大数据量和高并发场景下提升gpu显卡计算效率的系统
技术领域
1.本发明涉及gpu显卡计算效率技术领域,尤其涉及大数据量和高并发场景下提升gpu显卡计算效率的系统。
背景技术:
2.深度学习模型训练完成后,一般需要在gpu显卡上部署推理服务,用来为客户端发来的数据请求给出基于深度学习模型的计算结果。例如,训练完文本的舆情分类模型后,需要在gpu显卡上部署推理服务,以便对客户端发来的文本舆情分类的请求,快速的给出计算结果。
3.为了在大数据量和高并发请求的场景下,提高gpu显卡的利用率,以便提升推理服务的数据处理速度,目前业内常用的策略有:
4.1.客户端增加每次请求发送的数据条数(batch size),或者通过多线程和多进程的方式提升请求并发度,来将计算压力全部施加给gpu显卡端。但由于性能和带宽等的限制,大多采用cpu服务器的客户端一般也难以大幅的增加请求的并发度,这会导致gpu端显卡的利用率不容易达到饱和运行状态,浪费了gpu的计算能力,也不容易整体提升数据的处理效率;而如果增加每次请求发送的数据量,在gpu显卡端就需要相应的构造更大的数据矩阵来容纳和处理这些数据,这又可能会导致显存溢出风险的提升,同时也会增加单次请求计算超时的风险。
5.2.增加配置固态硬盘或部署更多的gpu显卡,即通过横向扩展昂贵的高性能硬件资源,来提升数据读写和计算的速度。但这显然也会增加系统的硬件成本,对广大初创型或资金相对有限的研发团队来说,并不是友好和现实的方案。而且,如果不能充分利用好单张gpu显卡的计算能力,横向扩展更多的gpu显卡数量也会造成更大的资源浪费。
技术实现要素:
6.本发明的目的在于:为了解决上述问题,而提出的大数据量和高并发场景下提升gpu显卡计算效率的系统。
7.为了实现上述目的,本发明采用了如下技术方案:
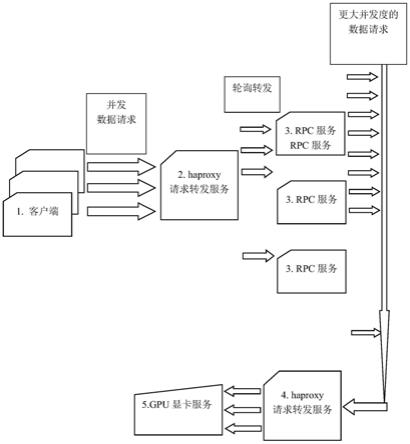
8.大数据量和高并发场景下提升gpu显卡计算效率的系统,包括:客户端、cpu服务器、3台用于rpc服务的服务器和gpu显卡,其特征在于,所述客户端用于发送并发数据请求,所述cpu服务器用来接收数据处理请求和将请求轮询转发给后续的处理端,所述gpu显卡具有模型计算服务。
9.优选地,所述cpu服务器部署开源的haproxy请求转发服务,用来接收客户端发来的请求,并通过轮询的方式转发给rpc服务。
10.优选地,3台用于rpc服务的所述服务器均采用开源的thrift服务充当rpc服务,进一步放大对gpu显卡的并发请求度。
11.优选地,所述cpu服务器接收用thrift启动的rpc服务发来的经过放大并发量的计
算请求,通过轮询的方式转发给gpu显卡上启动的模型计算服务。
12.优选地,所述gpu显卡启动三个舆情模型的计算服务,用来实际计算文本的舆情分类任务。
13.优选地,所述模型计算服务计算完成后,可按流程编号的逆序,将结果返回给客户端,上述采用的开源部署框架,都支持双向的数据请求和传输。
14.综上所述,由于采用了上述技术方案,本发明的有益效果是:
15.本技术通过不增加额外的高性能硬件资源,利用相对廉价的cpu服务器,并且每个客户端每次只需发送相对少量的请求数据,以及支持更多的客户端连接,就可以使gpu显卡达到满负载的运算状态,从而提升数据处理效率,且不容易发生溢出和超时等风险。
附图说明
16.图1示出了根据本发明实施例提供的系统流程结构示意图。
具体实施方式
17.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
18.请参阅图1,本发明提供一种技术方案:
19.大数据量和高并发场景下提升gpu显卡计算效率的系统,包括:客户端、cpu服务器、3台用于rpc服务的服务器和gpu显卡,客户端用于发送并发数据请求,cpu服务器用来接收数据处理请求和将请求轮询转发给后续的处理端,gpu显卡具有模型计算服务。cpu服务器部署开源的haproxy请求转发服务,用来接收客户端发来的请求,并通过轮询的方式转发给rpc服务。3台用于rpc服务的服务器均采用开源的thrift服务充当rpc服务,进一步放大对gpu显卡的并发请求度。cpu服务器接收用thrift启动的rpc服务发来的经过放大并发量的计算请求,通过轮询的方式转发给gpu显卡上启动的模型计算服务。gpu显卡启动三个舆情模型的计算服务,用来实际计算文本的舆情分类任务。模型计算服务计算完成后,可按流程编号的逆序,将结果返回给客户端,上述采用的开源部署框架,都支持双向的数据请求和传输。
20.具体的,如图1所示,cpu服务器部署开源的haproxy请求转发服务,用来接收客户端发来的请求,并通过轮询的方式转发后续3.中的rpc服务。示例的请求转发配置如下:
21.listen sentiment_thrift_60000
22.bind 192.168.12.2:60000
23.mode tcp
24.balance roundrobin
25.option tcplog
26.option abortonclose
27.option forwardfor except 127.0.0.0/8
28.maxconn 51200
29.server nlp0l 192.168.12.11:60001check inter 2000rise 2fall 3
30.server nlp02 192.168.12.11:60002check inter 2000rise 2fall 3
31.......
32.server nlp09 192.168.12.11:60009 check inter 2000 rise 2 fall 3
33.server nlp010 192.168.12.12:60001 check inter 2000 rise 2 fall 3
34.server nlp011 192.168.12.12:60002 check inter 2000 rise 2 fall 3
35.......
36.server nlp018 192.168.12.12:60009 check inter 2000 rise 2 fall 3
37.server nlp019 192.168.12.13:60001 check inter 2000 rise 2 fall 3
38.server nlp020 192.168.12.13:60002 check inter 2000 rise 2 fall 3
39.......
40.server nlp027 192.168.12.13:60009check inter 2000rise 2fall 3
41.这里的haproxy转发服务器的ip是192.168.12.2,并开放60000端口,用于接收客户端发来的数据请求;然后通过轮询(roundrobin)模式,将请求转发给配置中的三台服务器(ip分别是192.168.12.11、192.168.12.12、192.168.12.13)。并且,这三台服务器上分别开放从60001到60009的9个端口用于接收和处理请求,总共3*9=27个rpc的工作端口。
42.具体的,如图1所示,3台用于rpc服务的服务器均采用开源的thrift服务充当rpc服务,进一步放大对gpu显卡的并发请求度。3台用于rpc服务的服务器为上述中的那三台接收haproxy转发请求的服务器(ip分别是192.168.12.11、192.168.12.12、192.168.12.13,并分别开放从60001到60009的端口)。在这三台服务器上,可以用开源的thrift服务充当rpc服务,用来对接1.中客户端的请求(经过2.中haproxy轮询转发)和后续5.中的gpu显卡推理服务(同样经过4.中的haproxy轮询转发)。之所以在这里需要部署用于rpc的thrift服务,是因为通过thrift服务自带的多进程(forking)或线程池(thread pool)的服务模式,可以进一步放大对gpu显卡的并发请求度。也就是说,一方面可以容纳更大并发的客户端请求,另一方面可以相对客户端以更进一步放大的并发度请求gpu显卡上的计算服务。并且可以在每个客户端的每次请求计算数据量不大的情况下,通过充分利用gpu显卡计算的时间片和运算性能,在保持gpu显卡处于满负载运行状态的同时,大幅提升数据处理的速度。这里的三台rpc服务器上的27个thrift服务端口,通过设置,每个又可以支持数十到数百的响应并发度,从而达到27*n的请求并发度发送给后续的处理服务。这里的n是每个thrift服务端口程序配置的响应并发度(可设置为数十到数百)。并且,这里还可以配置数据处理策略,将客户端一次发送的较大的数据量,切分为多个批次,每个批次的数据量相对较少,避免后续gpu显卡服务因为单次处理的数据量过大而导致的溢出和超时的风险;同时,通过更大的并发度,充分利用gpu计算性能和时间片,让其保持满负荷的计算状态,达到整体提升数据计算速度的效果。
43.具体的,如图1所示,cpu服务器接收用thrift启动的rpc服务发来的计算请求,通过轮询的方式转发给gpu显卡上启动的模型计算服务,gpu显卡启动三个舆情模型的计算服务,用来实际计算文本的舆情分类任务。这里可以用跟2.中同一台的haproxy服务器。示例的转发配置如下:
44.listen sentiment_gpu_service_51000
45.bind 192.168.12.2:51000
46.mode tcp
47.balance roundrobin
48.option tcplog
49.option abortonc lose
50.option forwardfor except 127.0.0.0/8
51.maxconn 51200
52.server nlp0l 192.168.12.69:50001check inter 2000rise 2fall 3
53.server nlp02 192.168.12.69:50002check inter 2000rise 2fall 3
54.server nlp03 192.168.12.69:50003check inter 2000rise 2fall 3
55.即,在haproxy转发服务器上(ip为192.168.12.2)开放51000端口,用于接收3.中27个rpc端口发来的27*n个请求,再通过轮询(roundrobin)的模式,转发给gpu显卡上启动的3个模型推理的服务端口(这里gpu的ip为192.168.12.69,三个模型服务端口是50001、50002、50003)。在gpu的一张显卡上启动三个舆情模型的计算服务(这里采用bert的3层模型,语义向量维度为768),用来实际计算文本的舆情分类任务。这里的gpu服务器的ip和三个服务端口,就是上述4.中配置的192.168.12.69和50001、50002、50003。
56.具体的,如图1所示,模型计算服务计算完成后,可按流程编号的逆序,将结果返回给客户端,上述采用的开源部署框架,都支持双向的数据请求和传输。
57.实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
