1.本发明属于生物医学领域,具体涉及一种检测高度近视易感人群的生物标志物组合。
背景技术:
2.我国是近视高发国家,高度近视的患病人数逐年增长,且呈现出年轻化趋势。高度近视可能会引起多种严重的并发症,甚至致盲,其带来的视力损害是永久性且不可逆的,目前公认为高度近视是致盲性眼病。依据2017年中华医学会眼科学分会眼视光学组制定的《重视高度近视防控的专家共识》,高度近视可以分为低风险的单纯性高度近视,以及高风险的病理性近视。低风险的高度近视虽然度数高,但一般不具有严重的眼底病变,且成年后趋于稳定。高风险的高度近视和病理性近视则会出现不可逆甚至致盲性的眼底病变,随着病程进展不断加深,近视度数会不断加深,伴随患者终生。
3.高度近视的发生涉及多因素复杂过程,发病机制仍不清楚,人类基因储存并传递着疾病相关发生风险的遗传信息,检测高度近视相关的基因突变能够尽早发现高度近视的发病风险隐患,并及时采取更科学理性的方式预防高度近视的发生。由此可见,寻找更有效的方法对高度近视患者和高危人群进行早期检测、风险预测和早期干预具有重要的临床意义。
4.目前中国人群高度近视遗传风险预测的方案主要是从欧美近视人群近视遗传学和基因组学研究的结果中挑选的12个到400个不等的易感基因(非hla区域基因)。根据这些基因设计探针,进行芯片杂交检测或者采用mass arrray飞行时间质谱(maldi-tof)技术进行检测。
5.现有技术主要缺陷有3个方面,1)主要的易感基因来自于欧美人群近视的研究,对中国人群适用性差,此外近视和高度近视的遗传易感机制有巨大差异,近视易感基因不能代表高度近视易感基因;2)易感基因遍布整个基因组,要提高预测精度,就需要尽可能多的基因,同时,预测的成本会相应增加;3)检测的技术局限于芯片和质谱技术,对于新的变异形式缺少敏感性。
技术实现要素:
6.本发明为解决目前存在的技术问题,通过大规模采样检测,开发可以用来检测高度近视易感人群的标志物,结果显示高度近视同hla区域相关,并且hla区域有明显的欧美和亚洲人群特征,检测在所述hla区域内的snp位点在临床检测中具有应用价值。
7.snp组合
8.一方面,本发明提供了一种检测高度近视易感人群的snp组合,所述snp组合包括:rs41287240、rs9264661、rs2076183、rs9260167、rs36219014、rs1775070340、rs2071789、rs443198、rs1050459、rs1233712、rs11967、rs3132526、rs9277351、rs3130827、rs8227、rs204886、rs406113、rs4248153、rs210162、rs422951、rs41562816、rs1562746140、
rs397302、rs707951、rs3130100、rs145762166、rs2904763、rs2249464中的至少一个。
9.优选地,所述组合包括:rs41287240、rs9264661、rs2076183、rs9260167、rs36219014、rs1775070340、rs2071789、rs443198、rs1050459、rs1233712、rs11967、rs3132526、rs9277351、rs3130827、rs8227、rs204886、rs406113、rs4248153、rs210162、rs422951、rs41562816、rs1562746140、rs397302、rs707951、rs3130100、rs145762166、rs2904763、rs2249464。
10.以上snp位点的风险基因型如本发明表1所示。
11.本发明所述“snp”是指基因组水平上由单个核苷酸的变异所引起的dna序列多态性,在群体中的发生频率不小于1%,包括单个碱基的转换、颠换、插入和缺失等。
12.本发明所述“高度近视”也可以称为病理性近视、恶性近视,近视度数在600以上就称为高度近视。
13.本发明所述“检测高度近视易感人群”也就是预测高度近视的发生风险,在以上snp组合中任意一个或多个上的风险基因型的风险值高于阈值(cutoff)的受试者,更容易成为高度近视患者,也就称为高度近视易感人群。
14.方法
15.另一方面,本发明提供了一种检测高度近视易感人群的方法,所述方法包括根据hla区域的检测结果判断高度近视的发生风险的步骤。
16.优选地,所述方法包括根据hla区域的基因型判断高度近视的发生风险的步骤。
17.优选地,所述hla区域上包括前述snp组合。
18.优选地,所述hla区域是指前述snp组合。
19.优选地,所述hla区域的位置包括6号染色体上第28000000位-第34000000位(hg19)。更具体地,所述hla区域的位置是6号染色体上第28193131位-第33560896位。
20.优选地,所述hla区域的检测结果是指前述snp组合上风险基因型的频率的检测结果。
21.优选地,所述方法包括以下步骤:
22.1)采集受试者样本,
23.2)提取dna,
24.3)检测snp,
25.4)根据测序结果计算snp组合上风险基因型的频率,
26.5)分析高度近视的发生风险。
27.优选地,所述受试者是青少年,具体地,青少年所对应的年龄是在6-18岁之间。
28.优选地,所述样本包括:口腔拭子、组织、血液、尿液、唾液、精液、乳汁、脑脊髓液、泪液、痰、粘液、腹水、胸膜积液、羊水、膀胱冲洗液和支气管肺泡灌洗液。
29.优选地,所述样本是口腔拭子。
30.优选地,所述提取dna可以采用本领域技术人员所熟知的任何方式,也可以提取rna后反转录得到dna。
31.优选地,所述检测snp是指检测snp风险基因型的频率。
32.优选地,所述检测snp的方法包括但不限于:taqman探针法、测序法、芯片法、飞行质谱仪(maldi-tofms)检测、限制性片段长度多态性法(pcr-rflp)、单链构象多态性法
(pcr-sscp)、等位基因特异性pcr(as-pcr)、snapshot法、snplex法、变性高效液相色谱法(dhplc)、变性梯度凝胶电泳法(dgge)。
33.本发明所述“单链构象多态性法(pcr-sscp)”是指单链dna在中性条件下会形成二级结构,不同的二级结构在电泳中会出现不同的迁移率。这种二级结构依赖于碱基的组成,单个碱基的改变也会影响其构象,最终会导致在凝胶上迁移速度的改变。在非变性聚丙烯酰胺凝胶上,短的单链dna和rna分子依其单碱基序列的不同而形成不同的构象,这样在凝胶上的迁移速率不同,出现不同的条带,检测snp。
34.本发明所述“限制性片段长度多态性法(pcr-rflp)”是指利用限制性内切酶的酶切位点的特异性,用两种或两种以上的限制性内切酶作用于同一dna片断,如果存在snp位点,酶切片断的长度和数量则会出现差异,根据电泳的结果就可以判断是否snp位点。但是该技术应用的前提是snp的位点必须含有该限制内切酶的识别位点。
35.本发明所述“变性梯度凝胶电泳法(dgge)”是利用长度相同的双链dna片段解链温度不同的原理,通过梯度变性胶将dna片段分开的电泳技术。电泳开始时,dna在胶中的迁移速率仅与分子大小有关,而一旦dna泳动到某一点时,即到达该dna变性浓度位置时,使得dna双链开始分开,从而大大降低了迁移速率。当迁移阻力与电场力平衡时,dna片段在凝胶中基本停止迁移。由于不同的dna片段的碱基组成有差异,使得其变性条件产生差异,从而在凝胶上形成不同的条带。
36.本发明所述“变性高效液相色谱法(dhplc)”是指目标核酸片段pcr扩增,部分加热变性后,含有突变碱基的dna序列由于错配碱基与正常碱基不能配对而形成异源双链。因包含错配碱基的杂合异源双链区比完全配对的同源配对区和固定相的亲和力弱,更易被从分离柱上洗脱下来,从而达到分离的目的。snps的有无最终表现为色谱峰的峰形或数目差异,依据此现象可很容易从色谱图中判断出突变的碱基。
37.本发明所述“等位基因特异性pcr(as-pcr)”是根据snp位点设计特异引物,其中一条链(特异链)的3
′
末端与snp位点的碱基互补(或相同),另一条链(普通链)按常规方法进行设计,因此,as-pcr技术是一种基于snp的pcr标记。因为特异引物在一种基因型中有扩增产物,在另一种基因型中没有扩增产物,用凝胶电泳就能够很容易地分辨出扩增产物的有无,从而确定基因型的snp。
38.本发明所述“利用飞行质谱仪(maldi-tofms)”是将变性的单链pcr产物通过与硅芯片上的化合物共价结合后,在硅芯片上进行引物的退火,延伸反应,突变部位配对的碱基与正常配对的碱基不相同。根据引物在延伸反应中所结合的不同碱基的不同质量在质谱仪上显示不同峰而检测snp。
39.优选地,所述测序法包括但不限于第一代测序、第二代测序、第三代测序。
40.优选地,所述第一代测序方法包括但不限于sanger法、焦磷酸测序法、连接酶法。
41.优选地,所述第二代测序的应用包括靶向区域测序、全外显子测序、全基因组测序、线粒体dna测序等。
42.本发明所述“第三代测序”是指单分子测序技术。dna测序时,不需要经过pcr扩增,实现了对每一条dna分子的单独测序。三代测序技术是未来主要发展方向,第三代测序技术应用包括但不限于在基因组测序、甲基化研究、突变鉴定(snp检测)这三个方面上。
43.优选地,所述检测snp选用测序法。
44.试剂盒
45.另一方面,本发明提供了一种检测高度近视易感人群的试剂盒,所述试剂盒包括检测前述hla区域的试剂和/或仪器。
46.优选地,所述hla区域包括前述snp组合。
47.优选地,所述检测snp的试剂/或仪器包括以下方法中使用的试剂/或仪器:taqman探针法、测序法、芯片法、飞行质谱仪(maldi-tofms)检测、限制性片段长度多态性法(pcr-rflp)、单链构象多态性法(pcr-sscp)、等位基因特异性pcr(as-pcr)、snapshot法、snplex法、变性高效液相色谱法(dhplc)、变性梯度凝胶电泳法(dgge)。
48.优选地,所述利用taqman探针法确定snp的多态性或基因型所需的试剂和/或仪器包括taqman探针、pcr引物对、定量pcr仪、进行基因分型的模块、taqman探针法所需要的其他试剂中的至少一种。
49.优选地,所述芯片法中可以使用的芯片包括基于核酸杂交反应的芯片、基于单碱基延伸反应的芯片、基于等位基因特异性引物延伸反应的芯片、基于“一步法”反应的芯片、基于引物连接反应的芯片、基于限制性内切酶反应的芯片、基于蛋白dna结合反应的芯片、基于荧光分子dna结合反应的芯片中的至少一种。
50.优选地,所述利用飞行质谱仪(maldi-tofms)检测法确定snp的多态性或基因型所需的试剂和/或仪器包括pcr引物对、基于单碱基延伸反应的延伸引物、磷酸酶、树脂、芯片、maldi-tof(matrix-assisted laser desorption/ionization
–
time of fligh,基质辅助激光解吸附电离飞行时间质谱)、sequenom massarray技术所需要的其他试剂和仪器中的至少一种。
51.系统
52.另一方面,本发明提供了一种检测高度近视易感人群的系统,所述系统包括根据hla区域的检测结果判断高度近视的发生风险的装置。
53.优选地,所述系统包括根据hla区域的基因型判断高度近视的发生风险的装置。
54.优选地,所述hla区域上包括前述snp组合。
55.优选地,所述hla区域的基因型是指前述snp组合的风险基因型的频率。
56.优选地,所述系统包括用于输入hla区域的基因型的输入装置。
57.优选地,所述系统还可以包括用于输出预测结果的输出装置。
58.优选地,所述系统还可以包括snp的检测装置。
59.优选地,所述系统还包括评估结果发送装置,所述评估结果发送装置可以将受试者的评估结果发送到患者或医护人员可以查阅的信息通信终端装置。
60.应用
61.另一方面,本发明提供了检测前述hla区域的基因型、snp组合的试剂在检测高度近视易感人群中的应用。
62.另一方面,本发明提供了前述检测高度近视易感人群的试剂盒、检测高度近视易感人群的系统在检测高度近视易感人群中的应用。
63.优选地,在制备检测高度近视易感人群的产品中的应用。
64.本发明的有益效果:本发明基于中国青少年高度近视万人队列,检测了hla区域,并进行关联分析和易感风险预测,结果表明hla区域能将有效地区分出正常人群和高度近
视人群。
附图说明
65.图1为测序平均深度对比图。
66.图2为不同位点上的测序深度统计图。
67.图3为pca聚类分析图。
68.图4为发现队列中基因型的关联分析图。
69.图5为prs28和prs1-4在验证队列中的区分结果,横坐标是1-特异性,纵坐标是灵敏度。
70.图6为prs28和prs5-8在验证队列中的区分结果,横坐标是1-特异性,纵坐标是灵敏度。
71.图7为prs28和prs9-12在验证队列中的区分结果,横坐标是1-特异性,纵坐标是灵敏度。
72.图8为prs28和prs13-16在验证队列中的区分结果,横坐标是1-特异性,纵坐标是灵敏度。
73.图9为prs28和prs17-20在验证队列中的区分结果,横坐标是1-特异性,纵坐标是灵敏度。
74.图10为prs28和prs21-24在验证队列中的区分结果,横坐标是1-特异性,纵坐标是灵敏度。
75.图11为prs28和prs25-28在验证队列中的区分结果,横坐标是1-特异性,纵坐标是灵敏度。
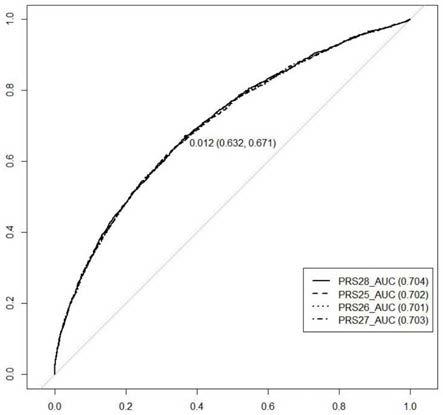
具体实施方式
76.下面结合实施例对本发明做进一步的说明,以下所述,仅是对本发明的较佳实施例而已,并非对本发明做其他形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更为同等变化的等效实施例。凡是未脱离本发明方案内容,依据本发明的技术实质对以下实施例所做的任何简单修改或等同变化,均落在本发明的保护范围内。
77.实施例1、基因突变的筛选及验证
78.实验方法
79.招募万例青少年高度近视人群和万例正常对照人群,对2万例人进行口腔拭子采样。对口腔拭子样本进行遗传物质dna提取,靶向hla区段外显子测序,平均测序深度及区域的具体测序深度如图1和图2所示。
80.实验结果
81.1)对hla区域测序数据进行质控、比对和变异检测,共检测到30310变异位点。
82.2)这些位点进行pca聚类分析,根据pca结果将样本分成发现队列(7346例高度近视样本 6827例正常人群样本)和验证队列(2952例高度近视样本 4524正常人群样本),如图3所示,其中发现队列如pca图上显示的患者样本和对照样本能最大程度重叠,保证发现队列是不受人群群体遗传结构的影响,进一步确保后续用发现队列进行关联分析的准确性。
83.3)对发现队列补充基因型后进行关联分析(logistic回归),找出在高度近视人群和正常人群频率差异大的变异位点,如图4所示。
84.4)去除位置上强连锁的位点后选取在发现队列关联分析结果中最显著的28个位点,进行多基因风险评分(polygenic risk score,prs),检验这些位点组合对验证队列的区分效果。
85.按照评分分数从高到低依次命名为snp1-28,28个位点及其在发现队列关联分析的p值如下表1,将突变位点组合之后,验证其诊断roc曲线,曲线图如图5-11所示,auc值汇总如表2所示。
86.表1.28个位点及其在发现队列关联分析的p值
[0087][0088]
表2.预测效果汇总
[0089][0090]
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。