1.本发明属于计算机数据处理技术领域,尤其涉及一种多模态数据扩充方法、系统、介质、计算机设备及终端。
背景技术:
2.目前,随着多媒体和互联网技术的发展,使用多模态信息来描述事件和事物已成为一种普遍的现象,例如,结合图像和文本模态进行新闻报道、结合视频和音频模态进行短视频制作等等。一般而言,同时出现的不同模态的数据之间存在着相关性,分析这种相关性对于挖掘数据和保护数据都有着重要的意义。目前,在多模态机器学习领域,相关的研究方向包括:图片描述(image captioning)、跨模态检索(cross-modal retrieval)、视觉问答(visual question answering)等,它们提供了开源的数据集,这些数据集为多模态机器学习的技术验证提供了支撑。为了取得更好的机器学习效果、提高模型在实际场景中的可用性,往往需要对数据进行扩充,在更丰富的数据集上训练模型。
3.数据扩充的一种可选方式是人工收集和标注数据,但这实施起来费时费力、效率低,现有的技术更倾向于自动扩充数据。对于图像模态,经典的自动数据扩充方法有:图像翻转、色度调整、随机擦除等等,对于文本模态,有:同义词替换、回译、随机噪声注入等等。然而,在多模态机器学习的背景下,这些传统的方式难以满足数据扩充的需求,以图片描述任务为例,该任务的目标是给图片生成相应的自然语言描述,训练集中的每个样本由一张图和一段文本描述组成,如果采用图像色度调整的方式扩充数据,那么扩充后图片的“颜色”语义将和文本段中的描述不一致,例如一个“红色的”苹果经过自动色度调整后可能成为一个“灰绿色”的苹果。类似的,图像翻转可能导致“方位”语义改变、随机擦除可能导致图像语义的缺失,而这些语义改变目前难以自动化地在文本描述上进行精确修正。因此,亟需设计一种新的数据扩充方法。
4.通过上述分析,现有技术存在的问题及缺陷为:
5.(1)传统的通过人工收集和标注数据的方法实施起来费时费力、效率低。
6.(2)在多模态机器学习的背景下,传统的方式难以满足数据扩充的需求。
7.(3)现有的数据扩充方式可能导致图像语义的缺失,而这些语义改变目前难以自动化地在文本描述上进行精确修正。
8.解决以上问题及缺陷的难度为:(1)需要消耗大量人工成本,难度较大。上述问题(2)、(3)目前尚没有统一的解决方案,解决难度大。
9.解决以上问题及缺陷的意义为:(1)降低数据扩充人工成本、提高数据扩充效率。(2)为多模态数据扩充的需求提供一种可行的解决方案。(3)可应用于跨模态检索、视觉问答、图像描述等多模态任务,使其训练样本更加丰富,提升训练效果。
技术实现要素:
10.针对现有技术存在的问题,本发明提供了一种多模态数据扩充方法、系统、介质、
计算机设备及终端。
11.本发明是这样实现的,一种多模态数据扩充方法,所述多模态数据扩充方法包括:通过扩充图像特征实现数据扩充;在提取时,使用基于卷积神经网络的目标检测模型进行提取,通过扰动感受野内图像的内容、改变目标检测框标定的位置,对进行扰动。
12.进一步,所述多模态数据扩充方法包括以下步骤:
13.步骤一,每次随机取k张图,对数据集中的图片进行拼接;通过图片拼接改变感受野中的图片内容,为扰动图片特征、扩充数据打下基础。
14.步骤二,在拼接后的大图上进行目标检测,得到检测框集合;是使用基于目标检测模型提取图像特征的常规步骤,通过观察比较本步骤得到的检测框与拼接前得到的检测框,发现框的位置和大小都有所差别,这为数据扩充提供了依据。
15.步骤三,对检测框集合中的检测框进行分组,将原属于一张图的检测框分为一组,对于一张拼接图,共得到k组检测框;
16.步骤四,对每组检测框对应的图片区域进行特征提取,与相应原图的文本描述结合为一对新的训练样本,对于每张拼接图,共得到k对新的训练样本。
17.在本发明的步骤三和步骤四中:对于拼图中的任意一个子图片(也就是拼接前的一张原图),保证了它经过扩充得到的特征不掺杂拼图中其他图片的特征,从而保证数据扩充不改变原图像的语义,起到高质量扩充的积极作用。步骤四中使得每次拼接能够得到k对新的训练样本,起到高效扩充的积极作用。
18.进一步,所述步骤一中的图片拼接后,感受野内的部分图像内容发生改变。
19.进一步,所述步骤一中的图片拼接包括:
20.设多模态数据集d中所有的图片集合为i={i1,i2,...,in},对于每个ii,随机取k张不重复的图片ik∈i,拼接为一张大图包括:
21.(1)在一次完整的数据扩充流程中,对于每个ii,拼接时k保持一致;
22.(2)k是整数,2≤k≤9;
23.(3)拼接的排布原则是使拼接后图片的长宽比尽可能小,当k=2时,两张图片选左右拼接或上下拼接,k=4时,图片拼接为“田”字型,k=6时,图片拼接为三行两列或两行三列,k=9时,图片排布为“九宫格”型,其他取值以最接近所述排布的方式进行拼接;
24.(4)拼接时不改变任一图片的长宽比,按所述板式拼接后,未对齐的部分用0值补齐。
25.进一步,所述步骤二中的获取检测框集合包括:
26.基于目标检测模型获取检测框,要求如下:
27.(1)根据k和拼接板式,按比例放大目标检测模型长边和短边的像素限制,当k=2,取左右拼接时,长边阈值取原阈值的2倍,短边阈值不变,k=4时,呈“田”字拼接,长边和短边阈值均为原阈值的2倍,k=9时,呈“九宫格”型拼接,长边和短边阈值均为原阈值的3倍;
28.(2)将输入目标检测模型,得到检测框位置集合共m*k个检测框;
29.(3)将检测框按照拼接前所属的图片进行分组,得到其中每
个其中p是检测框的置信度;
30.(4)对于长度大于m的,将检测框按照置信度排序,取置信度最高的前m个框,反之,用p=((0,0),(0,0),0)补齐;
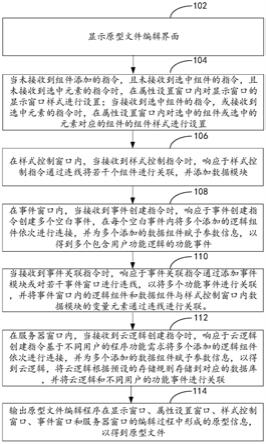
31.(5)由于检测框是分布在上,得到的坐标均以的左上角为原点;对于集合ik中的每个根据在上的位置及坐标集合将坐标修正为以左上角为原点的坐标,从而与原始数据集的数据分布保持一致,修正后的的坐标表示为得到的k组坐标集合表示为
32.进一步,所述步骤三中的新的训练样本的获取包括:
33.对于oi中的每个与其对应的取对应区域图片,输入特征抽取模型,得到新的特征则为一对新的训练样本。通过该方式,经过一次拼接得到k个新样本,若原数据集中图片集合的大小为n,那么经过一次完整的数据扩充流程,得到n*k个新的训练样本。
34.本发明的另一目的在于提供一种应用所述的多模态数据扩充方法的多模态数据扩充系统,所述多模态数据扩充系统包括:
35.图片拼接模块,用于通过每次随机取k张图对数据集中的图片进行拼接;
36.检测框集合获取模块,用于在拼接后大图上进行目标检测得到检测框集合;
37.检测框分组模块,用于对检测框集合中的检测框进行分组,将原属于一张图的检测框分为一组,对于一张拼接图,共得到k组检测框;
38.训练样本获取模块,用于对每组检测框对应的图片区域进行特征提取,与相应原图的文本描述结合为一对新的训练样本,对于每张拼接图,共得到k对新的训练样本。
39.本发明的另一目的在于提供一种计算机设备,所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行如下步骤:
40.通过扩充实现数据扩充;在提取时,基于卷积神经网络的目标检测模型提到的特征与感受野的大小、目标检测框标定的位置,以及图片的内容相关,在网络结构不变的情况下,感受野的大小不变,通过改变感受野内图片的内容,或者改变目标检测框标定的位置对提取到的特征进行扰动。
41.本发明的另一目的在于提供一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行如下步骤:
42.通过扩充实现数据扩充;在提取时,基于卷积神经网络的目标检测模型提到的特征与感受野的大小、目标检测框标定的位置,以及图片的内容相关,在网络结构不变的情况下,感受野的大小不变,通过改变感受野内图片的内容,或者改变目标检测框标定的位置对提取到的特征进行扰动。
43.本发明的另一目的在于提供一种信息数据处理终端,所述信息数据处理终端用于实现所述的多模态数据扩充系统。
44.结合上述的所有技术方案,本发明所具备的优点及积极效果为:本发明提供的多模态数据扩充方法,通过扩充图像特征来进行数据扩充,能够在不改变任一模态数据语义信息的情况下,自动进行数据扩充。因此,本发明不改变多模态训练数据中任一模态的语义信息,数据扩充效果好;本发明能够自动进行数据扩充,人工成本低、数据扩充效率高。
45.本发明在跨模态检索、视觉问答、图像描述任务上进行了验证,能够使训练样本更加丰富,提升训练效果。
附图说明
46.为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例中所需要使用的附图做简单的介绍,显而易见地,下面所描述的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下还可以根据这些附图获得其他的附图。
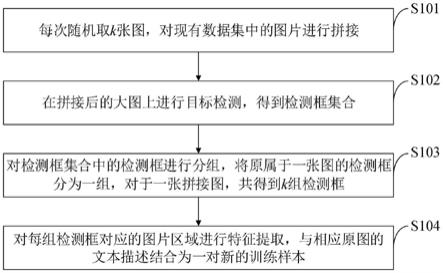
47.图1是本发明实施例提供的多模态数据扩充方法流程图。
48.图2是本发明实施例提供的多模态数据扩充系统结构框图;
49.图中:1、图片拼接模块;2、检测框集合获取模块;3、检测框分组模块;4、训练样本获取模块。
50.图3是本发明实施例提供的拼接前后图片对比示意图。
51.图3a是本发明实施例提供的拼接前图片i
190141
的示意图。
52.图3b是本发明实施例提供的拼接前图片i
202099
的示意图。
53.图3c是本发明实施例提供的拼接后图片的示意图。
54.图4是本发明实施例提供的拼接图片的检测框位置示意图。
55.图5是本发明实施例提供的拼接前图片的检测框位置示意图。
56.图5a是本发明实施例提供的拼接前图片i
190141
的检测框位置示意图。
57.图5b是本发明实施例提供的拼接前图片i
202099
的检测框位置示意图。
具体实施方式
58.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
59.针对现有技术存在的问题,本发明提供了一种多模态数据扩充方法、系统、介质、计算机设备及终端,下面结合附图对本发明作详细的描述。
60.如图1所示,本发明实施例提供的多模态数据扩充方法包括以下步骤:
61.s101,每次随机取k张图,对现有数据集中的图片进行拼接;
62.s102,在拼接后的大图上进行目标检测,得到检测框集合;
63.s103,对检测框集合中的检测框进行分组,将原属于一张图的检测框分为一组,对于一张拼接图,共得到k组检测框;
64.s104,对每组检测框对应的图片区域进行特征提取,与相应原图的文本描述结合为一对新的训练样本。
65.如图2所示,本发明实施例提供的多模态数据扩充系统包括:
66.图片拼接模块1,用于通过每次随机取k张图对数据集中的图片进行拼接;
67.检测框集合获取模块2,用于在拼接后的大图上进行目标检测,得到检测框集合;
68.检测框分组模块3,用于对检测框集合中的检测框进行分组,将原属于一张图的检测框分为一组,对于一张拼接图,共得到k组检测框;
69.训练样本获取模块4,用于对每组检测框对应的图片区域进行特征提取,与相应原图的文本描述结合为一对新的训练样本,对于每张拼接图,共得到k对新的训练样本。
70.下面结合具体实施例对本发明的技术方案作进一步描述。
71.实施例1
72.鉴于现有技术存在的问题,本发明提供了一种多模态数据扩充方式,能够在不改变任一模态数据语义信息的情况下,自动进行数据扩充。
73.一、方案阐述
74.设有多模态数据集d={(i1,t1),(i2,t2),...,(in,tn)},其中ii是一张图片,ti是图片对应的一条文本,(ii,ti)组成一对样本,数据集中有n对样本,对于这样的数据,一般的流程是先分别提取ii的特征和ti的特征然后基于多模态机器学习模型对和之间的关系建模,因而实际上构成一对训练样本。特别的,提取分为两步,第一步是通过卷积神经网络目标检测模型从ii中检测出图片中的所有目标物体,将目标出现的位置表示为一个大小为m的集合o={p1,p2,...pm},其中,pj=((w0,h0),(w1,h1)),pj是一个检测框的坐标,标识一个目标物体在图片中的位置,以图片左上角为坐标原点,(w0,h0)是检测框左上角的坐标,(w1,h1)是右下角的坐标,w代表宽度(长边),h代表高度(短边)。第二步是对于每个pj,提取它在ii中对应区域的特征向量fj,得到
75.本发明通过扩充来实现数据扩充。在提取时,基于卷积神经网络的目标检测模型提到的特征与感受野的大小、目标检测框标定的位置,以及图片的内容相关,在网络结构不变的情况下,感受野的大小不变,那么,可以通过改变感受野内图片的内容,或者改变目标检测框标定的位置来对提取到的特征进行扰动。本发明希望在不改变图像的语义的前提下高效地扩充数据,提出的思路是:第一步,对现有数据集中的图片进行拼接,每次随机取k张图拼接,通过这个步骤,感受野内的部分图像内容发生改变。接着,在拼接后的大图上进行目标检测,得到检测框集合,在这个步骤中,目标检测框可能发生改变。然后,对检测框集合中的检测框进行分组,将原属于一张图的检测框分为一组,对于一张拼接图,共得到k组检测框,通过分组,每组检测框排除了不属于本张图片的检测框对图片语义的影响。最后,对每组检测框对应的图片区域进行特征提取,与相应原图的文本描述结合为一对新的训练样本。具体过程描述如下:
76.1.图片拼接
77.设多模态数据集d中所有的图片集合为i={i1,i2,...,in},对于每个ii,随机取k张不重复的图片ik∈i,拼接为一张大图本发明要求:
78.1)在一次完整的数据扩充流程中,对于每个ii,拼接时k保持一致;
79.2)k是整数,2≤k≤9;
80.3)拼接的排布原则是使拼接后图片的长宽比尽可能小,当k=2时,两张图片可选
左右拼接或上下拼接,k=4时,图片拼接如“田”字型,k=6时,图片拼接为三行两列或两行三列,k=9时,图片排布为“九宫格”型,其他的取值以最接近上述几种排布的方式进行拼接;
81.4)拼接时不改变任一图片的长宽比,按上述板式拼接后,未对齐的部分用0值补齐。
82.2.获取检测框集合
83.基于目标检测模型获取检测框,本发明要求:
84.1)根据k和拼接板式,按比例放大目标检测模型长边和短边的像素限制,例如k=2,取左右拼接时,长边阈值取原阈值的2倍,短边阈值不变,k=4时,呈“田”字拼接,长边和短边阈值都应为原阈值的2倍,k=9时,呈“九宫格”型拼接,长边和短边阈值都应为原阈值的3倍;
85.2)将输入目标检测模型,得到检测框位置集合共m*k个检测框;
86.3)将检测框按照拼接前所属的图片进行分组,得到其中每个其中p是检测框的置信度;
87.4)由于检测框是分布在上,分组后的长度可能不统一,对于长度大于m的,将检测框按照置信度排序,取置信度最高的前m个框,反之,用p=((0,0),(0,0),0)补齐;
88.5)由于检测框是分布在上,得到的坐标都是以的左上角为原点的,因此,对于集合ik中的每个需要根据它在上的位置及坐标集合将坐标修正为以左上角为原点的坐标,从而与原始数据集的数据分布保持一致,修正后的的坐标表示为得到的k组坐标集合表示为
89.3.得到新的训练样本
90.对于oi中的每个与其对应的取对应区域图片,输入特征抽取模型,得到新的特征则为一对新的训练样本。
91.通过上述方式,经过一次拼接可以得到k个新样本,若原数据集中图片集合的大小为n,那么经过一次完整的数据扩充流程,可以得到n*k个新的训练样本,在不改变任一模态数据的语义的情况下,高效地扩充了数据。
92.实施例2
93.本实施例描述了一次拼接的实施过程,以“coco caption train2014”数据集中的图片集合i为例,取k=2,m=10,即拼接2张图片,每张图片取10个检测目标对象的特征。
94.1.图片拼接
95.以i中标号为000000190141的图片i
190141
为例,随机取到图片集合{i
190141
,i
202099
},对于k=2,本实施例采用左右拼接的方式,拼接为图片拼接不改变这两张图片的长宽比,拼接前i
190141
的分辨率为640*423,i
202099
的分辨率为640*480,由于i
190141
和i
202099
宽度
不同,拼接时未对齐的部分用0值补齐,拼接后的分辨率为1280*480。图3展示了拼接前后的图片。
96.2.获取检测框集合
97.本实施例使用fasterrcnn目标检测模型获取检测框。
98.1)模型原默认长边分辨率阈值为1333,短边阈值为800,根据图片拼接的张数和布局,本实施例将长边阈值放大为2666,短边阈值不变。
99.2)将输入模型,取置信度最高的前20个检测框集合,图4展示了这些检测框的位置。
100.3)将检测框按照拼接前所属的图片进行分组,本例通过计算检测框的面积与原图片的相交比来自动判断一个检测框是否属于某张图片,计算方法如下:
[0101][0102][0103]
4)在本实施例中,分组后,每组恰好有10个检测框,无需截断或补齐。
[0104]
5)对于图i
190141
,它在中的坐标为(0,0,640,423),它与的坐标原点重合,无需修正属于该图的检测框,该图的检测框坐标集合为合,无需修正属于该图的检测框,该图的检测框坐标集合为对于图i
202099
,它在中的坐标为(640,0,1280,480),其坐标原点与不重合,对于属于该图的检测框,修正为以该图左上角为原点的坐标,得到检测框集合
[0105]
3.得到新的训练样本
[0106]
基于fasterrcnn,提取i
190141
对应中检测框的特征得到新样本提取i
202099
对应中检测框的特征得到新样本
[0107]
经过本例的拼接过程得到了2个新样本,图5展示了拼接前图i
190141
和i
202099
中前10个检测框的位置,对比图4,对应图片的检测框位置有所不同,可以推知根据这些区域得到的特征也有所区别,也就是说,通过本发明的流程,能够得到更丰富的特征。一次完整的数据扩充是需要对原数据集中的每个样本进行本例所示的过程,经过一次完整的数据扩充,能够得到n*k个新样本。本发明对跨模态检索、视觉问答、图像描述等图-文模态的多模态研究方向都可以适用。具体落地应用场景例如:电商平台以文本检索商品、基于图像描述的网络图像自动审核等。
[0108]
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用全部或部分地以计算机程序产品的形式实现,所述计算机程序产品包括一个或多个计算机指令。在计算机上加载或执行所述计算机程序指令时,全部或部分地产生按照本发明实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(dsl)或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输)。所述计算机可读取存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质(例如软盘、硬盘、磁带)、光介质(例如dvd)、或者半导体介质(例如固态硬盘solid state disk(ssd))等。
[0109]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。