基于视觉建模和词义分析的vr内容库的构建方法
技术领域
1.本发明属于三维建模与虚拟内容模拟领域,具体涉及一种基于视觉建模和词义分析的vr内容库的构建方法。
背景技术:
2.对于三维建模来说,一般主要有两大类型、三种方法。第一种类型是正向建模,即使用专业的三维建模软件来手工建模;第二种类型是逆向建模,即通过实物反求出几何模型逆向生成3d模型,可以分为使用三维激光扫描设备测量进行建模的主动式方法和基于图像或者视频来进行建模的被动式方法。
3.现有三维建模技术的缺点是效率低、废人力。使用专业的三维建模软件进行手工建模,需要从点到边、从边到面进行构造,而且要得到与真实场景的尺寸、纹理等一致的三维模型,还涉及到对真实场景的测量工作以及指定其与三维模型的对应关系。这一过程十分复杂,相当耗时耗力,效率不高。同时在虚拟内容模拟中,需要根据剧本调整虚拟内容中所出现的道具,传统的调整方法耗时大,效率低下。
4.鉴于此,目前亟待提出一种基于视觉建模和词义分析的vr内容库的构建方法。
技术实现要素:
5.为此,本发明提供一种基于视觉建模和词义分析的vr内容库的构建方法,结合虚拟现实内容的制作需求为虚拟现实内容制作匹配所需道具模型,从而提高制作效率、降低人力成本。
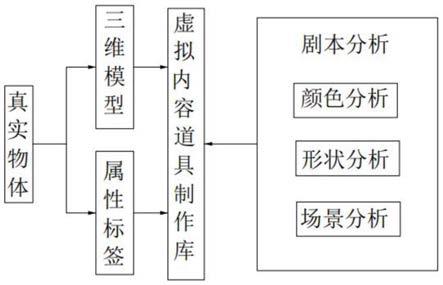
6.本发明的基于视觉建模和词义分析的vr内容库的构建方法,包括如下步骤:
7.步骤1、获取真实物体的图像数据,根据图像数据建模后得到三维模型导入vr内容库;
8.步骤2、获取真实物体的物理属性,将物理属性对应映射至三维模型,同时生成基于三维模型的属性标签和属性标签集合导入vr内容库;所述物理属性包括颜色、形状和真实物体所处的场景;
9.步骤3、获取剧本,对剧本进行词义分割后提取词义信息,然后基于词义信息检索三维模型,与三维模型及其属性标签匹配。
10.进一步的,所述步骤一中获取真实物体的图像数据的具体过程为:
11.相机对真实物体进行多角度拍摄获取多张图像,且于不同角度拍摄时的光圈、快门、iso以及白平衡参数一致。
12.进一步的,步骤一中根据图像数据建模的具体过程为:
13.步骤1.1、对图像数据进行不同尺度的高斯模糊和降采样,得到具有m组、每组n层图像的高斯金字塔;
14.步骤1.2、对高斯金字塔每组图像中相邻两层图像相减得到高斯差分金字塔;
15.遍历高斯差分金字塔中的像素点检测灰度极值点,将所述灰度极值点作为候选关
键点;
16.计算候选关键点的大小和方向,生成直方图;
17.以直方图的峰值为主方向旋转坐标轴后,以候选关键点为中心在其尺度图像中选择子区域,绘制子区域8个方向的梯度直方图,沿方向向量排序后得到sift特征描述符;
18.步骤1.3、对不同角度的图像进行sift特征描述符比对,计算一张图像中的一个关键点距离另一张图像中所有关键点的欧式距离,得到最近点和次近点,计算关键点与最近点的距离、关键点与次近点的距离两者的比值,若比值小于阈值,将关键点与最近点作为一对匹配点;
19.步骤1.4、计算至少8对匹配点后,计算基础矩阵f,所述基础矩阵包括相机的内参与外参;
20.步骤1.5、通过相机内外参数反求出图像点到空间点的投影矩阵,从而计算得出空间坐标,最终获得三维点云,将三维点云三角化最终得到三维模型。
21.进一步的,所述步骤2具体包括:
22.步骤2.1、获取真实物体的颜色、形状以及所处的场景,同时生成三维模型对应的属性标签s1、s2……
sn;
23.步骤2.2、将真实物体的颜色映射至对应的三维模型中,并记录于三维模型对应的属性标签内;
24.步骤2.3、将真实物体的形状映射至对应的三维模型中,并记录于三维模型对应的属性标签内;
25.步骤2.4、将真实物体的所处的场景映射至对应的三维模型中,并记录于三维模型对应的属性标签内;
26.步骤2.5、将s1、s2……
sn导入vr内容库。
27.进一步的,所述步骤3具体包括:
28.步骤3.1、获取剧本,对剧本内容按句进行分割;
29.再对句子通过ictclas进行分词、词性标注和过滤停用词的处理;
30.步骤3.2、抽取剧本中的道具信息,建立道具的数据标签y1、y2……yn
;
31.步骤3.2、抽取剧本中的道具颜色信息,并将道具颜色信息记录至所对应的数据标签中;
32.步骤3.3、抽取剧本中的道具形状信息,并将道具形状信息记录至所对应的数据标签中;
33.步骤3.4、抽取剧本中的道具场景信息,并将道具场景信息记录至所对应的数据标签中;
34.步骤3.5、各道具信息的数据集合分别与vr内容库中的三维模型属性标签数据集合逐一进行交集运算,实现剧本与虚拟现实内容的匹配。
35.进一步,步骤3.4的抽取剧本中的道具信息包括:
36.步骤3.4.1、将常见道具登入于分词词典中,直接进行抽取;
37.步骤3.4.2、抽取高频名词,同时检索高频名词的上下文包括“动词 道具”、“动词 数量词 道具”“形容词 道具”、“介词 道具”,然后抽取道具。
38.进一步,步骤3.5的抽取剧本中的道具颜色信息具体为:。
39.以道具的词汇为中心对其上下文的预定范围字符进行检索,检索表示颜色的词汇,抽取道具的颜色。
40.进一步,步骤3.6中的抽取剧本中的道具形状信息具体为:
41.以道具的词汇为中心对其上下文的预定范围字符进行检索,检索表示形状的词汇,抽取道具的颜色。
42.进一步的,步骤3.7中的抽取剧本中的道具所处的场景信息具体为:
43.以道具的词汇为中心对其上下文的预定范围字符进行检索,检索“动词 地点”、“介词 地点”的词汇,抽取道具所处的场景。
44.本发明的上述技术方案,相比现有技术具有以下优点:
45.结合虚拟现实内容的制作需求为虚拟现实内容制作匹配所需道具模型,从而提高制作效率、降低人力成本。
附图说明
46.图1是本发明实施例提供的流程示意图。
具体实施方式
47.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
48.实施例一。
49.本发明的基于视觉建模和词义分析的vr内容库的构建方法,包括如下步骤:
50.步骤1、获取真实物体的图像数据,根据图像数据建模后得到三维模型导入vr内容库;
51.步骤2、获取真实物体的物理属性,将物理属性对应映射至三维模型,同时生成基于三维模型的属性标签和属性标签集合导入vr内容库;所述物理属性包括颜色、形状和真实物体所处的场景;
52.步骤3、获取剧本,对剧本进行词义分割后提取词义信息,然后基于词义信息检索三维模型,与三维模型及其属性标签匹配。
53.进一步的,所述步骤一中获取真实物体的图像数据的具体过程为:
54.相机对真实物体进行多角度拍摄获取多张图像,且于不同角度拍摄时的光圈、快门、iso以及白平衡参数一致。
55.进一步的,步骤一中根据图像数据建模的具体过程为:
56.步骤1.1、对图像数据进行不同尺度的高斯模糊和降采样,得到具有m组、每组n层图像的高斯金字塔;
57.步骤1.2、对高斯金字塔每组图像中相邻两层图像相减得到高斯差分金字塔;
58.遍历高斯差分金字塔中的像素点检测灰度极值点,将所述灰度极值点作为候选关键点;
59.计算候选关键点的大小和方向,生成直方图;
60.以直方图的峰值为主方向旋转坐标轴后,以候选关键点为中心在其尺度图像中选择子区域,绘制子区域8个方向的梯度直方图,沿方向向量排序后得到sift特征描述符;
61.步骤1.3、对不同角度的图像进行sift特征描述符比对,计算一张图像中的一个关键点距离另一张图像中所有关键点的欧式距离,得到最近点和次近点,计算关键点与最近点的距离、关键点与次近点的距离两者的比值,若比值小于阈值,将关键点与最近点作为一对匹配点;
62.步骤1.4、计算至少8对匹配点后,计算基础矩阵f,所述基础矩阵包括相机的内参与外参;
63.步骤1.5、通过相机内外参数反求出图像点到空间点的投影矩阵,从而计算得出空间坐标,最终获得三维点云,将三维点云三角化最终得到三维模型。
64.进一步的,所述步骤2具体包括:
65.步骤2.1、获取真实物体的颜色、形状以及所处的场景,同时生成三维模型对应的属性标签s1、s2……
sn;
66.步骤2.2、将真实物体的颜色映射至对应的三维模型中,并记录于三维模型对应的属性标签内;
67.步骤2.3、将真实物体的形状映射至对应的三维模型中,并记录于三维模型对应的属性标签内;
68.步骤2.4、将真实物体的所处的场景映射至对应的三维模型中,并记录于三维模型对应的属性标签内;
69.步骤2.5、将s1、s2……
sn导入vr内容库。
70.进一步的,所述步骤3具体包括:
71.步骤3.1、获取剧本,对剧本内容按句进行分割;
72.再对句子通过ictclas进行分词、词性标注和过滤停用词的处理;
73.步骤3.2、抽取剧本中的道具信息,建立道具的数据标签y1、y2……yn
;
74.步骤3.2、抽取剧本中的道具颜色信息,并将道具颜色信息记录至所对应的数据标签中;
75.步骤3.3、抽取剧本中的道具形状信息,并将道具形状信息记录至所对应的数据标签中;
76.步骤3.4、抽取剧本中的道具场景信息,并将道具场景信息记录至所对应的数据标签中;
77.步骤3.5、各道具信息的数据集合分别与vr内容库中的三维模型属性标签数据集合逐一进行交集运算,实现剧本与虚拟现实内容的匹配。
78.进一步,步骤3.4的抽取剧本中的道具信息包括:
79.步骤3.4.1、将常见道具登入于分词词典中,直接进行抽取;
80.步骤3.4.2、抽取高频名词,同时检索高频名词的上下文包括“动词 道具”、“动词 数量词 道具”“形容词 道具”、“介词 道具”,然后抽取道具。
81.进一步,步骤3.5的抽取剧本中的道具颜色信息具体为:。
82.以道具的词汇为中心对其上下文的预定范围字符进行检索,检索表示颜色的词汇,抽取道具的颜色。
83.进一步,步骤3.6中的抽取剧本中的道具形状信息具体为:
84.以道具的词汇为中心对其上下文的预定范围字符进行检索,检索表示形状的词汇,抽取道具的颜色。
85.进一步的,步骤3.7中的抽取剧本中的道具所处的场景信息具体为:
86.以道具的词汇为中心对其上下文的预定范围字符进行检索,检索“动词 地点”、“介词 地点”的词汇,抽取道具所处的场景。
87.实施例二
88.本实施例是在实施例一基础上所实际使用的具体实施例。
89.对于真实物体的数据采集采用单反相机进行拍摄,应采用多角度(如俯视、平视、仰视、左视、右视、前视、后视等)的方式组合拍照,且照片的光圈、快门、iso、白平衡要尽量一致。
90.对图像做不同尺度的高斯模糊和降价采样(隔点采样),生成高斯金字塔。高斯金字塔共m组,每组共n层图像,组数,(m是原始图像的行高,n是原始图像的列宽,t为塔顶图像的最小维数的对数值),层数n一般为3~5层。将原始图像和不同尺度的高斯函数做卷积,即(σ是尺度空间因子,决定图像的模糊程度,一般取1.6),其中g(x,y,σ)是卷积核可变的高斯函数,i(x,y,σ)是输入图像。
91.如先是将第0组图像组内每层图像分别乘以不同的尺度因子(0,σ,kσ,k2σ,k3σ,k4σ,
……kn-2
σ),再将第0组倒数第三层图像作比例因子为2的降采样得到第1组的第1层图像,将第1组图像组内每层图像分别乘以不同的尺度因子(0,σ,kσ,k2σ,k3σ,k4σ,
……kn-2
σ),重复上述步骤得到高斯金字塔。
92.高斯金子塔每组中相邻两层相减生成高斯差分金字塔。即:
93.d(x,y,σ)=(g(x,y,kσ)-g(x,y,σ))*i(x,y)=l(x,y,kσ)-l(x,y,σ)
94.在高斯差分金字塔中检测极值点。将某像素点与其同尺度的8个相邻像素点、上下相邻尺度对应位置的邻域18个像素点进行比较,共计26个点。当此像素点灰度值为极值时,则认为此点为候选关键点。
95.根据
96.和
97.计算关键点的大小和方向,并将信息统计为直方图,直方图中的峰值为主方向。
98.根据上述主方向将坐标轴旋转为关键点的方向,确保旋转不变性,以该点为中心在其尺度图像中选择子区域。其中,该区域为一个大小为4
×
4的窗口。同时,各子区域包括4
×
4个像素点。然后,统计子区域8个方向的梯度,绘制其直方图。将这8个方向向量排列顺序,得到128维特征向量,即sift特征描述符。
99.对两张图的sift特征描述符进行相似性比对,计算一张图片中的某个关键点距离另一张图片所有关键点的欧氏距离,得出最近点和次近点。
100.上述计算过程如下:wi(w1,w2,w3,
……w128
)和ri(r1,r2,r3,
……r128
)两组sift特征
向量,其欧式距离为最近距离与次近距离的比值小于阈值(根据实际情况进行设定)则匹配成功。
101.对于不同视角下的两幅图中的匹配点m和m’用齐次坐标表示为(u,v,1)和(u’,v’,1)。
102.m'一定位于m在图像i'中的对极线l'上,且l'=fm,f称之为基础矩阵。m’位于l’上则有m’t
fm=0,
103.可以线性表示为uf=0,
104.u=(u’u,u’v,u’,v’u,v’v,v’,u,v,1),
105.f=(f
11
,f
12
,f
13
,f
21
,f
22
,f
23
,f
31
,f
32
,f
33
)
t
,有8对匹配点即可求出f。
106.基础矩阵f包含相机的内参和外参,两个相机内部参数矩阵k和k’已知,e=k’t
fk,对于两幅图的对称点m和m’有m=rm’ t,其中r是旋转矩阵,t是平移向量。将平移向量进行叉乘得到叉乘矩阵
[0107][0108]
对上式两边同乘mt[t]x,mt[t]xrm’=mtem’,e=[t]xr是包含旋转矩阵和平移矩阵的本质矩阵。对本质矩阵进行奇异值分解(svd)即可求得相机外参数矩阵r和t。通过相机内外参数反求出图像点到空间点的投影矩阵,从而计算得出空间坐标,最终获得三维点云。将三维点云三角化最终得到三维模型。
[0109]
第2个环节为物体属性标签录入,完善虚拟现实内容制作道具库,包括如下步骤。
[0110]
将第1个环节得到的三维模型多个维度属性信息(如颜色信息、形状信息、场景信息等)录入到虚拟现实内容制作道具库。
[0111]
将三维模型的颜色信息color录入到虚拟现实内容制作道具库,如红色、蓝色、黄色、
……
。
[0112]
将三维模型的形状信息shape录入到虚拟现实内容制作道具库,如圆形、方形、三角形、
……
。
[0113]
将三维模型的场景信息scene录入到虚拟现实内容制作道具库,如咖啡店、书店、卧室、
……
。
[0114]
由上述步骤可以将各物体模型的属性标签数据集合s1、s2、s3、
……
补充到虚拟现实内容制作道具库中。
[0115]
第3个环节为剧情与虚拟现实内容制作道具库进行匹配,包括如下步骤。
[0116]
输入虚拟现实内容制作的剧本,对剧本内容按句进行分割。再对句子通过ictclas进行分词、词性标注和过滤停用词的处理,如标点符号、语气、人称等。利用词嵌入技术将处理好的文本进行词向量化,把自然语言的符号信息转化为向量形式的数字信息,以便进行后续处理。对处理过的剧本进行信息抽取,主要是道具及其属性的信息获取。
[0117]
对于剧本中出现的道具进行信息抽取。大部分的道具名称都被收录在分词词典中,而未登录词需要基于高词频和上下文词性进行抽取,道具会在整个剧本或剧本部分段
落出现得较为频繁,道具的上下文词性有“动词 道具”、“动词 数量词 道具”“形容词 道具”、“介词 道具”等形式。对抽取到的道具一、道具二、道具三等分别建立相应的数据集合y1、y2、y3、
……
。
[0118]
对道具的颜色信息进行分析。道具的颜色信息主要是基于规则进行抽取,以道具词为中心对上下文k个字符内进行搜索(k的大小由实际情况决定),对文本中出现的“红、黄、蓝、
……”
等表示颜色的词语进行抽取。将道具一的颜色信息color记录到数据集合y1,将道具二的颜色信息color记录到数据集合y2
……
以此类推。
[0119]
对道具的形状信息进行分析。道具的形状信息抽取与颜色信息抽取类似,以道具词为中心对上下文k个字符内进行搜索(k的大小由实际情况决定),对文本中出现的“圆形、方形、三角形、
……”
等表示形状的词语进行抽取。将道具一的形状信息shape记录到数据集合y1,将道具二的形状信息shape记录到数据集合y2
……
以此类推。
[0120]
对道具的场景信息主要是通过场景指示词、构词规则进行分析。场景指示词是指剧本中表示场景词出现的特定指示词,如“来到xx”、“走到xx”、“在xx”等。将道具一的场景信息scene记录到数据集合y1,将道具二的场景信息scene记录到数据集合y2
……
以此类推。
[0121]
根据上述道具属性信息的分析可以得到各道具信息的数据集合,在虚拟内容制作道具库中进行匹配。将各道具信息的数据集合分别与虚拟现实内容制作道具库中的物体模型属性标签数据集合s1、s2、s3、
……
逐一进行交集运算,这些交集的势越大则匹配度越高。
[0122]
显然,上述实施例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引伸出的显而易见的变化或变动仍处于本发明创造的保护范围之中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
