1.本发明涉及图像处理技术领域,尤其涉及一种结合跨尺度特征提取及帧结构感知聚合的视频人脸识别技术,具体是一种基于帧结构感知聚合的视频人脸识别方法。
背景技术:
2.针对视频人脸识别这一技术有所突破,将会提高视频监控、人物身份识别等任务的效率。视频比图像多了一个时间维度,可以理解为一个有序图像集,其中人脸图像大都低质。如何从视频序列中提取利于识别的特征表示尤为重要。目前,在较为先进的视频人脸识别模型中,其输入都是经过预处理的视频帧,且主要的方案大致分为两种:对视频帧进行质量评估及筛选后再进行特征提取及识别和完整地利用视频序列的每一帧进行识别。第一类方法主要为了从视频片段中挑选关键帧,从而得到最佳质量的人脸特征表示。然而低质量帧的存在依旧会对视频帧的完整性以及结构信息的保留起着重要影响。第二类通常是基于图像集或是字典的方法,但此类方法往往存在效率低下及对视频中面部的复杂变化不敏感的问题。
3.视频人脸的特征学习可以分成两个阶段,分别是学习精确的特征表示和构建有效的视频帧聚合模型。第一阶段通常利用基于卷积神经网络的深度学习方法来实现,然而普通的深度网络并不能很好的完成对视频片段中面部的局部细节特征的学习。目前比较常见的特征聚合策略有最大池化及平均池化,且都是基于特征值的简单融合,易于实现但在应用于实际监控视频或是无约束条件下拍摄的视频,因遮挡、光照及模型等因素影响时,性能则通常较差。这类方法大多没有重视视频帧的位置、结构信息以及帧与帧之间的相互关系,从而在单个视频人脸图像帧数较多的ytf数据集和ijb-a数据集上综合性能表现不佳。
4.所以,需要一个新的技术方案来解决上述问题。
技术实现要素:
5.本发明的目的是针对现有技术不足,而提供一种基于帧结构感知聚合的视频人脸识别方法。这种方法采用跨尺度特征提取网络及帧结构感知聚合模块,学习更具鲁棒性的特征表示后进一步进行特征聚合,以达到提升视频人脸识别准确率的目的。
6.实现本发明目的的技术方案是:
7.一种基于帧结构感知聚合的视频人脸识别方法,包括如下步骤:
8.1)采用多任务卷积神经网络模型mtcnn(multi-task convolutional neural network,简称mtcnn)检测ijb-a和ytf数据集中的每一帧视频人脸数据,并将面部区域裁剪为固定尺寸的图像,得到输入视频帧大小为224
×
224;
9.2)采用跨尺度特征提取网络提取输入的每一个视频帧的特征表示:跨尺度特征提取网络包括全局特征提取、局部特征提取以和特征融合操作,用于全局特征提取的主干卷积网络由两层conv-64、两层conv-128、两层conv-256、两层conv-512依次叠加而成,且每个输出特征图尺寸逐步缩小,每类卷积层之后加入maxpool,主干卷积网络最后连接三层全连
接层及单层softmax;用来进行局部特征提取的局部聚合网络n1,n2,n3各包含两个尺寸为1
×
1卷积层、且n1,n2,n3分别接入主干网络的conv-64、conv-128及conv-256之后,最终由局部聚合网络n1,n2,n3得到各个尺度的特征图记为则得到每一帧的特征表示fi为:
[0010][0011]
式中,concat表示特征融合,up(
·
)为上采样操作;
[0012]
3)采用帧结构感知聚合模块为步骤2)中获得的每个特征图fi,i=1,...,n赋予权重:一次性将步骤2)中得到的多帧特征图fi,i=1,...,n输入至帧结构感知聚合模块,接着采用帧结构感知聚合,首先采用两种嵌入函数ψs(fi)=relu(w
ψfi
)及ψs(fj)=relu(w
ψfj
)得到某帧与其它帧之间的相互关系fi:fj,然后用s
(i,:)
=[s
i1
,s
i2
,s
i3
,...,s
in
]表示第i帧与各个视频帧的关系向量,用s
(:,i)
=[s
1i
,s
2i
,s
3i
,...,s
ni
]表示各个视频帧与第i帧的关系向量,进一步利用这两种关系向量得到结构因子σi,这一参数有助于确定某一帧在视频序列中的重要程度,将结构因子结合初始化内核q与该帧特征图得到对应权重en,并利用softmax进行归一化得到最终权重wn;
[0013]
4)将步骤2)中获得的每个特征图fi,i=1,...,n进行降维、并根依据步骤3)中获得的权重进行聚合,得到视频人脸特征向量:令第i帧视频帧特征为vi,采用全连接层对vi进行降维,视频人脸特征向量通过下式聚合而成:
[0014][0015]
式中,r表示视频人脸特征,wi为第i帧视频帧对应的权重;
[0016]
5)训练跨尺度特征提取网络及帧结构感知聚合:将步骤2)中的跨尺度特征提取网络与步骤3)、步骤4)所述的帧结构感知聚合过程结合在一起,形成端到端的训练方式:首先,不引入σn并初始化全零q,在ijb-a和ytf数据集上进行训练,接着固定参数q,再引入σn并进一步训练模型,让网络自动调整参数,采用构建两个共享权重的帧结构感知聚合过程来最小化平均对比损失:
[0017][0018]
式中,ri、rj分别为第i个对象的人脸特征与第j个对象的人脸特征,且当y
i,j
=1时,对象i与对象j有相同的标签,当y
i,j
=0时,对象i与对象j标签不同,常数m设置值为2;
[0019]
6)采用步骤5)得到的视频人脸识别模型完成识别任务:将不同质量的视频片段输入到步骤5)得到的模型中,输出最终的人脸特征表示r,再采用人脸识别网络框架deepface进行人脸识别。
[0020]
步骤3)中所述的帧间相互关系fi:fj的公式为:
[0021]si,j
=fi:fj=φ(fi)
t
ψs(fj),
[0022]
式中,fi和fj分别为第i帧与第j帧的特征表示,嵌入函数φs(fi)=relu(w
φfi
)与嵌入函数ψs(fj)=relu(w
ψfj
)在训练网络挖掘帧间结构关系的过程中采用1
×
1卷积实现、并引入relu激活函数,s
i,j
表示第i帧与第j帧的相互关系。
[0023]
步骤3)中所述的结构因子σi为:
[0024][0025]
式中,s
(i,:)
=[s
i1
,s
i2
,s
i3
,...,s
in
]表示第i帧与各个视频帧的关系向量,与此相对,用s
(:,i)
=[s
1i
,s
2i
,s
3i
,...,s
ni
]表示各个视频帧与第i帧的关系向量,其中i=1,...,n。
[0026]
步骤3)中所述的最终权重为:
[0027]en
=σ
nqtfn
,
[0028][0029]
其中,en表示帧特征图对应的权重,σi为结构因子,q为初始化内核,fn为第n帧特征表示,wn表示归一化之后的最终权重。
[0030]
本技术方案采用跨尺度特征提取网络学习视频帧特征表示,随着视频帧人脸姿态及镜头远近的变化,人脸局部特征可能会以不同的比例呈现,且当整体面部外观发生巨大变化时,精确地提取局部特征对识别起着重要作用,本技术方案在适应局部特征比例变化的同时,保持对不同尺度特征的高效学习;帧结构感知聚合过程聚合视频帧的特征,在聚合过程中各帧间特征的相互竞争与协作关系,关注视频全局范围的结构信息的同时,也对各个视频帧的位置信息进行了挖掘,最终根据这些信息确定每个帧的重要程度,这样得到的视频人脸特征表示将会大大提高识别准确率。
[0031]
这种方法采用跨尺度特征提取网络及帧结构感知聚合模块,学习更具鲁棒性的特征表示后进一步进行特征聚合,以达到提升视频人脸识别准确率的目的。
附图说明
[0032]
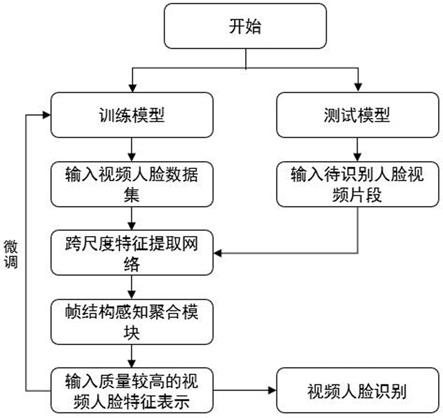
图1为实施例的流程示意图;
[0033]
图2为实施例中跨尺度特征提取网络示意图;
[0034]
图3为实施例中帧结构感知聚合过程示意图。
具体实施方式
[0035]
下面结合附图和实施例对本发明的内容作进一步地说明,但不是对本发明的限定。
[0036]
实施例:
[0037]
参照图1,一种基于帧结构感知聚合的视频人脸识别方法,包括如下步骤:
[0038]
1)采用多任务卷积神经网络模型mtcnn检测ijb-a和ytf数据集中的每一帧视频人脸数据,并将面部区域裁剪为固定尺寸的图像,得到输入视频帧大小为224
×
224;在本例中,得到的人脸图像大多从监控视频及无约束条件下拍摄而来,对视频人脸数据集的预处理阶段,首先采用多任务卷积神经网络模型来检测数据集中的人脸图像,得到含有人脸的且固定尺寸的输入视频帧,大小为224
×
224,该视频帧数量可变,本例调整为单个对象的视频帧数为24帧;
[0039]
2)采用跨尺度特征提取网络提取输入的每一个视频帧的特征表示:如图2所示,跨尺度特征提取网络包括全局特征提取、局部特征提取以和特征融合操作,在本例中,输入尺寸为224
×
224的视频帧,输出为h
×w×
c的特征,图用于全局特征提取的主干卷积网络由两
层conv-64、两层conv-128、两层conv-256、两层conv-512依次叠加而成,且每个输出特征图尺寸逐步缩小,每类卷积层之后加入maxpool,主干卷积网络最后连接三层全连接层及单层softmax;用来进行局部特征提取的局部聚合网络n1,n2,n3各包含两个尺寸为1
×
1卷积层、且n1,n2,n3分别接入主干网络的conv-64、conv-128及conv-256之后,最终由局部聚合网络n1,n2,n3得到各个尺度的特征图记为则得到每一帧的特征表示fi为:
[0040][0041]
式中,concat表示特征融合,up(
·
)为上采样操作,
[0042]
3)采用帧结构感知聚合模块为步骤2)中获得的每个特征图fi,i=1,...,n赋予权重:如图3所示,一次性将步骤2)中得到的多帧特征图fi,i=1,...,n输入至帧结构感知聚合模块,接着采用帧结构感知聚合,首先采用两种嵌入函数φs(fi)=relu(w
φfi
)及ψs(fj)=relu(w
ψfj
)得到某帧与其它帧之间的相互关系fi:fj,然后用s
(i,:)
=[s
i1
,s
i2
,s
i3
,...,s
in
]表示第i帧与各个视频帧的关系向量,用s
(:,i)
=[s
1i
,s
2i
,s
3i
,...,s
ni
]表示各个视频帧与第i帧的关系向量,进一步利用这两种关系向量得到结构因子σi,这一参数有助于确定某一帧在视频序列中的重要程度,将结构因子结合初始化内核q与该帧特征图得到对应权重en,并利用softmax进行归一化得到最终权重wn,本例中,考虑一个视频片段f={f1,f2,f3,...,fn},其中fi为视频帧的特征向量,n表示该视频帧的帧数;
[0043]
4)将步骤2)中获得的每个特征图fi,i=1,...,n进行降维、并根依据步骤3)中获得的权重进行聚合,得到视频人脸特征向量:令第i帧视频帧特征为vi,采用全连接层对vi进行降维,视频人脸特征向量通过下式聚合而成:
[0044][0045]
式中,r表示视频人脸特征,wi为第i帧视频帧对应的权重,本例中,采用全连接层对每一帧的特征图进行降维,结合上下文以及视频帧结构的信息,在融合过程中重要程度低的帧将进一步降低影响力,同时也使得到的特征向量更具判别性。
[0046]
5)训练跨尺度特征提取网络及帧结构感知聚合:将步骤2)中的跨尺度特征提取网络与步骤3)、步骤4)所述的帧结构感知聚合过程结合在一起,形成端到端的训练方式:首先,不引入σn并初始化全零q,在ijb-a和ytf数据集上进行训练,接着固定参数q,再引入σn并进一步训练模型,让网络自动调整参数,采用构建两个共享权重的帧结构感知聚合过程来最小化平均对比损失:
[0047][0048]
式中,ri、rj分别为第i个对象的人脸特征与第j个对象的人脸特征,且当y
i,j
=1时,对象i与对象j有相同的标签,当y
i,j
=0时,对象i与对象j标签不同,常数m设置值为2;
[0049]
6)采用步骤5)得到的视频人脸识别模型完成识别任务:将不同质量的视频片段输入到步骤5)得到的模型中,输出最终的人脸特征表示r,再采用人脸识别网络框架deepface进行人脸识别。
[0050]
步骤3)中所述的帧间相互关系fi:fj的公式为:
[0051]si,j
=fi:fj=φ(fi)
t
ψs(fj),
[0052]
式中,fi和fj分别为第i帧与第j帧的特征表示,嵌入函数φs(fi)=relu(w
φfi
)与嵌
入函数ψs(fj)=relu(w
ψfj
)在训练网络挖掘帧间结构关系的过程中采用1
×
1卷积实现、并引入relu激活函数,s
i,j
表示第i帧与第j帧的相互关系。
[0053]
步骤3)中所述的结构因子σi为:
[0054][0055]
式中,s
(i,:)
=[s
i1
,s
i2
,s
i3
,...,s
in
]表示第i帧与各个视频帧的关系向量,与此相对,用s
(:,i)
=[s
1i
,s
2i
,s
3i
,...,s
ni
]表示各个视频帧与第i帧的关系向量,其中i=1,...,n,这两个向量融合了该帧对应于视频片段f的位置和结构信息。
[0056]
步骤3)中所述的最终权重为:
[0057]en
=σ
nqtfn
,
[0058][0059]
其中,en表示帧特征图对应的权重,σi为结构因子,q为初始化内核,fn为第n帧特征表示,wn表示归一化之后的最终权重,关系向量和帧特征融合过后得到的描述符记为vi,其中i=1,2,...,n,该描述符既包含了各帧的全部特征也囊括了其与整体视频帧的结构关系及位置信息,结构因子在初始化内核q与帧特征相乘的同时为每帧赋予基于结构信息的权重。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。