技术特征:
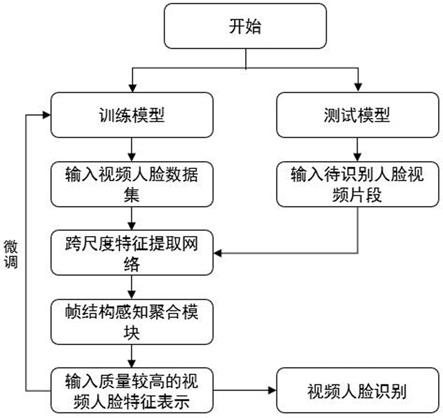
1.一种基于帧结构感知聚合的视频人脸识别方法,其特征在于,包括如下步骤:1)采用多任务卷积神经网络模型mtcnn检测ijb-a和ytf数据集中的每一帧视频人脸数据,并将面部区域裁剪为固定尺寸的图像,得到输入视频帧大小为224
×
224;2)采用跨尺度特征提取网络提取输入的每一个视频帧的特征表示:跨尺度特征提取网络包括全局特征提取、局部特征提取以和特征融合操作,用于全局特征提取的主干卷积网络由两层conv-64、两层conv-128、两层conv-256、两层conv-512依次叠加而成,且每个输出特征图尺寸逐步缩小,每类卷积层之后加入maxpool,主干卷积网络最后连接三层全连接层及单层softmax;用来进行局部特征提取的局部聚合网络n1,n2,n3各包含两个尺寸为1
×
1卷积层、且n1,n2,n3分别接入主干网络的conv-64、conv-128及conv-256之后,最终由局部聚合网络n1,n2,n3得到各个尺度的特征图记为则得到每一帧的特征表示f
i
为:式中,concat表示特征融合,up(
·
)为上采样操作;3)采用帧结构感知聚合模块为步骤2)中获得的每个特征图f
i
,i=1,...,n,赋予权重:一次性将步骤2)中得到的多帧特征图f
i
,i=1,...,n,输入至帧结构感知聚合模块,接着采用帧结构感知聚合,首先采用两种嵌入函数φ
s
(f
i
)=relu(w
φ
f
i
)及ψ
s
(f
j
)=relu(w
ψ
f
j
)得到某帧与其它帧之间的相互关系f
i
:f
j
,然后用s
(i,:)
=[s
i1
,s
i2
,s
i3
,...,s
in
]表示第i帧与各个视频帧的关系向量,用s
(:,i)
=[s
1i
,s
2i
,s
3i
,...,s
ni
]表示各个视频帧与第i帧的关系向量,进一步利用这两种关系向量得到结构因子σ
i
,将结构因子结合初始化内核q与该帧特征图得到对应权重e
n
,并利用softmax进行归一化得到最终权重w
n
;4)将步骤2)中获得的每个特征图f
i
,i=1,...,n,进行降维、并根依据步骤3)中获得的权重进行聚合,得到视频人脸特征向量:令第i帧视频帧特征为v
i
,并采用全连接层对v
i
进行降维,视频人脸特征向量通过下式聚合而成:式中,r表示视频人脸特征,w
i
为第i帧视频帧对应的权重;5)训练跨尺度特征提取网络及帧结构感知聚合:将步骤2)中的跨尺度特征提取网络与步骤3)、步骤4)所述的帧结构感知聚合过程结合在一起,形成端到端的训练方式:首先,不引入σ
n
并初始化全零q,在ijb-a和ytf数据集上进行训练,接着固定参数q,再引入σ
n
并进一步训练模型,让网络自动调整参数,采用构建两个共享权重的帧结构感知聚合过程来最小化平均对比损失:式中,r
i
、r
j
分别为第i个对象的人脸特征与第j个对象的人脸特征,且当y
i,j
=1时,对象i与对象j有相同的标签,当y
i,j
=0时,对象i与对象j标签不同,常数m设置值为2;6)采用步骤5)得到的视频人脸识别模型完成识别任务:将不同质量的视频片段输入到步骤5)得到的模型中,输出最终的人脸特征表示r,再采用人脸识别网络框架deepface进行人脸识别。2.根据权利要求1所述的基于帧结构感知聚合的视频人脸识别方法,其特征在于,步骤
3)中所述的帧间相互关系f
i
:f
j
的公式为:s
i,j
=f
i
:f
j
=φ(f
i
)
t
ψ
s
(f
j
),式中,f
i
和f
j
分别为第i帧与第j帧的特征表示,嵌入函数φ
s
(f
i
)=relu(w
φ
f
i
)与嵌入函数ψ
s
(f
j
)=relu(w
ψ
f
j
)在训练网络挖掘帧间结构关系的过程中采用1
×
1卷积实现、并引入relu激活函数,s
i,j
表示第i帧与第j帧的相互关系。3.根据权利要求1所述的基于帧结构感知聚合的视频人脸识别方法,其特征在于,步骤3)中所述的结构因子σ
i
为:式中,s
(i,:)
=[s
i1
,s
i2
,s
i3
,...,s
in
]表示第i帧与各个视频帧的关系向量,s
(:,i)
=[s
1i
,s
2i
,s
3i
,...,s
ni
]表示各个视频帧与第i帧的关系向量,其中i=1,...,n。4.根据权利要求1所述的基于帧结构感知聚合的视频人脸识别方法,其特征在于,步骤3)中所述的最终权重为:e
n
=σ
n
q
t
f
n
,其中,e
n
表示帧特征图对应的权重,σ
i
为结构因子,q为初始化内核,f
n
为第n帧特征表示,w
n
表示归一化之后的最终权重。
技术总结
本发明公开了一种基于帧结构感知聚合的视频人脸识别方法,包括:采用人脸检测模型检测视频数据中每一帧中所含的面部区域并裁剪为固定尺寸的图像,作为输入视频帧;采用跨尺度特征提取网络提取输入的每一个视频帧的特征表示;采用帧结构感知聚合模块为每个特征表示赋予权重;将每个特征图降维、并根据权重进行聚合,得到视频人脸特征向量;集训练模型、并微调网络参数;采用人脸识别网络框架完成最后的识别任务。这种特征提取网络能适应面部特征比例变化的同时,保持对不同尺度特征的高效学习,同时结合帧间关系的挖掘对上下文信息进行有效建模,能够利用各个视频帧的特征及其空间结构信息,最终获得更具鲁棒性的视频人脸特征表示用于识别。表示用于识别。表示用于识别。
技术研发人员:林乐平 张和为 欧阳宁 莫建文
受保护的技术使用者:桂林电子科技大学
技术研发日:2022.01.18
技术公布日:2022/4/22
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。