1.本发明属于声学技术领域,尤其涉及一种声学成像设备及分析方法。
背景技术:
2.声学分析顾名思义就是对于声源进行声学分析,为了更好的实现声学分析过程,开发了麦克风阵列,麦克风阵列顾名思义就是麦克风的排列。其实,其主要是由一定数目的声学传感器(一般是麦克风)组成,用来对声场的空间特性进行采样并处理的系统。
3.现有的麦克风阵列声学分析设备,一般只设置有对于声源的捕捉的传感器,仅仅可对于声场的空间特性进行采样并处理,并未在其上设置有场景镜头,无法对于空间内的场景进行要素捕捉,也无法进行场景分析,无法将二者结合,实现一个全面的分析过程,功能单一,使用效果一般,整体精准度也无法提升。
技术实现要素:
4.本发明的目的在于:为了解决现有的麦克风阵列声学分析设备,一般只设置有对于声源的捕捉的传感器,仅仅可对于声场的空间特性进行采样并处理,并未在其上设置有场景镜头,无法对于空间内的场景进行要素捕捉,也无法进行场景分析,无法将二者结合,实现一个全面的分析过程,功能单一,使用效果一般,整体精准度也无法提升的问题,而提出的基于球形麦克风阵列的场景分析声学成像设备及分析方法。
5.为了实现上述目的,本发明采用了如下技术方案:基于球形麦克风阵列的场景分析声学成像设备,包括计算机,所述计算机的一侧通过数据线连接有麦克风阵列组件,所述麦克风阵列组件包括麦克风阵列球体与支架。
6.作为上述技术方案的进一步描述:
7.所述麦克风阵列球体的底部固定安装有支架,所述麦克风阵列球体的外部镶嵌安装有场景镜头,所述麦克风阵列球体的内部设置有若干声学收录口。
8.进一步地,通过装置的外部设置有场景镜头,可有效对于场景要素进行捕捉,并通过深度学习算法,根据场景要素判定场景的类型,可与声源分析相互结合,不仅可对于声源进行判断,还可实现对于声源物的判断,由于有场景分析与声源分析的相互结合,可使分析结果更加精确,功能强大。
9.本文还公开了基于球形麦克风阵列的场景声学分析方法,包括如下步骤:
10.s1、开启装置,利用场景镜头对于场景内容进行捕捉;
11.s2、将数据通过数据线回传至计算机内;
12.s3、计算机对于拍摄的图像进行场景分析;
13.s4、声学收录口开启对于语音信号进行收集;
14.s5、继续将数据通过数据线回传至计算机内;
15.s6、对于语音信号进行分段处理;
16.s7、对于分段的语音信号源进行杂讯分析;
17.s8、对于具有杂讯的语音信号进行除杂;
18.s9、对于分段的语音信号源进行正交分析;
19.s10、进行声源方位的确定;
20.s11、对于声源方位与场景分析结果进行结合进行分析处理。
21.作为上述技术方案的进一步描述:
22.所述s1中,开启装置,利用场景镜头对于场景内容进行捕捉,其中场景镜头为ccd工业相机镜头或数字高清镜头中的一种或多种。
23.作为上述技术方案的进一步描述:
24.所述s3中,计算机利用深度学习算法对于拍摄的图像进行场景分析。
25.作为上述技术方案的进一步描述:
26.所述s6中,对于语音信号进行移帧分段处理,具体步骤为:对于可移动的有限长度窗口进行加权,进行采样频率和频率分辨率的调整。
27.作为上述技术方案的进一步描述:
28.所述s7中,对于分段的语音信号源进行杂讯分析,若分段的语音信号源进行傅里叶变换后,在频域并未叠交,则代表分段的语音信号源并无杂讯,反之,则代表分段的语音信号源有杂讯。
29.作为上述技术方案的进一步描述:
30.所述s8中,利用小波阈值算法对于具有杂讯的语音信号进行除杂。
31.作为上述技术方案的进一步描述:
32.所述s9中,利用duet算法对于分段的语音信号源进行正交分析。
33.作为上述技术方案的进一步描述:
34.所述s11中,对于声源方位与场景分析结果进行结合进行分析处理,具体步骤为:根据深度学习算法对于场景图像进行场景分析后,得到具体的场景信息,进而结合场景信息与声源方位信息,标识出该场景中该声源方位所对应的具体物体,从而实现声源方位的定位及声源发生物的标识识别。
35.综上所述,由于采用了上述技术方案,本发明的有益效果是:
36.本发明中,通过在装置的外部设置有场景镜头,可有效对于场景要素进行捕捉,并通过深度学习算法,根据场景要素判定场景的类型,可与声源分析相互结合,不仅可对于声源进行判断,还可实现对于声源物的判断,由于有场景分析与声源分析的相互结合,可使分析结果更加精确,功能强大,同时在方法内还设置有专门针对于语音信号的分段处理,继而对于语音信号进行杂讯分析与语音除杂,可有效保证语音信号的清晰度,降低语音信号的杂乱性,提高后续进行声源分析的精准度,提高了该方法的使用效果,适于推广。
附图说明
37.图1为基于球形麦克风阵列的场景分析声学成像设备的立体结构示意图。
38.图2为基于球形麦克风阵列的场景声学分析方法流程图。
39.图例说明:
40.1、计算机;2、数据线;3、麦克风阵列组件;31、声学收录口;32、场景镜头;33、麦克风阵列球体;34、支架。
具体实施方式
41.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
42.实施例1
43.请参阅图1-2,本发明提供一种技术方案:基于球形麦克风阵列的场景分析声学成像设备,包括计算机1,所述计算机1的一侧通过数据线2连接有麦克风阵列组件3,所述麦克风阵列组件3包括麦克风阵列球体33与支架34,所述麦克风阵列球体33的底部固定安装有支架34,所述麦克风阵列球体33的外部镶嵌安装有场景镜头32,所述麦克风阵列球体33的内部设置有若干声学收录口31;
44.其具体实施方式为:通过装置的外部设置有场景镜头32,可有效对于场景要素进行捕捉,并通过深度学习算法,根据场景要素判定场景的类型,可与声源分析相互结合,不仅可对于声源进行判断,还可实现对于声源物的判断,由于有场景分析与声源分析的相互结合,可使分析结果更加精确,功能强大;
45.本文还公开了基于球形麦克风阵列的场景声学分析方法,包括如下步骤:
46.s1、开启装置,利用场景镜头32对于场景内容进行捕捉,其中场景镜头32为ccd工业相机镜头;
47.s2、将数据通过数据线2回传至计算机1内;
48.s3、计算机1利用深度学习算法对于拍摄的图像进行场景分析;
49.s4、声学收录口31开启对于语音信号进行收集;
50.s5、继续将数据通过数据线2回传至计算机1内;
51.s6、对于语音信号进行移帧分段处理,具体步骤为:对于可移动的有限长度窗口进行加权,进行采样频率和频率分辨率的调整;
52.s7、对于分段的语音信号源进行杂讯分析,若分段的语音信号源进行傅里叶变换后,在频域并未叠交,则代表分段的语音信号源并无杂讯,反之,则代表分段的语音信号源有杂讯;
53.s8、利用小波阈值算法对于具有杂讯的语音信号进行除杂;
54.s9、利用duet算法对于分段的语音信号源进行正交分析;
55.s10、进行声源方位的确定;
56.s11、对于声源方位与场景分析结果进行结合进行分析处理,具体步骤为:根据深度学习算法对于场景图像进行场景分析后,得到具体的场景信息,进而结合场景信息与声源方位信息,标识出该场景中该声源方位所对应的具体物体,从而实现声源方位的定位及声源发生物的标识识别。
57.实施例2
58.请参阅图1-2,本发明提供一种技术方案:基于球形麦克风阵列的场景分析声学成像设备,包括计算机1,所述计算机1的一侧通过数据线2连接有麦克风阵列组件3,所述麦克风阵列组件3包括麦克风阵列球体33与支架34,所述麦克风阵列球体33的底部固定安装有支架34,所述麦克风阵列球体33的外部镶嵌安装有场景镜头32,所述麦克风阵列球体33的
内部设置有若干声学收录口31;
59.其具体实施方式为:通过装置的外部设置有场景镜头32,可有效对于场景要素进行捕捉,并通过深度学习算法,根据场景要素判定场景的类型,可与声源分析相互结合,不仅可对于声源进行判断,还可实现对于声源物的判断,由于有场景分析与声源分析的相互结合,可使分析结果更加精确,功能强大;
60.本文还公开了基于球形麦克风阵列的场景声学分析方法,包括如下步骤:
61.s1、开启装置,利用场景镜头32对于场景内容进行捕捉,其中场景镜头32为数字高清镜头;
62.s2、将数据通过数据线2回传至计算机1内;
63.s3、计算机1利用深度学习算法对于拍摄的图像进行场景分析;
64.s4、声学收录口31开启对于语音信号进行收集;
65.s5、继续将数据通过数据线2回传至计算机1内;
66.s6、对于语音信号进行移帧分段处理,具体步骤为:对于可移动的有限长度窗口进行加权,进行采样频率和频率分辨率的调整;
67.s7、对于分段的语音信号源进行杂讯分析,若分段的语音信号源进行傅里叶变换后,在频域并未叠交,则代表分段的语音信号源并无杂讯,反之,则代表分段的语音信号源有杂讯;
68.s8、利用小波阈值算法对于具有杂讯的语音信号进行除杂;
69.s9、利用duet算法对于分段的语音信号源进行正交分析;
70.s10、进行声源方位的确定;
71.s11、对于声源方位与场景分析结果进行结合进行分析处理,具体步骤为:根据深度学习算法对于场景图像进行场景分析后,得到具体的场景信息,进而结合场景信息与声源方位信息,标识出该场景中该声源方位所对应的具体物体,从而实现声源方位的定位及声源发生物的标识识别。
72.实施例3
73.请参阅图1-2,本发明提供一种技术方案:基于球形麦克风阵列的场景分析声学成像设备,包括计算机1,所述计算机1的一侧通过数据线2连接有麦克风阵列组件3,所述麦克风阵列组件3包括麦克风阵列球体33与支架34,所述麦克风阵列球体33的底部固定安装有支架34,所述麦克风阵列球体33的外部镶嵌安装有场景镜头32,所述麦克风阵列球体33的内部设置有若干声学收录口31;
74.其具体实施方式为:通过装置的外部设置有场景镜头32,可有效对于场景要素进行捕捉,并通过深度学习算法,根据场景要素判定场景的类型,可与声源分析相互结合,不仅可对于声源进行判断,还可实现对于声源物的判断,由于有场景分析与声源分析的相互结合,可使分析结果更加精确,功能强大;
75.本文还公开了基于球形麦克风阵列的场景声学分析方法,包括如下步骤:
76.s1、开启装置,利用场景镜头32对于场景内容进行捕捉,其中场景镜头32为ccd工业相机镜头与数字高清镜头;
77.s2、将数据通过数据线2回传至计算机1内;
78.s3、计算机1利用深度学习算法对于拍摄的图像进行场景分析;
79.s4、声学收录口31开启对于语音信号进行收集;
80.s5、继续将数据通过数据线2回传至计算机1内;
81.s6、对于语音信号进行移帧分段处理,具体步骤为:对于可移动的有限长度窗口进行加权,进行采样频率和频率分辨率的调整;
82.s7、对于分段的语音信号源进行杂讯分析,若分段的语音信号源进行傅里叶变换后,在频域并未叠交,则代表分段的语音信号源并无杂讯,反之,则代表分段的语音信号源有杂讯;
83.s8、利用小波阈值算法对于具有杂讯的语音信号进行除杂;
84.s9、利用duet算法对于分段的语音信号源进行正交分析;
85.s10、进行声源方位的确定;
86.s11、对于声源方位与场景分析结果进行结合进行分析处理,具体步骤为:根据深度学习算法对于场景图像进行场景分析后,得到具体的场景信息,进而结合场景信息与声源方位信息,标识出该场景中该声源方位所对应的具体物体,从而实现声源方位的定位及声源发生物的标识识别。
87.本实施例中,设置有专门针对于语音信号的分段处理,继而对于语音信号进行杂讯分析与语音除杂,可有效保证语音信号的清晰度,降低语音信号的杂乱性,提高后续进行声源分析的精准度,提高了该方法的使用效果,适于推广。
88.实施例1-3中,需要说明的是:
89.s9与s10的具体步骤如下:
90.分段的信号分别为:s1(t),s2(t),s3(t)
……
sn(t),该装置收到的信号为:
[0091][0092][0093]
其中,x1表示第一声学收录口接收到的混合信号,x2表示第二声学收录口接收到的混合信号,σi表示两麦克风之间的相对延时,ai表示语音信号到达两麦克风之间的相对衰减系数。
[0094]
基于无反射无混响的假设前提,对两路信号进行加窗傅里叶变换,将信号的时域表达式转换为频域表达式:
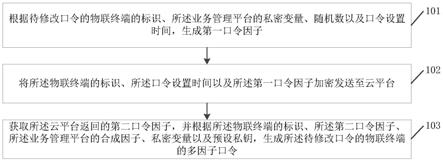
[0095][0096]
可以认为在每一个时频点(τ,ω)处,最多只有一个声源起主导作用,则每个时频点处的频域表达式可以表示为:
[0097]
[0098]
令
[0099]
扩展到n个同质声学收录口,则可得到任意两个同质声学收录口在时频点(τ,ω)处的频域相关系数矩阵:
[0100][0101][0102]
使用的定位计算是通过得到信号源产生的信号到达各个麦克风的时间差,确定声源距离两麦克风的距离差,进而得到声源的位置。
[0103]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。