习网络输出动作决策,完成目标导航。6.如权利要求5所述的服务机器人自适应目标导航方法,其特征是,所述智能体将基于当前模型中的参数在动作空间中决策选出最佳动作;是通过构建一种次级目标状态回溯模型来搜索经验池中某条成功轨迹中对收益值存在最大影响的中间状态;具体包括:其中,s
t
′
表示与当前状态s
t
最相关的次级状态;利用残差函数进行适应性设计,用于处理轨迹中的过去状态,如公式(11)所示,其中,f
ω
(s
i
)对第i时刻的状态输入s
i
进行线性变换,系数α
i
是softmax归一化向量α的第i个元素,代表过去时刻的状态s
i
与当前状态s
t
之间的相关性,亦即状态s
i
是一个需要达到的重要次级目标状态的可能性,归一化操作如公式(12)所示,s1:s
t-1
是t时刻前智能体所有状态的串联,q
ω
和k
w
是关于状态的线性函数;向量α的归一化操作计算如公式(12)所示;7.如权利要求1所述的服务机器人自适应目标导航方法,其特征是,获取智能体第一人称视角下的视觉观测图像,基于训练后的卷积神经网络,提取视觉观测图像的语义特征和目标图像的语义特征;其中,训练后的卷积神经网络,训练过程包括:
构建第一训练集;所述第一训练集为已知语义特征的视觉观测图像;将第一训练集输入到卷积神经网络中,对卷积神经网络进行训练,得到训练后的卷积神经网络。8.服务机器人自适应目标导航系统,其特征是,包括:获取模块,其被配置为:获取室内若干幅家庭场景图像,确定导航任务目标图像,将服务机器人视为智能体,设置智能体的初始位置为场景中的随机点;特征提取模块,其被配置为:获取智能体第一人称视角下的视觉观测图像,基于训练后的卷积神经网络,提取视觉观测图像的语义特征和目标图像的语义特征;概率分布计算模块,其被配置为:基于目标图像的语义特征,和智能体每执行一个动作所采集的视觉观测图像的语义特征,确定目标注意概率分布;基于智能体每执行一个动作所采集的视觉观测图像的语义特征和智能体当前时刻之前的轨迹中所收集到的经验,确定经验注意概率分布;所述智能体当前时刻之前的轨迹中所收集到的经验,包括:历史动作、按照序列观察到的图像和观测-经验联合表征;嵌入向量构建模块,其被配置为:基于目标注意概率分布和经验注意概率分布,得到融合概率分布;基于融合概率分布、当前时刻视觉观测图像的语义特征、当前时刻目标图像的语义特征和视觉观测图像区域位置空间特征,构建全局注意嵌入向量;目标导航模块,其被配置为:将全局注意嵌入向量,输入到深度强化学习网络中,深度强化学习网络输出动作决策,完成目标导航。9.一种电子设备,其特征是,包括:存储器,用于非暂时性存储计算机可读指令;以及处理器,用于运行所述计算机可读指令,其中,所述计算机可读指令被所述处理器运行时,执行上述权利要求1-7任一项所述的方法。10.一种存储介质,其特征是,非暂时性地存储计算机可读指令,其中,当所述非暂时性计算机可读指令由计算机执行时,执行权利要求1-7任一项所述方法的指令。
技术总结
本发明公开了服务机器人自适应目标导航方法及系统,所述方法包括:获取室内若干幅家庭场景图像,确定导航任务目标图像,将服务机器人视为智能体,获取智能体第一人称视角下的视觉观测图像,提取视觉观测图像的语义特征和目标图像的语义特征;确定目标注意概率分布;确定经验注意概率分布;基于目标注意概率分布和经验注意概率分布,得到融合概率分布;基于融合概率分布、当前时刻视觉观测图像的语义特征、当前时刻目标图像的语义特征和视觉观测图像区域位置空间特征,构建全局注意嵌入向量;将全局注意嵌入向量,输入到深度强化学习网络中,深度强化学习网络输出动作决策,完成目标导航。提高机器人对于新环境的认知能力和探索能力。能力。能力。
技术研发人员:周风余 杨志勇 夏英翔 尹磊
受保护的技术使用者:山东大学
技术研发日:2022.02.10
技术公布日:2022/5/10
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。