进行分类。
12.进一步地,步骤2中生成投影矩阵和特征矩阵,具体为基于mindspore开源计算框 架实现2dpca并生成投影矩阵,步骤如下:
13.步骤2.1、获取数据集:假设有n个样本,构成训练集的图片需要在相同的照明条 件下拍摄,并将所有图像的眼睛和嘴对齐,图像样本的宽为w,高为h,表示为二维矩 阵ai∈rh×w,数据集s=a1,...,an,i=1,...,n;
14.步骤2.2、对图像进行中心化处理:每一个图像矩阵需要减掉均值矩阵根据得到中心化图像cai;
15.步骤2.3、基于水平方向的2dpca方法得到协方差矩阵g
t
∈ rn×n;
16.步骤2.4、根据g
t
ui=λiui进行特征值分解,λi表示特征值,ui表示特征向量;
17.步骤2.5、将n个特征值从大到小排序,截取前k个特征值及其对应的特征向量, 组成水平方向的变换矩阵u=[e1,e2,...,ek],u∈rn×k,ei为特征向量ei∈rn×1,这些 特征向量组成了投影空间u,图像的特征矩阵b=au;
[0018]
步骤2.6、基于垂直方向的2dpca方法得到协方差矩阵h
t
∈ rm×m;
[0019]
步骤2.7、根据h
t
vi=λivi进行特征值分解,λi表示特征值,vi表示特征向量;
[0020]
步骤2.8、将m个特征值从大到小排序,截取前k个特征值及其对应的特征向量, 组成垂直方向的变换矩阵v=[e1,e2,...,ek]
t
,v∈rm×k,ei为特征向量ei∈rn×1,这些 特征向量组成了投影空间v,图像的特征矩阵c=v
t
a。
[0021]
进一步地,步骤4所述生成扰动的基于水平方向的投影矩阵,具体如下:
[0022]
基于归一化后的基于水平方向的投影矩阵u,在投影矩阵每一列的索引位置加入敏感度为1、噪声尺度为1/ε的拉普拉斯噪声lap(1/ε),生成扰动的投影矩阵u
′
, ε表示隐私预算。
[0023]
进一步地,步骤5所述重构人脸图像,具体如下:
[0024]
根据f
new
=vv
t
au
′u′
t
得到重构人脸图像f
new
,其中,v表示基于垂直方向的投影 矩阵,u
′
表示加噪后的基于水平方向的投影矩阵;
[0025]
根据加噪后的投影矩阵u
′
重构人脸图像f
new
,客户端将重构人脸图像上传至服务器。
[0026]
进一步地,步骤6所述训练重构人脸图像数据集,具体步骤如下:
[0027]
取重构人脸图像数据集的70%当作训练集,30%当作测试集,将图片和标签送入 网络进行训练并保存模型,通过多层感知机mlp训练数据集进行人脸识别;
[0028]
多层感知机mlp是一种前馈神经网络,多层感知机mlp是含有至少一个隐藏层 的由全连接层组成的神经网络,该神经网络由两层全连接层和一层激活函数组成,第一 个全连接层fc1的输入有w*h个节点,输出有512个节点,激活后的全连接层输入节 点数为512,输出节点数为人脸集的类别数。
[0029]
进一步地,步骤2.4中所述根据g
t
ui=λiui进行特征值分解,具体如下:
[0030]
协方差矩阵是一个高维矩阵c∈rn×n,当n远大于m时,先进行a
t
a的特征值分 解,a
t
a∈rm×m,得到a
t
avi=βivi,假设β1,β2,...,βm是a
t
a的特征值,v1,v2,...,vm是 特征值对应的特征向量,两边左乘a得到aa
t
avi=βiavi,即cavi=βiavi,β1,β2,...,βm也是aa
t
的特征值,av1,av2,...,avm是特征值对应的特征向量,实际上aa
t
应该有n个特 征值,以及n个线性无关的特征向量,而a
t
a的m个特征值与特征向量对应着aa
t
的前 m个最大的特征值以及特征值相对应的特征向量;通过这种变换求出aa
t
的特征向量 ui=avi,i=1,2,...,m。
[0031]
本发明与现有技术相比,其显著优点为:(1)2dpca中,图像的协方差矩阵通过 使用原始图像矩阵直接构造,比pca构造的协方差矩阵维数小很多,减少计算特征向 量所需要的时间;(2)将数据发送给第三方前进行扰动,较好的保证了数据的隐私性; (3)在标准隐私设置下,算法分类准确率为82%-91%。
附图说明
[0032]
图1为本发明基于mindspore的隐私保护人脸识别方法整体框架图。
[0033]
图2为本发明中生成投影矩阵的流程图。
[0034]
图3为本发明中扰动投影矩阵的流程图。
[0035]
图4为本发明不同隐私预算下重构人脸图像的对比图。
具体实施方式
[0036]
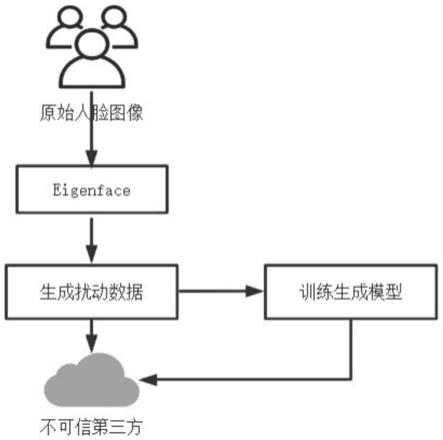
本发明提出一种基于mindspore的隐私保护人脸识别方法,其基于mindspore深度 学习框架搭建,数据由边缘端传给服务器,引入2dpca和差分隐私,结合图1,其主 要步骤具体如下:
[0037]
步骤1、获取人脸图像:将人脸图像裁剪成统一的大小,宽为w、高为h;
[0038]
步骤2、得到投影矩阵和特征矩阵:根据数据集中人脸图像的二维矩阵ai,ai∈rh×w, 分别基于水平方向和垂直方向生成协方差矩阵g
t
和h
t
,进一步得到水平方向的最佳投影 矩阵u和特征矩阵b,以及垂直方向的最佳投影矩阵v和特征矩阵c;
[0039]
步骤3、基于水平方向的投影矩阵归一化:将生成的基于水平方向的特征矩阵u数 据归一化到[0,1];
[0040]
步骤4、生成扰动的基于水平方向的投影矩阵:在基于水平方向的投影矩阵上加入 拉普拉斯噪声生成扰动的投影矩阵u
′
;
[0041]
步骤5、重构人脸图像:根据扰动的基于水平方向的2dpca方法得到的投影矩阵 u和基于垂直方向的2dpca得到的投影矩阵v生成重构人脸图像f
new
;
[0042]
步骤6、训练重构人脸图像数据集:使用多层感知机mlp训练重构人脸图像数据 集进行分类。
[0043]
进一步地,用户发送人脸图像给服务器之前会对图像进行随机化,通过扰动的投影 矩阵重新生成人脸图像,从而保护图像隐私信息。
[0044]
进一步地,其服务器接收扰动后的人脸图像,不可信的第三方无法获取图像包含的 人脸信息。
[0045]
进一步地,其服务器端对重构人脸数据集进行人脸识别,通过调节不同的隐私预
算 等参数,保持人脸识别准确性和图像隐私性的平衡。
[0046]
本发明基于mindspore的人脸图像隐私保护方法,基于mindspore开源计算框架实 现步骤2中所述的2dpca方法生成投影矩阵和特征矩阵,结合图2,其基本步骤具体 如下:
[0047]
步骤2.1、获取数据集:假设有n个样本,构成训练集的图片需要在相同的照明条 件下拍摄,并将所有图像的眼睛和嘴对齐,图像样本的宽为w,高为h,表示为二维矩 阵ai∈rh×w,数据集s=a1,...,an,i=1,...,n;
[0048]
步骤2.2、对图像进行中心化处理:每一个图像矩阵需要减掉均值矩阵根据得到中心化图像cai。
[0049]
步骤2.3、基于水平方向的2dpca方法得到协方差矩阵g
t
∈ rn×n;
[0050]
步骤2.4、根据g
t
ui=λiui进行特征值分解,λi表示特征值,ui表示特征向量;
[0051]
步骤2.5、将n个特征值从大到小排序,截取前k个特征值及其对应的特征向量, 组成水平方向的变换矩阵u=[e1,e2,...,ek],u∈rn×k,ei为特征向量ei∈rn×1,这些 特征向量组成了投影空间u,图像的特征矩阵b=au;
[0052]
步骤2.6、基于垂直方向的2dpca方法得到协方差矩阵h
t
∈ rm×m;
[0053]
步骤2.7、根据h
t
vi=λivi进行特征值分解,λi表示特征值,vi表示特征向量;
[0054]
步骤2.8、将m个特征值从大到小排序,截取前k个特征值及其对应的特征向量, 组成垂直方向的变换矩阵v=[e1,e2,...,ek]
t
,v∈rm×k,ei为特征向量ei∈rn×1,这些 特征向量组成了投影空间v,图像的特征矩阵c=v
t
a。
[0055]
进一步地,所述特征值分解的方法,当n远大于m时的具体内容如下:
[0056]
协方差矩阵是一个高维矩阵c∈rn×n,如果直接进行特征分解,当n远大于m时 不仅消耗资源且费时。因此当n远大于m时,先进行a
t
a的特征值分解,因为a
t
a∈ rm×m,此时维度要小得多,由此可以得到a
t
avi=βivi,假设β1,β2,...,βm是a
t
a的特征 值,v1,v2,...,vm是特征值对应的特征向量,两边左乘a可以得到aa
t
avi=βiavi,即 cavi=βiavi,可以看出β1,β2,...,βm也是aa
t
的特征值,av1,av2,...,avm是特征值对应的 特征向量,实际上aa
t
应该有n个特征值(考虑重根),以及n个线性无关的特征向量, 而a
t
a的m个特征值与特征向量对应着aa
t
的前m个最大的特征值以及特征值相对应 的特征向量。所以通过这种变换,可以快速地求出aa
t
的特征向量ui=avi,i=1,2,...,m。
[0057]
进一步地,所述生成扰动的基于水平方向的投影矩阵的方法,结合图3,具体内容 如下:
[0058]
基于归一化后的基于水平方向的投影矩阵u,在投影矩阵每一列的索引位置加入敏感度为1、噪声尺度为1/ε的拉普拉斯噪声lap(1/ε),生成扰动的投影矩阵u
′
, ε表示隐私预算。
[0059]
进一步地,所述重构人脸图像的方法,具体内容如下:
[0060]
根据f
new
=vv
t
au
′u′
t
得到重构人脸图像f
new
,其中,v表示基于垂直方向的投影 矩
阵,u
′
表示加噪后的基于水平方向的投影矩阵。根据加噪后的投影矩阵u
′
重构人脸图 像f
new
,客户端将重构人脸图像上传至服务器。
[0061]
进一步地,在mindspore开源框架下利用神经网络进行人脸识别,步骤6所述训练 重构人脸图像,具体内容如下:
[0062]
取重构人脸图像数据集的70%当作训练集,将其中30%当作测试集,将图片和标 签送入网络进行训练并保存模型,通过多层感知机(mlp)训练数据集进行人脸识别。多 层感知机是一种前馈神经网络,含有至少一个隐藏层的由全连接层组成的神经网络,该 网络由两层全连接层和一层激活函数组成,第一个全连接层fc1的输入有w*h个节点, 输出有512个节点,激活后的全连接层输入节点数为512,输出节点数为人脸集的类别 数。
[0063]
进一步地,所述投影矩阵扰动的前后对比,具体内容如下:
[0064]
2dpca在pca方法上进行改进,不需要事先把图像转成一维向量,而是直接根据 图像的二维矩阵生成总体散布矩阵,进而根据特征值最大的k个特征值对应的特征向量 生成投影矩阵,将投影矩阵中的数据归一化,敏感度作为噪声量大小的参数,表示删除 数据集中某一记录对查询结果造成的最大影响,因此其敏感度为1,根据中某一记录对查询结果造成的最大影响,因此其敏感度为1,根据在投影矩阵上加入拉普拉斯噪声,其中,ε表示隐私预算,表示 归一化后的投影矩阵的位置,表示根据归一化矩阵计算的扰动,加入扰动的投影矩 阵进行重构数据时保护了图像的隐私信息。
[0065]
进一步地,发明者在本发明mindspore的隐私保护人脸识别方法中使用lfw数据 集,选取其中1140张人脸图像,它们来自人脸图像数量超过100张的5个人,将其中 70%的数据当作训练集,30%的数据当作测试集。在实际操作中基于不同的光照条件和 成像角度时会导致人脸识别率大幅下降的问题,使用投影矩阵时需限制图像在统一的光 照条件下使用正面图像进行识别。
[0066]
进一步地,发明者在本发明mindspore的隐私保护人脸识别方法中使用多层感知机 对人脸数据集分类,是一种前馈神经网络,该网络由两层全连接层和一层激活函数组成, 其克服了感知器不能对线性不可分数据进行识别的弱点。
[0067]
进一步地,结合图4,发明者在本发明基于mindspore的隐私保护人脸识别方法中 调节参数维持人脸识别准确性和图像隐私性的平衡。随着隐私预算ε的不断增大,分类 准确率逐渐增大,隐私性逐步降低,因此ε保持在(0,9]有利于保持准确性和图像隐私性 的平衡;并且,随着主成分数量的增大,每个人的人脸图像数量越多,分类准确率随之 提高。将数据发送给第三方前进行扰动,较好的保证了数据的隐私性,化解了消费者在 使用数据驱动的产品或服务遭遇的隐私危机,促进了数据产业的发展。
[0068]
下面将结合实例对本发明作进一步详细说明。
[0069]
实施例
[0070]
本发明提出一种基于mindspore的隐私保护人脸识别方法,其基于mindspore深度 学习框架搭建,数据集采用lfw数据集,数据由边缘端传给服务器,引入2dpca和 差分隐私,结合图1,其主要步骤具体如下:
[0071]
步骤1、获取人脸图像:将人脸图像裁剪成统一的大小,宽为w、高为h;
[0072]
步骤2、得到投影矩阵和特征矩阵:根据数据集中人脸图像的二维矩阵ai,ai∈rh×w, 分别基于水平方向和垂直方向生成协方差矩阵g
t
和h
t
,进一步得到水平方向的最佳投影 矩阵u和特征矩阵b,以及垂直方向的最佳投影矩阵v和特征矩阵c;
[0073]
步骤3、基于水平方向的投影矩阵归一化:将生成的基于水平方向的特征矩阵u数 据归一化到[0,1];
[0074]
步骤4、生成扰动的基于水平方向的投影矩阵:在基于水平方向的投影矩阵上加入 拉普拉斯噪声生成扰动的投影矩阵u
′
;
[0075]
步骤5、重构人脸图像:根据扰动的基于水平方向的2dpca方法得到的投影矩阵 u和基于垂直方向的2dpca得到的投影矩阵v生成重构人脸图像f
new
;
[0076]
步骤6、训练重构人脸图像数据集:使用多层感知机mlp训练重构人脸图像数据 集进行分类。
[0077]
进一步地,用户发送人脸图像给服务器之前会对图像进行随机化,通过扰动的投影 矩阵重新生成人脸图像,从而保护图像隐私信息。
[0078]
进一步地,其服务器接收扰动后的人脸图像,不可信的第三方无法获取图像包含的 人脸信息。
[0079]
进一步地,其服务器端对重构人脸数据集进行人脸识别,通过调节不同的隐私预算 等参数,保持人脸识别准确性和图像隐私性的平衡。
[0080]
表1符号描述
[0081]
[0082]
本发明提出一种扰动投影矩阵的人脸图像隐私保护方法,其特征在于,基于 mindspore开源计算框架实现步骤2中所述的2dpca方法生成投影矩阵和特征矩阵, 结合图2,其基本步骤具体如下:
[0083]
其所述2dpca方法,结合表1、图2,其基本步骤具体如下:
[0084]
步骤2.1、获取数据集:假设有n个样本,构成训练集的图片需要在相同的照明条 件下拍摄,并将所有图像的眼睛和嘴对齐,图像样本的宽为w,高为h,表示为二维矩 阵ai∈rh×w,数据集s=a1,...,an,i=1,...,n;
[0085]
步骤2.2、对图像进行中心化处理:每一个图像矩阵需要减掉均值矩阵根据得到中心化图像cai。
[0086]
步骤2.3、基于水平方向的2dpca方法得到协方差矩阵g
t
∈rn×n;
[0087]
步骤2.4、根据g
t
ui=λiui进行特征值分解,λi表示特征值,ui表示特征向量;
[0088]
步骤2.5、将n个特征值从大到小排序,截取前k个特征值及其对应的特征向量, 组成水平方向的变换矩阵u=[e1,e2,...,ek],u∈rn×k,ei为特征向量ei∈rn×1,这些 特征向量组成了投影空间u,图像的特征矩阵b=au;
[0089]
步骤2.6、基于垂直方向的2dpca方法得到协方差矩阵h
t
∈ rm×m;
[0090]
步骤2.7、根据h
t
vi=λivi进行特征值分解,λi表示特征值,vi表示特征向量;
[0091]
步骤2.8、将m个特征值从大到小排序,截取前k个特征值及其对应的特征向量, 组成垂直方向的变换矩阵v=[e1,e2,...,ek]
t
,v∈rm×k,ei为特征向量ei∈rn×1,这些 特征向量组成了投影空间v,图像的特征矩阵c=v
t
a;
[0092]
进一步地,所述特征值分解的方法,当n远大于m时的具体内容如下:
[0093]
协方差矩阵是一个高维矩阵c∈rn×n,如果直接进行特征分解,当n远大于m时 不仅消耗资源且费时。因此当n远大于m时,先进行a
t
a的特征值分解,因为a
t
a∈ rm×m,此时维度要小得多,由此可以得到a
t
avi=βivi,假设β1,β2,...,βm是a
t
a的特征 值,v1,v2,...,vm是特征值对应的特征向量,两边左乘a可以得到aa
t
avi=βiavi,即 cavi=βiavi,可以看出β1,β2,...,βm也是aa
t
的特征值,av1,av2,...,avm是特征值对应的 特征向量,实际上aa
t
应该有n个特征值(考虑重根),以及n个线性无关的特征向量, 而a
t
a的m个特征值与特征向量对应着aa
t
的前m个最大的特征值以及特征值相对应 的特征向量。所以通过这种变换,可以快速地求出aa
t
的特征向量ui=avi,i=1,2,...,m。
[0094]
进一步地,所述生成扰动的基于水平方向的投影矩阵的方法,结合图3,具体内容 如下:
[0095]
基于归一化后的基于水平方向的投影矩阵u,在投影矩阵每一列的索引位置加入敏感度为1、噪声尺度为1/ε的拉普拉斯噪声lap(1/ε),生成扰动的投影矩阵u
′
, ε表示隐私预算。
[0096]
进一步地,所述重构人脸图像的方法,具体内容如下:
[0097]
根据f
new
=vv
t
au
′u′
t
得到重构人脸图像f
new
,其中,y表示基于垂直方向的投影 矩阵,u
′
表示加噪后的基于水平方向的投影矩阵。根据加噪后的投影矩阵u
′
重构人脸图 像f
new
,客户端将重构人脸图像上传至服务器。
[0098]
进一步地,在mindspore开源框架下利用神经网络进行人脸识别,步骤6所述训练 重构人脸图像,具体内容如下:
[0099]
取重构人脸图像数据集的70%当作训练集,将其中30%当作测试集,将图片和标 签送入网络进行训练并保存模型,通过多层感知机(mlp)训练数据集进行人脸识别。多 层感知机是一种前馈神经网络,含有至少一个隐藏层的由全连接层组成的神经网络,该 网络由两层全连接层和一层激活函数组成,第一个全连接层fc1的输入有w*h个节点, 输出有512个节点,激活后的全连接层输入节点数为512,输出节点数为人脸集的类别 数。
[0100]
进一步地,所述投影矩阵扰动的前后对比,具体内容如下:
[0101]
2dpca在pca方法上进行改进,不需要事先把图像转成一维向量,而是直接根据 图像的二维矩阵生成总体散布矩阵,进而根据特征值最大的k个特征值对应的特征向量 生成投影矩阵,将投影矩阵中的数据归一化,敏感度作为噪声量大小的参数,表示删除 数据集中某一记录对查询结果造成的最大影响,因此其敏感度为1,根据中某一记录对查询结果造成的最大影响,因此其敏感度为1,根据在投影矩阵上加入拉普拉斯噪声,其中,ε表示隐私预算,表示 归一化后的投影矩阵的位置,表示根据归一化矩阵计算的扰动,加入扰动的投影矩 阵进行重构数据时保护了图像的隐私信息。
[0102]
进一步地,本实施例在2.30ghz intel core i5-6300处理器以及8.00gb ram的 windows平台上进行实验,实验环境:python版本为3.7.5,mindspore版本为1.3.0。
[0103]
进一步地,发明者在本发明mindspore的隐私保护人脸识别方法中使用lfw数据 集,选取其中1140张人脸图像,它们来自人脸图像数量超过100张的5个人,这五个 人分别是colin powell,donald rumsfeld,george w bush,gerhard schroeder和tony blair, 将其中70%的数据当作训练集,30%的数据当作测试集。在实际操作中基于不同的光 照条件和成像角度时会导致人脸识别率大幅下降的问题,使用投影矩阵时需限制图像在 统一的光照条件下使用正面图像进行识别。
[0104]
进一步地,发明者在本发明mindspore的隐私保护人脸识别方法中使用多层感知机 对人脸数据集分类,是一种前馈神经网络,该网络由两层全连接层和一层激活函数组成, 其克服了感知器不能对线性不可分数据进行识别的弱点。
[0105]
进一步地,结合图4,发明者在本发明基于mindspore的隐私保护人脸识别方法中 调节参数维持人脸识别准确性和图像隐私性的平衡。随着隐私预算ε的不断增大,分类 准确率逐渐增大,隐私性逐步降低,因此ε保持在(0,9]有利于保持准确性和图像隐私性 的平衡;并且,随着主成分数量的增大,每个人的人脸图像数量越多,分类准确率随之 提高。将数据发送给第三方前进行扰动,将个人图像添加扰动,有效地掩盖图像原始特 征,较好的保证了数据的隐私性,该方法足够高效且轻量级,保障了产品功能正常的使 用,化解了消费者在使用数据驱动的产品或服务遭遇的隐私危机,促进了数据产业的发 展。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。