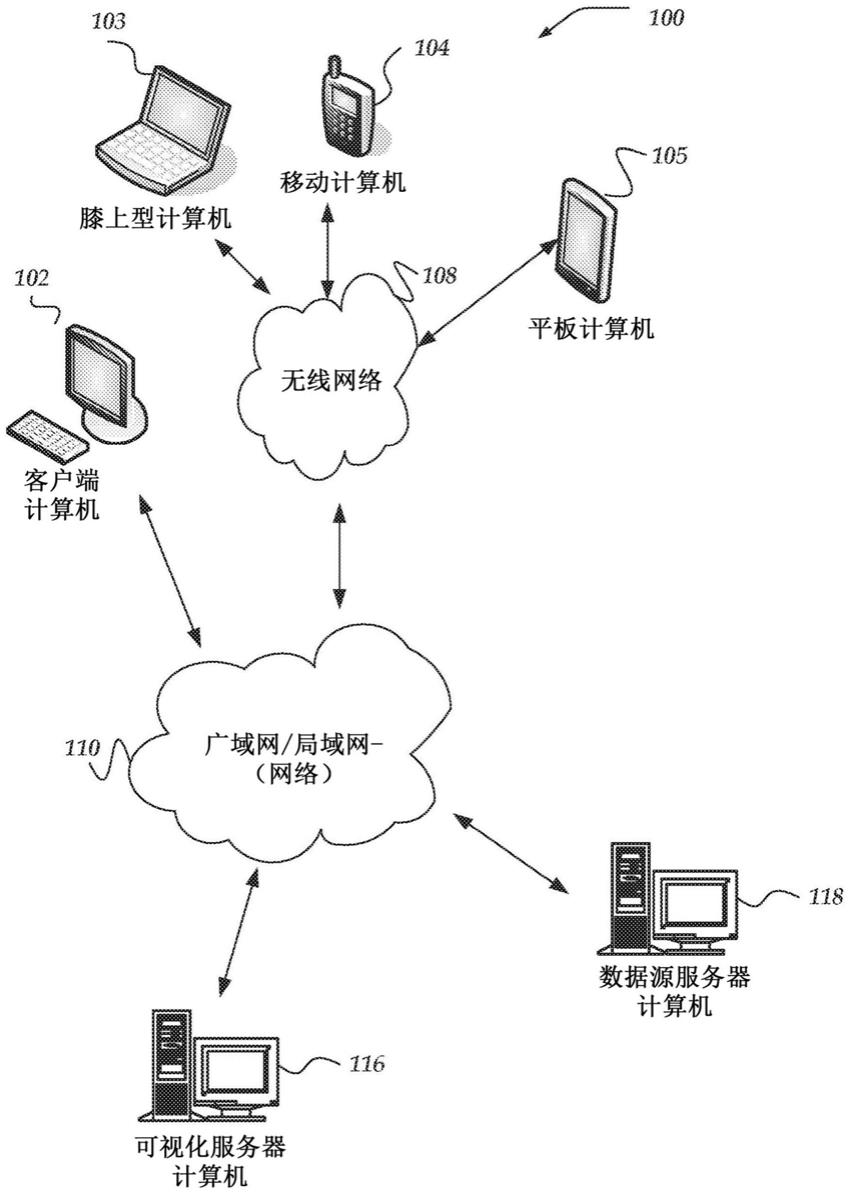
1.所公开的实现大体上涉及神经网络,且更具体地涉及用于神经网络的硬件实现的系统和方法。
2.背景
3.传统硬件未能跟上神经网络中的创新和基于机器学习的应用的日益普及。随着数字微处理器的发展处于停滞,神经网络的复杂性继续超过cpu和gpu的计算能力。基于脉冲神经网络(spike neural network)的神经形态(neuromorphic)处理器(例如loihi和true north)在它们的应用中被限制。对于类似gpu的架构,这样的架构的功率和速度受数据传输速度限制。数据传输可以消耗高达80%的芯片功率,且可以显著影响计算的速度。边缘应用(edge application)要求低功率消耗,但目前没有消耗小于50毫瓦的功率的已知高性能硬件实现。
4.使用交叉开关(cross-bar)技术的基于忆阻器的架构对于制造循环(recurrent)和前馈(feed-forward)神经网络仍然是不实用的。例如,基于忆阻器的交叉开关具有许多缺点,包括使它们变得不实用的在操作期间的电流泄漏和高时延。此外,在制造基于忆阻器的交叉开关时存在可靠性问题,特别是当神经网络具有负权重和正权重时。对于具有许多神经元的大型神经网络,在高维度处,基于忆阻器的交叉开关不能用于不同信号的同时传播,这在神经元由运算放大器表示时又使信号的求和变得复杂。此外,基于忆阻器的模拟集成电路具有许多限制,例如电阻状态的数量小、当形成忆阻器时的第一次循环问题、当训练忆阻器时的沟道形成的复杂性、对忆阻器的尺寸的不可预测的依赖性、忆阻器的缓慢操作以及电阻状态的漂移。
5.此外,神经网络所需的训练过程对神经网络的硬件实现提出了独特的挑战。训练后的神经网络用于特定的推断(inferencing)任务,例如分类。一旦神经网络被训练,硬件等价物就被制造。当神经网络被再训练时,硬件制造过程被重复,抬高了成本。虽然一些可重新配置的硬件解决方案存在,但是这样的硬件不容易被大规模生产,并且比不可重新配置的硬件花费多得多(例如,花费多5倍)。此外,边缘环境(例如智能家居应用)本身不需要可重编程性。例如,神经网络的所有应用的85%在操作期间不需要任何再训练,因此片上学习不是那么有用。此外,边缘应用包括噪声环境,其可以使可重编程硬件变得不可靠。
6.概述
7.因此,存在对解决至少一些上面指出的缺陷的方法、电路和/或接口的需要。对训练后的神经网络建模并根据本文所述的技术制造的模拟电路可以提供提高的每瓦性能的优点,在边缘环境中实现硬件解决方案方面可以是有用的,并可以处理各种应用,例如无人机导航和自动驾驶汽车。由所提出的制造方法和/或模拟网络架构提供的成本优点对较大的神经网络更加明显。此外,神经网络的模拟硬件实现提供了提高的并行性和神经形态。此外,神经形态模拟部件当与数字对应物相比时对噪声和温度变化不敏感。
8.根据本文描述的技术制造的芯片在尺寸、功率和性能方面提供优于传统系统的数量级改进,并且对于边缘环境(包括对于再训练目的)是理想的。这样的模拟神经形态芯片
可以用于实现边缘计算应用或用在物联网(iot)环境中。由于模拟硬件,可以消耗超过80-90%的功率的初步处理(例如,用于图像识别的描述符的形成)可以在芯片上移动,从而降低能量消耗和网络负载,这可以打开新的应用市场。
9.各种边缘应用可以受益于这样的模拟硬件的使用。例如,对于视频处理,本文描述的技术可以用于包括到cmos传感器的直接连接而无需数字接口。各种其他视频处理应用包括汽车的路标识别、用于机器人的基于摄像机的真实深度和/或同步定位和地图构建、没有服务器连接的房间访问控制以及对安全和医疗保健的始终在线解决方案。这样的芯片可以用于雷达和激光雷达的数据处理以及用于低水平数据融合。这样的技术可以用于实现大型电池组的电池管理功能、没有到数据中心的连接的声音/语音处理、在移动设备上的语音识别、iot传感器的唤醒语音指令、将一种语言翻译成另一种语言的翻译器、具有低信号强度的iot的大型传感器阵列和/或具有数百个传感器的可配置过程控制。
10.根据一些实现,神经形态模拟芯片可以在标准的基于软件的神经网络仿真/训练之后被大规模生产。客户端的神经网络可以用定制的芯片设计和生产被容易移植,而不管神经网络的结构如何。此外,根据一些实现,提供了准备好制作片上解决方案(网络仿真器)的库。这样的解决方案只需要训练一次光刻掩模更换,其后芯片可以被大规模生产。例如,在芯片生产期间,只有部分的光刻掩模需要被更换。
11.本文描述的技术可以用于设计和/或制造在数学上等效于训练后的神经网络(前馈或者循环神经网络)的模拟神经形态集成电路。根据一些实现,该过程以训练后的神经网络开始,该神经网络首先被变换成由标准元件组成的经变换的网络。使用具有代表标准元件的已知模型的软件来仿真经变换的网络的操作。软件仿真用于确定在经变换的网络中的每个电阻器的单独电阻值。基于在经变换的网络中的标准元件的排列来布置光刻掩模。使用与标准元件对应的电路的现有库来将每个标准元件布置在掩模中以简化和加快该过程。在一些实现中,电阻器布置在与包括经变换的网络中的其他元件(例如运算放大器)的掩模分离的一个或更多个掩模中。以这种方式,如果神经网络被再训练,则只有包含表示在再训练后的神经网络中的新权重的电阻器或其他类型的固定电阻元件的掩模需要被重新生成,这简化并加快了该过程。光刻掩模然后被发送到晶圆厂(fab)用于制造模拟神经形态集成电路。
12.在一个方面中,根据一些实现,提供了一种用于神经网络的硬件实现的方法。该方法包括获得训练后的神经网络的神经网络拓扑和权重。该方法还包括将神经网络拓扑变换成模拟部件的等效模拟网络。该方法还包括基于训练后的神经网络的权重来计算等效模拟网络的权重矩阵。权重矩阵的每个元素表示在等效模拟网络的模拟部件之间的相应连接。该方法还包括基于权重矩阵来生成用于实现等效模拟网络的示意性模型,包括选择模拟部件的部件值。
13.在一些实现中,生成示意性模型包括生成针对权重矩阵的电阻矩阵。电阻矩阵的每个元素对应于权重矩阵的相应权重,并表示电阻值。
14.在一些实现中,该方法还包括获得用于训练后的神经网络的新权重,基于新权重来计算用于等效模拟网络的新权重矩阵以及生成针对新权重矩阵的新电阻矩阵。
15.在一些实现中,神经网络拓扑包括一层或更多层神经元,每层神经元基于相应数学函数来计算相应的输出,并且将神经网络拓扑变换成模拟部件的等效模拟网络包括:对
于一层或更多层神经元中的每层:(i)针对相应层基于相应数学函数识别一个或更多个函数块。每个函数块有相应示意实现,该相应示意实现具有符合相应数学函数的输出的块输出;以及(ii)基于排列一个或更多个函数块来生成模拟神经元的相应多层网络。每个模拟神经元实现一个或更多个函数块的相应函数,并且多层网络的第一层的每个模拟神经元连接到多层网络的第二层的一个或更多个模拟神经元。
16.在一些实现中,一个或更多个函数块包括选自由下列项组成的组的一个或更多个基本函数块:(i)具有块输出v
out
=relu(∑wi.v
iin
bias)的加权求和块,relu是修正线性单元(relu)激活函数或类似的激活函数,vi表示第i个输入,wi表示对应于第i个输入的权重,以及bias表示偏差值,并且∑是求和运算符;(ii)具有块输出v
out
=coeff.vi.vj的信号乘法器块,vi表示第i个输入,以及vj表示第j个输入,并且coeff是预定系数;(iii)具有块输出的sigmoid(s型)激活块,v表示输入,以及a和b是sigmoid激活块的预定系数值;(iv)具有块输出v
out
=a*tanh(b*v
in
)的双曲正切激活块,v
in
表示输入,以及a和b为预定系数值;以及(v)具有块输出u(t)=v(t-dt)的信号延迟块,t表示当前时间段,v(t-dt)表示前一时间段t-dt的信号延迟块的输出,以及dt是延迟值。
17.在一些实现中,识别一个或更多个函数块包括基于相应层的类型来选择一个或更多个函数块。
18.在一些实现中,神经网络拓扑包括一层或更多层神经元,每层神经元基于相应数学函数来计算相应的输出,并且将神经网络拓扑变换成模拟部件的等效模拟网络包括:(i)将神经网络拓扑的第一层分解成多个子层,包括分解对应于第一层的数学函数以获得一个或更多个中间数学函数。每个子层实现一个中间数学函数;以及(ii)对于神经网络拓扑的第一层的每个子层:(a)针对相应子层基于相应的中间数学函数选择一个或更多个子函数块;以及(b)基于排列一个或更多个子函数块来生成模拟神经元的相应多层模拟子网。每个模拟神经元实现一个或更多个子函数块的相应函数,并且多层模拟子网的第一层的每个模拟神经元连接到多层模拟子网的第二层的一个或更多个模拟神经元。
19.在一些实现中,对应于第一层的数学函数包括一个或更多个权重,并且分解数学函数包括调整一个或更多个权重,使得组合一个或更多个中间函数产生数学函数。
20.在一些实现中,该方法还包括:(i)针对神经网络拓扑的一个或更多个输出层生成数字部件的等效数字网络;以及(ii)将等效模拟网络的一层或更多层的输出连接到数字部件的等效数字网络。
21.在一些实现中,模拟部件包括多个运算放大器和多个电阻器,每个运算放大器表示等效模拟网络的模拟神经元,以及每个电阻器表示在两个模拟神经元之间的连接。
22.在一些实现中,选择模拟部件的部件值包括执行梯度下降方法以识别对于多个电阻器的可能电阻值。
23.在一些实现中,神经网络拓扑包括一个或更多个gru或lstm神经元,并且变换神经网络拓扑包括针对一个或更多个gru或lstm神经元的每个循环连接生成一个或更多个信号延迟块。
24.在一些实现中,一个或更多个信号延迟块以与神经网络拓扑的预定输入信号频率匹配的频率被激活。
25.在一些实现中,神经网络拓扑包括执行无限激活函数的一层或更多层神经元,并且变换神经网络拓扑包括应用选自由下列项组成的组的一个或更多个变换:(i)用有限激活代替无限激活函数;以及(ii)调整等效模拟网络的连接或权重,使得对于预定的一个或更多个输入,在训练后的神经网络和等效模拟网络之间的输出中的差异被最小化。
26.在一些实现中,该方法还包括基于电阻矩阵来生成用于制造实现模拟部件的等效模拟网络的电路的一个或更多个光刻掩模。
27.在一些实现中,该方法还包括:(i)获得用于训练后的神经网络的新权重;(ii)基于新权重来计算等效模拟网络的新权重矩阵;(iii)针对新权重矩阵生成新电阻矩阵;以及(iv)基于新电阻矩阵来生成用于制造实现模拟部件的等效模拟网络的电路的新光刻掩模。
28.在一些实现中,使用软件仿真来对训练后的神经网络进行训练以生成权重。
29.在另一方面中,根据一些实现,提供了一种用于神经网络的硬件实现的方法。该方法包括获得训练后的神经网络的神经网络拓扑和权重。该方法还包括基于模拟集成电路(ic)设计约束来计算一个或更多个连接约束。该方法还包括将神经网络拓扑变换成满足一个或更多个连接约束的模拟部件的等效稀疏连接网络。该方法还包括基于训练后的神经网络的权重来计算等效稀疏连接网络的权重矩阵。权重矩阵的每个元素表示在等效稀疏连接网络的模拟部件之间的相应连接。
30.在一些实现中,将神经网络拓扑变换成模拟部件的等效稀疏连接网络包括根据一个或更多个连接约束来导出可能的输入连接度ni和输出连接度no。
31.在一些实现中,神经网络拓扑包括具有k个输入和l个输出以及权重矩阵u的至少一个密集连接层。在这样的情况下,变换至少一个密集连接层包括构建具有k个输入、l个输出和个层的等效稀疏连接网络,使得输入连接度不超过ni,并且输出连接度不超过no。
32.在一些实现中,神经网络拓扑包括具有k个输入和l个输出以及权重矩阵u的至少一个密集连接层。在这样的情况下,变换至少一个密集连接层包括构建具有k个输入、l个输出、输出和个层的等效稀疏连接网络。每个层m由对应的权重矩阵um表示,其中缺少的连接用零表示,使得输入连接度不超过ni,并且输出连接度不超过no。方程u=π
m=1..m
um以预定精度被满足。
33.在一些实现中,神经网络拓扑包括具有k个输入和l个输出、最大输入连接度pi、最大输出连接度po以及权重矩阵u的单个稀疏连接层,其中缺少的连接用零表示。在这样的情况下,变换单个稀疏连接层包括构建具有k个输入、l个输出、个层的等效稀疏连接层,每个层m由对应的权重矩阵um表示,其中缺少的连接用零表示,使得输入连接度不超过ni,并且输出连接度不超过no。方程u=π
m=1..m
um以预定精度被满足。
34.在一些实现中,神经网络拓扑包括具有k个输入和l个输出的卷积层。在这样的情况下,将神经网络拓扑变换成模拟部件的等效稀疏连接网络包括将卷积层分解成具有k个输入、l个输出、最大输入连接度pi和最大输出连接度po的单个稀疏连接层。pi≤ni并且po≤no。
35.在一些实现中,利用权重矩阵生成用于实现等效稀疏连接网络的示意性模型。
36.在一些实现中,神经网络拓扑包括循环神经层。在这样的情况下,将神经网络拓扑
变换成模拟部件的等效稀疏连接网络包括将循环神经层变换成具有信号延迟连接的一个或更多个密集或稀疏连接层。
37.在一些实现中,神经网络拓扑包括循环神经层。在这样的情况下,将神经网络拓扑变换成模拟部件的等效稀疏连接网络包括将循环神经层分解成若干层,其中层中的至少一个等效于具有k个输入和l个输出以及权重矩阵u的密集或稀疏连接层,其中缺少的连接用零表示。
38.在一些实现中,神经网络拓扑包括k个输入、权重向量u∈rk和具有计算神经元的单层感知器,该计算神经元具有激活函数f。在这样的情况下,将神经网络拓扑变换成模拟部件的等效稀疏连接网络包括:(i)根据一个或更多个连接约束导出等效稀疏连接网络的连接度n;(ii)使用方程计算等效稀疏连接网络的层的数量m;以及(iii)构建具有k个输入、m个层和连接度n的等效稀疏连接网络。等效稀疏连接网络在m个层中的每个层中包括相应的一个或更多个模拟神经元,前m-1个层的每个模拟神经元实现恒等变换,且最后一层的模拟神经元实现单层感知器的计算神经元的激活函数f。此外,在这样的情况下,计算等效稀疏连接网络的权重矩阵包括通过基于权重向量u对方程组求解来计算等效稀疏连接网络的连接的权重向量w。方程组包括具有s个变量的k个方程,并且s使用方程被计算。
39.在一些实现中,神经网络拓扑包括k个输入、具有l个计算神经元的单层感知器以及包括对于l个计算神经元中的每个计算神经元的一行权重的权重矩阵v。在这样的情况下,将神经网络拓扑变换成模拟部件的等效稀疏连接网络包括:(i)根据一个或更多个连接约束导出等效稀疏连接网络的连接度n;(ii)使用方程计算等效稀疏连接网络的层的数量m;(iii)将单层感知器分解成l个单层感知器网络。每个单层感知器网络包括l个计算神经元中的相应计算神经元;(iv)对于l个单层感知器网络中的每个单层感知器网络:(a)为相应单层感知器网络构建具有k个输入、m个层和连接度n的相应等效金字塔状子网。等效金字塔状子网在m个层中的每个层中包括一个或更多个相应模拟神经元,前m-1个层的每个模拟神经元实现恒等变换,且最后一层的模拟神经元实现对应于相应单层感知器的相应计算神经元的激活函数;以及(b)通过将每个等效金字塔状子网连接在一起(包括将l个单层感知器网络的每个等效金字塔状子网的输入连接在一起以形成具有l*k个输入的输入向量)来构建等效稀疏连接网络。此外,在这样的情况下,计算等效稀疏连接网络的权重矩阵包括对于l个单层感知器网络中的每个单层感知器网络:(i)设定权重向量u=vi,权重矩阵v的第i行对应于相应计算神经元,相应计算神经元对应于相应单层感知器网络;以及(ii)通过基于权重向量u对方程组求解来计算相应等效金字塔状子网的连接的权重向量wi。该方程组包括具有s个变量的k个方程,并且s使用方程被计算。
40.在一些实现中,神经网络拓扑包括k个输入、具有s个层的多层感知器,s个层中的每个层i包括一组对应的计算神经元li和对应的权重矩阵vi,权重矩阵vi包括li个计算神经元中的每个计算神经元的一行权重。在这样的情况下,将神经网络拓扑变换成模拟部件的等效稀疏连接网络包括:(i)根据一个或更多个连接约束导出等效稀疏连接网络的连接度n;(ii)将多层感知器分解成q=∑
i=1,s
(li)个单层感知器网络。每个单层感知器网络包括q
个计算神经元中的相应计算神经元。分解多层感知器包括复制由q个计算神经元共享的k个输入中的一个或更多个输入;(iii)对于q个单层感知器网络中的每个单层感知器网络:(a)使用方程计算相应等效金字塔状子网的层的数量m。k
i,j
是在多层感知器中的相应计算神经元的输入的数量;以及(b)为相应单层感知器网络构建具有k
i,j
个输入、m个层和连接度n的相应等效金字塔状子网。等效金字塔状子网在m个层中的每个层中包括一个或更多个相应模拟神经元,前m-1个层的每个模拟神经元实现恒等变换,并且最后一层的模拟神经元实现对应于相应单层感知器网络的相应计算神经元的激活函数;以及(iv)通过将每个等效金字塔状子网连接在一起来构建等效稀疏连接网络,包括将q个单层感知器网络的每个等效金字塔状子网的输入连接在一起以形成具有q*k
i,j
个输入的输入向量。此外,在这样的情况下,计算等效稀疏连接网络的权重矩阵包括:对于q个单层感知器网络中的每个单层感知器网络:(i)设定权重向量u=v
ij
,权重矩阵v的第i行对应于相应计算神经元,相应计算神经元对应于相应单层感知器网络,其中j是在多层感知器中的相应计算神经元的对应层;以及(ii)通过基于权重向量u对方程组求解来计算相应等效金字塔状子网的连接的权重向量wi。方程组包括具有s个变量的k
i,j
个方程,并且s使用方程被计算。
41.在一些实现中,神经网络拓扑包括具有k个输入、s个层的卷积神经网络(cnn),s个层中的每个层i包括一组对应的计算神经元li和对应的权重矩阵vi,权重矩阵vi包括对于li个计算神经元中的每个计算神经元的一行权重。在这样的情况下,将神经网络拓扑变换成模拟部件的等效稀疏连接网络包括:(i)根据一个或更多个连接约束导出等效稀疏连接网络的连接度n;(ii)将cnn分解成q=∑
i=1,s
(li)个单层感知器网络。每个单层感知器网络包括q个计算神经元中的相应计算神经元。分解cnn包括复制由q个计算神经元共享的k个输入中的一个或更多个输入;(iii)对于q个单层感知器网络中的每个单层感知器网络:(a)使用方程计算相应等效金字塔状子网的层的数量m。j是在cnn中的相应计算神经元的对应层,以及k
i,j
是在cnn中的相应计算神经元的输入的数量;以及(b)为相应单层感知器网络构建具有k
i,j
个输入、m个层和连接度n的相应等效金字塔状子网。等效金字塔状子网在m个层中的每个层中包括一个或更多个相应模拟神经元,前m-1个层的每个模拟神经元实现恒等变换,并且最后一层的模拟神经元实现对应于相应单层感知器网络的相应计算神经元的激活函数;以及(iv)通过将每个等效金字塔状子网连接在一起来构建等效稀疏连接网络,包括将q个单层感知器网络的每个等效金字塔状子网的输入连接在一起以形成具有q*k
i,j
个输入的输入向量。此外,在这样的情况下,计算等效稀疏连接网络的权重矩阵包括:对于q个单层感知器网络中的每个单层感知器网络:(i)设定权重向量u=v
ij
,权重矩阵v的第i行对应于相应计算神经元,相应计算神经元对应于相应单层感知器网络,其中j是在cnn中的相应计算神经元的对应层;以及(ii)通过基于权重向量u对方程组求解来计算相应等效金字塔状子网的连接的权重向量wi。方程组包括具有s个变量的k
i,j
个方程,并且s使用方程被计算。
42.在一些实现中,神经网络拓扑包括k个输入、具有k个神经元的层l
p
、具有l个神经
元的层ln和权重矩阵w∈r
l
×k,其中r是实数的集合,层l
p
的每个神经元连接到层ln的每个神经元,层ln的每个神经元执行激活函数f,使得层ln的输出使用输入x的方程yo=f(w.x)被计算。在这样的情况下,将神经网络拓扑变换成模拟部件的等效稀疏连接网络包括执行梯形变换,该梯形变换包括:(i)根据一个或更多个连接约束导出可能的输入连接度ni》1和可能的输出连接度no》1;(ii)根据k
·
l《l
·
ni k
·
no的确定,构建包括具有执行恒等激活函数的k个模拟神经元的层la
p
、具有执行恒等激活函数的个模拟神经元的层lah和具有执行激活函数f的l个模拟神经元的层lao的三层模拟网络,使得在层la
p
中的每个模拟神经元具有no个输出,在层lah中的每个模拟神经元具有不多于ni个输入和no个输出,以及在层lao中的每个模拟神经元具有ni个输入。此外,在这样的情况下,计算等效稀疏连接网络的权重矩阵包括通过对矩阵方程wo.wh=w求解来生成稀疏权重矩阵wo和wh,该矩阵方程wo.wh=w包括采用k
·
no l
·
ni个变量的k
·
l个方程,使得层lao的总输出使用方程yo=f(wo.wh.x)被计算。稀疏权重矩阵wo∈rk×m表示在层la
p
和lah之间的连接,以及稀疏权重矩阵wh∈rm×
l
表示在层lah和lao之间的连接。
43.在一些实现中,执行梯形变换还包括:根据k
·
l≥l
·
ni k
·
no的确定:(i)使层l
p
分裂以获得具有k’个神经元的子层l
p1
和具有(k-k’)个神经元的子层l
p2
,使得k
′
·
l≥l
·
ni k
′
·
no;(ii)对于具有k’个神经元的子层l
p1
,执行构建和生成步骤;以及(iii)对于具有k-k’个神经元的子层l
p2
,循环地执行分裂、构建和生成步骤。
44.在一些实现中,神经网络拓扑包括多层感知器网络。在这样的情况下,该方法还包括,对于多层感知器网络的每对连续层,迭代地执行梯形变换并计算等效稀疏连接网络的权重矩阵。
45.在一些实现中,神经网络拓扑包括循环神经网络(rnn),其包括(i)两个完全连接层的线性组合的计算,(ii)逐元素相加,以及(iii)非线性函数计算。在这样的情况下,该方法还包括执行梯形变换并计算等效稀疏连接网络的权重矩阵,用于(i)两个完全连接层,和(ii)非线性函数计算。
46.在一些实现中,神经网络拓扑包括长短期记忆(lstm)网络或门控循环单元(gru)网络,其包括(i)多个完全连接层的线性组合的计算,(ii)逐元素相加,(iii)hadamard乘积,以及(iv)多个非线性函数计算。在这样的情况下,该方法还包括执行梯形变换并计算等效稀疏连接网络的权重矩阵,用于(i)多个完全连接层,和(ii)多个非线性函数计算。
47.在一些实现中,神经网络拓扑包括卷积神经网络(cnn),其包括(i)多个部分连接层和(ii)一个或更多个完全连接层。在这样的情况下,该方法还包括:(i)通过插入具有零权重的丢失连接来将多个部分连接层变换成等效完全连接层;以及(ii)对于等效完全连接层和一个或更多个完全连接层的每对连续层,迭代地执行梯形变换并计算等效稀疏连接网络的权重矩阵。
48.在一些实现中,神经网络拓扑包括k个输入、l个输出神经元和权重矩阵u∈r
l
×k,其中r是实数的集合,每个输出神经元执行激活函数f。在这样的情况下,将神经网络拓扑变换成模拟部件的等效稀疏连接网络包括执行近似变换,该近似变换包括:(i)根据一个或更多个连接约束导出可能的输入连接度ni》1和可能的输出连接度no》1;(ii)从集合中选择参数p;(iii)根据p》0的确定,构建形成等效稀疏连接网络
的前p个层的金字塔神经网络,使得金字塔神经网络在它的输出层中具有个神经元。金字塔神经网络中的每个神经元执行恒等函数;以及(iv)构建具有n
p
个输入和l个输出的梯形神经网络。梯形神经网络的最后一层中的每个神经元执行激活函数f,以及所有其他神经元执行恒等函数。在这样的情况下,计算等效稀疏连接网络的权重矩阵包括:(i)生成金字塔神经网络的权重,包括(a)根据下面的规则设定金字塔神经网络的第一层的每个神经元i的权重:c为非零常数,以及ki=(i-1)ni 1;和(b)对于除ki之外的神经元的所有权重j,以及(b)将金字塔神经网络的所有其他权重设定为1;以及(ii)生成梯形神经网络的权重,包括(a)根据方程设定梯形神经网络的第一层的每个神经元i的权重;以及(b)将梯形神经网络的其他权重设定为1。
49.在一些实现中,神经网络拓扑包括具有k个输入、s个层和在第i层中的l
i=1,s
个计算神经元以及对于第i层的权重矩阵的多层感知器,其中l0=k。在这样的情况下,将神经网络拓扑变换成模拟部件的等效稀疏连接网络包括:对于多层感知器的s个层中的每个层j:(i)通过对由l
j-1
个输入、lj个输出神经元和权重矩阵uj组成的相应单层感知器执行近似变换来构建相应金字塔-梯形网络ptnnxj;以及(ii)通过堆叠每个金字塔梯形网络来构建等效稀疏连接网络。
50.在另一方面中,根据一些实现,提供了一种用于神经网络的硬件实现的方法。该方法包括获得训练后的神经网络的神经网络拓扑和权重。该方法还包括将神经网络拓扑变换成包括多个运算放大器和多个电阻器的模拟部件的等效模拟网络。每个运算放大器表示等效模拟网络的模拟神经元,且每个电阻器表示在两个模拟神经元之间的连接。该方法还包括基于训练后的神经网络的权重来计算等效模拟网络的权重矩阵。权重矩阵的每个元素表示相应连接。该方法还包括针对权重矩阵生成电阻矩阵。电阻矩阵的每个元素对应于权重矩阵的相应权重,并表示电阻值。
51.在一些实现中,针对权重矩阵生成电阻矩阵包括:(i)获得可能电阻值的预定范围{r
min
,r
max
}并选择在预定范围内的初始基本(base)电阻值r
基本
;(ii)在预定范围内选择电阻值的有限长度集合,电阻值对于在电阻值的有限长度集合内的{ri,rj}的所有组合提供了在范围[-r
基本
,r
基本
]内的可能权重的最均匀的分布;(iii)基于每个神经元或等效模拟网络的每个层的传入连接的最大权重和偏差w
max
,针对每个模拟神经元或者针对等效模拟网络的每个层从电阻值的有限长度集合中选择电阻值r
=r-,使得r
=r-是最接近于r
基本
*w
max
的电阻器设定值;以及(iv)对于权重矩阵的每个元素,在可能电阻值的预定范围内的r1和r2的所有可能值中,选择根据方程最小化误差的相应的第一电阻值r1和相应的第二电阻值r2。w是权重矩阵的相应元素,以及r
err
是电阻的预定相对公差值。
[0052]
在一些实现中,可能电阻值的预定范围包括在范围100kω至1mω中根据标称系列e24的电阻。
[0053]
在一些实现中,r
和r-是针对等效模拟网络的每个层独立地选择的。
[0054]
在一些实现中,r
和r-是针对等效模拟网络的每个模拟神经元独立地选择的。
[0055]
在一些实现中,权重矩阵的第一一个或更多个权重和第一一个或更多个输入表示到等效模拟网络的第一运算放大器的一个或更多个连接。在这样的情况下,该方法还包括在生成电阻矩阵之前:(i)通过第一值修改第一一个或更多个权重;以及(ii)在执行激活函数之前配置第一运算放大器以使第一一个或更多个权重和第一一个或更多个输入的线性组合乘以第一值。
[0056]
在一些实现中,该方法还包括:(i)获得预定范围的权重;以及(ii)根据预定范围的权重更新权重矩阵,使得对于相同的输入,等效模拟网络产生与训练后的神经网络相似的输出。
[0057]
在一些实现中,训练后的神经网络被训练,使得神经网络拓扑的每个层具有量化的权重。
[0058]
在一些实现中,该方法还包括对训练后的神经网络进行再训练以降低对权重或电阻值中的误差的敏感度,误差使等效模拟网络产生与训练后的神经网络相比不同的输出。
[0059]
在一些实现中,该方法还包括对训练后的神经网络进行再训练,以便使在任何层中的权重最小化,该权重比该层的平均绝对权重大了预定阈值。
[0060]
在另一方面中,根据一些实现,提供了一种用于神经网络的硬件实现的方法。该方法包括获得训练后的神经网络的神经网络拓扑和权重。该方法还包括将神经网络拓扑变换成包括多个运算放大器和多个电阻器的模拟部件的等效模拟网络。每个运算放大器表示等效模拟网络的模拟神经元,以及每个电阻器表示在两个模拟神经元之间的连接。该方法还包括基于训练后的神经网络的权重来计算等效模拟网络的权重矩阵。权重矩阵的每个元素表示相应连接。该方法还包括针对权重矩阵生成电阻矩阵。电阻矩阵的每个元素对应于权重矩阵的相应权重。该方法还包括基于电阻矩阵修剪等效模拟网络以减少多个运算放大器或多个电阻器的数量,以获得模拟部件的优化模拟网络。
[0061]
在一些实现中,修剪等效模拟网络包括用导体替换与电阻矩阵中的具有低于预定最小阈值电阻值的电阻值的一个或更多个元素对应的电阻器。
[0062]
在一些实现中,修剪等效模拟网络包括移除等效模拟网络的、与电阻矩阵中的高于预定最大阈值电阻值的一个或更多个元素对应的一个或更多个连接。
[0063]
在一些实现中,修剪等效模拟网络包括移除等效模拟网络的、与权重矩阵中的近似为零的一个或更多个元素对应的一个或更多个连接。
[0064]
在一些实现中,修剪等效模拟网络还包括移除等效模拟网络的没有任何输入连接的一个或更多个模拟神经元。
[0065]
在一些实现中,修剪等效模拟网络包括:(i)当对一个或更多个数据集进行计算时,基于检测到模拟神经元的使用来对等效模拟网络的模拟神经元排名(ranking);(ii)基于排名来选择等效模拟网络的一个或更多个模拟神经元;以及(iii)从等效模拟网络移除该一个或更多个模拟神经元。
[0066]
在一些实现中,检测到模拟神经元的使用包括:(i)使用建模软件来建立等效模拟网络的模型;以及(ii)通过使用模型以生成一个或更多个数据集的计算来测量模拟信号的传播。
[0067]
在一些实现中,检测到模拟神经元的使用包括:(i)使用建模软件来建立等效模拟网络的模型;以及(ii)通过使用模型以生成一个或更多个数据集的计算来测量模型的输出信号。
[0068]
在一些实现中,检测到模拟神经元的使用包括:(i)使用建模软件来建立等效模拟网络的模型;以及(ii)通过使用模型以生成一个或更多个数据集的计算来测量由模拟神经元消耗的功率。
[0069]
在一些实现中,该方法还包括在修剪等效模拟网络之后并且在生成用于制造实现等效模拟网络的电路的一个或更多个光刻掩模之前,重新计算等效模拟网络的权重矩阵,并且基于重新计算的权重矩阵更新电阻矩阵。
[0070]
在一些实现中,该方法还包括:对于等效模拟网络的每个模拟神经元:(i)在计算权重矩阵的同时,基于训练后的神经网络的权重来计算相应模拟神经元的相应偏差值;(ii)根据相应偏差值高于预定最大偏差阈值的确定,从等效模拟网络移除相应模拟神经元;以及(iii)根据相应偏差值低于预定最小偏差阈值的确定,用等效模拟网络中的线性结(linear junction)替换相应模拟神经元。
[0071]
在一些实现中,该方法还包括在生成权重矩阵之前通过增加来自等效模拟网络的一个或更多个模拟神经元的连接的数量来减少等效模拟网络的神经元的数量。
[0072]
在一些实现中,该方法还包括在变换神经网络拓扑之前,使用神经网络的修剪技术来修剪训练后的神经网络,以更新训练后的神经网络的神经网络拓扑和权重,使得等效模拟网络包括少于预定数量的模拟部件。
[0073]
在一些实现中,考虑到在训练后的神经网络和等效模拟网络之间的输出中的匹配的准确度或水平,修剪被迭代地执行。
[0074]
在一些实现中,该方法还包括在将神经网络拓扑变换成等效模拟网络之前执行网络知识提取。
[0075]
在另一方面中,根据一些实现,提供了一种集成电路。该集成电路包括由一种方法制造的模拟部件的模拟网络,该方法包括:(i)获得训练后的神经网络的神经网络拓扑和权重;(ii)将神经网络拓扑变换成包括多个运算放大器和多个电阻器的模拟部件的等效模拟网络。每个运算放大器表示相应模拟神经元,以及每个电阻器表示在相应的第一模拟神经元和相应的第二模拟神经元之间的相应连接;(iii)基于训练后的神经网络的权重来计算等效模拟网络的权重矩阵,权重矩阵的每个元素表示相应连接;(iv)针对权重矩阵生成电阻矩阵。电阻矩阵的每个元素对应于权重矩阵的相应权重;(v)基于电阻矩阵来生成用于制造实现模拟部件的等效模拟网络的电路的一个或更多个光刻掩模;以及(vi)使用光刻工艺基于一个或更多个光刻掩模来制造电路。
[0076]
在一些实现中,集成电路还包括一个或更多个数模转换器,该数模转换器被配置为基于一个或更多个数字信号生成模拟部件的等效模拟网络的模拟输入。
[0077]
在一些实现中,集成电路还包括模拟信号采样模块,该模拟信号采样模块被配置为基于集成电路的推断(inference)的数量以某个采样频率来处理一维或二维模拟输入。
[0078]
在一些实现中,集成电路还包括电压转换器模块,该电压转换器模块按比例缩小或按比例放大模拟信号,以匹配多个运算放大器的操作范围。
[0079]
在一些实现中,集成电路还包括被配置为处理从ccd摄像机获得的一个或更多个
帧的触觉信号处理模块(tact signal processing module)。
[0080]
在一些实现中,训练后的神经网络是长短期记忆(lstm)网络。在这样的情况下,集成电路还包括一个或更多个时钟模块以使信号触觉同步并允许时间序列处理。
[0081]
在一些实现中,集成电路还包括被配置为基于模拟部件的等效模拟网络的输出来生成数字信号的一个或更多个模数转换器。
[0082]
在一些实现中,集成电路还包括被配置为处理从边缘应用获得的一维或二维模拟信号的一个或更多个信号处理模块。
[0083]
在一些实现中,使用包含针对不同气体混合物的气体传感器的阵列的信号的训练数据集来对训练后的神经网络进行训练,用于选择性地感测包含待检测的预定量的气体的气体混合物中的不同气体。在这样的情况下,神经网络拓扑是被设计用于基于由16个气体传感器进行的测量来检测3个二元气体成分的一维深度卷积神经网络(1d-dcnn),并且包括16个传感器式的1-d卷积块、3个共享或公共的1-d卷积块和3个密集层。在这样的情况下,等效模拟网络包括:(i)每模拟神经元最多100个输入和输出连接,(ii)延迟块,用于产生任何数量的时间步长的延迟,(iii)信号限制为5,(iv)15个层,(v)大约100,000个模拟神经元,以及(vi)大约4,900,000个连接。
[0084]
在一些实现中,使用包含对于不同mosfet的热老化时间序列数据的训练数据集来对训练后的神经网络进行训练,用于预测mosfet器件的剩余使用寿命(rul)。在这样的情况下,神经网络拓扑在每个层中包括有64个神经元的4个lstm层,后面是分别具有64个神经元和1个神经元的两个密集层。在这样的情况下,等效模拟网络包括:(i)每模拟神经元最多100个输入和输出连接,(ii)信号限制为5,(iii)18个层,(iv)3,000和3,200个之间的模拟神经元,以及(v)123,000和124,000个之间的连接。
[0085]
在一些实现中,使用包含时间序列数据的训练数据集来对训练后的神经网络进行训练,该时间序列数据包括在不同的市售li离子电池的连续使用期间的放电和温度数据,该训练用于监测锂离子电池的健康状态(soh)和充电状态(soc)以在电池管理系统(bms)中使用。在这样的情况下,神经网络拓扑包括一个输入层、在每个层中有64个神经元的2个lstm层,后面是具有用于生成soc和soh值的2个神经元的一个输出密集层。在这样的情况下,等效模拟网络包括:(i)每模拟神经元最多100个输入和输出连接,(ii)信号限制为5,(iii)9个层,(iv)1,200和1,300个之间的模拟神经元,以及(v)51,000和52,000个之间的连接。
[0086]
在一些实现中,使用包含时间序列数据的训练数据集来对训练后的神经网络进行训练,该时间序列数据包括在不同的市售li离子电池的连续使用期间的放电和温度数据,该训练用于监测锂离子电池的健康状态(soh)以在电池管理系统(bms)中使用。在这样的情况下,神经网络拓扑包括具有18个神经元的输入层、具有100个神经元的简单循环层和具有1个神经元的密集层。在这样的情况下,等效模拟网络包括:(i)每模拟神经元最多100个输入和输出连接,(ii)信号限制为5,(iii)4个层,(iv)200和300个之间的模拟神经元,以及(v)2,200和2,400个之间的连接。
[0087]
在一些实现中,使用包含语音命令的训练数据集来对训练后的神经网络进行训练,用于识别话音命令。在这样的情况下,神经网络拓扑是具有1个神经元的深度可分离卷积神经网络(ds-cnn)层。在这样的情况下,等效模拟网络包括:(i)每模拟神经元最多100个
输入和输出连接,(ii)信号限制为5,(iii)13个层,(iv)大约72,000个模拟神经元,以及(v)大约260万个连接。
[0088]
在一些实现中,使用包含针对在预定时间段内进行各种身体活动的不同个体的光电容积描记术(ppg)数据、加速度计数据、温度数据和皮肤电反应信号数据以及从ecg传感器获得的参考心率数据的训练数据集来对训练后的神经网络进行训练,用于基于ppg传感器数据和3轴加速度计数据来确定在身体锻炼期间的脉搏率。在这样的情况下,神经网络拓扑包括:两个conv1d层,每个层具有执行时间序列卷积的16个滤波器和20的内核;两个lstm层,每个层具有16个神经元;以及分别具有16个神经元和1个神经元的两个密集层。在这样的情况下,等效模拟网络包括:(i)延迟块,其产生任何数量的时间步长,(ii)每模拟神经元最多100个输入和输出连接,(iii)信号限制为5,(iv)16个层,(v)700和800个之间的模拟神经元,以及(vi)12,000和12,500个之间的连接。
[0089]
在一些实现中,训练后的神经网络被训练以基于脉冲多普勒雷达信号对不同的对象分类。在这样的情况下,神经网络拓扑包括多尺度lstm神经网络。
[0090]
在一些实现中,训练后的神经网络被训练以基于惯性传感器数据来执行人类活动类型识别。在这样的情况下,神经网络拓扑包括三个通道式(channel-wise)卷积网络,每个通道式卷积网络具有12个滤波器和64的内核尺寸的卷积层,以及每个卷积层后面是最大池化(max pooling)层,以及分别具有1024个神经元和n个神经元的两个公共密集层,其中n是类别的数量。在这样的情况下,等效模拟网络包括:(i)延迟块,其产生任何数量的时间步长,(ii)每模拟神经元最多100个输入和输出连接,(iii)10个模拟神经元的输出层,(iv)信号限制为5,(v)10个层,(vi)1,200和1,300个之间的模拟神经元,以及(vi)20,000到21,000个之间的连接。
[0091]
在一些实现中,训练后的神经网络被进一步训练以基于使用卷积运算与心率数据合并的加速度计数据来检测人类活动的异常模式。
[0092]
在另一方面中,提供了一种用于生成神经网络的硬件实现的库的方法。该方法包括获得多个神经网络拓扑,每个神经网络拓扑对应于相应的神经网络。该方法还包括将每个神经网络拓扑变换成模拟部件的相应等效模拟网络。该方法还包括生成用于制造多个电路的多个光刻掩模,每个电路实现模拟部件的相应等效模拟网络。
[0093]
在一些实现中,该方法还包括获得训练后的神经网络的新神经网络拓扑和权重。该方法还包括基于新神经网络拓扑与多个神经网络拓扑的比较从多个光刻掩模中选择一个或更多个光刻掩模。该方法还包括基于权重来计算新等效模拟网络的权重矩阵。该方法还包括针对权重矩阵生成电阻矩阵。该方法还包括基于电阻矩阵和一个或更多个光刻掩模生成用于制造实现新等效模拟网络的电路的新光刻掩模。
[0094]
在一些实现中,新神经网络拓扑包括多个子网拓扑,并且选择一个或更多个光刻掩模进一步基于每个子网拓扑与多个网络拓扑中的每个网络拓扑的比较。
[0095]
在一些实现中,多个子网拓扑中的一个或更多个子网拓扑未能与多个网络拓扑中的任何网络拓扑比较。在这样的情况下,该方法还包括:(i)将一个或更多个子网拓扑的每个子网拓扑变换成模拟部件的相应等效模拟子网;以及(ii)生成用于制造一个或更多个电路的一个或更多个光刻掩模,一个或更多个电路的每个电路实现模拟部件的相应等效模拟子网。
[0096]
在一些实现中,将相应网络拓扑变换成相应等效模拟网络包括:(i)将相应网络拓扑分解成多个子网拓扑;(ii)将每个子网拓扑变换成模拟部件的相应等效模拟子网;以及(iii)组合每个等效模拟子网以获得相应等效模拟网络。
[0097]
在一些实现中,分解相应网络拓扑包括将相应网络拓扑的一个或更多个层识别为多个子网拓扑。
[0098]
在一些实现中,通过下列操作来获得每个电路:(i)生成模拟部件的相应等效模拟网络的电路图(schematics);以及(ii)基于该电路图生成相应的电路布局设计。
[0099]
在一些实现中,该方法还包括在生成用于制造多个电路的多个光刻掩模之前组合一个或更多个电路布局设计。
[0100]
在另一方面中,根据一些实现,提供了一种用于优化模拟神经形态电路的能量效率的方法。该方法包括获得实现模拟部件的模拟网络的集成电路,模拟部件包括多个运算放大器和多个电阻器。模拟网络表示训练后的神经网络,每个运算放大器表示相应模拟神经元,以及每个电阻器表示在相应的第一模拟神经元和相应的第二模拟神经元之间的相应连接。该方法还包括使用集成电路针对多个测试输入生成推断,包括同时将信号从模拟网络的一层传输到下一层。该方法还包括,当使用集成电路生成推断时:(i)确定多个运算放大器的信号输出电平是否被平衡;以及(ii)根据信号输出电平被平衡的确定来:(a)确定影响用于信号的传播的信号形成的模拟网络的模拟神经元的活动集合(active set);以及在预定时间段内,为模拟网络的不同于模拟神经元的活动集合的一个或更多个模拟神经元关闭电源。
[0101]
在一些实现中,基于计算穿过模拟网络的信号传播的延迟来确定模拟神经元的活动集合。
[0102]
在一些实现中,基于检测到信号穿过模拟网络的传播来确定模拟神经元的活动集合。
[0103]
在一些实现中,训练后的神经网络是前馈神经网络,以及模拟神经元的活动集合属于模拟网络的活动层,并且关闭电源包括在模拟网络的活动层之前为一个或更多个层关闭电源。
[0104]
在一些实现中,考虑信号延迟,基于对信号穿过模拟网络的传播进行仿真来计算预定时间段。
[0105]
在一些实现中,训练后的神经网络是循环神经网络(rnn),以及模拟网络还包括除多个运算放大器和多个电阻器之外的一个或更多个模拟部件。在这样的情况下,该方法还包括,根据信号输出电平被平衡的确定,在预定时间段内为一个或更多个模拟部件关闭电源。
[0106]
在一些实现中,该方法还包括在预定时间段之后为模拟网络的一个或更多个模拟神经元接通电源。
[0107]
在一些实现中,确定多个运算放大器的信号输出电平是否被平衡基于检测模拟网络的一个或更多个运算放大器是否输出大于预定阈值的信号电平。
[0108]
在一些实现中,该方法还包括在生成推断时重复在预定时间段内关闭和在预定时间段内开启模拟神经元的活动集合。
[0109]
在一些实现中,该方法还包括:(i)根据信号输出电平被平衡的确定,对于每个推
断循环:(a)在第一时间间隔期间,确定影响用于信号的传播的信号形成的模拟网络的第一层模拟神经元;以及(b)在预定时间段内在该第一层之前为模拟网络的第一一个或更多个模拟神经元关闭电源;以及(ii)在第一时间间隔之后的第二时间间隔期间,在预定时间段内为第二一个或更多个模拟神经元关闭电源,该第二一个或更多个模拟神经元包括模拟网络的第一层模拟神经元和第一一个或更多个模拟神经元。
[0110]
在一些实现中,一个或更多个模拟神经元由模拟网络的第一一个或更多个层的模拟神经元组成,以及模拟神经元的活动集合由模拟网络的第二层的模拟神经元组成,并且模拟网络的第二层不同于第一一个或更多个层中的层。
[0111]
在一些实现中,计算机系统具有一个或更多个处理器、存储器和显示器。一个或更多个程序包括用于执行本文所述的任何方法的指令。
[0112]
在一些实现中,一种非暂时性计算机可读存储介质存储被配置为由具有一个或更多个处理器、存储器和显示器的计算机系统执行的一个或更多个程序。一个或更多个程序包括用于执行本文所述的任何方法的指令。
[0113]
因此,公开了用于训练后的神经网络的硬件实现的方法、系统和设备。
[0114]
附图简述
[0115]
为了对前面提到的系统、方法和图形用户界面以及提供数据可视化分析法和数据准备的额外系统、方法和图形用户界面的更好理解,应结合随附的附图来参考下面的实现的描述,在附图中相似的参考数字在全部附图中指代对应的部分。
[0116]
图1a是根据一些实现的用于使用模拟部件的训练后的神经网络的硬件实现的系统的框图。图1b是根据一些实现的用于使用模拟部件的训练后的神经网络的硬件实现的图1a的系统的替代表示的框图。图1c是根据一些实现的用于使用模拟部件的训练后的神经网络的硬件实现的图1a的系统的另一表示的框图。
[0117]
图2a是根据一些实现的计算设备的系统图。图2b示出了根据一些实现的计算设备的可选模块。
[0118]
图3a示出了根据一些实现的用于生成对应于训练后的神经网络的模拟网络的示意性模型的示例过程。图3b示出了根据一些实现的用于生成目标芯片模型的示例人工原型制作过程(manual prototyping process)。
[0119]
图4a、图4b和图4c示出了根据一些实现的被变换成数学上的等效模拟网络的神经网络的例子。
[0120]
图5示出了根据一些实现的神经元的数学模型的例子。
[0121]
图6a-6c示出了根据一些实现的用于计算输入值的异或(xor)的神经网络的模拟硬件实现的示例过程。
[0122]
图7示出了根据一些实现的示例感知器。
[0123]
图8示出了根据一些实现的示例金字塔神经网络。
[0124]
图9示出了根据一些实现的示例金字塔单神经网络。
[0125]
图10示出了根据一些实现的经变换的神经网络的例子。
[0126]
图11a-11c示出了根据一些实现的单层神经网络的t变换算法的应用。
[0127]
图12示出了根据一些实现的示例循环神经网络(rnn)。
[0128]
图13a是根据一些实现的lstm神经元的框图。
[0129]
图13b示出了根据一些实现的延迟块。
[0130]
图13c是根据一些实现的lstm神经元的神经元图式(schema)。
[0131]
图14a是根据一些实现的gru神经元的框图。
[0132]
图14b是根据一些实现的gru神经元的神经元图式。
[0133]
图15a和15b是根据一些实现的单个conv1d滤波器的变型的神经元图式。
[0134]
图16示出了根据一些实现的经变换的神经网络的示例架构。
[0135]
图17a-17c提供了根据一些实现的示出在输出误差和分类误差或权重误差之间的相关性的示例图表。
[0136]
图18提供了根据一些实现的用于电阻器量化的神经元模型的示例方案。
[0137]
图19a示出了根据一些实现的在cmos上制造的运算放大器的示意图。图19b示出了根据一些实现的图19a所示的示例电路的描述的表。
[0138]
图20a-20e示出了根据一些实现的lstm块的示意图。图20f示出了根据一些实现的图20a-20d所示的示例电路的描述的表。
[0139]
图21a-21i示出了根据一些实现的乘法器块的示意图。图21j示出了根据一些实现的图21a-21i所示的示意图的描述的表。
[0140]
图22a示出了根据一些实现的sigmoid神经元的示意图。图22b示出了根据一些实现的图22a所示的示意图的描述的表。
[0141]
图23a示出了根据一些实现的双曲正切函数块的示意图。图23b示出了根据一些实现的图23a所示的示意图的描述的表。
[0142]
图24a-24c示出了根据一些实现的单神经元cmos运算放大器的示意图。图24d示出了根据一些实现的图24a-24c所示的示意图的描述的表。
[0143]
图25a-25d示出了根据一些实现的单神经元cmos运算放大器的变型的示意图。图25e示出了根据一些实现的图25a-25d所示的示意图的描述的表。
[0144]
图26a-26k示出了根据一些实现的示例权重分布直方图。
[0145]
图27a-27j示出了根据一些实现的用于神经网络的硬件实现的方法的流程图。
[0146]
图28a-28s示出了根据一些实现的用于根据硬件设计约束的神经网络的硬件实现的方法的流程图。
[0147]
图29a-29f示出了根据一些实现的用于根据硬件设计约束的神经网络的硬件实现的方法的流程图。
[0148]
图30a-30m示出了根据一些实现的用于根据硬件设计约束的神经网络的硬件实现的方法的流程图。
[0149]
图31a-31q示出了根据一些实现的用于制造包括模拟部件的模拟网络的集成电路的方法的流程图。
[0150]
图32a-32e示出了根据一些实现的用于生成神经网络的硬件实现的库的方法的流程图。
[0151]
图33a-33k示出了根据一些实现的用于优化模拟神经形态电路(其模拟训练后的神经网络)的能量效率的方法的流程图。
[0152]
图34示出了根据一些实现描述mobilenet v1架构的表。
[0153]
现在将参考实现,其示例在附图中被示出。在下面的描述中,阐述了许多特定细
节,以便提供本发明的透彻理解。然而,对于本领域中的普通技术人员之一将明显的是,本发明可以被实践而不需要这些特定细节。
具体实施方式
[0154]
图1a是根据一些实现的用于使用模拟部件的训练后的神经网络的硬件实现的系统100的框图。该系统包括将训练后的神经网络102变换(126)成模拟神经网络104。在一些实现中,模拟集成电路约束184约束(146)变换(126)以生成模拟神经网络104。随后,系统通过有时被称为权重量化(128)的过程来导出(计算或生成)模拟神经网络104的权重106。在一些实现中,模拟神经网络包括多个模拟神经元,每个模拟神经元由模拟部件(例如运算放大器)表示,并且每个模拟神经元经由连接来连接到另一个模拟神经元。在一些实现中,使用减少在两个模拟神经元之间的电流的电阻器来表示连接。在一些实现中,系统针对连接将权重106变换(148)为电阻值112。系统随后基于权重106生成(130)用于实现模拟神经网络104的一个或更多个示意模型108。在一些实现中,系统优化电阻值112(或权重106)以形成优化的模拟神经网络114,其进一步用于生成(150)示意模型108。在一些实现中,系统针对连接生成(132)光刻掩模110和/或针对模拟神经元生成(136)光刻掩模120。在一些实现中,系统制造(134和/或138)实现模拟神经网络104的模拟集成电路118。在一些实现中,系统基于针对连接的光刻掩模110和/或针对模拟神经元的光刻掩模120来生成(152)光刻掩模库116。在一些实现中,系统使用(154)光刻掩模库116来制造模拟集成电路118。在一些实现中,当训练后的神经网络142被再训练(142)时,系统重新生成(或重新计算)(144)电阻值112(和/或权重106)、示意模型108和/或针对连接的光刻掩模110。在一些实现中,系统重新使用针对模拟神经元120的光刻掩模120。换句话说,在一些实现中,仅权重106(或对应于改变的权重的电阻值112)和/或针对连接的光刻掩模110被重新生成。因为如虚线156所指示的,只有连接、权重、示意模型和/或针对连接的对应光刻掩模被重新生成,所以当与用于神经网络的硬件实现的传统技术相比时,用于制造再训练后的神经网络的模拟集成电路的过程(或到模拟集成电路的路径)被显著简化,并且用于重新编造(re-spinning)神经网络的硬件的上市时间被减少。
[0155]
图1b是根据一些实现的用于使用模拟部件的训练后的神经网络的硬件实现的系统100的替代表示的框图。该系统包括用软件训练(156)神经网络,确定连接的权重,生成(158)等效于神经网络的电子电路,计算(160)对应于每个连接的权重的电阻器值,以及随后使用电阻器值生成(162)光刻掩模。
[0156]
图1c是根据一些实现的用于使用模拟部件的训练后的神经网络的硬件实现的系统100的另一表示的框图。根据一些实现,系统作为软件开发套件(sdk)180被分配。用户开发和训练(164)神经网络,并将训练后的神经网166输入到sdk 180。sdk估计(168)训练后的神经网166的复杂性。如果训练后的神经网的复杂性可以降低(例如,一些连接和/或神经元可以被移除,一些层可以被减少,或者神经元的密度可以被改变),则sdk 180修剪(178)训练后的神经网,并且再训练(182)该神经网以获得更新的训练后的神经网166。一旦训练后的神经网的复杂性降低,sdk180就将训练后的神经网166变换(170)成模拟部件的稀疏网络(例如,金字塔状或梯形状网络)。sdk 180还生成模拟网络的电路模型172。在一些实现中,sdk使用软件仿真来估计(176)由电路模型172生成的输出相对于对于相同输入的训练后的
神经网络的偏差。如果所估计的误差超过阈值误差(例如,由用户设定的值),sdk 180提示用户重新配置、重新开发和/或再训练神经网络。在一些实现中,虽然未示出,但sdk自动重新配置训练后的神经网166,以便减少所估计的误差。这个过程重复多次,直到误差降低到小于阈值误差为止。在图1c中,从块176(“在电路系统中出现的误差的估计”)到块164(“神经网络的开发和训练”)的虚线指示反馈回路。例如,如果被修剪的网络没有显示期望的准确度,则一些实现不同地修剪网络,直到对于给定应用准确度超过预定阈值(例如,98%的准确度)为止。在一些实现中,该过程包括重新计算权重,因为修剪包括整个网络的再训练。
[0157]
在一些实现中,上述系统100的部件在一个或更多个计算设备或服务器系统中被实现为计算模块。图2a是根据一些实现的计算设备200的框图。如本文所使用的,术语“计算设备”既包括个人设备102又包括服务器。计算设备200通常包括用于执行被存储在存储器214中的模块、程序和/或指令并从而执行处理操作的一个或更多个处理单元/核(cpu)202;一个或更多个网络或其它通信接口204;存储器214;以及用于将这些部件互连的一个或更多个通信总线212。通信总线212可以包括在系统部件之间进行互连和控制在系统部件之间的通信的电路系统。计算设备200可以包括用户接口206,用户接口206包括显示设备208和一个或更多个输入设备或机构210。在一些实现中,输入设备/机构210包括键盘;在一些实现中,输入设备/机构包括“软”键盘,其根据需要被显示在显示设备208上,使用户能够“按下”出现在显示器208上的“键”。在一些实现中,显示器208和输入设备/机构210包括触摸屏显示器(也被称为触敏显示器)。在一些实现中,存储器214包括高速随机存取存储器,例如dram、sram、ddr ram或其他随机存取固态存储器设备。在一些实现中,存储器214包括非易失性存储器,诸如一个或更多个磁盘存储设备、光盘存储设备、闪存设备或其他非易失性固态存储设备。在一些实现中,存储器214包括远离cpu 202定位的一个或更多个存储设备。存储器214或可选地在存储器214内的非易失性存储器设备包括计算机可读存储介质。在一些实现中,存储器214或存储器214的计算机可读存储介质存储下面的程序、模块和数据结构或其子集:
[0158]
操作系统216,其包括用于处理各种基本系统服务和用于执行硬件相关任务的过程;
[0159]
通信模块218,其用于经由一个或更多个通信网络接口204(有线的或无线的)和一个或更多个通信网络(例如互联网、其它广域网、局域网、城域网等)将计算设备200连接到其它计算机和设备;
[0160]
包括权重222和神经网络拓扑224的训练后的神经网络220。根据一些实现,下面参考图4a-4c、图12、图13a和图14a描述输入神经网络的例子;
[0161]
神经网络变换模块226,其包括变换的模拟神经网络228、数学公式230、基本函数块232、模拟模型234(有时被称为神经元模型)
[0162]
和/或模拟集成电路(ic)设计约束236。下面至少参考图5、图6a-6c、图7、图8、图9、图10和图11a-11c以及在图27a-27j和图28a-28s中所示的流程图来描述神经网络变换模块226的示例操作;和/或
[0163]
权重矩阵计算(有时被称为权重量化)模块238,其包括变换的网络的权重272,并且可选地包括电阻计算模块240、电阻值242。根据一些实现,至少参考图17a-17c、图18和图29a-29f来描述权重矩阵计算模块238和/或权重量化的示例操作。
[0164]
一些实现包括如图2b所示的一个或更多个可选模块244。一些实现包括模拟神经网络优化模块246。根据一些实现,下面参考图30a-30m描述模拟神经网络优化的例子。
[0165]
一些实现包括光刻掩模生成模块248,其进一步包括针对电阻(对应于连接)的光刻掩模250和/或针对模拟部件(例如运算放大器、乘法器、延迟块等)而不是电阻(或连接)的光刻掩模。在一些实现中,使用cadence、synopsys或mentor graphics(明导)软件包在芯片设计之后基于芯片设计布局来生成光刻掩模。一些实现使用来自硅晶圆制造厂(有时被称为晶圆厂)的设计套件。光刻掩模意欲被用在提供设计套件(例如,tsmc 65nm设计套件)的那个特定晶圆厂中。所生成的光刻掩模文件用于在晶圆厂处制造芯片。在一些实现中,基于cadence、mentor graphics或synopsys软件包的芯片设计从spice或fast spice(mentor graphics)软件包半自动地生成。在一些实现中,具有芯片设计技能的用户驱动从spice或fast spice电路到cadence、mentor graphics或synopsis芯片设计的转换。一些实现组合单个神经元单元的cadence设计块,在块之间建立适当的互连。
[0166]
一些实现包括库生成模块254,其进一步包括光刻掩模库256。根据一些实现,下面参考图32a-32e描述库生成的例子。
[0167]
一些实现包括集成电路(ic)制造模块258,其进一步包括模数转换(adc)、数模转换(dac)或类似的其他接口260和/或所制造的ic或模型262。根据一些实现,下面参考图31a-31q描述示例集成电路和/或相关模块。
[0168]
一些实现包括能量效率优化模块264,其进一步包括推断模块266、信号监测模块268和/或功率优化模块270。根据一些实现,下面参考图33a-33k描述能量效率优化的例子。
[0169]
上面识别的可执行模块、应用或过程集中的每个可以被存储在前面提到的存储器设备中的一个或更多个中,并且对应于用于执行上述功能的指令集。上面识别的模块或程序(即,指令集)不需要被实现为单独的软件程序、过程或模块,因此这些模块的各种子集可以在各种实现中被组合或以其他方式重新布置。在一些实现中,存储器214存储上面识别的模块和数据结构的子集。此外,在一些实现中,存储器214存储上面未描述的附加模块或数据结构。
[0170]
尽管图2a示出了计算设备200,但是图2a更预期作为可以存在的各种特征的功能描述,而不是作为本文所述的实现的结构示意图。在实践中且如本领域中的普通技术人员认识到的,单独示出的项可以组合并且一些项可以被分离。
[0171]
用于生成模拟网络的示意模型的示例过程
[0172]
图3a示出了根据一些实现的用于生成对应于训练后的神经网络的模拟网络的示意模型的示例过程300。如图3a所示,训练后的神经网络302(例如mobilenet)被变换(322)成目标或等效模拟网络304(使用有时被称为t变换的过程)。目标神经网络(有时被称为t网络)304被输出(324)到使用单神经元模型(snm)的spice(作为spice模型306),其从spice被导出(326)到使用cadence模型308的cadence和全片上设计。针对一个或更多个验证输入对照初始神经网络来交叉验证(328)cadence模型308。
[0173]
在上面和下面的描述中,数学神经元是接收一个或更多个加权输入并产生标量输出的数学函数。在一些实现中,数学神经元可以具有记忆(例如,长短期记忆(lstm)、循环神经元)。平凡神经元(trivial neuron)是执行函数的数学神经元,表示“理想”数学神经元v
out
=f(∑(v
iin
.ωi 偏差),其中f(x)是激活函数。snm是有以示意形式表示特定类型的数
学神经元(例如平凡神经元)的模拟部件(例如运算放大器、电阻器r1、
…
、rn和其他部件)的示意模型。snm输出电压由对应的公式表示,该公式取决于k个输入电压和snm部件值根据一些实现,利用适当地选择的部件值,snm公式等效于具有期望权重集的数学神经元公式。在一些实现中,权重集完全由在snm中使用的电阻器确定。目标(模拟)神经网络304(有时被称为t网络)是一组数学神经元,其定义snm表示以及对它们之间的连接加权,形成神经网络。t网络遵循几个限制,例如入站(inbound)限制(在t网络内的任何神经元的入站连接的最大限制)、出站(outbound)限制(在t网络内的任何神经元的出站连接的最大限制)和信号范围(例如,所有信号应在预定义信号范围内)。t变换(322)是将某个期望神经网络(例如mobilenet)转换成对应的t网络的过程。spice模型306是t网络304的spice神经网络模型,其中每个数学神经元用对应的一个或更多个snm代替。cadence nn模型310是t网络304的cadence模型,其中每个数学神经元用对应的一个或更多个snm代替。此外,如本文所述,如果对于这些网络的所有神经元输出则两个网络l和m具有数学等价性,其中eps是相对小的(例如,在操作电压范围的0.1-1%之间)。同样,如果对于给定的验证输入数据集{i1,
…
,in},分类结果大多是相同的,即,p(l(ik)=m(ik))=1-eps,则两个网络l和m具有函数等价性,其中eps是相对小的。
[0174]
图3b示出了根据一些实现的用于基于cadence上的snm模型314来生成目标芯片模型320的示例人工原型制作过程。注意,尽管下面的描述使用cadence,但是根据一些实现,来自mentor graphic设计或synopsys(例如synopsys设计套件)的可选工具可以被使用来代替cadence工具。该过程包括选择snm限制,包括入站和出站限制以及信号限制、针对神经元之间的连接选择模拟部件(例如电阻器,包括特定的电阻器阵列技术)以及开发cadence snm模型314。基于在cadence上的snm模型314来开发(330)原型snm模型316(例如pcb原型)。比较原型snm模型316与spice模型的等价性。在一些实现中,当神经网络满足等价性要求时,神经网络针对片上原型被选择。因为神经网络尺寸小,所以t变换可以针对等价性被手工验证。随后,基于snm模型原型316生成(332)片上snm模型318。根据一些实现,片上snm模型尽可能被优化。在一些实现中,在最终化(finalizing)snm模型之后,在基于片上snm模型318生成(334)目标芯片模型320之前,计算snm模型的片上密度。在原型制作过程期间,从业者可以反复选择神经网络任务或应用和特定神经网络(例如,具有大约10万个到110万个神经元的神经网络),执行t变换,建立cadence神经网络模型,设计接口和/或目标芯片模型。
[0175]
示例输入神经网络
[0176]
图4a、图4b和图4c示出了根据一些实现的训练后的神经网络(例如神经网络220)的例子,训练后的神经网络被输入到系统100并被变换成数学上等效的模拟网络。图4a示出了由人工神经元组成的示例神经网络(有时被称为人工神经网络),该人工神经元接收输入、使用激活函数来组合输入并产生一个或更多个输出。输入包括数据,例如图像、传感器数据和文档。一般,每个神经网络执行特定任务,例如对象识别。网络包括在神经元之间的连接,每个连接提供神经元的输出作为另一个神经元的输入。在训练之后,每个连接被分配对应的权重。如图4a所示,神经元通常被组织成多个层,每一层神经元只连接到紧接的前一层和后一层神经元。神经元的输入层402接收外部输入(例如,输入x1、x2、
…
、xn)。输入层402
后面是神经元的一个或更多个隐藏层(例如层404和406),其后是产生输出410的输出层408。各种类型的连接模式连接连续层的神经元,例如将一层中的每个神经元连接到下一层的所有神经元的完全连接模式或者将一层中的一组神经元的输出连接到下一层中的单个神经元的池化模式。与图4a所示的有时被称为前馈网络的神经网络相反,图4b所示的神经网络包括从一层中的神经元到同一层中的其他神经元或前一层中的神经元的一个或更多个连接。图4b中所示的例子是循环神经网络的例子,并且在输入层中包括两个输入神经元412(其接受输入x1)和414(其接受输入x2),后面是两个隐藏层。第一隐藏层包括神经元416和418,其与输入层中的神经元以及第二隐藏层中的神经元420、422和424完全连接。第二隐藏层中的神经元420的输出连接到第一隐藏层中的神经元416,提供反馈回路。包括神经元420、422和424的隐藏层被输入到输出层中的产生输出y的神经元426。
[0177]
图4c示出了根据一些实现的卷积神经网络(cnn)的例子。与图4a和图4b所示的神经网络相比,图4c所示的例子包括不同类型的神经网络层,其包括用于特征学习的层的第一阶段和用于分类任务(例如对象识别)的层的第二阶段。特征学习阶段包括卷积和修正线性单元(relu)层430,后面是池化层432,其后面是另一个卷积和relu层434,其后面又是另一个池化层436。第一层430从输入428(例如,输入图像或其部分)提取特征,并对它的输入执行卷积运算以及一个或更多个非线性运算(例如,relu、tanh或sigmoid)。当输入是大的时,池化层(例如层432)减少了参数的数量。池化层436的输出被层438压平(flattened),并输入到具有一个或更多个层(例如层440和442)的完全连接神经网络。完全连接神经网络的输出被输入到softmax层444以对完全连接网络的层442的输出分类,以产生许多不同输出446之一(例如,输入图像428的对象类别或类型)。
[0178]
一些实现将输入神经网络的布局或组织存储在存储器214中作为神经网络拓扑224,该输入神经网络的布局或组织包括每层中的神经元的数量、神经元的总数、每个神经元的操作或激活函数和/或在神经元之间的连接。
[0179]
图5示出了根据一些实现的神经元的数学模型500的例子。数学模型包括传入信号502的输入,其乘以突触权重504并由单位求和506来求和。根据一些实现,单位求和506的结果被输入到非线性转换单元508以产生输出信号510。
[0180]
图6a-6c示出了根据一些实现的用于计算输入值的异或(异或结果的分类)的神经网络的模拟硬件实现的示例过程。图6a示出了分别沿着x轴和y轴的可能输入值x1和x2的表600。预期结果值由空心圆(表示值1)和实心或黑色圆(表示值0)指示,这是具有2个输入信号和2个类别的典型异或问题。仅当值x1和x2中的任一个而不是两个为1时,预期结果才为1,否则为0。训练集由4种可能的输入信号组合(x1和x2输入的二进制值)组成。图6b示出了根据一些实现的解决图6a的异或分类的基于relu的神经网络602。神经元不使用任何偏差值,而使用relu激活。输入604和606(其分别对应于x1和x2)被输入到第一relu神经元608-2。输入604和606也输入到第二relu神经元608-4。两个relu神经元608-2和608-4的结果被输入到执行输入值的线性求和的第三神经元608-6,以产生输出值510(out值)。神经网络602具有对于relu神经元608-2的权重-1和1(分别对于输入值x1和x2)、对于relu神经元608-4的权重1和-1(分别对于输入值x1和x2)以及权重1和1(分别对于rellu神经元608-2和608-4的输出)。在一些实现中,训练后的神经网络的权重作为权重222存储在存储器214中。
[0181]
图6c示出了根据一些实现的网络602的示例等效模拟网络。x1输入604和x2输入606
的模拟等效输入614和616被输入到第一层的模拟神经元n1 618和n2 620。神经元n1和n2与第二层的神经元n3和n4密集地连接。第二层的神经元(即神经元n3 622和神经元n4 624)与产生输出out(等效于网络602的输出610)的输出神经元n5 626连接。神经元n1、n2、n3、n4和n5具有relu(最大值=1)激活函数。
[0182]
一些实现使用keras学习,该keras学习在大约1000次迭代时收敛,并产生用于连接的权重。在一些实现中,权重作为权重222的一部分存储在存储器214中。在下面的示例中,数据格式为“神经元[第1链接权重,第2链接权重,偏差]”。
[0183]
n1[-0.9824321,0.976517,-0.00204677];
[0184]
n2[1.0066702,-1.0101418,-0.00045485];
[0185]
n3[1.0357606,1.0072469,-0.00483723];
[0186]
n4[-0.07376373,-0.7682612,0.0];以及
[0187]
n5[1.0029935,-1.1994369,-0.00147767]。
[0188]
接下来,为了计算在神经元之间的连接的电阻器值,一些实现计算电阻器范围。一些实现设定1mω的电阻器标称值(r ,r-)、100kω至1mω的可能的电阻器范围以及标称系列e24。一些实现如下针对每个连接计算w1、w2、wbias电阻器值。对于每个权重值wi(例如权重222),一些实现评估在选择的标称系列内的所有可能的(ri-,ri )电阻器对选项,并选择产生最小误差值的电阻器对。根据一些实现,下面的表提供了对于每个连接的权重w1、w2和偏差的示例值。
[0189] 模型值r-(mω)r (mω)所实现的值n1_w1-0.98243210.360.56-0.992063n1_w20.9765170.560.360.992063n1_bias-0.002046770.10.10.0n2_w11.00667020.430.31.007752n2_w2-1.01014180.180.22-1.010101n2_bias-0.000454850.10.10.0n3_w11.03576060.910.471.028758n3_w21.00724690.430.31.007752n3_bias-0.004837230.10.10.0n4_w1-0.073763730.911.0-0.098901n4_w2-0.76826120.30.39-0.769231n4_bias0.00.10.10.0n5_w11.00299350.430.31.007752n5_w2-1.19943690.30.47-1.205674n5_bias-0.001477670.10.10.0
[0190]
变换的神经网络的示例优点
[0191]
在描述变换的例子之前,值得注意的是变换的神经网络优于传统架构的一些优点。如本文所述,输入的训练后的神经网络被变换成金字塔状或梯形状模拟网络。金字塔或梯形优于交叉开关的一些优点包括更低的时延、同时的模拟信号传播、使用标准集成电路
(ic)设计元件(包括电阻器和运算放大器)制造的可能性、计算的高度并行性、高准确度(例如,相对于传统方法,准确度随着层的数量而增加)、对在每个权重中和/或在每个连接处的误差的容限(例如,金字塔使误差平衡)、低rc(与信号通过网络的传播相关的低电阻电容延迟)和/或操纵在变换的网络的每层中的每个神经元的偏差和函数的能力。此外,金字塔本身是优秀的计算块,因为它是可以用一个输出对任何神经网络建模的多级感知器。根据一些实现,使用不同的金字塔或梯形几何结构来实现具有几个输出的网络。金字塔可以被认为是具有一个输出和几个层(例如n个层)的多层感知器,其中每个神经元具有n个输入和1个输出。类似地,梯形是多层感知器,其中每个神经元有n个输入和m个输出。根据一些实现,每个梯形是金字塔状网络,其中每个神经元具有n个输入和m个输出,其中n和m受到ic模拟芯片设计限制的限制。
[0192]
一些实现执行任何训练后的神经网络到金字塔或梯形的子系统的无损变换。因此,金字塔和梯形可以用作用于变换任何神经网络的通用构造块。基于金字塔或梯形的神经网络的一个优点是使用标准光刻技术使用标准ic模拟元件(例如运算放大器、电阻器、在循环神经元的情况下的信号延迟线)来实现任何神经网络的可能性。将变换的网络的权重限制到某个区间也是可能的。换句话说,根据一些实现,无损变换在权重被限制到某个预定义范围的情况下被执行。使用金字塔或梯形的另一个优点是在信号处理中的高度并行性或模拟信号的同时传播,其提高了计算的速度,提供更低的时延。此外,许多现代神经网络是稀疏连接网络,并且当被变换成金字塔时比变换成交叉开关时好得多(例如,更紧凑、具有低rc值、没有漏电流),金字塔和梯形网络比基于交叉开关的忆阻器网络相对更紧凑。
[0193]
此外,模拟神经形态梯形状芯片拥有对于模拟器件不典型的许多特性。例如,信噪比不随着在模拟芯片中的级联的数量而增加,外部噪声被抑制,且温度的影响极大地被降低。这样的特性使梯形状模拟神经形态芯片类似于数字电路。例如,根据一些实现,单独神经元基于运算放大器调平(level)信号,并且以20,000-100,000hz的频率操作,并且不被具有高于操作范围的频率的噪声或信号影响。由于在运算放大器如何运转方面的独特性,梯形状模拟神经形态芯片也执行输出信号的滤波。这样的梯形状模拟神经形态芯片抑制同相(synphase)噪声。由于运算放大器的低欧姆输出,噪声也显著降低。由于在每个运算放大器输出处的信号的调平和放大器的同步工作,由温度引起的参数的漂移不影响在最终输出处的信号。梯形状模拟神经形态电路容忍输入信号中的误差和噪声,并且容忍与神经网络中的权重值对应的电阻器值的偏差。梯形状模拟神经形态网络也容忍任何类型的系统误差,如在电阻器值设定中的误差,如果这样的误差基于运算放大器由于模拟神经形态梯形状电路的本质而对所有电阻器是相同的。
[0194]
训练后的神经网络的示例无损变换(t变换)
[0195]
在一些实现中,本文描述的示例变换由神经网络变换模块226执行,该神经网络变换模块226基于数学公式230、基本函数块232、模拟部件模型234和/或模拟设计约束236来变换训练后的神经网络220以获得变换的神经网络228。
[0196]
图7示出了根据一些实现的示例感知器700。感知器在接收8个输入的输入层中包括k=8个输入和8个神经元702-2、
…
、702-16。存在输出层,在输出层中有对应于l=4个输出的4个神经元704-2、
…
、704-8。输入层中的神经元完全连接到输出层中的神经元,建立8
×
4=32个连接。假设连接的权重由权重矩阵wp表示(元素wp
i,j
对应于在输入层中的第i个
神经元和输出层中的第j个神经元之间的连接的权重)。进一步假设每个神经元执行一个激活函数f。
[0197]
图8示出了根据一些实现的示例金字塔神经网络(p-nn)800,其是一种目标神经网络(t-nn或tnn),等效于图7所示的感知器。为了执行感知器(图7)到pn-nn架构(图8)的这个变换,假设对于t-nn,输入的数量被限制到ni=4以及输出的数量被限制到no=2。t-nn包括具有神经元802-2、
…
、802-34的输入层lti,其为具有神经元802-2、
…
、802-16的输入层的两个副本的串联,总共为2
×
8=16个输入神经元。神经元的集合804(包括神经元802-20、
…
、802-34)是神经元802-2、
…
、802-18的副本,并且输入被复制。例如,神经元802-2的输入也被输入到神经元802-20,神经元802-4的输入也被输入到神经元802-22,等等。图8还包括具有神经元806-02、
…
、806-16(2乘16除以4=8个神经元)的隐藏层lth1,这些神经元是线性神经元。来自输入层lti的每组ni个神经元完全连接到来自lth1层的两个神经元。图8还包括具有2乘8除以4=4个神经元808-02、
…
、808-08的输出层lto,每个神经元执行激活函数f。lto层中的每个神经元连接到来自层lth1中的不同组的不同神经元。图8所示的网络包括40个连接。一些实现针对图8中的p-nn执行权重矩阵计算,如下所示。隐藏层lth1的权重(wth1)根据权重矩阵wp被计算,并且对应于输出层lto的权重(wto)形成具有等于1的元素的稀疏矩阵。
[0198]
图9示出了根据一些实现的对应于图8的输出神经元的金字塔单神经网络(psnn)900。psnn包括具有输入神经元902-02、
…
、902-16(对应于图7的网络700中的8个输入神经元)的层(lpsi)。隐藏层lpsh1包括8除以4=2个线性神经元904-02和904-04,并且来自lti的每组ni个神经元连接到lpsh1层的一个神经元。输出层lpso由具有激活函数f的1个神经元906组成,神经元906同时连接到隐藏层的神经元904-02和904-04。为了计算psnn 900的权重矩阵,一些实现针对lpsh1层计算等于wp的第一行的向量wpsh1。对于lpso层,一些实现计算具有2个元素的权重向量wpso,每个元素等于1。该过程对于第一、第二、第三和第四输出神经元重复。p-nn(例如图8所示的网络)是psnn的并集(对于4个输出神经元)。每个psnn的输入层是p的输入层的单独副本。对于这个例子,p-nn 800包括具有8乘以4=32个输入的输入层、具有2乘以4=8个神经元的隐藏层和具有4个神经元的输出层。
[0199]
对具有n个输入和1个输出的目标神经元的示例变换
[0200]
在一些实现中,本文描述的示例变换由神经网络变换模块226执行,该神经网络变换模块226基于数学公式230、基本函数块232、模拟部件模型234和/或模拟设计约束236来变换训练后的神经网络220以获得变换的神经网络228。
[0201]
具有一个输出的单层感知器
[0202]
假设单层感知器slp(k,1)包括k个输入和具有激活函数f的一个输出神经元。进一步假设u∈rk是slp(k,1)的权重的向量。下面的算法neuron2tnn1从具有n个输入和1个输出的t神经元(被称为tn(n,1))构建t神经网络。
[0203]
算法neuron2tnn1
[0204]
1.通过包括来自slp(k,1)的所有输入来构建t-nn的输入层。
[0205]
2.如果k》n,则:
[0206]
a.将k个输入神经元分成个组,使得每个组由不多于n个输入组成。
[0207]
b.从m1个神经元构建t-nn的第一隐藏层lth1,每个神经元执行恒等激活函数。
[0208]
c.将来自每个组的输入神经元连接到来自下一层的对应神经元。因此,来自lth1的每个神经元具有不多于n个输入连接。
[0209]
d.根据下面的方程设定新连接的权重:
[0210]wij
=uj,j=(i-1)*n 1,
…
,i*n
[0211][0212]
3.否则(即,如果k《=n),则):
[0213]
a.用计算激活函数f的1个神经元构建输出层。
[0214]
b.将输入神经元连接到单个输出神经元。它具有k≤n个连接。
[0215]
c.借助于下面的方程设定新连接的权重:
[0216][0217]
d.终止算法
[0218]
2.设定l=1
[0219]
3.如果m
l
》n:
[0220]
a.将m
l
个神经元分成个组,每个组由不多于n个神经元组成。
[0221]
b.从m
l 1
个神经元构建t-nn的隐藏层lth
l 1
,每个神经元具有恒等激活函数。
[0222]
c.将来自每个组的输入神经元连接到来自下一层的对应神经元。
[0223]
d.根据下面的方程设定新连接的权重:
[0224][0225][0226]
e.设定l=l 1
[0227]
4.否则(如果m》=n):
[0228]
a.用计算激活函数f的1个神经元构建输出层
[0229]
b.将所有的lth
l
的神经元连接到单个输出神经元。
[0230]
c.根据下面的方程设定新连接的权重:
[0231]
a.
[0232]
d.终止算法
[0233]
5.重复步骤5和6。
[0234]
在这里,是不小于x的最小整数。在借助于算法neuron2tnn1构建的t-nn中的层的数量是在t-nn中的权重的总数为:
[0235][0236]
图10示出了根据一些实现的构建的t-nn的例子。除第一层之外的所有层执行它们
的输入的恒等变换。根据一些实现,构建的t-nn的权重矩阵具有下面的形式。
[0237]
层1(例如层1002):
[0238][0239]
层i=2、3、
…
、h(例如,层1004、1006、1008和1010):
[0240][0241]
t-nn的输出值根据下面的公式被计算:
[0242]
y=f(wmw
m-1
…
w2w1x)
[0243]
第一层的输出根据下面的公式被计算为输出向量:
[0244][0245]
使所获得的向量乘以第二层的权重矩阵:
[0246][0247]
每个后续层输出一个向量,该向量具有等于x的某个子向量的线性组合的分量。
[0248]
最后,t-nn的输出等于:
[0249][0250]
这与在slp(k,1)中针对相同的输入向量x计算的值相同。所以slp(k,1)和构建的tnn的输出值是相等的。
[0251]
具有几个输出的单层感知器
[0252]
假设存在具有k个输入和l个输出神经元的单层感知器slp(k,l),每个神经元执行
一个激活函数f。进一步假设u∈r
l
×k是slp(k,l)的权重矩阵。下面的算法layer2tnn1从神经元tn(n,1)构建t神经网络。
[0253]
算法layer2tnn1
[0254]
1.对于每个输出神经元i=1、
…
、l
[0255]
a.将算法neuron2tnn1应用于slpi(k,1),其由k个输入、1个输出神经元和权重向量u
ij
,j=1、2、
…
、k组成。tnni被构建作为结果。
[0256]
2.通过将所有tnni组合为一个神经网来构建ptnn:
[0257]
a.将所有tnni的输入向量连接在一起,因此ptnn的输入具有l组k个输入,每个组是slp(k,l)的输入层的副本。
[0258]
对于相同的输入向量,ptnn的输出等于slp(k,l)的输出,因为每对slpi(k,1)和tnni的输出是相等的。
[0259]
多层感知器
[0260]
假设多层感知器(mlp)包括k个输入、s个层和在第i层中的li个计算神经元,其被表示为mlp(k,s,l1,
…
ls)。假设是第i层的权重矩阵。
[0261]
下面是根据一些实现的从神经元tn(n,1)构建t神经网络的示例算法。
[0262]
算法mlp2tnn1
[0263]
1.对于每一层i=1、
…
、s
[0264]
a.将算法layer2tnn1应用于由l
i-1
个输入、li个输出神经元和权重矩阵ui组成的slpi(l
i-1
,li),构建ptnni作为结果。
[0265]
2.通过将所有ptnni堆叠成一个神经网来构建mtnn;tnn
i-1
的输出被设定为tnni的输入。
[0266]
对于相同的输入向量,mtnn的输出等于mlp(k,s,l1,
…
ls)的输出,因为每对slpi(l
i-1
,li)和ptnni的输出是相等的。
[0267]
对具有ni个输入和no个输出的目标神经元的示例t变换
[0268]
在一些实现中,本文描述的示例变换由神经网络变换模块226执行,该神经网络变换模块226基于数学公式230、基本函数块232、模拟部件模型234和/或模拟设计约束236来变换训练后的神经网络220以获得变换的神经网络228。
[0269]
具有几个输出的单层感知器的示例变换
[0270]
假设单层感知器slp(k,l)包括k个输入和l个输出神经元,每个神经元执行一个激活函数f。进一步假设u∈r
l
×k是slp(k,l)的权重矩阵。根据一些实现,下面的算法从神经元tn(ni,no)构建t神经网络。
[0271]
算法layer2tnnx
[0272]
1.通过使用算法layer2tnn1(见上面的描述)从slp(k,l)构建ptnn。ptnn具有由l组k个输入组成的输入层。
[0273]
2.从l个组构成个子集。每个子集包含不多于no个组的输入向量副本。
[0274]
3.用输入向量的一个副本代替每个子集中的组。
[0275]
4.通过从每个输入神经元建立no个输出连接来由每个子集中的重建连接构建ptnnx。
[0276]
根据一些实现,借助于关于ptnn的相同公式(如上所述)来计算ptnnx的输出,因此输出是相等的。
[0277]
图11a-11c示出了根据一些实现的上述算法对于具有2个输出神经元和tn(ni,2)的单层神经网络(nn)的应用1100。图11a示出了根据一些实现的示例源或输入nn。k个输入被输入到属于层1104的两个神经元1和2。图11b示出了根据一些实现在算法的第一步骤之后构建的ptnn。ptnn由实现与图11a所示的nn的输出神经元1和神经元2对应的子网的两个部分组成。在图11b中,输入1102被复制并输入到输入神经元的两个集合1106-2和1106-4。输入神经元的每个集合连接到具有神经元的两个集合1108-2和1108-4的后一层神经元,神经元的每个集合包括m1个神经元。输入层后面是恒等变换块1110-2和1110-4,每个块包含具有恒等权重矩阵的一个或更多个层。恒等变换块1110-2的输出连接到输出神经元1112(对应于图11a中的输出神经元1),且恒等变换块1110-4的输出连接到输出神经元1114(对应于图11a中的输出神经元1)。图11c示出了算法的最后步骤的应用,包括用一个向量1116代替输入向量(1106-2和1106-4)的两个副本(步骤3),以及通过从每个输入神经元建立两个输出链接来在第一层1118中重建连接:一个链接连接到与输出1相关的子网,而另一个链接连接到输出2的子网。
[0278]
多层感知器的示例变换
[0279]
假设多层感知器(mlp)包括k个输入、s个层和在第i层中的li个计算神经元,被表示为mlp(k,s,l1,
…
ls)。假设是第i层的权重矩阵。根据一些实现,下面的示例算法从神经元tn(ni,no)构建t神经网络。
[0280]
算法mlp2tnnx
[0281]
1.对于每一层i=1、
…
、s
[0282]
a.将算法layer2tnnx应用于由l
i-1
个输入、li个输出神经元和权重矩阵ui组成的slpi(l
i-1
,li)。ptnni被构建作为结果。
[0283]
2.通过将所有ptnnxi堆叠成一个神经网来构建mtnnx;
[0284]
a.tnnx
i-1
的输出被设定为tnnxi的输入。
[0285]
根据一些实现,对于相同的输入向量,mtnnx的输出等于mlp(k,s,l1,
…
ls)的输出,因为每对slpi(l
i-1
,li)和ptnnxi的输出是相等的。
[0286]
循环神经网络的示例变换
[0287]
循环神经网络(rnn)包含允许保存信息的反向连接。图12示出了根据一些实现的示例rnn 1200。该示例示出了执行激活函数a的块1204,其接受输入x
t
1206并执行激活函数a,并输出值h
t
1202。根据一些实现,从块1204到它自身的反向箭头指示反向连接。等效网络在右侧示出,一直到激活块接收到输入x
t
1206时的时间点。在时间0处,网络接受输入x
t
1208并执行激活函数a 1204,并输出值ho1210;在时间1处,网络接受输入x11212和网络在时间0处的输出,并执行激活函数a 1204,并输出值h11214;在时间2处,网络接受输入x21216和网络在时间1处的输出,并且执行激活函数a 1204,并且输出值h11218。根据一些实现,该过程持续到时间t,此时网络接受输入x
t
1206和网络在时间t-1处的输出,并且执行激活函数a 1204,并且输出值h
t
1202。
[0288]
在rnn中的数据处理借助于下面的公式被执行:
[0289]ht
=f(w
(hh)ht-1
w
(hx)
x
t
)
[0290]
在上面的方程中,x
t
是当前输入向量,以及h
t-1
是rnn的关于前一输入向量x
t-1
的输出。该表达式由几个操作组成:对于两个完全连接层w
(hh)ht-1
和w
(hx)
x
t
的线性组合的计算、逐元素相加以及非线性函数计算(f)。第一个和第三个操作可以通过基于梯形的网络实现(一个完全连接层通过基于金字塔的网络实现,基于金字塔的网络为梯形网络的特例)。第二个操作是可以在任何结构的网络中实现的常见操作。
[0291]
在一些实现中,rnn的没有循环连接的层借助于上面所述的layer2tnnx算法来变换。在变换完成之后,在相关神经元之间添加循环链接。一些实现使用下面参考图13b描述的延迟块。
[0292]
lstm网络的示例变换
[0293]
长短期记忆(lstm)神经网络是rnn的特例。lstm网络的操作由下面的方程表示:
[0294]ft
=σ(wf[h
t-1
,x
t- bf);
[0295]it
=σ(wi[h
t-1
,x
t
] bi);
[0296]dt
=tanh(wd[h
t-1
,x
t
] bd);
[0297]ct
=(f
t
×ct-1
i
t
×dt
);
[0298]ot
=σ(wo[h
t-1
,x
t
] bo);以及
[0299]ht
=o
t
×
tanh(c
t
)。
[0300]
在上面的方程中,wf、wi、wd和wo是可训练的权重矩阵,bf、bi、bd和bo是可训练的偏差,x
t
是当前输入向量,h
t-1
是针对前一输入向量x
t-1
计算的lstm的内部状态,以及o
t
是当前输入向量的输出。在方程中,下标t表示时间实例t,以及下标t-1表示时间实例t-1。
[0301]
图13a是根据一些实现的lstm神经元1300的框图。sigmoid(σ)块1318处理输入h
t-1
1330和x
t
1332,并产生输出f
t
1336。第二sigmoid(σ)块1320处理输入h
t-1
1330和x
t
1332,并产生输出i
t
1338。双曲正切(tanh)块1322处理输入h
t-1
1330和x
t
1332,并产生输出d
t
1340。第三sigmoid(σ)块1328处理输入h
t-1
1330和x
t
1332,并产生输出o
t
1342。乘法器块1304处理f
t
1336和求和块1306(来自前一时间实例)的输出c
t-1
1302以产生输出,其又连同将输出i
t
1338和d
t
1340相乘的第二乘法器块1314的输出一起由求和块1306求和,以产生输出c
t
1310。输出c
t
1310被输入到产生输出的另一tanh块1312,该输出通过第三乘法器块1316与输出o
t
1342相乘以产生输出h
t
1334。
[0302]
存在在这些表达式中利用的几种类型的操作:(i)几个完全连接层的线性组合的计算,(ii)元素方式相加,(iii)hadamard乘积,以及(iv)非线性函数计算(例如,sigmoid(σ)和双曲正切(tanh))。一些实现通过基于梯形的网络来实现(i)和(iv)操作(一个完全连接层通过基于金字塔的网络来实现,基于金字塔的网络为梯形网络的特例)。一些实现对(ii)和(iii)操作使用各种结构的网络,(ii)和(iii)操作是常见的操作。
[0303]
根据一些实现,通过使用上面所述的layer2tnnx算法来变换没有循环连接的lstm层中的层。根据一些实现,在变换完成之后,在相关神经元之间添加循环链接。
[0304]
图13b示出了根据一些实现的延迟块。如上所述,在用于lstm操作的方程中的一些表达式依赖于保存、恢复和/或调用来自前一时间实例的输出。例如,乘法器块1304处理求和块1306(来自前一时间实例)的输出c
t-1
1302。图13b示出了根据一些实现的延迟块的两个例子。示例1350包括在左侧的延迟块1354,其在时间t处接受输入x
t
1352,并在dt的延迟之后输出该输入,其由输出x
t-dt
1356指示。根据一些实现,在右侧的示例1360示出了级联(或
多个)延迟块1364和1366在2个单位的时间延迟之后输出输入x
t
1362,其由输出x
t-2dt
1368指示。
[0305]
图13c是根据一些实现的lstm神经元的神经元图式。该图式包括加权求和器节点(有时被称为加法器块)1372、1374、1376、1378和1396、乘法器块1384、1392和1394以及延迟块1380和1382。输入x
t
1332连接到加法器块1372、1374、1376和1378。对于前一输入x
t-1
的输出h
t-1
1330也被输入到加法器块1372、1374、1376和1378。加法器块1372产生输出,其被输入到产生输出f
t
1336的sigmoid块1394-2。类似地,加法器块1374产生输出,其被输入到产生输出i
t
1338的sigmoid块1386。类似地,加法器块1376产生输出,其被输入到产生输出d
t
1340的双曲正切块1388。类似地,加法器块1378产生输出,其被输入到产生输出o
t
1342的sigmoid块1390。乘法器块1392使用输出i
t
1338、f
t
1336和加法器块1396的来自前一时间实例的输出c
t-1
1302来产生第一输出。乘法器块1394使用输出i
t
1338和d
t
1340来产生第二输出。加法器块1396将第一输出和第二输出相加以产生输出c
t
1310。输出c
t
1310被输入到产生输出的双曲正切块1398,该输出连同sigmoid块1390的输出o
t
1342一起被输入到乘法器块1384以产生输出h
t
1334。延迟块1382用于调用(例如,保存和恢复)加法器块1396来自前一时间实例的输出。类似地,延迟块1380用于调用或保存和恢复乘法器块1384的对于前一输入x
t-1
(例如,来自前一时间实例)的输出。根据一些实现,上面参考图13b描述了延迟块的例子。
[0306]
gru网络的示例变换
[0307]
门控循环单元(gru)神经网络是rnn的特例。rnn的操作由下面的表达式表示:
[0308]zt
=σ(wzx
t
u
zht-1
);
[0309]rt
=σ(wrx
t
u
rht-1
);
[0310]jt
=tanh(wx
t
r
t
×
uh
t-1
);
[0311]ht
=z
t
×ht-1
(1-z
t
)
×jt
)。
[0312]
在上述方程中,x
t
是当前输入向量,并且h
t-1
是针对前一输入向量x
t-1
计算的输出。
[0313]
图14a是根据一些实现的grn神经元的框图。sigmoid(σ)块1418处理输入h
t-1
1402和x
t
1422,并产生输出r
t
1426。第二sigmoid(σ)块1420处理输入h
t-1
1402和x
t
1422,并产生输出z
t
1428。乘法器块1412使输出r
t
1426和输入h
t-1
1402相乘以产生输出,其(连同输入x
t
1422一起)被输入到双曲正切(tanh)块1424以产生输出j
t
1430。第二乘法器块1414使输出j
t
1430和输出z
t
1428相乘以产生第一输出。块1410计算1
–
输出z
t
1428以产生被输入到第三乘法器块1404的输出,第三乘法器块1404使该输出和输入h
t-1
1402相乘以产生乘积,该乘积连同第一输出(来自乘法器块1414)一起被输入到加法器块1406以产生输出h
t
1408。输入h
t-1
1402是gru神经元的来自前一时间间隔输出t-1的输出。
[0314]
图14b是根据一些实现的gru神经元1440的神经元图式。该图式包括加权求和器节点(有时被称为加法器块)1404、1406、1410、1406和1434、乘法器块1404、1412和1414以及延迟块1432。输入x
t
1422连接到加法器块1404、1410和1406。前一输入x
t-1
的输出h
t-1
1402也被输入到加法器块1404和1406以及乘法器块1404和1412。加法器块1404产生输出,其被输入到产生输出z
t
1428的sigmoid块1418。类似地,加法器块1406产生被输入到sigmoid块1420的输出,sigmoid块1420产生被输入到乘法器块1412的输出r
t
1426。乘法器块1412的输出被输入到加法器块1410,加法器块1410的输出被输入到产生输出1430的双曲正切块1424。输
出1430以及sigmoid块1418的输出被输入到乘法器块1414。sigmoid块1418的输出被输入到乘法器块1404,乘法器块1404使该输出与来自延迟块1432的输入相乘以产生第一输出。乘法器块产生第二输出。加法器块1434将第一输出和第二输出相加以产生输出h
t
1408。延迟块1432用于调用(例如保存和恢复)加法器块1434的来自前一时间实例的输出。根据一些实现,上面参考图13b描述了延迟块的例子。
[0315]
根据一些实现,在gru中使用的操作类型与针对(上述的)lstm网络的操作类型相同,因此gru按照上面针对lstm描述的原理(例如,使用layer2tnnx算法)被变换成基于梯形的网络。
[0316]
卷积神经网络的示例变换
[0317]
一般来说,卷积神经网络(cnn)包括几个基本操作,例如卷积(图像的(或内部图的)片段与内核的线性组合的集合)、激活函数和池化(如最大值、平均值等)。在cnn中的每个计算神经元遵循在mlp中的神经元的一般处理方案:一些输入与激活函数的随后计算的线性组合。因此,根据一些实现,使用上面针对多层感知器描述的mlp2tnnx算法来变换cnn。
[0318]
conv1d是在时间坐标上执行的卷积。图15a和图15b是根据一些实现的单个conv1d滤波器的变型的神经元图式。在图15a中,加权求和器节点1502(有时被称为加法器块,被标记为“ ”)具有5个输入,因此它对应于具有5的内核的1d卷积。输入是时间t的x
t
1504、时间t-1的x
t-1
1514(通过将输入输入到延迟块1506来获得)、时间t-2的x
t-2
1516(通过将延迟块1506的输出输入到另一个延迟块1508来获得)、时间t-3的x
t-3
1518(通过将延迟块1508的输出输入到另一个延迟块1510来获得)以及时间t-4的x
t-4
1520(通过将延迟块1510的输出输入到另一个延迟块1512来获得)。对于大内核,利用不同的频率延迟块有时是有益的,使得一些块产生更大的延迟。一些实现用几个小延迟块替换一个大延迟块,如图15b所示。除了图15a中的延迟块之外,该示例还使用产生时间t-3的x
t-3
1518的delay_3块1524以及产生时间t-5的x
t-5
1522的另一个延迟块1526。根据一些实现,delay_3 1524块是多个延迟块的例子。根据一些实现,该操作不减少块的总数,但是它可以减少对输入信号执行的后续操作的总数,并且减少误差的累积。
[0319]
在一些实现中,卷积层由梯形状神经元表示,而完全连接层由电阻器的交叉开关表示。一些实现使用交叉开关,并计算交叉开关的电阻矩阵。
[0320]
具有多个输出的单层感知器的示例近似算法
[0321]
在一些实现中,本文描述的示例变换由神经网络变换模块226执行,该神经网络变换模块226基于数学公式230、基本函数块232、模拟部件模型234和/或模拟设计约束236来变换训练后的神经网络220和/或模拟神经网络优化模块246以获得变换的神经网络228。
[0322]
假设单层感知器slp(k,l)包括k个输入和l个输出神经元,每个输出神经元执行一个激活函数f。进一步假设u∈r
l
×k是slp(k,l)的权重矩阵。下面是根据一些实现使用近似算法layer2tnnx_approx从神经元tn(ni,no)构建t神经网络的示例。该算法在第一阶段应用(上述的)layer2tnn1算法,以便减少神经元和连接的数量,并且随后应用layer2tnnx以处理减小的大小的输入。使用由layer2tnn1算法构建的层的共享权重来计算所得到的神经网的输出。这些层的数量由值p(算法的参数)确定。如果p等于0,则仅应用layer2tnnx算法,并且变换是等效的。如果p》0,则p个层具有共享权重,并且变换是近似的。
[0323]
算法layer2tnnx_approx
[0324]
1.用来自集合的值设定参数p。
[0325]
2.如果p》0,将对于神经元tn(ni,1)的算法layer2tnn1应用于网slp(k,l),并构建所得到的子网(pnn)的前p个层。网pnn在输出层中具有个神经元。
[0326]
3.应用对于神经元tn(ni,no)的算法layer2tnnx并构建具有n
p
个输入和l个输出的神经子网tnn。
[0327]
4.设定pnn网的权重。根据规则设定pnn的第一层的每个神经元i的权重。在这里,c是不等于零的任何常数,ki=(i-1)ni 1,并且对于除ki之外的这个神经元的所有权重j,pnn网的所有其他权重被设定为1。表示对于在第一层中的神经元i和神经元ki之间的连接的第一层的权重(如由上标(1)表示的)。
[0328]
5.设定tnn子网的权重。根据方程设定tnn的第一层(考虑整个网,这是第(p 1)层)的每个神经元i的权重。tnn的所有其他权重被设定为1。
[0329]
6.将tnn子网的最后一层的所有神经元的激活函数设定为f。所有其他神经元的激活函数是恒等的。
[0330]
图16示出了根据一些实现的所得到的神经网的示例架构1600。该示例包括连接到tnn 1606的pnn 1602。pnn 1602包括k个输入的一层并产生n
p
个输出,其作为输入1612连接到tnn 1606。根据一些实现,tnn1606生成l个输出1610。
[0331]
具有几个输出的多层感知器的近似算法
[0332]
假设多层感知器(mlp)包括k个输入、s个层和在第i层中的li个计算神经元,被表示为mlp(k,s,l1,
…
ls)。进一步假设是第i层的权重矩阵。根据一些实现,下面的示例算法从神经元tn(ni,no)构建t神经网络。
[0333]
算法mlp2tnnx_approx
[0334]
1.对于每一层i=1、
…
、s:
[0335]
a.将(上述的)算法layer2tnnx_approx应用于由l
i-1
个输入、li个输出神经元和权重矩阵ui组成的slpi(l
i-1
,li)。如果i=1,则l0=k。假设这个步骤构建ptnnxi作为结果。
[0336]
2.通过将所有ptnnxi堆叠成一个神经网来构建mtnnx(多层感知器),其中tnnx
i-1
的输出被设定为tnnxi的输入。
[0337]
变换的神经网络的压缩的示例方法
[0338]
在一些实现中,本文描述的示例变换由神经网络变换模块226执行,该神经网络变换模块226基于数学公式230、基本函数块232、模拟部件模型234和/或模拟设计约束236来变换训练后的神经网络220和/或模拟神经网络优化模块246以获得变换的神经网络228。
[0339]
本节描述了根据一些实现的变换的神经网络的压缩的示例方法。一些实现压缩模拟金字塔状神经网络,以便最小化在芯片上实现模拟网络所必需的运算放大器和电阻器的数量。在一些实现中,模拟神经网络的压缩的方法是修剪,类似于在软件神经网络中的修剪。然而,在金字塔状模拟网络的压缩中有一些特殊性,金字塔状模拟网络在硬件中可实现
为ic模拟芯片。因为元件(例如运算放大器和电阻器)的数量限定在基于模拟的神经网络中的权重,最大限度地减小放置在芯片上的运算放大器和电阻器的数量是至关重要的。这也将帮助最小化芯片的功率消耗。现代神经网络(例如卷积神经网络)可以被压缩5-200倍而没有网络的准确度的显著损失。在现代神经网络中的整个块常常可以被修剪而没有准确度的显著损失。密集神经网络到稀疏连接金字塔或梯形或交叉开关状神经网络的变换提供了修剪稀疏连接金字塔或梯形状模拟网络的机会,这些模拟网络然后由在模拟ic芯片中的运算放大器和电阻器表示。在一些实现中,除了传统的神经网络压缩技术之外,还应用这样的技术。在一些实现中,基于输入神经网络和/或变换的神经网络的特定架构(例如,金字塔相对于梯形相对于交叉开关)来应用压缩技术。
[0340]
例如,因为网络借助于模拟元件(例如运算放大器)来实现,一些实现确定当标准训练数据集被呈现时流经运算放大器的电流,并从而确定整个芯片是否需要结点(运算放大器)。一些实现分析芯片的spice模型,并确定结点和连接,其中没有电流流动且没有功率被消耗。一些实现确定通过模拟ic网络的电流流动,并因而确定结点和连接,其然后将被修剪。此外,如果连接的权重太高,一些实现也移除连接,和/或如果连接的权重太低,则将电阻器替换为直接连接器。如果通向该结点的所有连接具有低于预定阈值的权重(例如,接近于0),则一些实现修剪该结点,删除在其中运算放大器总是在输出处提供零的连接,和/或如果放大器在没有放大的情况下给出线性函数,则将运算放大器改变为线性结。
[0341]
一些实现应用特定于金字塔、梯形或交叉开关类型的神经网络的压缩技术。一些实现生成具有更大量的输入(与没有压缩的情况相比)的金字塔或梯形,因而最小化在金字塔或梯形中的层的数量。一些实现通过最大化每个神经元的输出的数量来生成更紧凑的梯形网络。
[0342]
最佳电阻器集合(resistor set)的示例生成
[0343]
在一些实现中,本文描述的示例计算由权重矩阵计算或权重量化模块238执行(例如,使用电阻计算模块240),权重矩阵计算或权重量化模块238计算变换的神经网络的连接的权重272和/或权重272的对应电阻值242。
[0344]
根据一些实现,本节描述了为训练后的神经网络生成最佳电阻器集合的示例。提供了一种示例方法,其用于将连接权重转换成电阻器标称量,用于在具有可能更少的电阻器标称量和可能更高的被允许的电阻器变化的微芯片上实现神经网络(有时被称为nn模型)。
[0345]
假设测试集“test”包括输入向量(x和y坐标)的大约10,000个值,其中两个坐标在范围[0;1]中以0.01的步长改变。假设对给定输入x的网络nn输出由out=nn(x)给出。进一步假设输入值类别如下被找到:class_nn(x)=nn(x)》0.61?1:0。
[0346]
下文将数学网络模型m与示意网络模型s进行比较。示意网络模型包括rv的可能电阻器变化,并处理“test”集,每次产生输出值s(test)=out_s的不同向量。输出误差由下面的方程定义:
[0347][0348]
分类误差由下面的方程定义:
[0349][0350]
一些实现将期望的分类误差设定为不大于1%。
[0351]
示例误差分析
[0352]
图17a示出了根据一些实现的示例图表1700,其示出在m网络上的输出误差和分类误差之间的相关性。在图17a中,x轴对应于分类间隔1704,以及y轴对应于总误差1702(见上面的描述)。该曲线图示出了对于输出信号的不同分类间隔的总误差(在模型m的输出和真实数据之间的差异)。对于这个例子,根据该图表,最佳分类间隔1706是0.610。
[0353]
假设另一个网络o产生相对于相关的m个输出值具有恒定偏移的输出值,则在o和m之间将有分类误差。为了将分类误差保持为低于1%,该偏移应该在[-0.045,0.040]的范围内。因此,s的可能的输出误差为45mv。
[0354]
通过分析在整个网络上的权重/偏差相对误差与输出误差之间的相关性来确定可能的权重误差。根据一些实现,通过在“test”集上对20个随机修改的网络取平均来获得分别在图17b和图17c中示出的图表1710和1720。在这些图表中,x轴表示绝对权重误差1712,以及y轴表示绝对输出误差1714。如从图表中可以看到,45mv(y=0.045)的输出误差限制对于每个权重允许有0.01相对误差值或0.01绝对误差值(x的值)。神经网络的最大权重系数(weight modulus)(在所有权重当中的权重的绝对值的最大值)为1.94。
[0355]
用于选择电阻器集合的示例过程
[0356]
电阻器集合连同从该集合选择的{r ,r-}对一起具有在具有某个程度的电阻器误差r_err的所需的权重范围[-wlim;wlim]内的值函数。在一些实现中,电阻器集合的值函数被计算如下:
[0357]
可能的权重选项数组连同依赖于电阻器误差的权重平均误差一起被计算;
[0358]
数组中的权重选项被限制到所需的权重范围[-wlim;wlim];
[0359]
在权重误差方面比邻近值更差的值被移除;
[0360]
在邻近值之间的距离的数组被计算;以及
[0361]
值函数是距离数组的平方平均数或最大值的组成。
[0362]
一些实现通过基于学习速率值连续地调整在电阻器集合中的每个电阻器值来迭代地搜索最佳电阻器集合。在一些实现中,学习速率随着时间变化。在一些实现中,初始电阻器集合被选择为均匀的(例如[1;1;
…
;1]),其中最小和最大电阻器值被选择在两个数量级范围内(例如[1;100]或[0.1;10])。一些实现选择r =r-。在一些实现中,迭代过程收敛到局部最小值。在一种情况中,该过程导致下面的集合:[0.17,1.036,0.238,0.21,0.362,1.473,0.858,0.69,5.138,1.215,2.083,0.275]。对于具有rmin=0.1(最小电阻)、rmax=10(最大电阻)和r_err=0.001(电阻中的估计误差)的权重范围[-2;2],这是12个电阻器的局部最佳电阻器集合。一些实现不使用整个可用范围[rmin;rmax],用于找到好的局部最佳值。仅可用范围的一部分(例如,在这种情况下是[0.17;5.13])被使用。电阻器集合的值是相对的,而不是绝对的。在这种情况下,30的相对值范围对于电阻器集合是足够的。
[0363]
在一个实例中,对于上面提到的参数,获得长度20的下面的电阻器集合:[0.300,0.461,0.519,0.566,0.648,0.655,0.689,0.996,1.006,1.048,1.186,1.222,1.261,
1.435,1.488,1.524,1.584,1.763,1.896,2.02]。在这个示例中,值1.763也是r-=r 值。该集合随后用于产生nn的权重,产生对应的模型s。假定相对电阻器误差接近于零,模型s的均方输出误差为11mv,因此20个电阻器的集合超过所需。在输入数据的集合上的最大误差被计算为33mv。在一个实例中,具有256个电平的s、dac和adc转换器作为单独的模型被分析,且结果显示14mv均方输出误差和49mv最大输出误差。在nn上的45mv的输出误差对应于1%的相对识别误差。45mv输出误差值也对应于0.01相对权重误差或0.01绝对权重误差,这是可接受的。在nn中的最大权重系数为1.94。以这种方式,基于期望的权重范围[-wlim;wlim]、电阻器误差(相对的)和可能的电阻器范围使用迭代过程来确定最佳(或接近最佳)电阻器集合。
[0364]
一般,非常宽的电阻器集合不是非常有益的(例如,在1-1/5数量级之间就足够了),除非不同的精度在不同的层或权重谱部分内是需要的。例如,假设权重在[0,1]的范围内,但大多数权重在[0,0.001]的范围内,则更好的精度在该范围内是需要的。在上面描述的示例中,假定相对电阻器误差接近于零,该20个电阻器的集合对以给定精度量化nn网络是绰绰有余的。在一个实例中,在电阻器的集合[0.300,0.461,0.519,0.566,0.648,0.655,0.689,0.996,1.006,1.048,1.186,1.222,1.261,1.435,1.488,1.524,1.584,1.763,1.896,2.02](注意,值是相对的)上,获得11mv的平均s输出误差。
[0365]
用于电阻器值的量化的示例过程
[0366]
在一些实现中,本文描述的示例计算由权重矩阵计算或权重量化模块238(例如,使用电阻计算模块240)执行,权重矩阵计算或权重量化模块238计算变换的神经网络的连接的权重272和/或权重272的对应电阻值242。
[0367]
本节描述了根据一些实现的用于量化与训练后的神经网络的权重对应的电阻器值的示例过程。示例过程实质上简化了使用模拟硬件部件来制造芯片用于实现神经网络的过程。如上所述,一些实现使用电阻器来表示神经网络权重和/或表示模拟神经元的运算放大器的偏差。这里描述的示例过程特别降低了在为芯片光刻制造电阻器集合时的复杂性。使用量化电阻器值的过程,只有电阻的选定值对芯片制造是需要的。以这种方式,该示例过程简化了芯片制造的整个过程,并且在需要时实现自动电阻器光刻掩模制造。
[0368]
图18提供了根据一些实现的用于电阻器量化的神经元模型1800的示例方案。在一些实现中,电路基于运算放大器1824(例如,ad824系列精密放大器),其从负权重固定电阻器(r1-1804、r2-1806、rb-偏差1816、rn-1818和r-1812)和正权重固定电阻器(r1 1808、r2 1810、rb 偏差1820、rn 1822和r 1814)接收输入信号。正权重电压被馈送到运算放大器1824的直接输入端,以及负权重电压被馈送到运算放大器1824的反向输入端。运算放大器1824用于允许来自每个电阻器的加权输出的加权求和运算,其中负权重从正权重被减去。运算放大器1824还将信号放大到电路操作所必需的程度。在一些实现中,运算放大器1824还在它的输出级联处完成输出信号的relu变换。
[0369]
下面的方程基于电阻器值确定权重:
[0370]
在神经元的输出处的电压由下面的方差确定:
[0371]
[0372]
每个连接的权重由下面的方程确定:
[0373][0374]
根据一些实现,下面的示例优化过程量化每个电阻的值,并最小化神经网络输出的误差:
[0375]
1.获得连接权重和偏差的集合{w1,
…
,wn,b}。
[0376]
2.获得可能的最小和最大电阻器值{rmin,rmax}。这些参数根据用于制造的技术来确定。一些实现使用tan或碲高电阻率材料。在一些实现中,电阻器的最小值由可以光刻地形成的最小平方(minimum square)来确定。最大值由对电阻器(例如由tan或碲制成的电阻器)可允许的长度确定以调整到期望面积,该期望面积又由在光刻掩模上的运算放大器正方形的面积确定。在一些实现中,电阻器的阵列的面积小于一个运算放大器的面积,因为电阻器的阵列是堆叠的(例如,一个在beol中,另一个在feol中)。
[0377]
3.假设每个电阻器具有r_err相对公差值
[0378]
4.目标是基于{w1,
…
,wn,b}值来选择在所定义的[rmin;rmax]内的给定长度n的电阻器值的集合{r1,
…
,rn}。下面提供了示例搜索算法以基于特定的优化准则来找到次优{r1,
…
,rn}集合。
[0379]
5.另一种算法为网络选择{rn,rp,rni,rpi},假设{r1
…
..rn}被确定。示例{r1,
……
,rn}搜索算法
[0380]
一些实现使用迭代方法用于电阻器集合搜索。一些实现在所定义的范围内选择初始(随机或均匀)集合{r1,
…
,rn}。一些实现选择电阻器集合的元素之一作为r-=r 值。一些实现通过当前学习速率值来改变在该集合内的每个电阻器,直到这样的改变产生“更好”的集合(根据值函数)为止。对该集合中的所有电阻器并使用几个不同的学习速率值重复该过程,直到没有进一步的改进是可能的为止。
[0381]
一些实现将电阻器集合的值函数定义如下:
[0382]
根据(上述的)公式计算可能的权重选项:
[0383][0384]
基于由ic制造技术确定的潜在电阻器相对误差r_err来估计每个权重选项的预期误差值。
[0385]
权重选项列表被限定或限制到[-wlim;wlim]范围。
[0386]
移除一些值,其具有的预期误差超过高阈值(例如,10倍于r_err)。
[0387]
值函数被计算为在两个邻近权重选项之间的距离的平方平均数(square mean)。所以,当权重选项被均匀地分布在[-wlim;wlim]
[0388]
范围内时,值函数是最小的。
[0389]
假设模型的所需权重范围[-wlim;wlim]被设定为[-5;5],且其他参数包括n=20,r_err=0.1%,rmin=100kω,rmax=5mω。在这里,rmin和rmax分别是电阻的最小值和最大值。
[0390]
在一个实例中,对于上面提到的参数,获得长度20的下面的电阻器集合:[0.300,
0.461,0.519,0.566,0.648,0.655,0.689,0.996,1.006,1.048,1.186,1.222,1.261,1.435,1.488,1.524,1.584,1.763,1.896,2.02]mω.r-=r =1.763mω。
[0391]
示例{rn,rp,rni,rpi}搜索算法
[0392]
一些实现使用迭代算法(例如上述算法)来确定rn和rp。一些实现设定rp=rn(确定rn和rp的任务是对称的,这两个量通常收敛到一个相似值)。然后,对于每个权重wi,一些实现选择一对电阻{rni,rpi},其最小化所估计的权重误差值:
[0393][0394]
一些实现随后使用{rni;rpi;rn;rp}值集合来实现神经网络电路图。在一个实例中,根据一些实现,电路图产生在10,000个均匀地分布的输入数据样本的集合上的11mv的均方输出误差(有时被称为上面所述的s均方输出误差)和33mv的最大误差。在一个实例中,s模型连同数模转换器(dac)、模数转换器(adc)一起被分析,其中256个电平(level)作为一个单独的模型。根据一些实现,该模型在同一数据集上产生14mv均方输出误差和49mv最大输出误差。dac和adc具有电平,因为它们将模拟值转换成位值,反之亦然。数字值的8位等于256个电平。对于8位adc,精度无法好于1/256。
[0395]
一些实现在连接的权重已知时基于基尔霍夫电路定律和运算放大器的基本原理(下面参考图19a描述的),使用mathcad或任何其他类似软件来计算模拟ic芯片的电阻值。在一些实现中,运算放大器既用于信号的放大又用于根据激活函数(例如relu、sigmoid、正切双曲或线性数学方程)的变换。
[0396]
一些实现在光刻层中制造电阻器,其中电阻器被形成为在sio2矩阵中的圆柱形孔,并且电阻值由孔的直径决定。一些实现使用非晶的tan、tin、crn或碲作为高电阻材料来制造高密度电阻器阵列。ta与n、ti与n和cr与n的一些比率提供了用于制造超高密度、高电阻率元件阵列的高电阻。例如,对于tan、ta5n6、ta3n5,n与ta的比率越高,电阻率就越高。一些实现使用ti2n、tin、crn或cr5n,并相应地确定比率。tan沉积是在芯片制造中使用的标准程序,且在所有主要的铸造厂中是可用的。
[0397]
示例运算放大器
[0398]
图19a示出了根据一些实现的在cmos(cmos opamp)1900上制造的运算放大器的示意图。在图19a中,in (正输入端或pos)1404、in-(负输入端或neg)1406和vdd-(相对于gnd的正电源电压)1402是接点(contact)输入端。接点vss-(负电源电压或gnd)由标签1408指示。电路输出为out 1410(接点输出端)。cmos晶体管的参数由以下几何尺寸的比率确定:l(栅极沟道的长度)与w(栅极沟道的宽度),其例子在图19b所示的表中示出(下面描述的)。电流镜在nmos晶体管m11 1944、m12 1946和电阻器r1 1921(具有12kω的示例电阻值)上被制造,并提供差分对(m1 1926和m3 1930)的补偿电流。差分放大器级(差分对)在nmos晶体管m1 1926和m3 1930被制造。晶体管m1、m3进行放大,而pmos晶体管m2 1928和m4 1932起有源电流负载的作用。信号从m3晶体管输入到输出pmos晶体管m7 1936的栅极。信号从晶体管m1输入到pmos晶体管m5(反相器)1934和在nmos晶体管m6 1934上的有源负载。流经晶体管m5 1934的电流被设置用于nmos晶体管m8 1938。晶体管m7 1936在具有用于正半波信号的公共源的情况下被包括在该方案中。m8晶体管1938由用于负半波信号的公共源电路使能。
为了增加运算放大器的总负载能力,m7 1936和m8 1938的输出包括在m9 1940和m101942晶体管上的反相器。电容器c1 1912和c2 1914阻塞。
[0399]
图19b示出了根据一些实现的图19a所示的示例电路的描述的表1948。参数的值作为例子被提供,并且各种其他配置是可能的。晶体管m1、m3、m6、m8、m10、m11和m12是具有显式衬底连接的n沟道mosfet晶体管。其他晶体管m2、m4、m5、m7和m9是具有显式衬底连接的p沟道mosfet晶体管。该表示出了针对每个晶体管(列3)提供的示例的快门长度比(shutter ratio of length)(l,列1)和快门宽度比(shutter ratio of width)(w,列2)。
[0400]
在一些实现中,运算放大器(例如上面所述的示例)被用作用于神经网络的硬件实现的集成电路的基本元件。在一些实现中,运算放大器具有40平方微米的尺寸,且根据45nm节点标准被制造。
[0401]
在一些实现中,激活函数(例如relu、双曲正切和sigmoid函数)由具有修改的输出级联的运算放大器表示。例如,根据一些实现,使用对应的众所周知的模拟电路图来将relu、sigmoid或正切函数实现为运算放大器(有时被称为opamp)的输出级联。
[0402]
在上面和下面描述的示例中,在一些实现中,运算放大器由允许加权求和运算的反相器、电流镜、两象限或四象限乘法器和/或其他模拟函数块代替。
[0403]
lstm块的示例方案
[0404]
图20a-20e示出了根据一些实现的lstm神经元20000的示意图。神经元的输入是vin1 20002和vin2 20004,其为在范围[-0.1,0.1]内的值。lstm神经元还输入计算神经元在某时间的结果的值h(t-1)(前一值;见上面对lst神经元的描述)20006和神经元在某时间的状态向量c(t-1)(前一值)20008。神经元lstm(在图20b中示出)的输出包括计算神经元在当前时间的结果h(t)20118和神经元在当前时间的状态向量c(t)20120。该方案包括:
[0405]
在图20a中示出的运算放大器u1 20094和u2 20100上装配的“神经元o”。电阻器r_wo1 20018、r_wo2 20016、r_wo3 20012、r_wo4 20010、r_uop1 20014、r_uom1 20020、rr 20068和rf220066设定单个“神经元o”的连接的权重。“神经元o”使用sigmoid(模块x1 20078,图20b)作为非线性函数;
[0406]
在运算放大器u3 20098(在图20c中示出)和u4 20100(在图20a中示出)上装配的“神经元c”。电阻器r_wc1 20030、r_wc2 20028、r_wc3 20024、r_wc4 20022、r_ucp1 20026、r_ucm1 20032、rr 20122和rf2 20120设定“神经元c”的连接的权重。“神经元c”使用双曲正切(模块x2 22080,图2b)作为非线性函数;
[0407]
在图20c中示出的运算放大器u5 20102和u6 20104上装配的“神经元i”。电阻器r_wi1 20042、r_wi2 20040、r_wi3 20036和r_wi4 20034、r_uip1 20038、r_uim1 20044、rr 20124和rf220126设定“神经元i”的连接的权重。“神经元i”使用sigmoid(模块x3 20082)作为非线性函数;以及
[0408]
如在图20d中示出的运算放大器u7 20106和u8 20108上装配的“神经元f”。电阻器r_wf1 20054、r_wf2 20052、r_wf3 20048、r_wf4 20046、r_ufp1 20050、r_ufm1 20056、rr 20128和rf220130设定“神经元f”的连接的权重。“神经元f”使用sigmoid(模块x4 20084)作为非线性函数。
[0409]
模块x2 20080(图20b)和x3 20082(图20c)的输出被输入到x5乘法器模块20086(图20b)。模块x4 20084(图20d)和缓冲器u9 20010的输出被输入到乘法器模块x6 20088。
2074、m14 21076和pmos晶体管m15 2078以及m16 21080上装配的多路复用器。该多路复用器的输出被输入到m5 21058nmos晶体管(在图21d中示出);
[0418]
v_one 21020和negb 21012被输入到在pmos晶体管m18 21084、m48 21144、m49 21146和m50 21148以及nmos晶体管m1721082、m47 21142上装配的多路复用器。该多路复用器的输出被输入到m9 pmos晶体管21066(在图21d中示出);
[0419]
nega 21010和v_two 21008被输入到在pmos晶体管m52 21152、m54 21156、m55 21158和m56 21160以及nmos晶体管m5121150和m53 21154上装配的多路复用器。该多路复用器的输出被输入到m2 nmos晶体管21054(在图21c中示出);
[0420]
negb 21012和v_one 21020被输入到在nmos晶体管m11 21070、m12 21072、m13 21074和m14 21076以及pmos晶体管m1521078和m16 21080上装配的多路复用器。该多路复用器的输出被输入到m10 nmos晶体管21068(在图21d中示出);
[0421]
negb 21012和nega 21010被输入到在nmos晶体管m35 21118、m36 21120、m37 21122和m38 21124以及pmos晶体管m3921126和m40 21128上装配的多路复用器。该多路复用器的输出被输入到m27 pmos晶体管21102(在图21h中示出);
[0422]
v_two 21008和v_one 21020被输入到在nmos晶体管m41 21130、m42 21132、m43 21134和m44 21136以及pmos晶体管m4521138和m46 21140上装配的多路复用器。该多路复用器的输出被输入到m30 nmos晶体管21108(在图21h中示出);
[0423]
v_one 21020和v_two 21008被输入到在pmos晶体管m58 21162、m60 21166、m61 21168和m62 21170以及nmos晶体管m5721160和m59 21164上装配的多路复用器。该多路复用器的输出被输入到m34 pmos晶体管21116(在图21h中示出);以及
[0424]
nega 21010和negb 21012被输入到在pmos晶体管m64 21174、m66 21178、m67 21180和m68 21182以及nmos晶体管m6321172和m65 21176上装配的多路复用器。该多路复用器的输出被输入到pmos晶体管m33 21114(在图21h中示出)。
[0425]
电流镜(晶体管m1 21052、m2 21053、m3 21054和m4 21056)为在左侧所示的由晶体管m5 21058、m6 21060、m7 21062、m8 21064、m9 21066和m10 21068制成的四象限乘法器电路的部分供电。电流镜(在晶体管m25 21098、m26 21100、m27 21102和m28 21104上)为由晶体管m2921106、m30 21108、m31 21110、m32 21112、m33 21114和m34 21116制成的四象限乘法器的右部分的电源供电。乘法结果取自与晶体管m3 21054并联的被使能的电阻器ro 21022和与晶体管m28 21104并联的被使能的电阻器ro 21188,被提供给在u3 21044上的加法器。u3 21044的输出被提供给具有7,1的增益的加法器,该加法器被装配在u5 21048上,u5 21048的第二个输入由电阻r1 21024和r2 21026以及缓冲器u4 21046所设定的参考电压补偿,如图21i所示。乘法结果从u5 21048的输出经由mult_out输出21170被输出。
[0426]
图21j示出了根据一些实现的图21a-21i所示的示意图的描述的表21198。u1
–
u5是cmos opamp。具有显式衬底连接的n沟道mosfet晶体管包括晶体管m1、m2、m25和m26(具有快门长度比(l)=2.4u和快门宽度比(w)=1.26u)、晶体管m5、m6、m29和m30(具有l=0.36u和w=7.2u)、晶体管m7、m8、m31和m32(具有l=0.36u和w=199.98u)、晶体管m11-m14、m19-m22、m35-m38和m41-m44(具有l=0.36u和w=0.4u)以及晶体管m17、m47、m51、m53、m57、m59、m43和m64(具有l=0.36u和w=0.72u)。具有显式衬底连接的p沟道mosfet晶体管包括晶体管m3、m4、m27和m28(具有快门长度比(l)=2.4u和快门宽度比(w)=1.26u)、晶体管m9、m10、
m33和m34(具有l=0.36u和w=7.2u)、晶体管m18、m48、m49、m50、m52、m54、m55、m56、m58、m60、m61、m62、m64、m66、m67和m68(具有l=0.36u和w=0.8u)以及晶体管m15、m16、m23、m24、m39、m40、m45和m46(具有l=0.36u和w=0.72u)。根据一些实现,示例电阻器额定值包括ro=1kω、rin=1kω、rf=1kω、rc4=2kω和rc5=2kω。
[0427]
sigmoid块的示例方案
[0428]
图22a示出了根据一些实现的sigmoid块2200的示意图。使用运算放大器u1 2250、u2 2252、u3 2254、u4 2256、u5 2258、u6 2260、u7 2262和u8 2264以及nmos晶体管m1 2266、m2 2268和m3 2270来实现sigmoid函数(例如,上面参考图20a-20f描述的模块x1 20078、x3 20082和x4 20084)。接点sigm_in 2206是模块输入,接点输入vdd1 2222是相对于gnd 2208的正电源电压 1.8v,以及接点vss1 2204是相对于gnd的负电源电压-1.0v。在该方案中,u4 2256具有-0.2332v的参考电压源,以及该电压由分压器r10 2230和r11 2232设定。u5 2258具有0.4v的参考电压源,以及该电压由分压器r12 2234和r13 2236设定。u6 2260具有0.32687v的参考电压源,该电压由分压器r14 2238和r15 2240设定。u7 2262具有-0.5v的参考电压源,该电压由分压器r16 2242和r17 2244设定。u8 2264具有-0.33v的参考电压源,该电压由分压器r18 2246和r19 2248设定。
[0429]
通过将在晶体管m1 2266和m2 2268上装配的差分模块上的对应参考电压相加来形成sigmoid函数。利用有源调节运算放大器u3 2254和nmos晶体管m3 2270装配差分级的电流镜。来自差分级的信号用nmos晶体管m2移除,并且电阻器r5 2220被输入到加法器u2 2252。输出信号sigm_out 2210从u2加法器2252的输出被移除。
[0430]
图22b示出了根据一些实现的图22a所示的示意图的描述的表2278。u1-u8是cmos opamp。根据一些实现,m1、m2和m3是具有快门长度比(l)=0.18u和快门宽度比(w)=0.9u的n沟道mosfet晶体管。
[0431]
双曲正切块的示例方案
[0432]
图23a示出了根据一些实现的双曲正切函数块2300的示意图。使用运算放大器(u1 2312、u2 2314、u3 2316、u4 2318、u5 2320、u6 2322、u7 2328和u8 2330)和nmos晶体管(m1 2332、m2 2334和m3 2336)来实现双曲正切函数(例如,上面参考图20a-20f描述的模块x2 20080和x7 20090)。在该方案中,接点tanh_in 2306是模块输入,接点输入vdd12304是相对于gnd 2308的正电源电压 1.8v,接点vss1 2302是相对于gnd的负电源电压-1.0v。此外,在该方案中,u4 2318具有-0.1v的参考电压源,该电压由分压器r10 2356和r11 2358设定。u5 2320具有1.2v的参考电压源,该电压由分压器r12 2360和r13 2362设定。u6 2322具有0.32687v的参考电压源,该电压由分压器r14 2364和r15 2366设定。u7 2328具有-0.5v的参考电压源,该电压由分压器r16 2368和r17 2370设定。u8 2330具有-0.33v的参考电压源,该电压由分压器r18 2372和r19 2374设定。通过将在晶体管m1 2332和m2 2334上制造的差分模块上的对应参考电压相加来形成双曲正切函数。用有源调节运算放大器u32316和nmos晶体管m3 2336获得差分级的电流镜。利用nmos晶体管m2 2334和电阻器r5 2346,信号从差分级移除并被输入到加法器u2 2314。输出信号tanh_out 2310从u2加法器2314的输出被移除。
[0433]
图23b示出了根据一些实现的图23a所示的示意图的描述的表2382。u1-u8是cmos opamp,以及m1、m2和m3是具有快门长度比(l)=0.18u和快门宽度比(w)=0.9u的n沟道
mosfet晶体管。
[0434]
单神经元op1 cmos opamp的示例方案
[0435]
图24a-24c示出了根据一些实现的单神经元op1 cmos opamp_2400的示意图。该示例是根据本文描述的op1方案在cmos上制成的运算放大器上的单神经元的变型。在该方案中,接点v1 2410和v2 2408是单神经元的输入,接点偏差2406是相对于gnd的电压 0.4v,接点输入vdd2402是相对于gnd的正电源电压 5.0v,接点vss 2404是gnd,以及接点out 2474是单神经元的输出。cmos晶体管的参数由几何尺寸的比率确定:l(栅极沟道的长度)和w(栅极沟道的宽度)。该op amp具有两个电流镜。在nmos晶体管m3 2420、m6 2426和m13 2440上的电流镜提供在nmos晶体管m2 2418和m5 2424上的差分对的补偿电流。在pmos晶体管m7 2428、m8 2430和m15 2444中的电流镜提供在pmos晶体管m9 2432和m10 2434上的差分对的补偿电流。在第一差分放大器级中,nmos晶体管m2 2418和m5 2424进行放大,而pmos晶体管m1 2416和m4 2422起有源电流负载的作用。信号从m5 2424晶体管输出到晶体管m13 2440的pmos栅极。信号从m2 2418晶体管输出到在pmos晶体管m9 2432和m10 2434上的第二差分放大器级的右输入端。nmos晶体管m11 2436和m12 2438对m9 2432和m10 2434晶体管起有源电流负载的作用。m17 2448晶体管根据该方案在具有用于信号的正半波的公共源的情况下被导通。m18 2450晶体管根据该方案在具有用于信号的负半波的公共源的情况下被导通。为了增加op amp的总负载能力,在m17 2448和m182450晶体管上的反相器在m13 2440和m14 2442晶体管的输出端处被使能。
[0436]
图24d示出了根据一些实现的图24a-24c所示的示意图的描述的表2476。单神经元(具有两个输入端和一个输出端)的连接的权重由电阻器比率设定:w1=(rp/r1 )
–
(rn/r1-);w2=(rp/r2 )
–
(rn/r2-);w偏差=(rp/rbias )
–
(rn/rbias-)。归一化电阻器(rnorm-和rnorm )对获得精确相等是必要的:(rn/r1-) (rn/r2-) (rn/rbias-) (rn/rnorm-)=(rp/r1 ) (rp/r2 ) (rp/rbias ) (rp/rnorm )。具有显式衬底连接的n沟道mosfet晶体管包括具有l=0.36u和w=3.6u的晶体管m2和m5、具有l=0.36u和w=1.8u的晶体管m3、m6、m11、m12、m14和m16以及具有l=0.36u和w=18u的晶体管m18。具有显式衬底连接的p沟道mosfet晶体管包括具有l=0.36u和w=3.96u的晶体管m1、m4、m7、m8、m13和m15、具有l=0.36u和w=11.88u的晶体管m9和m10以及具有l=0.36u和w=39.6u的晶体管m17。
[0437]
单神经元op3cmos opamp的示例方案
[0438]
图25a-25d示出了根据一些实现的根据op3方案在cmos上制造的运算放大器上的单神经元25000的变型的示意图。根据一些实现,单神经元由三个简单运算放大器(opamp)组成。单位神经元加法器在具有双极电源的两个opamp上被执行,以及relu激活函数在具有单极电源并具有=10的增益的opamp上被执行。晶体管m1 25028
–
m16 25058用于神经元的负连接的求和。晶体管m17 25060
–
m32 25090用于使神经元的正连接相加。relu激活函数在晶体管m33 25092
–
m46 25118上被执行。在该方案中,接点v1 25008和v2 25010是单神经元的输入,接点偏差25002是相对于gnd的电压 0.4v,接点输入vdd 25004是相对于gnd的正电源电压 2.5v,接点vss 25006是负电源电压-2.5v,以及接点out 25134是单神经元的输出。在单神经元中使用的cmos晶体管的参数由几何尺寸的比率确定:l(栅极沟道的长度)和w(栅极沟道的宽度)。考虑在单神经元中包括的最简单的opamp的操作。每个op amp具有两个电流镜。在nmos晶体管m3 25032(m19 25064、m35 25096)、m6 25038(m22 25070、m3825102)
和m16 25058(m32 25090、m48 25122)上的电流镜提供在nmos晶体管m2 25030(m18 25062、m34 25094)和m5 25036(m21 25068、m35 25096)上的差分对的补偿电流。在pmos晶体管m7 25040(m2325072、m39 25104)、m8 25042(m24 25074、m40 25106)和m15 25056(m31 2588)中的电流镜提供在pmos晶体管m9 25044(m25 25076、m41 25108)和m10 25046(m26 25078、m42 25110)上的差分对的补偿电流。在第一差分放大器级中,nmos晶体管m2 25030(m18 25062、m34 25094)和m5 25036(m21 25068、m37 25100)进行放大,以及pmos晶体管m1 25028(m17 25060、m33 25092)和m4 25034(m20 25066、m36 25098)起有源电流负载的作用。信号从晶体管m5 25036(m21 25068、m37 25100)输入到晶体管m13 25052(m29 25084、m45 25116)的pmos栅极。信号从晶体管m2 25030(m18 25062、m34 25094)输入到在pmos晶体管m9 25044(m25 25076,m41 25108)和m10 25046(m26 25078、m42 25110)上的第二差分放大器级的右输入端。nmos晶体管m11 25048(m27 25080、m43 25112)和m12 25048(m28 25080,m44 25114)对晶体管m9 25044(m25 25076、m41 25108)和m10 25046(m26 25078、m42 25110)起有源电流负载的作用。晶体管m13 25052(m29 25082、m45 25116)在具有用于正半波信号的公共源的情况下被包括在该方案中。晶体管m14 25054(m30 25084、m46 25118)在具有用于信号负半波的公共源的情况下根据该方案被导通。
[0439]
单神经元(具有两个输入端和一个输出端)的连接的权重由电阻器比率设定:w1=(r反馈/r1 )
–
(r反馈/r1-);w2=(r反馈/r2 )
–
(r反馈/r2-);wbias=(r反馈/rbias )
–
(r反馈/rbias-);w1=(r p*kamp/r1 )
–
(r n*k amp/r1-);w2=(r p*k amp/r2 )
–
(r n*k amp/r2-);wbias=(r p*k amp/rbias )
–
(r n*k amp/rbias-),其中k amp=r1relu/r2relu。r反馈=100k,仅用于计算w1、w2、w偏差。根据一些实现,示例值包括:r反馈=100k,rn=rp=rcom=10k,k amp relu=1 90k/10k=10,w1=(10k*10/22.1k)
–
(10k*10/21.5k)=-0.126276,w2=(10k*10/75k)
–
(10k*10/71.5k)=-0.065268,wbias=(10k*10/71.5k)
–
(10k*10/78.7k)=0.127953。
[0440]
神经元的负链加法器(m1
–
m17)的输入通过rcom电阻器从神经元的正链加法器(m17
–
m32)被接收。
[0441]
图25e示出了根据一些实现的图25a-25d所示的示意图的描述的表25136。具有显式衬底连接的n沟道mosfet晶体管包括具有l=0.36u和w=3.6u的晶体管m2、m5、m18、m21、m34和m37、具有l=0.36u和w=1.8u的晶体管m3、m6、m11、m12、m14、m16、m19、m22、m27、m28、m32、m38、m35、m38、m43、m44、m46和m48。具有显式衬底连接的p沟道mosfet晶体管包括具有l=0.36u和w=3.96u的晶体管m1、m4、m7、m8、m13、m15、m17、m20、m23、m24、m29、m31、m33、m36、m39、m40、m45和m47以及具有l=0.36u和w=11.88u的晶体管m9、m10、m25、m26、m41和m42。
[0442]
用于训练后的神经网络的模拟硬件实现的示例方法
[0443]
图27a-27j示出了根据一些实现的用于神经网络的硬件实现(2702)的方法2700的流程图。该方法在计算设备200处(例如,使用神经网络变换模块226)被执行(2704),该计算设备200具有一个或更多个处理器202和存储被配置用于由一个或更多个处理器202执行的一个或更多个程序的存储器214。该方法包括获得(2706)训练后的神经网络(例如网络220)的神经网络拓扑(例如拓扑224)和权重(例如权重222)。在一些实现中,使用软件仿真来训练(2708)训练后的神经网络以生成权重。
[0444]
该方法还包括将神经网络拓扑变换(2710)成模拟部件的等效模拟网络。接下来参
考图27c,在一些实现中,神经网络拓扑包括(2724)一层或更多层神经元。每层神经元基于相应数学函数计算相应输出。在这样的情况下,将神经网络拓扑变换成模拟部件的等效模拟网络包括对于一层或更多层神经元的每一层执行(2726)一系列步骤。该一系列步骤包括基于相应数学函数针对相应层识别(2728)一个或更多个函数块。每个函数块具有相应示意实现,其具有符合相应数学函数的输出的块输出。在一些实现中,识别一个或更多个函数块包括基于相应层的类型来选择(2730)一个或更多个函数块。例如,一个层可以由神经元组成,且该层的输出是它的输入的线性叠加。如果层的输出是线性叠加,则选择一个或更多个函数块基于层类型的这个识别或类似的模式识别。一些实现确定输出的数量是否大于1,然后使用梯形或者金字塔变换。
[0445]
接下来参考图27d,在一些实现中,一个或更多个函数块包括从由下列项组成的组中选择(2734)的一个或更多个基本函数块(例如,基本函数块232):(i)具有块输出v
out
=relu(∑wi.v
iin
bias)的加权求和块(2736)。relu是修正线性单元(relu)激活函数或类似的激活函数(例如,具有阈值的relu),vi表示第i个输入,wi表示对应于第i个输入的权重,以及bias表示偏差值,并且∑是求和运算符;(ii)具有块输出v
out
=coeff.vi.vj的信号乘法器块(2738)。vi表示第i个输入,以及vj表示第j个输入,并且coeff是预定系数;(iii)具有块输出的sigmoid激活块(2740)。v表示输入,以及a和b是sigmoid激活块的预定系数值(例如,a=-0.1;b=11.3);(iv)具有块输出v
out
=a*tanh(b*v
in
)的双曲正切激活块(2742),v
in
表示输入,以及a和b为预定系数值(例如,a=0.1,b=-10.1);以及具有块输出u(t)=v(t-dt)的信号延迟块(2744)。t表示当前时间段,v(t-1)表示前一时间段t-1的信号延迟块的输出,以及dt是延迟值。
[0446]
现在回来参考图27c,该一系列步骤还包括基于排列一个或更多个函数块来生成(2732)模拟神经元的相应多层网络。每个模拟神经元实现一个或更多个函数块的相应函数,并且多层网络的第一层的每个模拟神经元连接到多层网络的第二层的一个或更多个模拟神经元。
[0447]
现在回来参考图27a,根据一些实现,对于一些网络,例如gru和lstm,将神经网络拓扑变换(2710)成模拟部件的等效模拟网络需要更复杂的处理。接下来参考图27e,假设神经网络拓扑包括(2746)一层或更多层神经元。进一步假设每层神经元基于相应数学函数计算相应输出。在这样的情况下,将神经网络拓扑变换成模拟部件的等效模拟网络包括:(i)将神经网络拓扑的第一层分解(2748)成多个子层,包括分解对应于第一层的数学函数以获得一个或更多个中间数学函数。每个子层实现一个中间数学函数。在一些实现中,对应于第一层的数学函数包括一个或更多个权重,并且分解数学函数包括调整(2750)一个或更多个权重,使得组合一个或更多个中间函数产生数学函数;以及(ii)对于神经网络拓扑的第一层的每个子层执行(2752)一系列步骤。该一系列步骤包括:基于相应的中间数学函数针对相应子层选择(2754)一个或更多个子函数块;以及基于排列一个或更多个子函数块来生成(2756)模拟神经元的相应多层模拟子网。每个模拟神经元实现一个或更多个子函数块的相应函数,并且多层模拟子网的第一层的每个模拟神经元连接到多层模拟子网的第二层的一个或更多个模拟神经元。
[0448]
接下来参考图27h,假设神经网络拓扑包括(2768)一个或更多个gru或lstm神经
元。在那种情况下,变换神经网络拓扑包括针对一个或更多个gru或lstm神经元的每个循环连接生成(2770)一个或更多个信号延迟块。在一些实现中,外部循环定时器以恒定时间段(例如1、5或10个时间步长)激活一个或更多个信号延迟块。一些实现在一个信号上使用多个延迟块用于产生附加时间移位。在一些实现中,一个或更多个信号延迟块的激活频率与网络输入信号频率同步。在一些实现中,一个或更多个信号延迟块在与神经网络拓扑的预定输入信号频率匹配的频率处被激活(2772)。在一些实现中,该预定输入信号频率可以取决于应用,例如人类活动识别(har)或ppg。例如,对于视频处理的预定输入信号频率是30-60hz,对于har和ppg是100hz左右,对于声音处理是16khz,以及对于电池管理是1-3hz左右。一些实现激活不同的信号延迟块,其在不同的频率处激活。
[0449]
接下来参考图27i,假设神经网络拓扑包括(2774)执行无限激活函数的一层或更多层神经元。在一些实现中,在这样的情况下,变换神经网络拓扑包括应用(2776)选自由下列项组成的组的一个或更多个变换:用有限激活代替(2778)无限激活函数(例如,用阈值relu代替relu);以及调整(2780)等效模拟网络的连接或权重,使得对于预定的一个或更多个输入,在训练后的神经网络和等效模拟网络之间的输出的差异被最小化。
[0450]
现在回来参考图27a,该方法还包括基于训练后的神经网络的权重来计算(2712)等效模拟网络的权重矩阵。权重矩阵的每个元素表示在等效模拟网络的模拟部件之间的相应连接。
[0451]
该方法还包括基于权重矩阵生成(2714)用于实现等效模拟网络的示意模型,包括选择模拟部件的部件值。接下来参考图27b,在一些实现中,生成示意模型包括针对权重矩阵生成(2716)电阻矩阵。电阻矩阵的每个元素对应于权重矩阵的相应权重,并表示电阻值。在一些实现中,该方法包括针对再训练后的网络仅重新生成电阻器的电阻矩阵。在一些实现中,该方法还包括获得(2718)训练后的神经网络的新权重,基于新权重来计算(2720)等效模拟网络的新权重矩阵,以及针对新权重矩阵生成(2722)新电阻矩阵。
[0452]
接下来参考图27j,在一些实现中,方法还包括基于电阻矩阵来生成(2782)用于制造实现模拟部件的等效模拟网络的电路的一个或更多个光刻掩模(例如,使用掩模生成模块248来生成掩模250和/或252)。在一些实现中,该方法包括针对经再训练后的网络仅重新生成电阻器的掩模(例如掩模250)。在一些实现中,该方法还包括:(i)获得(2784)训练后的神经网络的新权重;(ii)基于新权重来计算(2786)等效模拟网络的新权重矩阵;(iii)针对新权重矩阵生成(2788)新电阻矩阵;以及(iv)基于新电阻矩阵来生成(2790)用于制造实现模拟部件的等效模拟网络的电路的新光刻掩模。
[0453]
现在回来参考图27g,模拟部件包括(2762)多个运算放大器和多个电阻器。每个运算放大器表示等效模拟网络的一个模拟神经元,以及每个电阻器表示在两个模拟神经元之间的连接。一些实现包括其他模拟部件,例如四象限乘法器、sigmoid函数电路和双曲正切函数电路、延迟线、求和器和/或分压器。在一些实现中,选择(2764)模拟部件的部件值包括执行(2766)梯度下降方法和/或其他权重量化方法以识别多个电阻器的可能电阻值。
[0454]
现在回来参考图27f,在一些实现中,该方法还包括在输出层中数字地实现某些激活函数(例如softmax)。在一些实现中,该方法还包括针对神经网络拓扑的一个或更多个输出层生成(2758)数字部件的等效数字网络,以及将等效模拟网络的一个或更多个层的输出连接(2760)到数字部件的等效数字网络。
[0455]
用于神经网络的受约束模拟硬件实现的示例方法
[0456]
图28a-28s示出了根据一些实现的用于根据硬件设计约束的神经网络的硬件实现(28002)的方法28000的流程图。该方法在计算设备200处(例如,使用神经网络变换模块226)被执行(28004),该计算设备200具有一个或更多个处理器202和存储被配置用于由一个或更多个处理器202执行的一个或更多个程序的存储器214。该方法包括获得(28006)训练后的神经网络(例如网络220)的神经网络拓扑(例如拓扑224)和权重(例如权重222)。
[0457]
该方法还包括基于模拟集成电路(ic)设计约束(例如约束236)来计算(28008)一个或更多个连接约束。例如,ic设计约束可以设定电流限制(例如1a),且神经元电路图和运算放大器(opamp)设计可以将opamp输出电流设定在范围[0-10ma]内,因此这将输出神经元连接限制到100。这意味着神经元具有100个输出,其允许电流通过100个连接流到下一层,但在运算放大器的输出端处的电流被限制到10ma,因此一些实现使用最多100个输出(0.1ma乘100=10ma)。在没有这个约束的情况下,一些实现使用电流中继器(current repeater)将输出的数量增加到例如多于100。
[0458]
该方法还包括将神经网络拓扑(例如,使用神经网络变换模块226)变换(28010)成满足一个或更多个连接约束的模拟部件的等效稀疏连接网络。
[0459]
在一些实现中,变换神经网络拓扑包括根据一个或更多个连接约束来导出(28012)可能的输入连接度ni和输出连接度no。
[0460]
接下来参考图28b,在一些实现中,神经网络拓扑包括(28018)具有k个输入(在前一层中的神经元)和l个输出(在当前层中的神经元)以及权重矩阵u的至少一个密集连接层,并且变换(28020)至少一个密集连接层包括构建(28022)具有k个输入、l个输出和个层的等效稀疏连接网络,使得输入连接度不超过ni,以及输出连接度不超过no。
[0461]
接下来参考图28c,在一些实现中,神经网络拓扑包括(28024)具有k个输入(在前一层中的神经元)和l个输出(在当前层中的神经元)以及权重矩阵u的至少一个密集连接层,并且变换(28026)至少一个密集连接层包括:构建(28028)具有k个输入、l个输出和个层的等效稀疏连接网络。每个层m由对应的权重矩阵um表示,其中缺少的连接用零表示,使得输入连接度不超过ni,以及输出连接度不超过no。方程u=π
m=1..m um以预定精度被满足。预定精度是合理的精度值,其在统计上保证改变的网络输出与参照网络(referent network)输出相差不大于被允许的误差值,并且该误差值是任务相关的(一般在0.1%和1%之间)。
[0462]
接下来参考图28d,在一些实现中,神经网络拓扑包括(28030)具有k个输入和l个输出、最大输入连接度pi、最大输出连接度po以及权重矩阵u的单个稀疏连接层,其中缺少的连接用零表示。在这样的情况下,变换(28032)单个稀疏连接层包括构建(28034)具有k个输入、l个输出、个层的等效稀疏连接网络。每个层m由对应的权重矩阵um表示,其中缺少的连接用零表示,使得输入连接度不超过ni,以及输出连接度不超过no,并且方程u=π
m=1..m um以预定精度被满足。
[0463]
接下来参考图28e,在一些实现中,神经网络拓扑包括(28036)具有k个输入(在前
一层中的神经元)和l个输出(在当前层中的神经元)的卷积层(例如深度卷积层或可分离卷积层)。在这样的情况下,将神经网络拓扑变换(28038)成模拟部件的等效稀疏连接网络包括将卷积层分解(28040)为具有k个输入、l个输出、最大输入连接度pi和最大输出连接度po的单个稀疏连接层,其中pi≤ni以及po≤no。
[0464]
回来参考图28a,该方法还包括基于训练后的神经网络的权重来计算(28014)等效稀疏连接网络的权重矩阵。权重矩阵的每个元素表示在等效稀疏连接网络的模拟部件之间的相应连接。
[0465]
现在参考图28f,在一些实现中,神经网络拓扑包括(28042)循环神经层,并且将神经网络拓扑变换(28044)成模拟部件的等效稀疏连接网络包括将循环神经层变换(28046)成具有信号延迟连接的一个或更多个密集或稀疏连接层。
[0466]
接下来参考图28g,在一些实现中,神经网络拓扑包括循环神经层(例如长短期记忆(lstm)层或门控循环单元(gru)层),以及将神经网络拓扑变换成模拟部件的等效稀疏连接网络包括将循环神经层分解成几个层,其中所述层中的至少一个等效于具有k个输入(在前一层中的神经元)和l个输出(在当前层中的神经元)和权重矩阵u的密集或稀疏连接层,其中缺少的连接用零表示。
[0467]
接下来参考图28h,在一些实现中,该方法包括执行具有一个计算神经元的单层感知器的变换。在一些实现中,神经网络拓扑包括(28054)k个输入、权重向量u∈rk和具有计算神经元的单层感知器,该计算神经元具有激活函数f。在这样的情况下,将神经网络拓扑变换(28056)成模拟部件的等效稀疏连接网络包括:(i)根据一个或更多个连接约束来导出(28058)等效稀疏连接网络的连接度n;(ii)使用方程来计算(28060)等效稀疏连接网络的层的数量m;以及(iii)构建(28062)具有k个输入、m个层和连接度n的等效稀疏连接网络。等效稀疏连接网络包括在m个层中的每一层中的相应的一个或更多个模拟神经元。前m-1个层的每个模拟神经元实现恒等变换,以及最后一层的模拟神经元实现单层感知器的计算神经元的激活函数f。此外,在这样的情况下,计算(28064)等效稀疏连接网络的权重矩阵包括通过基于权重向量u对方程组求解来计算(28066)等效稀疏连接网络的连接的权重向量w。方程组包括具有s个变量的k个方程,并且s使用方程被计算。
[0468]
接下来参考图28i,在一些实现中,该方法包括执行具有l个计算神经元的单层感知器的变换。在一些实现中,神经网络拓扑包括(28068)k个输入、具有l个计算神经元的单层感知器以及包括对于l个计算神经元中的每个计算神经元的一行权重的权重矩阵v。在这样的情况下,将神经网络拓扑变换(28070)成模拟部件的等效稀疏连接网络包括:(i)根据一个或更多个连接约束导出(28072)等效稀疏连接网络的连接度n;(ii)使用方程来计算(28074)等效稀疏连接网络的层的数量m;(iii)将单层感知器分解(28076)成l个单层感知器网络。每个单层感知器网络包括l个计算神经元中的相应计算神经元;(iv)对于l个单层感知器网络中的每个单层感知器网络(28078),针对相应单层感知器网络构建(28080)具有k个输入、m个层和连接度n的相应等效金字塔状子网。等效金字塔状子网在m个层中的每一层中包括一个或更多个相应模拟神经元,前m-1个层的每个模拟神
经元实现恒等变换,以及最后一层的模拟神经元实现对应于相应单层感知器的相应计算神经元的激活函数;以及(v)通过将每个等效金字塔状子网连接在一起来构建(28082)等效稀疏连接网络,包括将l个单层感知器网络的每个等效金字塔状子网的输入连接在一起以形成具有l*k个输入的输入向量。此外,在这样的情况下,计算(28084)等效稀疏连接网络的权重矩阵包括,对于l个单层感知器网络中的每个单层感知器网络(28086):(i)设定(28088)权重向量u=vi,权重矩阵v的第i行对应于相应计算神经元,相应计算神经元对应于相应单层感知器网络;以及(ii)通过基于权重向量u对方程组求解来计算(28090)相应等效金字塔状子网的连接的权重向量wi。该方程组包括具有s个变量的k个方程,并且s使用方程被计算。
[0469]
接下来参考图28j,在一些实现中,该方法包括对多层感知器执行变换算法。在一些实现中,神经网络拓扑包括(28092)k个输入、具有s个层的多层感知器,s个层中的每个层i包括一组对应的计算神经元li和对应的权重矩阵vi,权重矩阵vi包括li个计算神经元中的每个计算神经元的一行权重。在这样的情况下,将神经网络拓扑变换(28094)成模拟部件的等效稀疏连接网络包括:(i)根据一个或更多个连接约束为等效稀疏连接网络导出(28096)连接度n;(ii)将多层感知器分解(28098)成q=∑
i=1,s
(li)个单层感知器网络。每个单层感知器网络包括q个计算神经元中的相应计算神经元。分解多层感知器包括复制由q个计算神经元共享的k个输入中的一个或更多个输入;(iii)对于q个单层感知器网络中的每个单层感知器网络(28100):(a)使用方程计算(28102)相应等效金字塔状子网的层的数量m。k
i,j
是在多层感知器中的相应计算神经元的输入的数量;以及(b)针对相应单层感知器网络构建(28104)具有k
i,j
个输入、m个层和连接度n的相应等效金字塔状子网。等效金字塔状子网在m个层中的每个层中包括一个或更多个相应模拟神经元,前m-1个层的每个模拟神经元实现恒等变换,以及最后一层的模拟神经元实现对应于相应单层感知器网络的相应计算神经元的激活函数;以及(iv)通过将每个等效金字塔状子网连接在一起来构建(28106)等效稀疏连接网络,包括将q个单层感知器网络的每个等效金字塔状子网的输入连接在一起以形成具有q*k
i,j
个输入的输入向量。在这样的情况下,计算(28108)等效稀疏连接网络的权重矩阵包括:对于q个单层感知器网络中的每个单层感知器网络(28110):(i)设定(28112)权重向量u=v
ij
,权重矩阵v的第i行对应于相应计算神经元,相应计算神经元对应于相应单层感知器网络,其中j是在多层感知器中的相应计算神经元的对应层;以及(ii)通过基于权重向量u对方程组求解来计算(28114)相应等效金字塔状子网的连接的权重向量wi。方程组包括具有s个变量的k
i,j
个方程,以及s使用方程被计算。
[0470]
接下来参考图28k,在一些实现中,神经网络拓扑包括(28116)具有k个输入、s个层的卷积神经网络(cnn),s个层中的每个层i包括一组对应的计算神经元li和对应的权重矩阵vi,权重矩阵vi包括对于li个计算神经元中的每个计算神经元的一行权重。在这样的情况下,将神经网络拓扑变换(28118)成模拟部件的等效稀疏连接网络包括:(i)根据一个或更多个连接约束为等效稀疏连接网络导出(28120)连接度n;(ii)将cnn分解(28122)成q=∑
i=1,s
(li)个单层感知器网络。每个单层感知器网络包括q个计算神经元中的相应计算神经元。分解cnn包括复制由q个计算神经元共享的k个输入中的一个或更多个输入;(iii)对于q
个单层感知器网络中的每个单层感知器网络:(a)使用方程计算相应等效金字塔状子网的层的数量m。j是在cnn中的相应计算神经元的对应层,以及k
i,j
是在cnn中的相应计算神经元的输入的数量;以及(b)针对相应单层感知器网络构建具有k
i,j
个输入、m个层和连接度n的相应等效金字塔状子网。等效金字塔状子网在m个层中的每个层中包括一个或更多个相应模拟神经元,前m-1个层的每个模拟神经元实现恒等变换,以及最后一层的模拟神经元实现对应于相应单层感知器网络的相应计算神经元的激活函数;以及(iv)通过将每个等效金字塔状子网连接在一起来构建(28130)等效稀疏连接网络,包括将q个单层感知器网络的每个等效金字塔状子网的输入连接在一起以形成具有q*k
i,j
个输入的输入向量。在这样的情况下,计算(28132)等效稀疏连接网络的权重矩阵包括对于q个单层感知器网络中的每个单层感知器网络(28134):(i)设定权重向量u=v
ij
,权重矩阵v的第i行对应于相应计算神经元,相应计算神经元对应于相应单层感知器网络,其中j是在cnn中的相应计算神经元的对应层;以及(ii)通过基于权重向量u对方程组求解来计算相应等效金字塔状子网的连接的权重向量wi。方程组包括具有s个变量的k
i,j
个方程,以及s使用方程被计算。
[0471]
接下来参考图28l,在一些实现中,该方法包括将两个层变换成基于梯形的网络。在一些实现中,神经网络拓扑包括(28140)k个输入、具有k个神经元的层l
p
、具有l个神经元的层ln和权重矩阵w∈r
l
×k,其中r是实数的集合,层l
p
的每个神经元连接到层ln的每个神经元,以及层ln的每个神经元执行激活函数f,使得层ln的输出对于输入x使用方程yo=f(w.x)被计算。在这样的情况下,将神经网络拓扑变换(28142)成模拟部件的等效稀疏连接网络包括执行梯形变换,该梯形变换包括:(i)根据一个或更多个连接约束导出(28144)可能的输入连接度ni》1和可能的输出连接度no》1;以及(ii)根据k
·
l《l
·
ni k
·
no的确定,构建(28146)包括具有执行恒等激活函数的k个模拟神经元的层la
p
、具有执行恒等激活函数的个模拟神经元的层lah和具有执行激活函数f的l个模拟神经元的层lao的三层模拟网络,使得在层la
p
中的每个模拟神经元具有no个输出,在层lah中的每个模拟神经元具有不多于ni个输入和no个输出,以及在层lao中的每个模拟神经元具有ni个输入。在一些这样的情况下,计算(28148)等效稀疏连接网络的权重矩阵包括通过对矩阵方程wo.wh=w求解来生成(2850)稀疏权重矩阵wo和wh,该矩阵方程wo.wh=w包括采用k
·
no l
·
ni个变量的k
·
l个方程,使得层lao的总输出使用方程yo=f(wo.wh.x)被计算。稀疏权重矩阵wo∈rk×m表示在层la
p
和lah之间的连接,以及稀疏权重矩阵wh∈rm×
l
表示在层lah和lao之间的连接。
[0472]
接下来参考图28m,在一些实现中,执行梯形变换还包括:根据k
·
l≥l
·
ni k
·
no的确定:(i)使层l
p
分裂(28154)以获得具有k’个神经元的子层l
p1
和具有(k-k’)个神经元的子层l
p2
,使得k
′
·
l≥l
·
ni k
′
·
no;(ii)对于具有k’个神经元的子层l
p1
,执行(28156)构建和生成步骤;以及(iii)对于具有k-k’个神经元的子层l
p2
,循环地执行(28158)分裂、构建和生成步骤。
[0473]
接下来参考图28n,该方法包括将多层感知器变换成基于梯形的网络。在一些实现中,神经网络拓扑包括(28160)多层感知器网络。该方法还包括,对于多层感知器网络的每
对连续层,迭代地执行(28162)梯形变换并计算对于等效稀疏连接网络的权重矩阵。
[0474]
接下来参考图28o,该方法包括将循环神经网络变换成基于梯形的网络。在一些实现中,神经网络拓扑包括(28164)循环神经网络(rnn),其包括(i)对于两个完全连接层的线性组合的计算,(ii)逐元素相加,以及(iii)非线性函数计算。在这样的情况下,该方法还包括执行(28166)梯形变换并计算等效稀疏连接网络的权重矩阵,用于(i)两个完全连接层,和(ii)非线性函数计算。逐元素相加是可以在任何结构的网络中实现的常见操作,其例子在上面被提供。非线性函数计算是独立于no和ni限制的关于神经元的操作,且通常在每个神经元上单独地用“sigmoid”或“tanh”块被计算。
[0475]
接下来参考图28p,神经网络拓扑包括(28168)长短期记忆(lstm)网络或门控循环单元(gru)网络,其包括(i)多个完全连接层的线性组合的计算,(ii)逐元素相加,(iii)hadamard乘积,以及(iv)多个非线性函数计算(sigmoid和双曲正切运算)。在这样的情况下,该方法还包括执行(28170)梯形变换并计算等效稀疏连接网络的权重矩阵,用于(i)多个完全连接层,和(ii)多个非线性函数计算。逐元素相加和hadamard乘积是可以在上面所述的任何结构的网络中实现的常见操作。
[0476]
接下来参考图28q,神经网络拓扑包括(28172)卷积神经网络(cnn),其包括(i)多个部分连接层(例如,多个卷积和池化层的序列;每个池化层被假设为具有大于1的步幅的卷积层)和(ii)一个或更多个完全连接层(该序列在完全连接层中结束)。在这样的情况下,该方法还包括:(i)通过插入具有零权重的缺失连接来将多个部分连接层变换(28174)成等效完全连接层;以及对于等效完全连接层和一个或更多个完全连接层的每对连续层,迭代地执行(28176)梯形变换并计算等效稀疏连接网络的权重矩阵。
[0477]
接下来参考图28r,在一些实现中,神经网络拓扑包括(28178)k个输入、l个输出神经元和权重矩阵u∈r
l
×k,其中r是实数的集合,每个输出神经元执行激活函数f。在这样的情况下,将神经网络拓扑变换(28180)成模拟部件的等效稀疏连接网络包括执行近似变换,该近似变换包括:(i)根据一个或更多个连接约束导出(28182)可能的输入连接度ni》1和可能的输出连接度no》1;(ii)从集合中选择(28184)参数p;(iii)根据p》0的确定,构建(28186)形成等效稀疏连接网络的前p个层的金字塔神经网络,使得金字塔神经网络具有在它的输出层中的个神经元。金字塔神经网络中的每个神经元执行恒等函数;以及(iv)构建(28188)具有n
p
个输入和l个输出的梯形神经网络。梯形神经网络的最后一层中的每个神经元执行激活函数f,以及所有其他神经元执行恒等函数。此外,在这样的情况下,计算(28190)等效稀疏连接网络的权重矩阵包括:(i)生成(28192)金字塔神经网络的权重,包括(i)根据下面的规则设定金字塔神经网络的第一层的每个神经元i的权重:c为非零常数,以及ki=(i-1)ni 1;以及(b)对于除ki之外的神经元的所有权重j,以及(ii)将金字塔神经网络的所有其他权重设定为1;以及(ii)生成(28194)梯形神经网络的权重,包括(i)根据方程设定梯形神经网络的第一层(考虑到整个网,这是第(p 1)层)的每个神经元i的权重;以及(ii)将梯形神经网络的其他权重设定为1。
[0478]
接下来参考图28s,在一些实现中,神经网络拓扑包括(28196)具有k个输入、s个层和在第i层中的l
i=1,s
个计算神经元以及第i层的权重矩阵的多层感知器,其中l0=k。在这样的情况下,将神经网络拓扑变换(28198)成模拟部件的等效稀疏连接网络包括:对于多层感知器的s个层中的每个层j(28200):(i)通过对由l
j-1
个输入、lj个输出神经元和权重矩阵uj组成的相应单层感知器执行近似变换来构建(28202)相应金字塔-梯形网络ptnnxj;以及(ii)通过堆叠每个金字塔梯形网络来构建(28204)等效稀疏连接网络(例如,金字塔梯形网络ptnnxj-1的输出被设定为ptnnxj的输入)。
[0479]
回来参考图28a,在一些实现中,该方法还包括生成(28016)用于利用权重矩阵实现等效稀疏连接网络的示意模型。
[0480]
计算用于训练后的神经网络的模拟硬件实现的电阻值的示例方法
[0481]
图29a-29f示出了根据一些实现的用于根据硬件设计约束的神经网络的硬件实现(2902)的方法2900的流程图。该方法在计算设备200处(例如,使用权重量化模块238)被执行(2904),该计算设备200具有一个或更多个处理器202和存储被配置用于由一个或更多个处理器202执行的一个或更多个程序的存储器214。
[0482]
该方法包括获得(2906)训练后的神经网络(例如网络220)的神经网络拓扑(例如拓扑224)和权重(例如权重222)。在一些实现中,在训练期间执行权重量化。在一些实现中,训练后的神经网络被训练(2908),使得神经网络拓扑的每一层具有量化权重(例如,来自离散值的列表的特定值;例如,每层只有 1、0、-1这3个权重值)。
[0483]
该方法还包括将神经网络拓扑(例如,使用神经网络变换模块226)变换(2910)成包括多个运算放大器和多个电阻器的模拟部件的等效模拟网络。每个运算放大器表示等效模拟网络的一个模拟神经元,以及每个电阻器表示在两个模拟神经元之间的连接。
[0484]
该方法还包括基于训练后的神经网络的权重来计算(2912)等效模拟网络的权重矩阵。权重矩阵的每个元素表示相应连接。
[0485]
该方法还包括针对权重矩阵生成(2914)电阻矩阵。电阻矩阵的每个元素对应于权重矩阵的相应权重,并表示电阻值。
[0486]
接下来参考图29b,在一些实现中,针对权重矩阵生成电阻矩阵包括基于简化梯度下降的迭代方法以找到电阻器集合。在一些实现中,针对权重矩阵生成电阻矩阵包括:(i)获得(2916)可能电阻值的预定范围{r
min
,r
max
}并选择在预定范围内的初始基本电阻值r
基本
。例如,根据权重矩阵的元素的值来选择该范围和基本电阻;值由制造过程确定;范围-可以实际上被制造的电阻器;大电阻器不是优选的;可以实际上被制造的东西的量化。在一些实现中,可能电阻值的预定范围包括(2918)在范围100kω至1mω中根据标称系列e24的电阻;(ii)在预定范围内选择(2920)电阻值的有限长度集合,电阻值针对在电阻值的有限长度集合内的{ri,rj}的所有组合提供在范围[-r
基本
,r
基本
]内的可能权重的最均匀的分布。在一些实现中,权重值在这个范围之外,但在这个范围内的在权重之间的平方平均距离是最小值;(iii)基于每个神经元或等效模拟网络的每个层的传入连接的最大权重和偏差w
max
,针对每个模拟神经元或者针对等效模拟网络的每个层从电阻值的有限长度集合中选择(2922)电阻值r
=r-,使得r
=r-是最接近于r
基本
*w
max
的电阻器设定值。在一些实现中,针对等效模拟网络的每一层独立地选择(2924)r
和r-。在一些实现中,针对等效
模拟网络的每个模拟神经元独立地选择(2926)r
和r-;以及(iv)对于权重矩阵的每个元素,在可能电阻值的预定范围内的r1和r2的所有可能值中,选择(2928)根据方程的所有可能值中,选择(2928)根据方程最小化误差的相应的第一电阻值r1和相应的第二电阻值r2。w是权重矩阵的相应元素,以及r
err
是可能电阻值的预定相对公差值。
[0487]
接下来参考图29c,一些实现执行权重减小。在一些实现中,权重矩阵的第一一个或更多个权重和第一一个或更多个输入表示(2930)到等效模拟网络的第一运算放大器的一个或更多个连接。该方法还包括:在生成(2932)电阻矩阵之前,(i)通过第一值修改(2934)第一一个或更多个权重(例如,使第一一个或更多个权重除以第一值以减小权重范围,或者使第一一个或更多个权重乘以第一值以增加权重范围);以及(ii)在执行激活函数之前配置(2936)第一运算放大器以使第一一个或更多个权重和第一一个或更多个输入的线性组合乘以第一值。一些实现执行权重减小,以便改变一个或更多个运算放大器的乘法因子。在一些实现中,电阻器值集合产生某个范围的权重,并且在该范围的一些部分中,误差将高于在其他部分中的误差。假设只有2个标称量(例如1ω和4ω),这些电阻器可以产生权重[-3;-0.75;0;0.75;3]。假设神经网络的第一层具有{0,9}的权重,以及第二层具有{0,1}的权重,一些实现使第一层的权重除以3并使第二层的权重乘以3以减小总体误差。一些实现考虑在训练期间通过调整损失函数(例如,使用l1或l2正则化器)来限制权重值,使得所得到的网络没有对电阻器集合太大的权重。
[0488]
接下来参考图29d,该方法还包括将权重限制到区间。例如,该方法还包括获得(2938)权重的预定范围;以及根据权重的预定范围更新(2940)权重矩阵,使得对于相同的输入,等效模拟网络产生与训练后的神经网络相似的输出。
[0489]
接下来参考图29e,该方法还包括降低网络的权重敏感度。例如,该方法还包括再训练(2942)训练后的神经网络以降低对权重或电阻值中的误差的敏感度,该误差使等效模拟网络产生与训练后的神经网络相比不同的输出。换句话说,一些实现包括对已经训练的神经网络的附加训练,以便使它对小的随机分布的权重误差有较小敏感度。量化和电阻器制造产生小权重误差。一些实现变换网络,使得因而得到的网络对每个特定权重值不太敏感。在一些实现中,这通过在训练期间向至少一些层中的每个信号添加小的相对随机值来被执行(例如,类似于丢弃层(dropout layer))。
[0490]
接下来参考图29f,一些实现包括减小权重分布范围。一些实现包括再训练(2944)训练后的神经网络,以便最小化在任何层中的权重,该权重比该层的平均绝对权重大预定阈值。一些实现经由再训练来执行这个步骤。示例惩罚函数包括在所有层上的和(例如a*max(abs(w))/mean(abs(w)),其中max和mean在一层上被计算。另一个例子包括更高的数量级。在一些实现中,该函数影响权重量化和网络权重敏感度。例如,由于量化引起的权重的小相对变化可能导致高输出误差。示例技术包括在训练期间引入一些惩罚函数,当网络具有这样的权重被丢弃者(outcast)时,惩罚函数惩罚网络。
[0491]
用于训练后的神经网络的模拟硬件实现的优化的示例方法
[0492]
图30a-30m示出了根据一些实现的根据硬件设计约束的神经网络的硬件实现(3002)的方法3000的流程图。该方法在计算设备200处(例如,使用模拟神经网络优化模块246)被执行(3004),该计算设备200具有一个或更多个处理器202和存储被配置用于由一个
或更多个处理器202执行的一个或更多个程序的存储器214。
[0493]
该方法包括获得(3006)训练后的神经网络(例如网络220)的神经网络拓扑(例如拓扑224)和权重(例如权重222)。
[0494]
该方法还包括将神经网络拓扑(例如,使用神经网络变换模块226)变换(3008)成包括多个运算放大器和多个电阻器的模拟部件的等效模拟网络。每个运算放大器表示等效模拟网络的一个模拟神经元,以及每个电阻器表示在两个模拟神经元之间的连接。
[0495]
接下来参考图30l,在一些实现中,该方法还包括修剪训练后的神经网络。在一些实现中,该方法还包括在变换神经网络拓扑之前使用神经网络的修剪技术来修剪(3052)训练后的神经网络以更新训练后的神经网络的神经网络拓扑和权重,使得等效模拟网络包括少于预定数量的模拟部件。在一些实现中,考虑到在训练后的神经网络和等效模拟网络之间的输出的匹配的准确度或水平,迭代地执行(3054)修剪。
[0496]
接下来参考图30m,在一些实现中,该方法还包括在将神经网络拓扑变换成等效模拟网络之前,执行(3056)网络知识提取。知识提取不同于像修剪一样的随机/学习,但比修剪更具确定性。在一些实现中,独立于修剪步骤来执行知识提取。在一些实现中,在将神经网络拓扑变换成等效模拟网络之前,通过知识提取的方法,通过导出在隐藏神经元的输入和输出之间的因果关系,根据预定的最优性标准(例如,优选优于其他权重的零权重或在特定范围内的权重)来调整连接权重。从概念上,在单神经元或神经元的集合中,在特定的数据集上,可能有在输入和输出之间的因果关系,其允许权重的重新调整,使得:(1)权重的新集合产生相同的网络输出,以及(2)权重的新集合更容易用电阻器实现(例如,更均匀地分布的值、更多零值或没有连接)。例如,如果某个神经元输出在某个数据集上始终为1,则一些实现移除该神经元的输出连接(以及作为整体的神经元),且替代地调整跟随该神经元的神经元的偏差权重。以这种方式,知识提取步骤不同于修剪,因为修剪需要在移除神经元之后重新学习,且学习是随机的,而知识提取是确定性的。
[0497]
回来参考图30a,该方法还包括基于训练后的神经网络的权重来计算(3010)等效模拟网络的权重矩阵。权重矩阵的每个元素表示相应连接。
[0498]
接下来参考图30j,在一些实现中,该方法还包括基于偏差值来移除或变换神经元。在一些实现中,该方法还包括:对于等效模拟网络的每个模拟神经元:(i)在计算权重矩阵时,基于训练后的神经网络的权重来计算(3044)相应模拟神经元的相应偏差值;(ii)根据相应偏差值高于预定最大偏差阈值的确定,从等效模拟网络移除(3046)相应模拟神经元;以及(iii)根据相应偏差值低于预定最小偏差阈值的确定,用等效模拟网络中的线性结代替(3048)相应模拟神经元。
[0499]
接下来参考图30k,在一些实现中,该方法还包括最小化神经元的数量或使网络紧凑。在一些实现中,该方法还包括在生成权重矩阵之前通过增加来自等效模拟网络的一个或更多个模拟神经元的连接(输入和输出)的数量来减少(3050)等效模拟网络的神经元的数量。
[0500]
回来参考图30a,该方法还包括针对权重矩阵生成(3012)电阻矩阵。电阻矩阵的每个元素对应于权重矩阵的相应权重。
[0501]
该方法还包括基于电阻矩阵修剪(3014)等效模拟网络以减少多个运算放大器或多个电阻器的数量,以获得模拟部件的优化模拟网络。
[0502]
接下来参考图30b,在一些实现中,该方法包括用导体替换无价值的电阻。在一些实现中,修剪等效模拟网络包括用导体替换(3016)以下电阻器,该电阻器与电阻矩阵的具有的电阻值低于预定最小阈值电阻值的一个或更多个元素对应。
[0503]
接下来参考图30c,在一些实现中,该方法还包括移除具有非常高的电阻的连接。在一些实现中,修剪等效模拟网络包括移除(3018)等效模拟网络的、与电阻矩阵的高于预定最大阈值电阻值的一个或更多个元素对应的一个或更多个连接。
[0504]
接下来参考图30d,在一些实现中,修剪等效模拟网络包括移除(3020)等效模拟网络的、与权重矩阵的近似为零的一个或更多个元素对应的一个或更多个连接。在一些实现中,修剪等效模拟网络还包括移除(3022)没有任何输入连接的等效模拟网络的一个或更多个模拟神经元。
[0505]
接下来参考图30e,在一些实现中,该方法包括移除不重要的神经元。在一些实现中,修剪等效模拟网络包括:(i)当对一个或更多个数据集进行计算时,基于检测到模拟神经元的使用来对等效模拟网络的模拟神经元排名(3024)。例如,训练数据集用于对训练后的神经网络、典型数据集、为修剪程序开发的数据集进行训练。当经受训练数据集时,一些实现基于给定神经元或神经元块的使用频率来执行用于修剪的神经元的排名。例如,(a)当使用测试数据集时,如果在给定的神经元处从未有信号,意味着该神经元或神经元块从未在使用中,并且被修剪;(b)如果神经元的使用频率非常低,则该神经元被修剪而没有准确度的显著损失;以及(c)神经元总是在使用中,则该神经元不能被修剪;(ii)基于排名来选择(3026)等效模拟网络的一个或更多个模拟神经元;以及(iii)从等效模拟网络移除(3028)一个或更多个模拟神经元。
[0506]
接下来参考图30f,在一些实现中,检测到模拟神经元的使用包括:(i)使用建模软件(例如spice或类似软件)来建立(3030)等效模拟网络的模型;以及(ii)通过使用模型(移除块,其中当使用特殊训练集时信号不传播)以生成一个或更多个数据集的计算来测量(3032)模拟信号(电流)的传播。
[0507]
接下来参考图30g,在一些实现中,检测到模拟神经元的使用包括:(i)使用建模软件(例如spice或类似软件)来建立(3034)等效模拟网络的模型;以及(ii)通过使用模型以生成一个或更多个数据集的计算来测量(3036)模型的输出信号(电流或电压)(例如,在spice模型中或在真实电路中的一些块或放大器的输出处的信号,并且删除区域,在这些区域中训练集的输出信号总是为零伏)。
[0508]
接下来参考图30h,在一些实现中,检测到模拟神经元的使用包括:(i)使用建模软件(例如spice或类似软件)来建立(3038)等效模拟网络的模型;以及(ii)通过使用模型以生成一个或更多个数据集的计算来测量(3040)由模拟神经元消耗的功率(例如,由在spice模型中或者在真实电路中的运算放大器表示的某些神经元或神经元块消耗的功率,并删除不消耗任何功率的神经元或神经元块)。
[0509]
接下来参考图30i,在一些实现中,该方法还包括在修剪等效模拟网络之后并且在生成用于制造实现等效模拟网络的电路的一个或更多个光刻掩模之前,重新计算(3042)等效模拟网络的权重矩阵,并且基于重新计算的权重矩阵更新电阻矩阵。
[0510]
示例模拟神经形态集成电路和制造方法
[0511]
用于制造神经网络的模拟集成电路的示例方法
[0512]
图31a-31q示出了根据一些实现的用于制造包括模拟部件的模拟网络的集成电路3102的方法3100的流程图。该方法在计算设备200处(例如,使用集成电路制造模块258)被执行,该计算设备200具有一个或更多个处理器202和存储被配置用于由一个或更多个处理器202执行的一个或更多个程序的存储器214。该方法包括获得(3104)训练后的神经网络的神经网络拓扑和权重。
[0513]
该方法还包括(例如,使用神经网络变换模块226)将神经网络拓扑变换(3106)成包括多个运算放大器和多个电阻器的模拟部件的等效模拟网络(对于循环神经网络,还使用信号延迟线、乘法器、tanh模拟块、sigmoid模拟块)。每个运算放大器表示相应模拟神经元,以及每个电阻器表示在相应的第一模拟神经元和相应的第二模拟神经元之间的相应连接。
[0514]
该方法还包括基于训练后的神经网络的权重来计算(3108)等效模拟网络的权重矩阵。权重矩阵的每个元素表示相应连接。
[0515]
该方法还包括针对权重矩阵生成(3110)电阻矩阵。电阻矩阵的每个元素对应于权重矩阵的相应权重。
[0516]
该方法还包括基于电阻矩阵来生成(3112)用于制造实现模拟部件的等效模拟网络的电路的一个或更多个光刻掩模(例如,使用掩模生成模块248生成掩模250和/或252),以及使用光刻工艺基于一个或更多个光刻掩模来制造(3114)电路(例如ic 262)。
[0517]
接下来参考图31b,在一些实现中,集成电路还包括一个或更多个数模转换器(3116)(例如dac变换器260),该数模转换器被配置为基于一个或更多个数字信号(例如,来自一个或更多个ccd/cmos图像传感器的信号)为模拟部件的等效模拟网络生成模拟输入。
[0518]
接下来参考图31c,在一些实现中,集成电路还包括模拟信号采样模块(3118),该模拟信号采样模块被配置为基于集成电路的推断的数量以采样频率来处理一维或二维模拟输入(ic的推断的数量由产品规格确定,我们从神经网络操作和芯片被预期解决的确切任务中知道采样速率)。
[0519]
接下来参考图31d,在一些实现中,集成电路还包括按比例缩小或按比例放大模拟信号以匹配多个运算放大器的操作范围的电压转换器模块(3120)。
[0520]
接下来参考图31e,在一些实现中,集成电路还包括被配置为处理从ccd摄像机获得的一个或更多个帧的触觉信号处理模块(3122)。
[0521]
接下来参考图31f,在一些实现中,训练后的神经网络是长短期记忆(lstm)网络,以及集成电路还包括一个或更多个时钟模块以使信号触觉同步并允许时间序列处理。
[0522]
接下来参考图31g,在一些实现中,集成电路还包括被配置为基于模拟部件的等效模拟网络的输出来生成数字信号的一个或更多个模数转换器(3126)(例如adc转换器260)。
[0523]
接下来参考图31h,在一些实现中,集成电路包括被配置为处理从边缘应用获得的一维或二维模拟信号的一个或更多个信号处理模块(3128)。
[0524]
接下来参考图31i,使用包含针对不同气体混合物的气体传感器(例如2到25个传感器)的阵列的信号的训练数据集来训练(3130)训练后的神经网络,用于选择性地感测包含待检测的预定量的气体的气体混合物中的不同气体(换句话说,训练后的芯片的操作用于单独地确定气体混合物中的已知神经网络气体中的每个,尽管在混合物中存在其他气体)。在一些实现中,神经网络拓扑是被设计用于基于由16个气体传感器的测量来检测3个
二元气体成分的一维深度卷积神经网络(1d-dcnn),并且包括(3132)16个传感器式(sensor-wise)一维卷积块、3个共享或公共的一维卷积块和3个密集层。在一些实现中,等效模拟网络包括(3134):(i)每模拟神经元最多100个输入和输出连接,(ii)延迟块,其产生任何数量的时间步长的延迟,(iii)信号限制为5,(iv)15个层,(v)大约100,000个模拟神经元,以及(vi)大约4,900,000个连接。
[0525]
接下来参考图31j,使用包含对于不同mosfet的热老化时间序列数据的训练数据集(例如,包含对于42个不同mosfet的热老化时间序列的nasa mosfet数据集;数据每400ms被采样一次,且对于每个器件一般包括几个小时的数据)来训练(3136)训练后的神经网络,用于预测mosfet器件的剩余使用寿命(rul)。在一些实现中,神经网络拓扑包括(3138)4个lstm层,在每个层中有64个神经元,后面是分别具有64个神经元和1个神经元的两个密集层。在一些实现中,等效模拟网络包括(3140):(i)每模拟神经元最多100个输入和输出连接,(ii)信号限制为5,(iii)18个层,(iv)在3,000和3,200个之间的模拟神经元(例如3137个模拟神经元),以及(v)在123,000和124,000个之间的连接(例如123,200个连接)。
[0526]
接下来参考图31k,使用包含时间序列数据的训练数据集来训练(3142)训练后的神经网络,时间序列数据包括在不同的市售li离子电池的连续使用期间的放电和温度数据(例如,nasa电池使用数据集;该数据集提供6种市售li离子电池的连续使用的数据;网络操作基于电池的放电曲线的分析),该训练用于监测锂离子电池的健康状态(soh)和充电状态(soc)以在电池管理系统(bms)中使用。在一些实现中,神经网络拓扑包括(3144)一个输入层,2个lstm层,在每个层有64个神经元,后面是具有用于生成soc和soh值的2个神经元的一个输出密集层。等效模拟网络包括(3146):(i)每模拟神经元最多100个输入和输出连接,(ii)信号限制为5,(iii)9个层,(iv)在1,200和1,300个之间的模拟神经元(例如1271个模拟神经元),以及(v)在51,000和52,000个之间的连接(例如51,776个连接)。
[0527]
接下来参考图31l,使用包含时间序列数据的训练数据集来训练(3148)训练后的神经网络,时间序列数据包括在不同的市售li离子电池的连续使用期间的放电和温度数据(例如,nasa电池使用数据集;该数据集提供6种市售li离子电池的连续使用的数据;网络操作基于电池的放电曲线的分析),该训练用于监测锂离子电池的健康状态(soh)以在电池管理系统(bms)中使用。在一些实现中,神经网络拓扑包括(3150)具有18个神经元的输入层、具有100个神经元的简单循环层和具有1个神经元的密集层。在一些实现中,等效模拟网络包括(3152):(i)每模拟神经元最多100个输入和输出连接,(ii)信号限制为5,(iii)4个层,(iv)在200和300个之间的模拟神经元(例如201个模拟神经元),以及(v)在2,200和2,400个之间的连接(例如2,300个连接)。
[0528]
接下来参考图31m,使用包含语音命令的训练数据集(例如,google语音命令数据集)来训练(3154)训练后的神经网络,用于识别话音命令(例如,10个短口语关键词,包括“是”、“否”、“上”、“下”、“左”、“右”、“开”、“关”、“停”、“运转”)。在一些实现中,神经网络拓扑是(3156)具有1个神经元的深度可分离卷积神经网络(ds-cnn)层。在一些实现中,等效模拟网络包括(3158):(i)每模拟神经元最多100个输入和输出连接,(ii)信号限制为5,(iii)13个层,(iv)大约72,000个模拟神经元,(v)大约260万个连接。
[0529]
接下来参考图31n,使用包含针对在预定时间段内执行各种身体活动的不同个体的光电容积描记术(ppg)数据、加速度计数据、温度数据和皮肤电反应信号数据以及从ecg
传感器获得的参考心率数据(例如,来自ppg-dalia数据集(check license)的ppg数据)的训练数据集来训练(3160)训练后的神经网络。针对在每1-4小时期间执行各种身体活动的15个个体收集数据。基于手腕的传感器数据包含从4到64hz采样的ppg、3轴加速度计、温度和皮肤电反应信号,以及以大约2hz的采样频率从ecg传感器获得的参考心率数据。原始数据以500个时间步长的移位被分成1000个时间步长(约15秒)的序列,因此得到总共16541个样本。数据集被分成13233个训练样本和3308个测试样本,用于基于ppg传感器数据和3轴加速度计数据来确定在体育锻炼期间的脉搏率(例如慢跑、健身运动、爬楼梯)。神经网络拓扑包括(3162):两个conv1d层,每个层具有执行时间序列卷积的16个滤波器和20的内核;两个lstm层,每个层具有16个神经元;以及分别具有16个神经元和1个神经元的两个密集层。在一些实现中,等效模拟网络包括(3164):(i)延迟块,其产生任何数量的时间步长,(ii)每模拟神经元最多100个输入和输出连接,(iii)信号限制为5,(iv)16个层,(v)在700和800个之间的模拟神经元(例如713个模拟神经元),以及(vi)在12,000和12,500个之间的连接(例如12,072个连接)。
[0530]
接下来参考图31o,训练后的神经网络被训练(3166)以基于脉冲多普勒雷达信号(移除杂波并向多普勒雷达信号提供噪声)对不同的对象(例如人、汽车、自行车、踏板车)分类,以及神经网络拓扑包括(3168)多尺度lstm神经网络。
[0531]
接下来参考图31p,训练后的神经网络被训练(3170)以基于惯性传感器数据(例如,来自健身跟踪设备、智能手表或移动电话的3轴加速度计、磁力计或陀螺仪数据;作为输入以高达96hz的频率被采样的3轴加速度计数据。网络在3个不同的公开可得到的数据集上被训练,呈现诸如“开启然后关闭洗碗机”、“站着喝水”、“关上左手门”、“慢跑”、“行走”、“爬楼梯”等的活动)来执行人类活动类型识别(例如,行走、跑步、坐着、爬楼梯、锻炼、活动跟踪)。在一些实现中,神经网络拓扑包括(3172)三个通道式卷积网络,每个通道式卷积网络具有12个滤波器和64的内核尺寸的卷积层,以及每个卷积层后面是最大池化层,以及分别具有1024个神经元和n个神经元的两个公共密集层,其中n是类别的数量。在一些实现中,等效模拟网络包括(3174):(i)延迟块,其产生任何数量的时间步长,(ii)每模拟神经元最多100个输入和输出连接,(iii)10个模拟神经元的输出层,(iv)信号限制为5,(v)10个层,(vi)在1,200和1,300个之间的模拟神经元(例如1296个模拟神经元),以及(vi)在20,000到21,000个之间的连接(例如20,022个连接)。
[0532]
接下来参考图31q,训练后的神经网络被进一步训练(3176)以基于使用卷积运算与心率数据合并的加速度计数据来检测人类活动的异常模式(以便在突发异常模式的情况下检测中风前或心脏病发作前的状态或信号,突发异常模式由由于医学原因引起的损伤或机能障碍如癫痫等引起)。
[0533]
一些实现包括未集成到芯片中的部件(即,这些是连接到芯片的外部元件),这些部件选自由下列项组成的组:语音识别、视频信号处理、图像感测、温度感测、压力感测、雷达处理、激光雷达处理、电池管理、mosfet电路电流和电压、加速度计、陀螺仪、磁传感器、心率传感器、气体传感器、体积传感器、液位传感器、gps卫星信号、人体电导传感器、气体流量传感器、浓度传感器、ph计和ir视觉传感器。
[0534]
根据一些实现,根据上述过程制造的模拟神经形态集成电路的例子在下面的章节中被提供。
[0535]
用于选择性气体检测的示例模拟神经形态ic
[0536]
在一些实现中,根据上述工艺制造神经形态ic。神经形态ic基于深度卷积神经网络,其被训练用于选择性地感测包含一些量的待检测气体的气体混合物中的不同气体。使用包含对不同气体混合物做出响应的气体传感器的阵列(例如,2至25个传感器)的信号的训练数据集来训练深度卷积神经网络。集成电路(或根据本文所述的技术制造的芯片)可用于确定气体混合物中的一种或更多种已知气体,尽管在混合物中存在其他气体。
[0537]
在一些实现中,训练后的神经网络是用于混合气体分类的多标签1d-dcnn网络。在一些实现中,网络被设计用于基于由16个气体传感器的测量来检测3种二元气体成分。在一些实现中,1d-dcnn包括传感器式的1d卷积块(16个这样的块)、3个公共1d卷积块和3个密集层。在一些实现中,该任务的1d-dcnn网络性能为96.3%。
[0538]
在一些实现中,用下面的参数对原始网络进行t变换:每神经元最大输入和输出连接=100;延迟块可以产生任何数量的时间步长的延迟;以及信号限制为5。
[0539]
在一些实现中,因而得到的t网络具有下面的特性:15个层、大约100,000个模拟神经元、大约4,900,000个连接。
[0540]
用于mosfet故障预测的示例模拟神经形态ic
[0541]
由于热应力而引起的mosfet导通电阻退化是在电力电子器件中的众所周知的严重问题。在真实世界应用中,mosfet器件温度常常在短时间内改变。这个温度扫描产生器件的热退化,这是由于器件可能展示指数分布。这个效应一般通过功率循环(其产生温度梯度)来研究,温度梯度导致mosfet退化。
[0542]
在一些实现中,根据上述工艺制造神经形态ic。神经形态ic基于在标题为“real-time deep learning at the edge for scalable reliability modeling of si-mosfet power electronics converters”的文章中讨论的网络,用于预测mosfet器件的剩余使用寿命(rul)。神经网络可以用于以超过80%的准确度确定器件的剩余使用寿命(rul)。
[0543]
在一些实现中,该网络在包含对于42个不同mosfet的热老化时间序列的nasa mosfet数据集上被训练。数据每400ms被采样一次,且对于每个器件一般包括几个小时的数据。该网络包含4个lstm层,每个层有64个神经元,后面是具有64个和1个神经元的2个密集层。
[0544]
在一些实现中,用下面的参数对网络进行t变换:每神经元最大输入和输出连接是100;信号限制为5,以及因而得到的t网络具有下面的特性:18个层、大约3,000个神经元(例如137个神经元),以及大约120,000个连接(例如123200个连接)。
[0545]
用于锂离子电池健康和soc监测的示例模拟神经形态ic
[0546]
在一些实现中,根据上述工艺制造神经形态ic。神经形态ic可用于锂离子电池的预测分析以在电池管理系统(bms)中使用。bms设备一般提供诸如过充电和过放电保护、监测健康状态(soh)和充电状态(soc)以及几个电池的负载平衡的功能。soh和soc监测通常需要数字数据处理器,这增加了设备的成本并消耗功率。在一些实现中,集成电路用于获得精确的soc和soh数据而不在设备上实现数字数据处理器。在一些实现中,集成电路以超过99%的准确度确定soc,并以超过98%的准确度确定soh。
[0547]
在一些实现中,网络操作基于温度以及电池的放电曲线的分析,和/或数据被呈现为时间序列。一些实现使用来自nasa电池使用数据集的数据。该数据集提供6种市售li离子
电池的连续使用的数据。在一些实现中,网络包括一个输入层、2个lstm层(每层64个神经元)和2个神经元(soc和soh值)的输出密集层。
[0548]
在一些实现中,用下面的参数对网络进行t变换:每神经元最大输入和输出连接数=100以及信号限制为5。在一些实现中,因而得到的t网络包括下面的特性:9个层,大约1,200个神经元(例如1,271个神经元)以及大约50,000个连接(例如51,776个连接)。在一些实现中,网络操作基于温度以及电池的放电曲线的分析。该网络使用在标题为“state-of-health estimation of li-ion batteries inelectric vehicle using indrnn under variableload condition”的论文中公开的网络indrnn来训练,该论文被设计用于处理来自nasa电池使用数据集的数据。该数据集提供6种市售li离子电池的连续使用的数据。indrnn网络包含具有18个神经元的输入层、100个神经元的简单循环层和1个神经元的密集层。
[0549]
在一些实现中,用下面的参数对indrnn网络进行t变换:每神经元最大输入和输出连接=100以及信号极限为5。在一些实现中,因而得到的t网络具有下面的特性:4个层、约200个神经元(例如201个神经元)和约2,000个连接(例如2,300个连接)。一些实现仅以1.3%的估计误差输出soh。在一些实现中,类似于如何获得soh来获得soc。
[0550]
用于关键词检出的示例模拟神经形态ic
[0551]
在一些实现中,根据上述工艺制造神经形态ic。神经形态ic可用于关键词检出。
[0552]
输入网络是具有2-d卷积层和2-d深度卷积层的神经网络,其具有大小49乘10的输入音频梅尔谱图。在一些实现中,网络包括5个卷积层、4个深度卷积层、平均池化层和最终密集层。
[0553]
在一些实现中,网络被预先训练以从google语音命令数据集以94.4%的识别准确度识别10个短口语关键词(“是”、“否”、“上”、“下”、“左”、“右”、“开”、“关”、“停”、“运转”)。
[0554]
在一些实现中,基于深度可分离卷积神经网络(ds-cnn)来制造集成电路,用于话音命令识别。在一些实现中,用下面参数对原始ds-cnn网络进行t变换:每神经元最大输入和输出连接=100、信号限制为5。在一些实现中,因而得到的t网络具有下面的特性:13个层、约72,000个神经元以及约260万个连接。
[0555]
示例ds-cnn关键词检出网络
[0556]
在一个实例中,根据一些实现,关键词检出网络被变换成t网络。该网络是2-d卷积层和2-d深度卷积层的神经网络,其具有大小49x10的输入音频谱图。网络由5个卷积层、4个深度卷积层、平均池化层和最终密集层组成。网络被预先训练以从google语音命令数据集https://ai.googleblog.com/2017/08/launching-speech-commands-dataset.html识别10个短口语关键词(“是”、“否”、“上”、“下”、“左”、“右”、“开”、“关”、“停”、“运转”)。有对应于“沉默”和“未知”的两个额外类别。网络输出是长度12的softmax。
[0557]
根据一些实现,训练后的神经网络(对变换的输入)具有94.4%的识别准确度。在神经网络拓扑中,每个卷积层后面是batchnorm层和relu层,并且relu激活是无界的,且包括大约250万次乘法-加法运算。
[0558]
在变换之后,用1000个样本(每个口语命令100个)的测试集测试变换的模拟网络。所有测试样本也用作在原始数据集中的测试样本。原始ds-cnn网络对这个测试集给出接近5.7%的识别误差。网络被转换成由平凡神经元组成的t型网络。在“测试”模式中的
batchnormalization层产生简单的线性信号变换,因此可以被解释为权重乘数 某个附加偏差。非常直接地对卷积层、平均池化层和密集层进行t变换。softmax激活函数未在t网络中实现,且单独地应用于t网络输出。
[0559]
因而得到的t网络具有12个层,包括一个输入层,大约72,000个神经元和大约250万个连接。
[0560]
图26a-26k分别示出了根据一些实现的层1至11的绝对权重的示例直方图2600。针对每个层计算权重分布直方图(对于绝对权重)。在图表中的虚线对应于相应层的平均绝对权重值。在变换(即t变换)之后,所转换的网络与原始网络比较的(在测试集上被计算的)平均输出绝对误差被计算为4.1e-9。
[0561]
根据一些实现,本文描述了用于设定变换的网络的网络限制的各种示例。对于信号限制,因为在网络中使用的relu激活是无界的,且一些实现在每一层上使用信号限制。这可能潜在地影响数学等效性。为此,一些实现在所有层上使用信号限制5,其对应于与输入信号范围相关的为5的电源电压。
[0562]
为了量化权重,一些实现使用30个电阻器的标称集合[0.001,0.003,0.01,0.03,0.1,0.324,0.353,0.436,0.508,0.542,0.544,0.596,0.73,0.767,0.914,0.985,0.989,1.043,1.101,1.149,1.157,1.253,1.329,1.432,1.501,1.597,1.896,2.233,2.582,2.844]。
[0563]
一些实现为每一层单独地选择r-和r 值(见上面的描述)。对于每一层,一些实现选择提供最大权重准确度的值。在一些实现中,随后在t网络中的所有权重(包括偏差)被量化(例如,被设定为可以利用输入或所选择的电阻器来达到的最接近的值)。
[0564]
一些实现如下转换输出层。输出层是没有relu激活的密集层。根据一些实现,该层具有softmax激活,其没有在t转换中实现,并且被留给数字部分。一些实现不执行额外的转换。
[0565]
用于获得心率的示例模拟神经形态ic
[0566]
ppg是可用于检测在组织的微血管床中的血液体积变化的光学地获得的体积描记图。常常通过使用脉搏血氧计来获得ppg,该脉搏血氧计照射皮肤并测量光吸收的变化。ppg常常在设备(例如健身跟踪器)中被处理以确定心率。从ppg信号导出心率(hr)是在边缘设备计算中的重要任务。从位于手腕上的设备获得的ppg数据通常仅在设备稳定时才允许获得可靠的心率。如果人参与身体锻炼,从ppg数据获得心率产生差的结果,除非与惯性传感器数据组合。
[0567]
在一些实现中,集成电路基于卷积神经网络和lstm层的组合可以用于基于来自光学体积描记术(ppg)传感器和3轴加速度计的数据来精确地确定脉搏率。该集成电路可用于抑制ppg数据的运动伪影,并以超过90%的准确度确定在身体锻炼(例如慢跑、健身锻炼和爬楼梯)期间的脉搏率。
[0568]
在一些实现中,输入网络用来自ppg-dalia数据集的ppg数据训练。针对在预定持续时间(例如,每个1-4小时)内执行各种身体活动的15个个体收集数据。包括基于手腕的传感器数据的训练数据包含从4到64hz采样的ppg、3轴加速度计、温度和皮肤电反应信号,以及以大约2hz的采样频率从ecg传感器获得的参考心率数据。原始数据以500个时间步长的移位被分成1000个时间步长(约15秒)的序列,因此产生总共16541个样本。数据集被分成
13233个训练样本和3308个测试样本。
[0569]
在一些实现中,输入网络包括:2个conv1d层,每个层具有执行时间序列卷积的16个滤波器;2个lstm层,每个层具有16个神经元;以及具有16个和1个神经元的2个密集层。在一些实现中,网络在测试集上产生小于每分钟6次跳动的mse误差。
[0570]
在一些实现中,用下面的参数对网络进行t变换:延迟块可以产生任何数量的时间步长的延迟、每神经元最大输入和输出连接=100以及信号限制为5。在一些实现中,因而得到的t网络具有下面的特性:15个层、大约700个神经元(例如713个神经元)以及大约12,000个连接(例如12072个连接)。
[0571]
用t转换的lstm网络处理ppg数据的示例
[0572]
如上所述,对于循环神经元,一些实现使用信号延迟块,其被添加到gru和lstm神经元的每个循环连接。在一些实现中,延迟块具有以恒定时间段dt激活延迟块的外部循环定时器(例如数字定时器)。该激活产生x(t-dt)的输出,其中x(t)是延迟块的输入信号。这样的激活频率可以例如对应于网络输入信号频率(例如,由t转换的网络处理的模拟传感器的输出频率)。一般,所有延迟块用相同的激活信号被同时激活。一些块可以在一个频率上被同时激活,而其他块可以在另一个频率上被激活。在一些实现中,这些频率具有公共乘法器,并且信号被同步。在一些实现中,在一个信号上使用多个延迟块,产生附加时间移位。上面参考图13b描述了延迟块的例子,图13b示出了根据一些实现的延迟块的两个例子。
[0573]
根据一些实现,用于处理ppg数据的网络使用一个或更多个lstm神经元。根据一些实现,上面参考图13a描述了lstm神经元实现的例子。
[0574]
该网络还使用conv1d,一种在时间坐标上执行的卷积。根据一些实现,上面参考图15a和15b描述了conv1d实现的例子。
[0575]
根据一些实现,在本文描述了ppg数据的细节。ppg是可用于检测在组织的微血管床中的血液体积变化的光学地获得的体积描记图。常常通过使用脉搏血氧计来获得ppg,该脉搏血氧计照射皮肤并测量光吸收的变化。ppg常常在设备(例如健身跟踪器)中被处理以确定心率。从ppg信号导出心率(hr)是在边缘设备计算中的重要任务。
[0576]
一些实现使用来自capnobase ppg数据集的ppg数据。数据包含42个个体的每个8分钟持续时间的原始ppg信号(每秒采样300个样本),以及以每秒采样约1个样本从ecg传感器获得的参考心率数据。对于训练和评估,一些实现以1000个时间步长的移位将原始数据分成6000个时间步长的序列,因而得到总共5838个样本的总集合。
[0577]
在一些实现中,基于训练后的神经网络nn的输入在从ppg数据获得心率(hr)时允许有1-3%的准确度。
[0578]
本节描述了相对简单的神经网络,以便演示t转换和模拟处理可以如何处理这个任务。根据一些实现,该描述作为例子被提供。
[0579]
在一些实现中,数据集被分成4,670个训练样本和1,168个测试样本。该网络包括:具有16个滤波器和20的内核的1个conv1d层;2个lstm层,每个层具有24个神经元;2个密集层(每个层具有24个和1个神经元)。在一些实现中,在训练该网络200个时期(epoch)之后,测试准确度被发现是2.1%。
[0580]
在一些实现中,用下面的参数对输入网络进行t变换:具有1、5和10个时间步长的周期的延迟块以及下面的特性:17个层、15,448个连接和329个神经元(op3神经元和乘法器
块,不将延迟块计算在内)。
[0581]
用于基于脉冲多普勒雷达信号的对象识别的示例模拟神经形态集成电路
[0582]
在一些实现中,基于多尺度lstm神经网络来制造集成电路,该集成电路可用于基于脉冲多普勒雷达信号对对象分类。该ic可用于基于多普勒雷达信号对不同的对象(例如人、汽车、自行车、踏板车)分类,移除杂波,并将噪声提供给多普勒雷达信号。在一些实现中,利用多尺度lstm网络对对象分类的准确度超过90%。
[0583]
用于基于惯性传感器数据的人类活动类型识别的示例模拟神经形态集成电路
[0584]
在一些实现中,神经形态集成电路被制造并且可以用于基于多通道卷积神经网络的人类活动类型识别,多通道卷积神经网络具有来自3轴加速度计以及可能来自健身跟踪设备、智能手表或移动电话的磁力计和/或陀螺仪的输入信号。多通道卷积神经网络可用于区分开不同类型的人类活动,例如行走、跑步、坐着、爬楼梯、锻炼,并可用于活动跟踪。该ic可用于基于与心率数据卷积地合并的加速度计数据来检测人类活动的异常模式。根据一些实现,这样的ic可以在突发异常模式的情况下检测中风前或心脏病发作前的状态或信号,突发异常模式由由于医学原因引起的损伤或机能障碍如癫痫等引起。
[0585]
在一些实现中,ic基于在文章“convolutional neural networks for human activity recognition using mobile sensors”中讨论的通道式1d卷积网络。在一些实现中,该网络接受3轴加速度计数据作为输入,该数据以高达96hz的频率被采样。在一些实现中,网络在3个不同的公开可得到的数据集上训练,呈现诸如“开启然后关闭洗碗机”、“站着喝水”、“关上左手门”、“慢跑”、“行走”、“爬楼梯”等的这种活动。在一些实现中,该网络包括3个通道式卷积网络,其具有12个滤波器和64的内核的卷积层,每个卷积层后面是最大池化(4)层,以及分别具有1024个和n个神经元的2个公共密集层,其中n是类别的数量。在一些实现中,以低误差率(例如,3.12%的误差)执行活动分类。
[0586]
在一些实现中,用下面的参数对网络进行t变换:延迟块可以产生任何数量的时间步长的延迟、每神经元最大输入和输出连接=100、10个神经元的输出层以及信号限制为5。在一些实现中,因而得到的t网络具有下面的特性:10个层、大约1,200个神经元(例如1296个神经元),以及大约20,000个连接(例如20022个连接)。
[0587]
用于生成库的模块化网结构的示例变换
[0588]
根据一些实现,在本文描述了转换的神经网络的模块化结构。模块化型神经网络的每个模块在一个或更多个训练后的神经网络(的全部或一部分)的变换之后被获得。在一些实现中,一个或更多个训练后的神经网络被细分成部分,且随后被变换成等效模拟网络。模块化结构对于目前使用的神经网络中的一些是特有的,且神经网络的模块化划分对应于在神经网络发展中的趋势。每个模块可以具有任意数量的输入或输入神经元到所连接模块的输出神经元的任意数量的连接以及连接到后续模块的输入层的任意数量的输出。在一些实现中,开发了初步变换模块(或变换模块的种子列表)的库,包括用于每个模块的制造的光刻掩模。最终芯片设计作为初步开发模块的组合(或通过连接初步开发模块)被获得。一些实现执行在模块之间的交换。在一些实现中,使用现成的模块设计模板来将在模块内的神经元和连接转化为芯片设计。这明显简化了通过仅连接对应模块而完成的芯片的制造。
[0589]
一些实现生成现成的t转换的神经网络和/或t转换的模块的库。例如,cnn网络的一个层是模块化构造块,lstm链是另一个构造块,等等。更大的神经网络nn也具有模块化结
构(例如lstm模块和cnn模块)。在一些实现中,神经网络的库不只是示例过程的副产物,并且可以独立地被销售。例如,第三方可以以在库中的模拟电路、电路图或设计开始制造神经网络(例如,使用cadence电路、文件和/或光刻掩模)。一些实现为典型的神经网络生成t转换的神经网络(例如,可变换成cadence或类似软件的网络),并且转换的神经网络(或相关联信息)被出售给第三方。在一些实例中,根据一些实现,第三方选择不公开初始神经网络的结构和/或目的,但使用转换软件(例如上面所述的sdk)来将初始网络转换成梯形状网络,并将变换的网络传递给制造商以制造变换的网络,其中权重矩阵使用上述过程之一被获得。作为另一个例子,其中现成网络的库根据本文描述的过程被生成,对应的光刻掩模被生成,并且消费者可以为他的任务训练可用网络架构之一,执行无损变换(有时被称为t变换),并且向制造商提供权重用于针对训练后的神经网络制造芯片。
[0590]
在一些实现中,模块化结构概念也用在多芯片系统或多级3d芯片的制造中,其中3d芯片的每一层表示一个模块。在3d芯片的情况下模块的输出到所连接模块的输入的连接将通过标准互连来建立,该标准互连提供在多层3d芯片系统中的不同层的欧姆接触。在一些实现中,某些模块的模拟输出通过层间互连来连接到所连接模块的模拟输入。在一些实现中,模块化结构也用于制造多芯片处理器系统。这样的多芯片组件的区别特征是在不同芯片之间的模拟信号数据线。使用在模拟电路系统中开发的模拟信号交换和去交换的标准方案来实现对将几个模拟信号压缩到一条数据线中和在接收器芯片处的模拟信号的对应的去交换所特有的模拟交换方案。
[0591]
根据上述技术制造的芯片的一个主要优点在于,模拟信号传播可以扩展到多层芯片或多芯片组件,其中所有信号互连且数据线传输模拟信号,而没有对模数或数模转换的需要。以这种方式,模拟信号传输和处理可以扩展到3d多层芯片或多芯片组件。
[0592]
用于为了神经网络的硬件实现生成库的示例方法
[0593]
图32a-32e示出了根据一些实现的用于为了神经网络的硬件实现生成(3202)库的方法3200的流程图。该方法在计算设备200处(例如,使用库生成模块254)被执行(3204),该计算设备200具有一个或更多个处理器202以及存储被配置用于由一个或更多个处理器202执行的一个或更多个程序的存储器214。
[0594]
该方法包括获得(3206)多个神经网络拓扑(例如拓扑224),每个神经网络拓扑对应于相应的神经网络(例如神经网络220)。
[0595]
该方法还包括将每个神经网络拓扑(例如,使用神经网络变换模块226)变换(3208)成模拟部件的相应等效模拟网络。
[0596]
接下来参考图32d,在一些实现中,将相应网络拓扑变换(3230)成相应等效模拟网络包括:(i)将相应网络拓扑分解(3232)成多个子网拓扑。在一些实现中,分解相应网络拓扑包括将相应网络拓扑的一个或更多个层(例如lstm层、完全连接层)识别(3234)为多个子网拓扑;(ii)将每个子网拓扑变换(3236)成模拟部件的相应等效模拟子网;以及(iii)组成(3238)每个等效模拟子网以获得相应等效模拟网络。
[0597]
回来参考图32a,该方法还包括生成(3210)用于制造多个电路的多个光刻掩模(例如掩模256),每个电路实现模拟部件的相应等效模拟网络。
[0598]
接下来参考图32e,在一些实现中,每个电路通过下列操作来获得:(i)生成(3240)模拟部件的相应等效模拟网络的电路图;以及(ii)基于电路图生成(3242)相应的电路布局
设计(使用特殊软件,例如cadence)。在一些实现中,该方法还包括在生成用于制造多个电路的多个光刻掩模之前组合(3244)一个或更多个电路布局设计。
[0599]
接下来参考图32b,在一些实现中,该方法还包括:(i)获得(3212)训练后的神经网络的新神经网络拓扑和权重;(ii)基于新神经网络拓扑与多个神经网络拓扑的比较来从多个光刻掩模选择(3214)一个或更多个光刻掩模。在一些实现中,新神经网络拓扑包括多个子网拓扑,并且选择一个或更多个光刻掩模进一步基于将每个子网拓扑与多个网络拓扑中的每个网络拓扑进行比较(3216);(iii)基于权重来计算(3218)新等效模拟网络的权重矩阵;(iv)针对权重矩阵生成(3220)电阻矩阵;以及(v)基于电阻矩阵和一个或更多个光刻掩模来生成(3222)用于制造实现新等效模拟网络的电路的新光刻掩模。
[0600]
接下来参考图32c,多个子网拓扑中的一个或更多个子网拓扑未能与多个网络拓扑中的任何网络拓扑比较(3224),并且该方法还包括:(i)将一个或更多个子网拓扑中的每个子网拓扑变换(3226)成模拟部件的相应等效模拟子网;以及生成(3228)用于制造一个或更多个电路的一个或更多个光刻掩模,一个或更多个电路中的每个电路实现模拟部件的相应等效模拟子网。
[0601]
用于优化神经形态模拟集成电路的能量效率的示例方法
[0602]
图33a-33j示出了根据一些实现的用于优化(3302)模拟神经形态电路(其对训练后的神经网络建模)的能量效率的方法3300的流程图。该方法在计算设备200处(例如,使用能量效率优化模块264)被执行(3204),该计算设备200具有一个或更多个处理器202和存储被配置用于由一个或更多个处理器202执行的一个或更多个程序的存储器214。
[0603]
该方法包括获得(3306)集成电路(例如ic 262),该集成电路实现包括多个运算放大器和多个电阻器的模拟部件的模拟网络(例如,变换的模拟神经网络228)。模拟网络表示训练后的神经网络(例如神经网络220),每个运算放大器表示相应模拟神经元,以及每个电阻器表示在相应的第一模拟神经元和相应的第二模拟神经元之间的相应连接。
[0604]
该方法还包括使用集成电路为多个测试输入生成(3308)推断(例如,使用推断模块266),包括同时将信号从模拟网络的一层传输到后一层。在一些实现中,模拟网络具有分层结构,信号同时从前一层到达下一层。在推断过程期间,信号通过电路逐层传播;在设备级处的仿真;每分钟的时间延迟。
[0605]
该方法还包括,在使用集成电路生成推断时,(例如,使用信号监测模块268)确定(3310)多个运算放大器的信号输出电平是否被平衡。运算放大器在接收输入之后经历瞬变周期(例如,从瞬变到平稳信号持续小于1毫秒的周期),在此之后信号的电平被平衡并且不改变。根据信号输出电平被平衡的确定,该方法还包括:(i)确定(3312)影响用于信号的传播的信号形成的模拟网络的模拟神经元的活动集合。神经元的活动集合不需要是一个层或更多个层的一部分。换句话说,确定步骤起作用,而不考虑模拟网络是否包括神经元的层;以及(ii)在预定时间段内,(例如,使用功率优化模块270)关闭(3314)与模拟神经元的活动集合不同的模拟网络的一个或更多个模拟神经元的电源。例如,一些实现(例如,使用功率优化模块270)切断运算放大器的电源,这些运算放大器在活动层后面的层中(此时信号传播到活动层),并且不影响在活动层上的信号形成。这可以基于穿过ic的信号传播的rc延迟来计算。因此,在操作层(或活动层)后面的所有层被关闭以节省功率。所以信号穿过芯片的传播像冲浪一样,信号形成的波传播穿过芯片,并且不影响信号形成的所有层被关闭。在一
些实现中,对于逐层网络,信号从一层传播到另一层,并且该方法还包括在对应于神经元的活动集合的层之前降低功率消耗,因为在该层之前没有对放大的需要。
[0606]
接下来参考图33b,在一些实现中,在一些实现中,确定模拟神经元的活动集合基于计算(3316)穿过模拟网络的信号传播的延迟。接下来参考图33c,在一些实现中,确定模拟神经元的活动集合基于检测(3318)信号穿过模拟网络的传播。
[0607]
接下来参考图33d,在一些实现中,训练后的神经网络是前馈神经网络,并且模拟神经元的活动集合属于模拟网络的活动层,并且关闭电源包括在模拟网络的活动层之前为一个或更多个层关闭(3320)电源。
[0608]
接下来参考图33e,在一些实现中,考虑到信号延迟(使用特殊软件,例如cadence),基于对信号穿过模拟网络的传播进行仿真来计算(3322)预定时间段。
[0609]
接下来参考图33f,在一些实现中,训练后的神经网络是(3324)循环神经网络(rnn),并且模拟网络还包括除了多个运算放大器和多个电阻器之外的一个或更多个模拟部件。在这样的情况下,该方法还包括,根据信号输出电平被平衡的确定,在预定时间段内(例如,使用功率优化模块270)为一个或更多个模拟部件关闭(3326)电源。
[0610]
接下来参考图33g,在一些实现中,该方法还包括在预定时间段之后(例如,使用功率优化模块270)为模拟网络的一个或更多个模拟神经元开启电源(3328)。
[0611]
接下来参考图33h,在一些实现中,确定多个运算放大器的信号输出电平是否被平衡基于检测(3330)模拟网络的一个或更多个运算放大器是否输出大于预定阈值的信号电平(例如功率、电流或电压)。
[0612]
接下来参考图33i,在一些实现中,该方法还包括重复(3332)(例如,通过功率优化模块270)在预定时间段内关闭和在预定时间段内开启模拟神经元的活动集合,同时生成推断。
[0613]
接下来参考图33j,在一些实现中,该方法还包括,根据信号输出电平被平衡的确定,对于每个推断周期(3334):(i)在第一时间间隔期间,确定(3336)影响用于信号的传播的信号形成的模拟网络的第一层模拟神经元;以及(ii)在第一层之前在预定时间段内(例如,使用功率优化模块270)为模拟网络的第一一个或更多个模拟神经元关闭(3338)电源;以及在第一时间间隔之后的第二时间间隔期间,在预定时间段内(例如,使用功率优化模块270)为包括模拟网络的第一层模拟神经元和第一一个或更多个模拟神经元的第二一个或更多个模拟神经元关闭(3340)电源。
[0614]
接下来参考图33k,在一些实现中,一个或更多个模拟神经元由模拟网络的前一层或更多层的模拟神经元组成(3342),并且模拟神经元的活动集合由模拟网络的第二层的模拟神经元组成,以及模拟网络的第二层不同于前一层或更多层中的层。
[0615]
一些实现包括用于延迟和/或控制所得到的硬件实现的神经网络的从一层到另一层的信号传播的装置。
[0616]
mobilenet v.1的示例变换
[0617]
根据一些实现,本文描述了mobilenet v.1到等效模拟网络的示例变换。在一些实现中,单个模拟神经元被生成,然后在权重从mobilenet变换成电阻器值的情况下转换成spice电路图。在图34中所示的表中描绘mobilenet v1架构。在该表中,第一列3402对应于层和步幅的类型,第二列3404对应于对应层的滤波器形状,以及第三列3406对应于对应层
的输入大小。在mobilenet v.1中,每个卷积层后面是批量归一化层和relu 6激活函数(y=max(0,min(6,x))。该网络由27个卷积层和1个密集层组成,并对于224
×
224
×
3的输入图像有大约6亿次乘法-累加运算。输出值是softmax激活函数的结果,这意味着值分布在范围[0,1]内,且总和为1。一些实现接受mobilenet 32x32和alpha=1作为输入用于变换。在一些实现中,网络针对cifar-10任务被预先训练(50,000个32x32x3的图像分为10个不交叉的类别)。批量归一化层在“测试”模式中操作以产生简单的线性信号变换,因此这些层被解释为权重乘数 一些附加偏差。根据一些实现,使用上述技术来变换卷积层、平均池化层和密集层。在一些实现中,softmax激活函数不在变换的网络中实现,而是单独地应用于变换的网络(或等效模拟网络)的输出。
[0618]
在一些实现中,所得到的变换的网络包括30个层,包括输入层、大约104,000个模拟神经元以及大约1100万个连接。在变换之后,变换的网络与mobilenet v.1比较的平均输出绝对误差(在100个随机样本上被计算)为4.9e-8。
[0619]
因为mobilenet的每个卷积层和其他层具有激活函数relu6,在变换的网络的每个层上的输出信号也被值6限制。作为变换的一部分,使权重符合电阻器标称量集合。在每个标称量集合下,不同的权重值是可能的。一些实现使用在[0.1-1]兆欧姆的范围内的电阻器标称量集合e24、e48和e96。假定每个层的权重范围改变,并且对于大多数层,权重值不超过1-2,为了实现更大的权重准确度,一些实现减小r-和r 值。在一些实现中,从集合[0.05,0.1,0.2,0.5,1]兆欧姆为每个层单独地选择r-和r 值。在一些实现中,对于每个层,选择提供最大权重准确度的值。然后,在变换的网络中的所有权重(包括偏差)被“量化”,即,被设定为可以用用所使用的电阻器实现的最接近的值。在一些实现中,这根据下面所示的表降低了变换的网络相对于原始mobilenet的准确度。该表示出了根据一些实现当使用不同的电阻器集合时变换的网络的均方误差。
[0620]
电阻器集合均方误差e24 0.1-1mω0.01e24 0.1-5mω0.004e48 0.1-1mω0.007e96 0.1-1mω0.003
[0621]
在本文中本发明的描述所使用的术语仅为了描述特定实现的目的,且并不意欲限制本发明。如在本发明的描述和所附的权利要求中所使用的,单数形式“一(a)”、“一(an)”、和“该(the)”意欲也包括复数形式,除非上下文另外清楚地指示。还要理解的是,如在本文使用的术语“和/或”指相关的所列出的项目中的一个或更多个的任何和所有可能的组合并包括这些组合。还要理解的是,术语“包括(comprises)”和/或“包括(comprising)”当在本说明书中使用时指定所陈述的特征、步骤、操作、元件和/或部件的存在,但不排除一个或更多个其它特征、步骤、操作、元件、部件和/或它们的组合的存在或添加。
[0622]
为了解释的目的,前面的描述参考了特定的实现进行描述。然而,上面的说明性讨论并没有被规定为无遗漏的或将本发明限制到所公开的精确形式。鉴于上面的教导,许多修改和变形是可能的。实现被选择和描述是为了最好地解释本发明的原理及其实际应用,以从而使本领域中的技术人员能够以适合于所设想的特定用途的各种修改最好地利用本发明和各种实现。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。