用于数字病理学的用于处理载片的图像以对所处理的载片图像进行自动优先级化的系统和方法
1.相关申请本技术要求2019年5月31日提交的美国临时申请号62/855,199的优先权,其全部公开内容通过引用整体并入本文。
技术领域
2.本公开的各种实施例一般涉及基于图像的载片优先级化(slide prioritization)、提高数字病理学工作流程的效率、和相关的图像处理方法。更具体讲,本公开的特定实施例涉及用于提供自动优先级化过程以制备、处理和复查组织样本的载片的图像的系统和方法。
背景技术:
3.对于病理学患者病例,没有标准化或高效的方法对组织样本图像的复查进行优先级化。延伸而言,没有用于复查病理载片的标准化过程。在一些学术机构中,病理学实习生可对患者病例进行初步审查,对有重大发现和/或需要额外诊断检查(例如,免疫组织化学染色、重切(recut)、分子研究、特殊染色、科内磋商)的病例进行分类和优先级化。同时,患者诊断可能涉及使用数字化病理载片进行初步诊断。希望找到一种方法来加快载片制备过程并提高其效率。还希望找到一种方法来确保在病理学家复查载片时,病理载片具有足够的信息以得到诊断。
技术实现要素:
4.根据本公开的某些方面,公开了用于处理对应于样本的图像并自动对载片处理进行优先级化的系统和方法。
5.一种处理对应于样本的电子图像并自动对电子图像的处理进行优先级化的计算机实现方法包括:接收对应于目标样本的载片的目标电子图像,目标样本包括患者的组织采样;使用机器学习系统计算目标电子图像的优先级值,机器学习系统是通过处理多个训练图像而生成的,每个训练图像包括人体组织的图像和表征载片形态、诊断值、病理学家复查结果和/或分析难度中的至少一个的标签;以及输出数字化病理图像的序列,其中,基于目标电子图像的优先级值来将目标电子图像放置在序列中。
6.一种用于处理对应于样本的电子图像并自动对电子图像的处理进行优先级化的系统,包括:至少一个存储指令的存储器;以及至少一个处理器,被配置为执行所述指令以实行包括以下的操作:接收对应于目标样本的载片的目标电子图像,目标样本包括患者的组织采样;使用机器学习系统计算目标电子图像的优先级值,机器学习系统是通过处理多个训练图像而生成的,每个训练图像包括人体组织的图像和表征载片形态、诊断值、病理学家复查结果和/或分析难度中的至少一个的标签;以及输出数字化病理图像的序列,其中,基于目标电子图像的优先级值来将目标电子图像放置在序列中。
7.一种存储指令的非暂时性计算机可读介质,所述指令在被至少一个处理器执行时使得所述至少一个处理器实行用于处理对应于样本的电子图像并自动对图像处理进行优先级化的方法,所述方法包括:接收对应于目标样本的载片的目标电子图像,目标样本包括患者的组织采样;使用机器学习系统计算目标电子图像的优先级值,机器学习系统是通过处理多个训练图像而生成的,每个训练图像包括人体组织的图像和表征载片形态、诊断值、病理学家复查结果和/或分析难度中的至少一个的标签;以及输出数字化病理图像的序列,其中,基于目标电子图像的优先级值来将目标电子图像放置在序列中。
8.应当理解,前面的总体描述和下面的详细描述都只是示例性和解释性的,而不是对所要求保护的公开实施例的限制。
附图说明
9.并入本说明书并构成本说明书的一部分的附图示出了各种示例性实施例,并与说明书一起用于解释所公开的实施例的原理。
10.图1a是根据本公开的示例性实施例的用于提供用于制备、处理和复查组织样本的载片的图像的自动优先级化过程的系统和网络的示例性框图。
11.图1b是根据本公开的示例性实施例的疾病检测平台100的示例性框图。
12.图1c是根据本公开的示例性实施例的载片优先级化工具101的示例性框图。
13.图1d是根据本公开的示例性实施例的用于病理载片制备、处理和复查的自动优先级化过程的示例性系统的示图。
14.图2是根据本公开的示例性实施例的示例性方法的流程图,该示例性方法用于使用机器学习来分析对应于样本的载片的图像并提供经自动优先级化的载片处理。
15.图3是根据本公开的示例性实施例的用于自动对病理载片制备、处理和复查进行优先级化的示例性实施例的流程图。
16.图4是根据本公开的示例性实施例的生成和使用基于质量控制的病理载片制备优先级化工具的示例性实施例的流程图。
17.图5是根据本公开的示例性实施例的关于质量控制生成和使用病理载片制备优先级化工具的示例性实施例的流程图。
18.图6是根据本公开的示例性实施例的生成和使用诊断特征优先级化工具的示例性实施例的流程图。
19.图7是根据本公开的示例性实施例的生成和使用病理载片处理优先级化工具的示例性实施例的流程图。
20.图8是根据本公开的示例性实施例的生成和使用病理载片复查和分配优先级化工具的示例性实施例的流程图。
21.图9是根据本公开的示例性实施例的生成和使用个性化病理载片优先级化工具的示例性实施例的流程图。
22.图10是根据本公开的示例性实施例的生成和使用教育病理载片优先级化工具的示例性实施例的流程图。
23.图11描绘了可以执行本文呈现的技术的示例系统。
具体实施方式
24.现在将详细参考本公开的示例性实施例,其示例已经在附图中示出了。在可能的任何情况下,在所有附图中使用相同的附图标记来表示相同或相似的部件。
25.通过示例并参考附图详细描述了本文公开的系统、设备和方法。本文所讨论的示例仅是示例,并且被提供以帮助解释本文所描述的装置、设备、系统和方法。对于这些设备、系统或方法中的任何一个的任何特定实施方式,附图中所示或以下讨论的特征或组件都不应被认为是强制性的,除非被具体指定为强制性的。
26.此外,对于所描述的任何方法,无论该方法是否结合流程图来描述,应当理解,除非上下文另外指定或要求,否则在方法的执行中执行的步骤的任何显式或隐式排序都不暗示这些步骤必须以所呈现的顺序来执行,而是可以以不同的顺序或并行地执行。
27.如本文所用,术语“示例性”是在“示例”而非“理想”的意义上使用。此外,术语“一”和“一个”在此不表示数量的限制,而是表示存在一个或多个所引用的项目。
28.病理学涉及疾病的研究。更具体讲,病理学是指执行用于诊断疾病的测试和分析。例如,组织采样可被放置在载片上,以便由病理学家(例如,作为分析组织采样以确定是否存在任何异常的专家的医师)在显微镜下观察。也就是说,病理样本可以被切成多个分段、染色并制备成载片以供病理学家检查和进行诊断。当不确定载片上的诊断发现时,病理学家可命令(order)额外的切割水平、染色或其他测试以从组织中收集更多信息。然后,技术人员可以创建新的载片,其可以包含供病理学家在进行诊断时使用的额外信息。这种产生额外载片的过程可能是耗时的,不仅因为它可能会涉及取回组织块、将其切割以制作一个新的载片、然后对该载片染色,而且因为它可能会被分批用于多个命令。这可能会显著地延迟病理学家做出的最终诊断。另外,即使在延迟之后,可能也仍然不能保证新的载片将具有足以进行诊断的信息。
29.病理学家可以单独评估癌症和其他疾病的病理载片。统一的工作流程可以改进对癌症和其他疾病的诊断。该工作流程可以在一个工作站中集成例如载片评估、任务、图像分析和癌症检测人工智能(ai)、注释、磋商和建议。具体讲,示例性用户接口以及可被集成到工作流程中以加快和改善病理学家的工作的ai工具可以在工作流程中可用。
30.例如,计算机可被用于分析组织采样的图像以快速标识是否需要关于特定组织采样的额外信息,和/或向病理学家突显出他或她应该更靠近观看的区域。因此,获得额外的染色载片和测试的过程可以在病理学家检查之前自动完成。当与自动载片分段和染色机器配对之后,其可以提供完全自动化的载片制备流水线。
31.使用计算机来辅助病理学家的过程被称为计算病理学。用于计算病理学的计算方法可以包括但不限于统计分析、自主或机器学习和ai。ai可以包括但不限于深度学习、神经网络、分类、聚类和回归算法。通过使用计算病理学,可以通过帮助病理学家提高他们的诊断准确性、可靠性、效率和可及性来挽救生命。例如,计算病理学可以用于辅助检测疑似癌症的载片,从而使病理学家在进行最终诊断之前检查和确认他们的初始评估。
32.组织病理学是指对已经放置在载片上的样本的研究。例如,数字病理图像可以包括包含样本(例如,涂片)的显微镜载片的数字化图像。病理学家可以用于分析载片上的图像的一种方法是标识细胞核并对细胞核是正常的(例如,良性的)还是异常的(例如,恶性的)进行分类。为了帮助病理学家标识和分类细胞核,可以使用组织学染色来使细胞可见。
已经开发了许多基于染料的染色系统,包括高碘酸-schiff反应、masson三色、尼氏和亚甲蓝、以及苏木精和曙红(h&e)。对于医学诊断来说,h&e是广泛使用的基于染料的方法,其中苏木精将细胞核染成蓝色,曙红将细胞质和胞外基质染成粉红色,而其他组织区域呈现出这些颜色的变化。然而,在许多情况下,h&e染色的组织学制备物不能为病理学家提供足够的信息,以从视觉上标识可以帮助诊断或指导治疗的生物标记。在这种情况下,可以使用诸如免疫组织化学(ihc)、免疫荧光、原位杂交(ish)或荧光原位杂交(fish)之类的技术。ihc和免疫荧光例如包括使用与组织中的特定抗原结合的抗体,使得能够实现表达特定目的蛋白的细胞的视觉检测,这可以揭示出受过训练的病理学家不能基于h&e染色载片的分析可靠地标识的生物标记。根据所用探针的类型(例如用于基因拷贝数的dna探针和用于评估rna表达的rna探针),ish和fish可被用于评估基因拷贝数或特定rna分子的丰度。如果这些方法也未能提供足够的信息来检测一些生物标记,那么,组织的遗传测试可被用于确认生物标记是否存在(例如,肿瘤中特定蛋白质或基因产物的过表达、癌症中给定基因的扩增)。
33.可以准备数字化图像以示出染色的显微镜载片,这可以允许病理学家手动地查看载片上的图像并估计图像中染色的异常细胞的数目。然而,该过程可能是耗时的,并且可能会导致标识异常中的错误,因为一些异常难以检测。计算过程和设备可以用于帮助病理学家检测可能以其他方式难以检测的异常。例如,ai可以用于从使用h&e和其他基于染料的方法而染色的组织的数字图像内的显著区域中预测生物标记(例如蛋白质和/或基因产物的过表达、扩增或特定基因的突变)。组织的图像可以是全载片图像(wsi)、微阵列内的组织核心的图像或组织切片内的选定的感兴趣区域的图像。使用染色方法(如h&e),这些生物标记对于人类来说可能难以在没有额外测试的帮助下从视觉上检测或定量。使用ai从组织的数字图像推断这些生物标记具有改善病人照护的潜力,同时也更快且更便宜。
34.然后,检测到的生物标记或图像可以单独用于建议特定癌症药物或药物组合疗法以用于治疗患者,并且ai可以通过将检测到的生物标记与治疗选项的数据库相关联来标识哪些药物或药物组合不可能成功。这可以用于促进免疫治疗药物的自动建议以靶向患者的特定癌症。此外,这可被用于实现针对患者的特定子集和/或较罕见癌症类型的个性化癌症治疗。
35.在病理学领域中,可能难以在整个组织病理学工作流程中提供关于病理学样本制备的系统质量控制(“qc”)和关于诊断质量的质量保证(“qa”)。系统质量保证是困难的,因为它是资源和时间密集型的,因为它可能需要两个病理学家的重复努力。用于质量保证的一些方法包括(1)第二次复查第一次诊断癌症病例;(2)质量保证委员会对不一致或变化的诊断的定期复查;和/或(3)病例子集的随机复查。这些是非穷举的、大多是回顾性的和手动的。利用自动化和系统化的qc和qa机制,可以在整个工作流程中为每种病例确保质量。实验室质量控制和数字病理学质量控制对于患者样本的成功摄取、处理、诊断和存档是关键的。qc和qa的手工和抽样方法具有显著的益处。系统性qc和qa具有提供效率和提高诊断质量的潜力。
36.如上所述,本文描述的示例实施例提供了集成平台,其允许全自动过程,包括经由web浏览器或其他用户接口的数字病理图像的数据摄取、处理和查看,同时与实验室信息系统(lis)集成。此外,可以使用患者数据的基于云的数据分析来聚合临床信息。数据可以来自医院、诊所、本领域研究人员等,并且可以通过机器学习、计算机视觉、自然语言处理和/
或统计算法来分析,以在多个地理特异性水平上进行健康模式的实时监测和预测。
37.以前,无法对病理载片的制作或分析进行优先级化。因此,本文描述的示例实施例自动对载片制备、处理和复查进行优先级化,以便加速基于数字化病理图像的诊断并提高其效率。
38.这种自动化至少具有以下益处:(1)最小化病理学家确定载片不足以进行诊断所浪费的时间量,(2)通过避免在命令额外测试和产生额外测试之间的额外时间来最小化从样本采集到诊断的(平均总)时间,(3)允许病理学家在更短的时间内处理或复查更大量的载片,(4)通过减少向病理学家请求额外测试的开销而有助于更可靠/准确的诊断,(5)识别或验证数字病理图像的正确属性(例如,关于样本类型),和/或(6)训练病理学家,等等。本公开将所有病理病例的自动化检测、优先级化和分类用于涉及数字化病理载片的临床数字工作流程,使得病理载片分析可以在病理学家进行诊断复查之前被优先级化。例如,所公开的实施例可以提供病例级优先级化,并且对每个病例内具有重要发现的载片进行优先级化。这些优先级化实施例可在各种背景下(例如,学术、商业实验室、医院等)使病理载片的数字复查更高效。
39.所公开的实施例的示例性全局输出可以包含关于整个图像或载片的信息或载片参数,例如,所描绘的样本类型、载片中样本的整体切割质量、玻璃病理载片本身的整体质量或组织形态特征。示例性局部输出可指示图像或载片的特定区域中的信息,例如,特定载片区域可被标记为模糊或包含不相关样本。本公开包括用于开发和使用所公开的用于载片制备、处理和复查的自动优先级化过程的实施例,如下文进一步详细描述的。
40.图1a示出了根据本公开的示例性实施例的用于使用机器学习来提供用于制备、处理和复查组织样本的载片的图像的自动优先级化过程的系统和网络的框图。
41.具体讲,图1a示出了可以连接到医院、实验室和/或医生办公室等处的服务器的电子网络120。例如,医师服务器121、医院服务器122、临床试验服务器123、研究实验室服务器124和/或实验室信息系统125等可以各自通过一个或多个计算机、服务器和/或手持移动设备连接到例如因特网的电子网络120。根据本技术的一个示例性实施例,电子网络120还可以连接到服务器系统110,其可以包括被配置为实现疾病检测平台100的处理设备,该疾病检测平台包括根据本公开的一个示例性实施例的用于提供用于制备、处理和复查组织样本的载片的图像的自动优先级化过程的载片优先级化工具101。
42.医师服务器121、医院服务器122、临床试验服务器123、研究实验室服务器124和/或实验室信息系统125可以创建或以其他方式获得一个或多个患者的细胞学样本、组织病理学样本、细胞学样本载片的图像、组织病理学样本载片的数字化图像或其任何组合。医师服务器121、医院服务器122、临床试验服务器123、研究实验室服务器124和/或实验室信息系统125还可以获得患者特定信息的任何组合,所述患者特定信息是例如年龄、病史、癌症治疗史、家族史、过去的活检或细胞学信息等。医师服务器121、医院服务器122、临床试验服务器123、研究实验室服务器124和/或实验室信息系统(lis)125可以通过电子网络120将数字化的载片图像和/或患者特定信息传输到服务器系统110中。服务器系统110可以包括一个或多个存储设备109,其用于存储从医师服务器121、医院服务器122、临床试验服务器123、研究实验室服务器124和/或实验室信息系统125中的至少一个接收的图像和数据。服务器系统110还可以包括用于处理存储在存储设备109中的图像和数据的处理设备。服务器
系统110还可以包括一种或多种机器学习工具或能力。例如,根据一个实施例,处理设备可以包括用于疾病检测平台100的机器学习工具。作为替选或补充,本公开(或本公开的系统和方法的部分)可以在本地处理设备(例如,膝上型计算机)上执行。
43.医师服务器121、医院服务器122、临床试验服务器123、研究实验室服务器124和/或lis 125是指由病理学家用于检查载片图像的系统。在医院环境中,组织类型信息可以存储在lis 125中。根据本公开的一个示例性实施例,可以在不需要访问lis 125的情况下自动对载片进行优先级化。例如,可以在没有存储在lis中的对应样本类型标签的情况下向第三方开放对图像内容的匿名访问。另外,对lis内容的访问可能会由于其敏感内容而受到限制。
44.图1b示出了疾病检测平台100的示例性框图,该疾病检测平台100用于使用机器学习来提供用于制备、处理和复查组织样本的载片的图像的自动优先级化过程。
45.具体讲,图1b描绘了根据一个实施例的疾病检测平台100的组件。例如,疾病检测平台100可以包括载片优先级化工具101、数据摄取工具102、载片摄取工具103、载片扫描仪104、载片管理器105、存储器106和查看应用工具108。
46.如下所述,根据一个示例性实施例,载片优先级化工具101是指用于提供用于制备、处理和复查组织样本的载片的图像的自动优先级化过程的过程和系统。
47.根据一个示例性实施例,数据摄取工具102指的是有利于数字病理图像传输到用于分类和处理数字病理图像的各种工具、模块、组件和设备的过程和系统。
48.根据一个示例性实施例,载片摄取工具103指的是用于扫描病理图像并将其转换为数字形式的过程和系统。可以用载片扫描器104来扫描载片,并且载片管理器105可以将载片上的图像处理成数字化病理图像,并将该数字化图像存储在存储器106中。
49.根据一个示例性实施例,查看应用工具108是指用于向用户(例如,病理学家)提供与数字病理图像有关的样本属性或图像属性信息的过程和系统。可以通过各种输出接口(例如,屏幕、监视器、存储设备和/或web浏览器等)来提供信息。
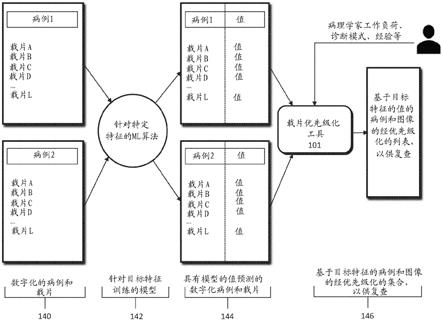
50.载片优先级化工具101及其每个组件可以通过网络120针对服务器系统110、医师服务器121、医院服务器122、临床试验服务器123、研究实验室服务器124和/或实验室信息系统125发送和/或接收数字化载片图像和/或患者信息。此外,服务器系统110可以包括用于存储从载片优先级化工具101、数据摄取工具102、载片摄取工具103、载片扫描器104、载片管理器105和查看应用工具108中的至少一个接收到的图像和数据的存储设备。服务器系统110还可以包括用于处理存储在存储设备中的图像和数据的处理设备。服务器系统110还可以包括由例如处理设备而提供的一种或多种机器学习工具或能力。作为替选或补充,本公开(或本公开的系统和方法的部分)也可以在本地处理设备(例如,膝上型计算机)上执行。
51.上述设备、工具和模块中的任何一个可以位于通过一个或多个计算机、服务器和/或手持移动设备连接到诸如因特网或云服务提供商之类的电子网络120的设备上。
52.图1c示出根据本发明的一个示例性实施例的载片优先级化工具101的一个示例性框图。载片优先级化工具101可以包括训练图像平台131和/或目标图像平台135。
53.训练图像平台131可以包括训练图像摄取模块132、标签处理模块133和/或优先级排序模块134。
54.训练图像平台131可以创建或接收训练图像,其用于训练机器学习模型和/或系统以高效地分析和分类数字病理图像。例如,可以从服务器系统110、医师服务器121、医院服务器122、临床试验服务器123、研究实验室服务器124和/或实验室信息系统125中的任何一个或任何组合接收训练图像。用于训练的图像可以来自真实源(例如,人、动物等)或者可以来自合成源(例如,图形渲染引擎、3d模型等)。数字病理图像的示例可以包括(a)用各种染色剂染色的数字化载片,例如(但不限于)h&e、单独的苏木精、ihc、分子病理学等;和/或(b)来自3d成像设备(例如microct)的数字化组织采样。
55.训练图像摄取模块132可以创建或接收数据集,其包括与人类组织的图像和/或经图形渲染的图像相对应的一个或多个训练图像。例如,可以从服务器系统110、医师服务器121、医院服务器122、临床试验服务器123、研究实验室服务器124和/或实验室信息系统125中的任何一个或任何组合接收训练图像。该数据集可以保存在数字存储设备上。标签处理模块133可以针对每个训练图像确定标签,所述标签表征载片形态、诊断值、病理学家复查结果和/或分析难度中的至少一个。优先级排序模块134可以处理组织的图像,并为每个训练图像确定预测的优先级排序。
56.根据一个实施例,目标图像平台135可以包括目标图像摄取模块136、优先级值模块137和输出接口138。目标图像平台135可以接收目标图像并且将机器学习模型应用于目标图像以计算目标图像的优先级值。例如,可以从服务器系统110、医师服务器121、医院服务器122、临床试验服务器123、研究实验室服务器124和/或实验室信息系统125中的任何一个或任何组合接收目标图像。目标图像摄取模块136可以接收对应于目标样本的目标图像。优先级值模块137可以将机器学习模型应用于目标图像以计算目标图像的优先级值。
57.输出接口138可以用于输出关于目标图像和目标样本的信息。(例如,输出到屏幕、监视器、存储设备、web浏览器等)。
58.图1d描绘了用于在数字病理工作流程中对载片进行优先级化的示例性系统和工作流程的示意图。在该工作流程中,机器学习模型142可以接收数字化的病例和载片140作为输入。数字化的病例和载片140可以包括患者病理载片的图像和/或关于患者特点、治疗史、患者背景、载片数据等的电子数据。患者特点可以包括患者的年龄、身高、体重、家族病史、过敏反应等。治疗史可以包括对患者进行的测试、对患者进行的既往手术、患者的辐射暴露等。病例背景可以是指病例/载片是否是临床研究、实验性治疗、随访报告等的一部分。载片数据可以包括进行的染色、组织切片的位置、制作载片的时间/日期、制作载片的实验室等。
59.可以使用数字化的病例和载片140来训练机器学习模型142。经训练的机器学习模型142可以输出一个或多个优先级值预测144。例如,经训练的机器学习模型142可以为所选数字化病例/载片生成优先级值144。所选数字化病例/载片可以是新的或另外的病例/载片,未包括在输入的数字化病例和载片140中。替换地,机器学习模型142还可以用于输出作为数字化的病例和载片140的一部分的所选数字化病例/载片的优先级值。
60.可以基于所生成的优先级值144来生成优先级顺序146。例如,可以由机器学习模型142针对一组病例/载片中的每个病例/载片输出优先级值144。然后,优先级顺序146可以包括供病理学家复查的病例列表或一览表,其中基于每个病例的优先级值144按顺序列出病例。通过对病例进行优先级化,病理学家可以对其病例进行分类,并首先复查更紧迫或更
优先的病例。在一些情况下,可以在病理学家复查之前调整优先级顺序146。例如,如果一个病例已经在队列中超过一定的时间量,或者如果接收到关于该病例的另外信息,则该病例的优先级值144可以增加。下面进一步详细描述图1d的方法。
61.图2是示出根据本公开的示例性实施例的用于处理对应于样本的载片的图像并自动对载片处理进行优先级化的工具的示例性方法的流程图。例如,示例性方法200(例如,步骤202至206)可由载片优先级化工具101自动地或响应于来自用户(例如,医师、病理学家等)的请求来执行。
62.根据一个实施例,用于自动对载片处理进行优先级化的示例性方法200可以包括以下步骤中的一个或多个。在步骤202中,该方法可以包括接收对应于目标样本的载片的目标图像,目标样本包括患者的组织采样。例如,可以从服务器系统110、医师服务器121、医院服务器122、临床试验服务器123、研究实验室服务器124和/或实验室信息系统125中的任何一个或其任何组合接收目标图像。
63.在步骤204中,该方法可以包括使用机器学习模型计算目标图像的优先级值,机器学习模型是通过处理多个训练图像而生成的,每个训练图像包括人体组织的图像和表征载片形态、诊断值、病理学家复查结果和/或分析难度中的至少一个的标签。标签可以包括对应于要对目标图像进行进一步制备的可能性的制备值。可基于样本重切、免疫组织化学染色、额外诊断测试、额外磋商和/或特殊染色中的至少一种对目标图像进行进一步制备。标签可以包括目标图像的诊断特征,诊断特征包括癌症存在、癌症等级、治疗效果、癌前病变和/或感染性生物体的存在中的至少一个。目标图像的优先级值可以包括针对第一用户的目标图像的第一优先级值和针对第二用户的目标图像的第二优先级值,第一优先级值可以基于第一用户的偏好来确定,并且第二优先级值可以基于第二用户的偏好来确定。标签可以包括对应于扫描线、缺失组织和/或模糊中的至少一个的伪影标签。
64.可以从服务器系统110、医师服务器121、医院服务器122、临床试验服务器123、研究实验室服务器124和/或实验室信息系统125中的任何一个或其任何组合接收训练图像。该数据集可以保存在数字存储设备上。用于训练的图像可以来自真实源(例如,人、动物等)或者可以来自合成源(例如,图形渲染引擎、3d模型等)。数字病理图像的示例可以包括(a)用各种染色剂染色的数字化载片,例如(但不限于)h&e、单独的苏木精、ihc、分子病理学等;和/或(b)来自3d成像设备(例如microct)的数字化组织采样。
65.在步骤206中,该方法可以包括输出数字化病理图像的序列,并且基于目标图像的优先级值将目标图像放置在该序列中。
66.用于实现机器学习算法和/或架构的不同方法可以包括但不限于(1)cnn(卷积神经网络);(2)mil(多实例学习);(3)rnn(递归神经网络);(4)通过cnn进行特征聚合;和/或(5)特征提取然后是集成方法(例如,随机森林)、线性/非线性分类器(例如,svm(支持向量机)、mlp(多层感知器)和/或降维技术(例如,pca(主成分分析)、lda(线性判别分析)等)。示例特征可以包括来自cnn的向量嵌入、来自cnn的单类/多类输出、和/或来自cnn的多维输出(例如,原始图像的掩模覆盖)。cnn可以直接从像素学习分类任务的特征表示,这可以得到更好的诊断性能。当区域的详细注释或逐像素标签可用时,如果有大量加标签的数据,则可以直接对cnn进行训练。然而,当标签仅在整个载片水平或在一组载片的集合上(在病理学中可称为“部分”)时,mil可用于训练cnn或另一神经网络分类器,其中mil学习对于分类任
务而言是诊断性的图像区域,从而得到在没有穷尽注释的情况下学习的能力。可以对从多个图像区域(例如,图块)提取的特征使用rnn,然后对其进行处理以进行预测。其他机器学习方法,例如,随机森林、svm和许多其他方法,可以与由cnn、具有mil的cnn学习的特征一起使用,或者使用手工制作的图像特征(例如,sift或surf)来执行分类任务,但是当直接从像素训练时,它们可能表现不佳。当有大量带注释的训练数据可用时,与基于cnn的系统相比,这些方法可能表现不佳。在使用上述任何分类器之前,可以将降维技术用作预处理步骤,这在可用数据很少的情况下非常有用。
67.根据一个或多个实施例,任何上述算法、架构、方法、属性和/或特征可以与任何或所有其他算法、架构、方法、属性和/或特征相结合。例如,任何机器学习算法和/或架构(例如,神经网络方法、卷积神经网络(cnn)、递归神经网络(rnn)等可以用任何训练方法(例如,多实例学习、强化学习、主动学习等)进行训练。
68.下面对术语的描述仅仅是示例性的,并不打算以任何方式限制这些术语。
69.标签可以指的是关于算法试图预测的机器学习算法的输入的信息。
70.对于大小为nxm的给定图像,分割可以是另一个大小为nxm的图像,针对原始图像中的每个像素分配描述该像素的类别或类型的数字。例如,在wsi中,掩模中的元素可以将输入图像中的每个像素分类为属于例如背景、组织和/或未知的类别。
71.载片级别信息可以是指关于载片的一般信息,但不一定是该信息在载片中的特定位置。
72.启发式可以是指在给定输入的情况下确定性地产生输出的逻辑规则或函数。例如,如果某个载片优先于另一载片的预测大于或等于32%,则输出1,否则输出0。
73.嵌入可以是指低维数据的概念性高维数值表示。例如,如果wsi通过cnn训练,以对组织类型进行分类,则网络最后一层上的数字可提供包含关于载片的信息(例如,关于组织类型的信息)的数字阵列(例如,以千计)。
74.载片级别预测可以指对整个载片的具体预测。例如,载片级别预测可能是该载片应优先于另一载片。此外,载片级别预测可以指在一组定义的类别上的个别概率预测。
75.分类器可以是指被训练为获取输入数据并将其与类别进行关联的模型。
76.根据一个或多个实施例,可以以不同的方式训练机器学习模型。例如,机器学习模型的训练可以通过监督训练、半监督训练、无监督训练分类器训练、混合训练和/或不确定性估计中的任何一种或其任何组合来执行。使用的训练类型可取决于数据量、数据类型和/或数据质量。下面的表1描述了一些训练类型和相应特征的非限制性列表。表1
77.监督训练可以与少量数据一起使用,以为机器学习模型提供种子。在监督训练中,机器学习模型可以寻找特定项(例如,气泡、组织褶皱等)、标记载片、并量化载片中有多少特定项。
78.根据一个实施例,示例完全监督训练可以采用wsi作为输入,并且可以包括分割标签。完全监督训练的流水线可以包括(1)1;(2)1,启发式;(3)1,4,启发式;(4)1,4,5,启发式;和/或(5)1,5,启发式。完全监督训练的优点可以是:(1)它可需要更少的载片和/或(2)输出是可解释的,因为(a)可知道图像的哪些区域有助于诊断;和(b)可知道为什么一载片优先于另一载片(例如,诊断值、分析难度等)。使用完全监督训练的缺点可以是,它可能需要大量的分割,这可能很难获得。
79.根据一个实施例,示例性半监督(例如,弱监督)训练可以采用wsi作为输入,并且可以包括载片级别信息的标签。半监督训练的流水线可以包括(1)2;(2)2,启发式;(3)2,4,启发式;(4)2,4,5,启发式;和/或(5)2,5,启发式。使用半监督训练的优点可以是:(1)所需标签的类型可存在于许多医院记录中;以及(2)输出是可解释的,因为(a)可知道图像的哪些区域对诊断贡献最大;和(b)可知道为什么一载片优先于另一载片(例如,诊断值、分析难度等)。使用半监督训练的缺点是训练可能比较困难。例如,模型可能需要使用训练方案,如多实例学习、主动学习和/或分布式训练,以虑及以下事实:关于该信息在载片中的位置的应得出决策的信息有限。
80.根据一个实施例,示例性无监督训练可以采用wsi作为输入,并且可以不需要标签。用于无监督训练的流水线可以包括(1)3,4;和/或(2)3,4,启发式。无监督训练的优点可以是它不需要任何标签。使用无监督训练的缺点可以是:(1)训练可能比较困难;例如,可能需要使用多实例学习、主动学习和/或分布式训练等训练方案来虑及以下事实:关于该信息在载片中的位置的应得出决策的信息有限;(2)可能需要额外的载片;和/或(3)它可能不太可解释,因为它可能输出预测和概率而不解释为什么进行该预测。
81.根据一个实施例,示例混合训练可以包括训练针对完全监督训练、半监督训练和/或无监督训练的上述示例流水线中的任何,然后将所得模型用作任何训练方法的初始点。混合训练的优点可以是:(1)它可需要较少的数据;(2)它可具有改进的性能;和/或(3)它可允许不同级别的标签的混合(例如,分段、载片级别信息、无信息)。混合训练的缺点可以是:(1)训练可能更复杂和/或更昂贵;和/或(2)它可需要更多的代码,这可能增加潜在错误的数量和复杂度。
82.根据一个实施例,示例性不确定性估计可以包括训练针对完全监督训练、半监督
训练和/或无监督训练的上述示例流水线中的任何,在流水线末端针对与载片数据相关的任何任务使用不确定性估计,此外,启发式或分类器可用于基于测试预测中的不确定性的量来预测一载片是否应优先于另一载片。不确定性估计的优点可以是它对分布外数据是稳健的。例如,当出现不熟悉的数据时,它仍然可以正确地预测它是不确定的。不确定性估计的缺点可以是:(1)它可需要更多的数据;(2)整体性能可能较差;和/或(3)它可能不太可解释,因为模型可能不一定识别载片或载片嵌入是如何异常的。
83.根据一个实施例,集成训练可以包括同时运行由上述任何示例流水线产生的模型,并且通过启发式或分类器组合输出以产生鲁棒且准确的结果。集成训练的优点可以是:(1)它对分布外的数据是稳健的;和/或(2)它可组合其他模型的优点和缺点,导致缺点的最小化(例如,与不确定性估计模型组合的监督训练模型,以及当传入数据在分布中时使用监督模型而当数据在分布外时使用不确定性模型的启发式算法等)。集成训练的缺点可以是:(1)它可能更复杂;和/或(2)训练和运行可能是昂贵的。
84.本文讨论的训练技术也可以分阶段进行,其中具有较好注释的图像最初用于训练,这可以允许使用具有较少注释、较少监督等的载片进行更高效的后续训练。
85.相对于可使用的所有训练载片图像,训练可以始于使用注释最完备的载片。例如,训练可以始于使用监督学习。第一组载片图像可以被接收或确定有相关联的注释。每个载片可具有标记和/或掩蔽的区域,并且可以包括诸如该载片是否应优先于另一载片之类的信息。第一组载片可以被提供给训练算法,例如cnn,其可以确定第一组载片与其相关联注释之间的相关性。
86.在用第一组图像的训练完成之后,可以接收或确定具有比第一组更少的注释的第二组载片图像,例如具有部分注释。在一个实施例中,注释可仅指示载片具有与其相关联的诊断或质量问题,但可不指明可发现什么或在何处发现疾病等。第二组载片图像可以使用与第一组不同的训练算法来训练,例如多实例学习。第一组训练数据可用于部分训练系统,并可使第二轮训练更高效地产生准确的算法。
87.以这种方式,基于训练载片图像的质量和类型,可以使用任何数量的算法以任何数量的阶段进行训练。这些技术可以在接收到多个训练图像集的情况下使用,这些训练图像集可以具有不同的质量、注释级别和/或注释类型。
88.图3示出了用于确定分析多个病理载片的顺序的示例性方法。例如,示例性方法300和320(例如,步骤301-325)可以由载片优先级化工具101自动地或响应于来自用户(例如,医师、病理学家等)的请求来执行。
89.根据一个实施例,用于确定分析多个病理载片的顺序的示例性方法300可以包括以下步骤中的一个或多个。在步骤301中,该方法可以包括创建跨癌症亚型和组织样本(例如,组织学、细胞学、血液学、微ct等)的一个或多个数字化病理图像的数据集。在步骤303中,该方法可以包括接收或确定针对数据集中的每个病理图像的一个或多个标签(例如,载片形态、诊断、结果、难度等)。在步骤305中,该方法可以包括将每个图像及其对应的标签存储在数字存储设备(例如,硬盘、网络驱动器、云存储、ram等)中。
90.在步骤307中,该方法可以包括训练基于计算病理学的机器学习算法,该基于计算病理学的机器学习算法采用病理样本的一个或多个数字图像作为输入,并预测每个数字图像的优先级排序。实现机器学习算法的不同方法可以包括但不限于:(1)cnn(卷积神经网
络);(2)mil(多实例学习);(3)rnn(递归神经网络);(4)通过cnn进行特征聚合;和/或(5)特征提取然后是集成方法(例如,随机森林)、线性/非线性分类器(例如,svm、mlp和/或降维技术(例如,pca、lda等)。示例特征可以包括来自cnn的向量嵌入、来自cnn的单类/多类输出、和/或来自cnn的多维输出(例如,原始图像的掩模覆盖)。cnn可以直接从像素学习分类任务的特征表示,这可以得到更好的诊断性能。当区域的详细注释或逐像素标签可用时,如果有大量加标签的数据,则可以直接对cnn进行训练。然而,当标签仅在整个载片水平或在一组载片的集合上(在病理学中可称为“部分”)时,mil可用于训练cnn或另一神经网络分类器,其中mil学习对于分类任务而言是诊断性的图像区域,从而得到在没有穷尽注释的情况下学习的能力。可以对从多个图像区域(例如,图块)提取的特征使用rnn,然后对其进行处理以进行预测。其他机器学习方法,例如,随机森林、svm和许多其他方法,可以与由cnn、具有mil的cnn学习的特征一起使用,或者使用手工制作的图像特征(例如,sift或surf)来执行分类任务,但是当直接从像素训练时,它们可能表现不佳。当有大量带注释的训练数据可用时,与基于cnn的系统相比,这些方法有可能表现不佳。在使用上述任何分类器之前,可以将降维技术用作预处理步骤,这在可用数据很少的情况下非常有用。
91.针对图2的机器学习算法的上述描述(例如,表1和相应描述)也可以应用于图3的机器学习算法。
92.使用载片优先级化工具的示例性方法320可以包括以下一个或多个步骤。在步骤321中,该方法可以包括接收对应于用户的数字病理图像。在步骤323中,该方法可以包括确定与接收的数字病理图像相关联的载片和/或病例的排序顺序(rank order)或统计量。可以通过将经训练的计算病理学机器学习算法(例如,方法300的算法)应用于接收到的图像来确定排序顺序或统计量。排序顺序或统计量可用于针对与接收的图像相关联的载片或与接收的图像相关联的病例的复查或额外载片制备进行优先级化。
93.在步骤325中,该方法可以包括输出排序顺序或统计量。一个输出可以包括基于偏好、启发式、统计量、用户的目标(例如,效率、难度、紧迫性等)按顺序确定和/或显示一个或多个变化。替换地或附加地,输出可以包括基于所生成的顺序在病例级别对接收的图像进行视觉排序。例如,这种视觉排序可以包括显示,该显示包括基于目标特征的最大或最小载片概率、基于目标特征跨所有载片的平均概率、基于示出目标特征的原始载片数量等排序的病例排序。又一输出可以包括基于所生成的顺序在每个病例内在载片级别或组织块级别上的排序的可视化。视觉排序可以由用户和/或通过计算来执行。
94.上述载片优先级化工具可以包括可用于研究和/或生产/临床/工业场景的特定应用或实施例。这些实施例可以出现在开发和使用的不同阶段。工具可以采用下面的一个或多个实施例。
95.根据一个实施例,优先级化可以基于质量控制。质量控制问题可能会影响病理学家做出诊断的能力。换言之,质量控制问题可能会增加病例的周转时间。例如,制备不充分的扫描载片可能在发现质量控制问题之前被发送到病理学家的队列中。根据一个实施例,通过在载片到达病理学家的队列之前识别质量控制问题,可以缩短周转时间,因此节省了病理诊断工作流程中的时间。例如,本实施例可以识别和分类具有质量控制问题的病例/载片,并在载片到达病理学家之前将问题通知实验室和扫描技术人员。工作流程中的早期质量控制截获可以提高效率。
96.图4示出了用于开发质量控制优先级化工具的示例性方法。例如,示例性方法400和420(例如,步骤401-425)可以由载片优先级化工具101自动地或响应于来自用户(例如,医师、病理学家等)的请求来执行。
97.根据一个实施例,用于开发质量控制优先级化工具的示例性方法400可以包括以下步骤中的一个或多个。在步骤401中,该方法可以包括创建跨癌症亚型和组织样本(例如,组织学、细胞学、血液学、微ct等)的数字化病理图像的数据集。在步骤403中,该方法可以包括接收或确定针对数据集中的每个病理图像的一个或多个标签(例如,载片形态、诊断、结果、难度等)。另外的示例性标签可以包括但不限于扫描伪影(例如,扫描线、缺失组织、模糊等)和载片制备伪影(例如,褶皱的组织、染色不良、损坏的载片、标记等)。在步骤405中,该方法可以包括将每个图像及其对应的标签存储在数字存储设备(例如,硬盘、网络驱动器、云存储、ram等)中。
98.在步骤407中,该方法可以包括训练基于计算病理学的机器学习算法,该基于计算病理学的机器学习算法采用病理样本的一个或多个数字图像作为输入,并预测每个数字图像的优先级排序。实现机器学习算法的不同方法可以包括但不限于:(1)cnn(卷积神经网络);(2)mil(多实例学习);(3)rnn(递归神经网络);(4)通过cnn进行特征聚合;和/或(5)特征提取然后是集成方法(例如,随机森林)、线性/非线性分类器(例如,svm、mlp和/或降维技术(例如,pca、lda等)。示例特征可以包括来自cnn的向量嵌入、来自cnn的单类/多类输出、和/或来自cnn的多维输出(例如,原始图像的掩模覆盖)。cnn可以直接从像素学习分类任务的特征表示,这可以得到更好的诊断性能。当区域的详细注释或逐像素标签可用时,如果有大量加标签的数据,则可以直接对cnn进行训练。然而,当标签仅在整个载片水平或在一组载片的集合上(在病理学中可称为“部分”)时,mil可用于训练cnn或另一神经网络分类器,其中mil学习对于分类任务而言是诊断性的图像区域,从而得到在没有穷尽注释的情况下学习的能力。可以对从多个图像区域(例如,图块)提取的特征使用rnn,然后对其进行处理以进行预测。其他机器学习方法,例如,随机森林、svm和许多其他方法,可以与由cnn、具有mil的cnn学习的特征一起使用,或者使用手工制作的图像特征(例如,sift或surf)来执行分类任务,但是当直接从像素训练时,它们可能表现不佳。当有大量带注释的训练数据可用时,与基于cnn的系统相比,这些方法有可能表现不佳。在使用上述任何分类器之前,可以将降维技术用作预处理步骤,这在可用数据很少的情况下非常有用。
99.针对图2的机器学习算法的上述描述(例如,表1和相应描述)也可以应用于图4的机器学习算法。
100.使用质量控制优先级化工具的示例性方法420可以包括以下一个或多个步骤。在步骤421中,该方法可以包括接收对应于用户的数字病理图像。在步骤423中,该方法可以包括确定与接收的数字病理图像相关联的载片和/或病例的排序顺序或统计量。可以通过将经训练的计算病理学机器学习算法(例如,方法400的算法)应用于接收到的图像来确定排序顺序或统计量。排序顺序或统计量可用于针对与接收的图像相关联的载片或与接收的图像相关联的病例的复查或额外载片制备进行优先级化。
101.在步骤425中,该方法可以包括输出排序顺序或统计量。一个输出可以包括基于偏好、启发式、统计量、用户的目标(例如,效率、难度、紧迫性等)按顺序确定和/或显示一个或多个变化。替换地或附加地,输出可以包括基于所生成的顺序在病例级别对接收的图像进
行视觉排序。例如,这种视觉排序可以包括显示,该显示包括基于目标特征的最大或最小载片概率、基于目标特征跨所有载片的平均概率、基于示出目标特征的原始载片数量等排序的病例排序。另一输出可以包括基于所生成的顺序在每个病例内在载片级别或组织块级别上的排序的可视化。视觉排序可以由用户和/或通过计算来执行。又一输出可以包括特定质量控制问题的标识和/或解决所标识的质量控制问题的警报。例如,可以为每个载片计算质量控制指标。质量控制指标可以表示质量控制问题的存在和/或严重性。警报可传送给特定人员。例如,该步骤可以包括识别与所标识的质量控制问题相关联的人员,并为所识别的人员生成警报。警报的另一方面可以包括辨别质量控制问题是否影响做出诊断的步骤。在一些实施例中,可以仅当所标识的质量控制问题影响做出诊断时才生成或提示警报。例如,可以仅当与质量控制问题相关联的质量控制指标超过预定的质量控制指标阈值时才生成警报。
102.根据一个实施例,可以设计优先级化以提高效率。目前,大多数机构和实验室对每名病理学家都有标准化的周转时间预期。该时间可以从获取病理样本到主病理学家签字认可之间的时间来测量。实际上,在做出最终诊断之前,病理学家可能会针对某些病例命令额外的染色或重切以获取更多信息。在某些病理学亚种中,额外的染色或重切命令可能更多。额外的命令可能会增加周转时间,从而影响患者。当前实施例可以对这些类型的亚特异性病例进行优先级化以供复查,例如,使得可以在病理学家复查之前命令额外的染色或重切,或者使得病理学家可以更快地复查这样的载片并更快地命令额外的染色或重切。这种优先级化可以缩短周转时间并提高载片复查的效率。
103.图5示出了用于开发效率优先级化工具的示例性方法。例如,示例性方法500和520(例如,步骤501-525)可以由载片优先级化工具101自动地或响应于来自用户(例如,医师、病理学家等)的请求来执行。
104.根据一个实施例,用于开发效率优先级化工具的示例性方法500可以包括以下步骤中的一个或多个。在步骤501中,该方法可以包括创建跨癌症亚型和组织样本(例如,组织学、细胞学、血液学、微ct等)的数字化病理图像的数据集。在步骤503中,该方法可以包括接收或确定针对数据集中的每个病理图像的一个或多个标签(例如,载片形态、诊断、结果、难度等)。另外的示例性标签可以包括但不限于以下载片制备标签:(1)很可能需要样本重切;(2)很可能需要免疫组织化学染色;(3)很可能需要另外的诊断测试(例如,基因测试);(4)很可能需要补充意见(磋商);和/或(5)很可能需要特殊染色。
105.在步骤505中,该方法可以包括将每个图像及其对应的标签存储在数字存储设备(例如,硬盘、网络驱动器、云存储、ram等)中。在步骤507中,该方法可以包括训练基于计算病理学的机器学习算法,该基于计算病理学的机器学习算法采用病理样本的一个或多个数字图像作为输入,然后预测每个数字图像的优先级排序。实现机器学习算法的不同方法可以包括但不限于:(1)cnn(卷积神经网络);(2)mil(多实例学习);(3)rnn(递归神经网络);(4)通过cnn进行特征聚合;和/或(5)特征提取然后是集成方法(例如,随机森林)、线性/非线性分类器(例如,svm、mlp和/或降维技术(例如,pca、lda等)。示例特征可以包括来自cnn的向量嵌入、来自cnn的单类/多类输出、和/或来自cnn的多维输出(例如,原始图像的掩模覆盖)。cnn可以直接从像素学习分类任务的特征表示,这可以得到更好的诊断性能。当区域的详细注释或逐像素标签可用时,如果有大量加标签的数据,则可以直接对cnn进行训练。
然而,当标签仅在整个载片水平或在一组载片的集合上(在病理学中可称为“部分”)时,mil可用于训练cnn或另一神经网络分类器,其中mil学习对于分类任务而言是诊断性的图像区域,从而得到在没有穷尽注释的情况下学习的能力。可以对从多个图像区域(例如,图块)提取的特征使用rnn,然后对其进行处理以进行预测。其他机器学习方法,例如,随机森林、svm和许多其他方法,可以与由cnn、具有mil的cnn学习的特征一起使用,或者使用手工制作的图像特征(例如,sift或surf)来执行分类任务,但是当直接从像素训练时,它们可能表现不佳。当有大量带注释的训练数据可用时,与基于cnn的系统相比,这些方法有可能表现不佳。在使用上述任何分类器之前,可以将降维技术用作预处理步骤,这在可用数据很少的情况下非常有用。
106.针对图2的机器学习算法的上述描述(例如,表1和相应描述)也可以应用于图5的机器学习算法。
107.使用效率优先级化工具的示例性方法520可以包括以下一个或多个步骤。在步骤521中,该方法可以包括接收对应于用户的数字病理图像。在步骤523中,该方法可以包括确定与接收的数字病理图像相关联的载片和/或病例的排序顺序或统计量。可以通过将经训练的计算病理学机器学习算法(例如,方法500的算法)应用于接收到的图像来确定排序顺序或统计量。排序顺序或统计量可用于针对与接收的图像相关联的载片或与接收的图像相关联的病例的复查或额外载片制备进行优先级化。
108.在步骤525中,该方法可以包括输出排序顺序或统计量。一个输出可以包括基于偏好、启发式、统计量、用户的目标(例如,效率、难度、紧迫性等)按顺序确定和/或显示一个或多个变化。替换地或附加地,输出可以包括基于所生成的顺序在病例级别对接收的图像进行视觉排序。例如,这种视觉排序可以包括显示,该显示包括基于目标特征的最大或最小载片概率、基于目标特征跨所有载片的平均概率、基于示出目标特征的原始载片数量等排序的病例排序。视觉排序可以由用户和/或通过计算来执行。另一输出可以包括基于所生成的顺序在每个病例内在载片级别或块级别上的排序的可视化。又一输出可以包括染色或重切位置建议。又一输出可以包括生成预测染色命令、重切命令、测试或磋商命令的“预命令”或命令。
109.根据一个实施例,载片优先级化可以基于诊断特征。病理学家可能有不同的年数、不同的经验类型以及不同的资源获取水平。例如,一般病理学家可能会复查各种诊断不同的样本类型。随着病例量的增加和新病理学家的减少,执业病理学家可能面临复查大量不同病例的压力。以下实施例可以包括特征识别,以帮助病理学家对病例/载片进行分类。特征识别可以包括对其中图像特征可能原本被遗漏或忽视的数字化病理载片/病例图像中的图像特征的视觉辅助。
110.图6示出了用于开发诊断特征优先级化工具的示例性方法。例如,示例性方法600和620(例如,步骤601-625)可以由载片优先级化工具101自动地或响应于来自用户(例如,医师、病理学家等)的请求来执行。
111.根据一个实施例,用于开发诊断特征优先级化工具的示例性方法600可以包括以下步骤中的一个或多个。在步骤601中,该方法可以包括创建跨癌症亚型和组织样本(例如,组织学、细胞学、血液学、微ct等)的数字化病理图像的数据集。在步骤603中,该方法可以包括针对数据集中的每个病理图像的一个或多个标签(例如,载片形态、诊断、结果、难度等)。
另外的示例性诊断特征标签可以包括但不限于癌症存在、癌症等级、癌症接近手术边缘、治疗效果、癌前病变以及指示存在感染性生物体(例如,病毒、真菌、细菌、寄生虫等)的特征。在步骤605中,该方法可以包括将每个图像及其对应的标签存储在数字存储设备(例如,硬盘、网络驱动器、云存储、ram等)中。
112.在步骤607中,该方法可以包括训练基于计算病理学的机器学习算法,该基于计算病理学的机器学习算法采用病理样本的一个或多个数字图像作为输入,然后预测每个数字图像的优先级排序。实现机器学习算法的不同方法可以包括但不限于:(1)cnn(卷积神经网络);(2)mil(多实例学习);(3)rnn(递归神经网络);(4)通过cnn进行特征聚合;和/或(5)特征提取然后是集成方法(例如,随机森林)、线性/非线性分类器(例如,svm、mlp和/或降维技术(例如,pca、lda等)。示例特征可以包括来自cnn的向量嵌入、来自cnn的单类/多类输出、和/或来自cnn的多维输出(例如,原始图像的掩模覆盖)。cnn可以直接从像素学习分类任务的特征表示,这可以得到更好的诊断性能。当区域的详细注释或逐像素标签可用时,如果有大量加标签的数据,则可以直接对cnn进行训练。然而,当标签仅在整个载片水平或在一组载片的集合上(在病理学中可称为“部分”)时,mil可用于训练cnn或另一神经网络分类器,其中mil学习对于分类任务而言是诊断性的图像区域,从而得到在没有穷尽注释的情况下学习的能力。可以对从多个图像区域(例如,图块)提取的特征使用rnn,然后对其进行处理以进行预测。其他机器学习方法,例如,随机森林、svm和许多其他方法,可以与由cnn、具有mil的cnn学习的特征一起使用,或者使用手工制作的图像特征(例如,sift或surf)来执行分类任务,但是当直接从像素训练时,它们可能表现不佳。当有大量带注释的训练数据可用时,与基于cnn的系统相比,这些方法有可能表现不佳。在使用上述任何分类器之前,可以将降维技术用作预处理步骤,这在可用数据很少的情况下非常有用。
113.针对图2的机器学习算法的上述描述(例如,表1和相应描述)也可以应用于图6的机器学习算法。
114.使用诊断特征优先级化工具的示例性方法620可以包括以下一个或多个步骤。在步骤621中,该方法可以包括接收对应于用户的数字病理图像。在步骤623中,该方法可以包括确定与接收的数字病理图像相关联的载片和/或病例的排序顺序或统计量。可以通过将经训练的计算病理学机器学习算法(例如,方法600的算法)应用于接收到的图像来确定排序顺序或统计量。排序顺序或统计量可用于针对与接收的图像相关联的载片或与接收的图像相关联的病例的复查或额外载片制备进行优先级化。在该情况下,排序顺序或统计量可以包括与在数字病理图像中检测到的诊断特征相关联的统计量。
115.在步骤625中,该方法可以包括输出排序顺序或统计量。一个输出可以包括基于偏好、启发式、统计量、用户的目标(例如,效率、难度、紧迫性等)按顺序确定和/或显示一个或多个变化。替换地或附加地,输出可以包括基于所生成的顺序在病例级别对接收的图像进行视觉排序。例如,这种视觉排序可以包括显示,该显示包括基于目标特征的最大或最小载片概率、基于目标特征跨所有载片的平均概率、基于示出目标特征的原始载片数量等排序的病例排序。视觉排序可以由用户和/或通过计算来执行。另一输出可以包括基于所生成的顺序在每个病例内在载片级别或块级别上的排序的可视化。又一输出可以包括针对一个或多个所识别的诊断特征的列表、视觉指示或警报。一个实施例可以包括选项或菜单界面,供用户选择诊断特征中的一个(或任何组合)以用于复查的优先级化。
116.根据一个实施例,载片优先级化可以基于紧迫性。诊断可能对患者的医疗过程至关重要。根据病例的临床紧迫性对病理复查/诊断进行优先级化,可提高外科医师、病理学家、临床医师和患者之间的沟通效率。紧迫性可能很难检测到,因为许多临床情境涉及到没有既往癌症史的患者,其表现为体内有“肿块”。结果可能是首次意外的癌症诊断。在不存在或不可获得任何知识的情况下,“用户输入”可以定义何时认为某个病例“紧迫”。例如,临床医师可能会致电病理学家,并指出给定病例为紧迫病例。在这种情况下,人员/临床医师可能要求加急处理该病例。目前,临床医师可能会手动将样本标记为具有“加急”状态。样本可以包括来自新疑似癌症诊断患者的“肿块”。可将加急状态告知处理样本/病例的病理学家。当病理学家收到一组完成的载片时,病理学家可优先复查与“加急”样本相关联的载片。
117.图7示出了用于开发基于用户输入的优先级化工具的示例性方法。例如,示例性方法700和720(例如,步骤701-725)可以由载片优先级化工具101自动地或响应于来自用户(例如,医师、病理学家等)的请求来执行。
118.根据一个实施例,用于开发基于用户输入的优先级化工具的示例性方法700可以包括以下步骤中的一个或多个。在步骤701中,该方法可以包括创建跨癌症亚型和组织样本(例如,组织学、细胞学、血液学、微ct等)的数字化病理图像的数据集。在步骤703中,该方法可以包括接收或确定针对数据集中的每个病理图像的一个或多个标签(例如,载片形态、诊断、结果、难度等)。另外的示例性基于用户的优先级标签可以包括患者紧迫性、临床问题的诊断相关性、临床分类登记、已表现出的风险因素和/或用户输入。在步骤705中,该方法可以包括将每个图像及其对应的标签存储在数字存储设备(例如,硬盘、网络驱动器、云存储、ram等)中。
119.在步骤707中,该方法可以包括训练基于计算病理学的机器学习算法,该基于计算病理学的机器学习算法采用病理样本的一个或多个数字图像作为输入,然后预测每个数字图像的优先级排序。实现机器学习算法的不同方法可以包括但不限于:(1)cnn(卷积神经网络);(2)mil(多实例学习);(3)rnn(递归神经网络);(4)通过cnn进行特征聚合;和/或(5)特征提取然后是集成方法(例如,随机森林)、线性/非线性分类器(例如,svm、mlp和/或降维技术(例如,pca、lda等)。示例特征可以包括来自cnn的向量嵌入、来自cnn的单类/多类输出、和/或来自cnn的多维输出(例如,原始图像的掩模覆盖)。cnn可以直接从像素学习分类任务的特征表示,这可以得到更好的诊断性能。当区域的详细注释或逐像素标签可用时,如果有大量加标签的数据,则可以直接对cnn进行训练。然而,当标签仅在整个载片水平或在一组载片的集合上(在病理学中可称为“部分”)时,mil可用于训练cnn或另一神经网络分类器,其中mil学习对于分类任务而言是诊断性的图像区域,从而得到在没有穷尽注释的情况下学习的能力。可以对从多个图像区域(例如,图块)提取的特征使用rnn,然后对其进行处理以进行预测。其他机器学习方法,例如,随机森林、svm和许多其他方法,可以与由cnn、具有mil的cnn学习的特征一起使用,或者使用手工制作的图像特征(例如,sift或surf)来执行分类任务,但是当直接从像素训练时,它们可能表现不佳。当有大量带注释的训练数据可用时,与基于cnn的系统相比,这些方法有可能表现不佳。在使用上述任何分类器之前,可以将降维技术用作预处理步骤,这在可用数据很少的情况下非常有用。
120.针对图2的机器学习算法的上述描述(例如,表1和相应描述)也可以应用于图7的机器学习算法。
121.使用基于用户输入的优先级化工具的示例性方法720可以包括以下一个或多个步骤。在步骤721中,该方法可以包括接收对应于用户的数字病理图像。在步骤723中,该方法可以包括确定与接收的数字病理图像相关联的载片和/或病例的排序顺序或统计量。可以通过将经训练的计算病理学机器学习算法(例如,方法700的算法)应用于接收到的图像来确定排序顺序或统计量。排序顺序或统计量可用于针对与接收的图像相关联的载片或与接收的图像相关联的病例的复查或额外载片制备进行优先级化。在该情况下,排序顺序或统计量可以包括与在数字病理图像中检测到的诊断特征相关联的统计量。
122.在步骤725中,该方法可以包括输出排序顺序或统计量。一个输出可以包括基于偏好、启发式、统计量、用户的目标(例如,效率、难度、紧迫性等)按顺序确定和/或显示一个或多个变化。替换地或附加地,输出可以包括基于所生成的顺序在病例级别对接收的图像进行视觉排序。例如,这种视觉排序可以包括显示,该显示包括基于目标特征的最大或最小载片概率、基于目标特征跨所有载片的平均概率、基于示出目标特征的原始载片数量等排序的病例排序。视觉排序可以由用户和/或通过计算来执行。另一输出可以包括基于所生成的顺序在每个病例内在载片级别或块级别上的排序的可视化。又一输出可以包括基于所确定的排序顺序或统计量(例如,步骤725)的病例完成时间估计。时间估计可以基于方法700的算法,以及载片制备或处理的队列中的其他载片/病例。输出可以包括向医师提供时间估计。另一实施例可以包括在完成报告、诊断或载片制备时通知转诊医师。
123.图8示出了根据本公开的示例性实施例的示例性方法,其用于对病例进行优先级化并将病例分发给病理学家,以满足机构对每个病例的所需周转时间(例如,48小时)、患者紧迫度需求、人员配置约束等。例如,示例性方法800和820(例如,步骤801-825)可以由载片优先级化工具101自动地响应于来自用户(例如,医师、病理学家等)的请求来执行。
124.根据一个实施例,一种方法可以包括对病例进行优先级化并将病例分发给病理学家,以满足机构对每个病例的所需周转时间(例如,48小时)、患者紧迫度需求、人员配置约束等。如图8所示,用于开发病例分配优先级化工具的示例性方法800可以包括以下步骤中的一个或多个。在步骤801中,该方法可以包括创建跨癌症亚型和组织样本(例如,组织学、细胞学、血液学、微ct等)的数字化病理图像的数据集。在步骤803中,该方法可以包括接收或确定针对数据集中的每个病理图像的一个或多个标签(例如,载片形态、诊断、结果、难度等)。步骤803可以包括接收另外的输入,例如,机构/实验室网络/组织学实验室/病理学家要求和/或约束。在步骤805中,该方法可以包括将每个图像及其对应的标签存储在数字存储设备(例如,硬盘、网络驱动器、云存储、ram等)中。
125.在步骤807中,该方法可以包括训练基于计算病理学的机器学习算法,该基于计算病理学的机器学习算法采用(1)病理样本的一个或多个数字图像和/或(2)系统/工作流程要求/约束作为输入,然后预测每个数字图像的优先级排序(例如,步骤807)。实现机器学习算法的不同方法可以包括但不限于:(1)cnn(卷积神经网络);(2)mil(多实例学习);(3)rnn(递归神经网络);(4)通过cnn进行特征聚合;和/或(5)特征提取然后是集成方法(例如,随机森林)、线性/非线性分类器(例如,svm、mlp和/或降维技术(例如,pca、lda等)。示例特征可以包括来自cnn的向量嵌入、来自cnn的单类/多类输出、和/或来自cnn的多维输出(例如,原始图像的掩模覆盖)。cnn可以直接从像素学习分类任务的特征表示,这可以得到更好的诊断性能。当区域的详细注释或逐像素标签可用时,如果有大量加标签的数据,则可以直接
对cnn进行训练。然而,当标签仅在整个载片水平或在一组载片的集合上(在病理学中可称为“部分”)时,mil可用于训练cnn或另一神经网络分类器,其中mil学习对于分类任务而言是诊断性的图像区域,从而得到在没有穷尽注释的情况下学习的能力。可以对从多个图像区域(例如,图块)提取的特征使用rnn,然后对其进行处理以进行预测。其他机器学习方法,例如,随机森林、svm和许多其他方法,可以与由cnn、具有mil的cnn学习的特征一起使用,或者使用手工制作的图像特征(例如,sift或surf)来执行分类任务,但是当直接从像素训练时,它们可能表现不佳。当有大量带注释的训练数据可用时,与基于cnn的系统相比,这些方法有可能表现不佳。在使用上述任何分类器之前,可以将降维技术用作预处理步骤,这在可用数据很少的情况下非常有用。
126.针对图2的机器学习算法的上述描述(例如,表1和相应描述)也可以应用于图8的机器学习算法。
127.使用病例分配优先级化工具的示例性方法820可以包括以下一个或多个步骤。在步骤821中,该方法可以包括接收对应于用户的数字病理图像。在步骤823中,该方法可以包括确定与接收的数字病理图像相关联的载片和/或病例的排序顺序或统计量。可以通过将经训练的计算病理学机器学习算法(例如,方法800的算法)应用于接收到的图像来确定排序顺序或统计量。排序顺序或统计量可用于针对与接收的图像相关联的载片或与接收的图像相关联的病例的复查或额外载片制备进行优先级化。在该情况下,排序顺序或统计量可以包括与在数字病理图像中检测到的诊断特征相关联的统计量。
128.在步骤825中,该方法可以包括输出排序顺序或统计量。一个输出可以包括基于偏好、启发式、统计量、用户的目标(例如,效率、难度、紧迫性等)按顺序确定和/或显示一个或多个变化。替换地或附加地,输出可以包括基于所生成的顺序在病例级别对接收的图像进行视觉排序。例如,这种视觉排序可以包括显示,该显示包括基于目标特征的最大或最小载片概率、基于目标特征跨所有载片的平均概率、基于示出目标特征的原始载片数量等排序的病例排序。视觉排序可以由用户和/或通过计算来执行。另一输出可以包括基于所生成的顺序在每个病例内在载片级别或块级别上的排序的可视化。又一输出可以包括生成病例在病理学或亚种医疗团队内或在病理学家网络内的分发和/或分配。另一实施例可以包括将病例分配给特定的病理学家或一组病理学家。可以基于执业医师可用性、先前经验水平、医学专业、患者名册和/或机构/实验室要求和约束来优化所生成的分发或分配。
129.图9示出了根据本公开的示例性实施例的用于基于从病理学家处学习的模式来持续学习和优化优先级化系统的示例性方法。例如,示例性方法900和920(例如,步骤901-925)可以由载片优先级化工具101自动地或响应于来自用户(例如,医师、病理学家等)的请求来执行。该学习和优化过程可以在工具使用时进行。这种持续学习和优化可以允许病理学家体验根据他们的偏好(例如,先查看困难的病例,后查看容易的病例)和习惯(例如,针对特定样本针对某些染色下命令)定制的优先级化工具。
130.根据一个实施例,用于开发个性化工具的示例性方法900包括以下步骤中的一个或多个。在步骤901中,该方法可以包括创建跨癌症亚型和组织样本(例如,组织学、细胞学、血液学、微ct等)的数字化病理图像的数据集。在步骤903中,该方法可以包括接收或确定针对数据集中的每个病理图像的一个或多个标签(例如,载片形态、诊断、结果、难度等)。步骤903可以包括接收或检测另外的输入,例如,用户动作、输入(例如,偏好)、或模式。在步骤
905中,该方法可以包括将每个图像及其对应的标签存储在数字存储设备(例如,硬盘、网络驱动器、云存储、ram等)中。
131.在步骤907中,该方法可以包括训练基于计算病理学的机器学习算法,该基于计算病理学的机器学习算法采用(1)病理样本的一个或多个数字图像和/或(2)用户动作、输入或模式作为输入,然后预测每个数字图像的优先级排序(例如,步骤907)。实现机器学习算法的不同方法可以包括但不限于:(1)cnn(卷积神经网络);(2)mil(多实例学习);(3)rnn(递归神经网络);(4)通过cnn进行特征聚合;和/或(5)特征提取然后是集成方法(例如,随机森林)、线性/非线性分类器(例如,svm、mlp和/或降维技术(例如,pca、lda等)。示例特征可以包括来自cnn的向量嵌入、来自cnn的单类/多类输出、和/或来自cnn的多维输出(例如,原始图像的掩模覆盖)。cnn可以直接从像素学习分类任务的特征表示,这可以得到更好的诊断性能。当区域的详细注释或逐像素标签可用时,如果有大量加标签的数据,则可以直接对cnn进行训练。然而,当标签仅在整个载片水平或在一组载片的集合上(在病理学中可称为“部分”)时,mil可用于训练cnn或另一神经网络分类器,其中mil学习对于分类任务而言是诊断性的图像区域,从而得到在没有穷尽注释的情况下学习的能力。可以对从多个图像区域(例如,图块)提取的特征使用rnn,然后对其进行处理以进行预测。其他机器学习方法,例如,随机森林、svm和许多其他方法,可以与由cnn、具有mil的cnn学习的特征一起使用,或者使用手工制作的图像特征(例如,sift或surf)来执行分类任务,但是当直接从像素训练时,它们可能表现不佳。当有大量带注释的训练数据可用时,与基于cnn的系统相比,这些方法有可能表现不佳。在使用上述任何分类器之前,可以将降维技术用作预处理步骤,这在可用数据很少的情况下非常有用。
132.针对图2的机器学习算法的上述描述(例如,表1和相应描述)也可以应用于图9的机器学习算法。
133.使用该工具的示例性方法920可以包括以下一个或多个步骤。在步骤921中,该方法可以包括接收对应于用户的数字病理图像。在步骤923中,该方法可以包括确定与接收的数字病理图像相关联的载片和/或病例的排序顺序或统计量。可以通过将经训练的计算病理学机器学习算法(例如,方法900的算法)应用于接收到的图像来确定排序顺序或统计量。排序顺序或统计量可用于针对与接收的图像相关联的载片或与接收的图像相关联的病例的复查或额外载片制备进行优先级化。在该情况下,排序顺序或统计量可以包括与在数字病理图像中检测到的诊断特征相关联的统计量。
134.在步骤925中,该方法可以包括输出排序顺序或统计量。一个输出可以包括基于偏好、启发式、统计量、用户的目标(例如,效率、难度、紧迫性等)按顺序确定和/或显示一个或多个变化。替换地或附加地,输出可以包括基于所生成的顺序在病例级别对接收的图像进行视觉排序。例如,这种视觉排序可以包括显示,该显示包括基于目标特征的最大或最小载片概率、基于目标特征跨所有载片的平均概率、基于示出目标特征的原始载片数量等排序的病例排序。视觉排序可以由用户和/或通过计算来执行。另一输出可以包括基于所生成的顺序在每个病例内在载片级别或块级别上的排序的可视化。又一输出可以包括例如基于各病理学家偏好、强项、弱项、可用性等来生成病例在病理学或亚种医疗团队内或在病理学家网络内的分发和/或分配。
135.根据一个实施例,一种方法可以包括进行优化,以便教育和评估病理学家、医科学
生、病理住院医师、研究人员等。为了成为一名有能力的病理学家,医科学生和病理住院医师可能会看许多载片或载片图像,以熟练掌握这一技能。该实施例旨在通过向用户呈现提供最大教育益处的数字病理图像来使该学习过程更高效。例如,所呈现的病理图像可以显示某一疾病的原型、或者检测疾病时的常见混淆/错误点。该实施例可以针对预测和选择从业者可能最需要学习的图像,或者通过使用间隔重复机制。可以基于图像分类有多困难、用户先前是否在识别图像的图像属性或基于图像的诊断中有错误、用户是否应更新他们关于该图像的知识等的函数使用机器学习模型(例如,主动学习或该用户的模型)来计算图像的预测教育值。
136.图10示出了根据本公开的示例性实施例的用于生成和使用教育病理载片优先级化工具的示例性方法。例如,示例性方法1000和1020(例如,步骤1001-1027)可以由载片优先级化工具101自动地或响应于来自用户(例如,医师、病理学家等)的请求来执行。
137.根据一个实施例,用于开发教育工具的示例性方法1000可以包括以下步骤中的一个或多个。在步骤1001中,该方法可以包括创建跨癌症亚型和组织样本(例如,组织学、细胞学、血液学、微ct等)的数字化病理图像的数据集。在步骤1003中,该方法可以包括接收或确定针对数据集中的每个病理图像的一个或多个图像属性标签(例如,载片形态、诊断、结果、难度等)。在步骤1005中,该方法可以包括将每个图像及其对应的标签存储在数字存储设备(例如,硬盘、网络驱动器、云存储、ram等)中。在步骤1007中,该方法可以包括训练基于计算病理学的机器学习算法,该基于计算病理学的机器学习算法采用病理样本的一个或多个数字图像作为输入,然后预测每个数字图像的教育值。实现机器学习算法的不同方法可以包括但不限于:(1)cnn(卷积神经网络);(2)mil(多实例学习);(3)rnn(递归神经网络);(4)通过cnn进行特征聚合;和/或(5)特征提取然后是集成方法(例如,随机森林)、线性/非线性分类器(例如,svm、mlp和/或降维技术(例如,pca、lda等)。示例特征可以包括来自cnn的向量嵌入、来自cnn的单类/多类输出、和/或来自cnn的多维输出(例如,原始图像的掩模覆盖)。cnn可以直接从像素学习分类任务的特征表示,这可以得到更好的诊断性能。当区域的详细注释或逐像素标签可用时,如果有大量加标签的数据,则可以直接对cnn进行训练。然而,当标签仅在整个载片水平或在一组载片的集合上(在病理学中可称为“部分”)时,mil可用于训练cnn或另一神经网络分类器,其中mil学习对于分类任务而言是诊断性的图像区域,从而得到在没有穷尽注释的情况下学习的能力。可以对从多个图像区域(例如,图块)提取的特征使用rnn,然后对其进行处理以进行预测。其他机器学习方法,例如,随机森林、svm和许多其他方法,可以与由cnn、具有mil的cnn学习的特征一起使用,或者使用手工制作的图像特征(例如,sift或surf)来执行分类任务,但是当直接从像素训练时,它们可能表现不佳。当有大量带注释的训练数据可用时,与基于cnn的系统相比,这些方法有可能表现不佳。在使用上述任何分类器之前,可以将降维技术用作预处理步骤,这在可用数据很少的情况下非常有用。
138.针对图2的机器学习算法的上述描述(例如,表1和相应描述)也可以应用于图10的机器学习算法。
139.使用教育工具的示例性方法1020可以包括以下一个或多个步骤。在步骤1021中,该方法可以包括向用户(例如,病理学受训者)显示被预测为具有教育值的病理图像。在步骤1023中,该方法可以包括接收表示图像的一个或多个属性的用户输入。用户输入可以包
括图像属性的估计,例如癌症等级。在步骤1025中,该方法可以包括存储用户的输入和/或修正与所显示的图像相关联的图像难度指标。该工具还可以存储用户输入相对于已存储的图像属性的得分。
140.在步骤1027中,该工具可以向用户提供关于用户输入是否正确的反馈。反馈还可以包括帮助用户改进其对图像属性的识别的指示符。所存储的图像属性的示例性指示符可以例如通过突出显示患有癌症的区域来表示用户应进行查看以识别关键图像属性的地方。这些指示符可以帮助用户了解他们应该查看哪里。反馈还可以标识用户可改进的诊断区域,例如,用户始终未能标识出关键图像属性的地方。该工具的使用可能是重复的。例如,工具可以通过显示另一图像来训练用户,或者基于用户标识已存储的图像属性的能力(或不能)、或者基于用户命令或者其组合。
141.如图11所示,设备1100可以包括中央处理单元(cpu)1120。cpu 1120可以是任何类型的处理器设备,包括例如任何类型的专用或通用微处理器设备。如相关领域的技术人员应当理解的,cpu 1120还可以是多核/多处理器系统中的单个处理器,这样的系统可以单独操作,或者在集群或服务器场中操作的计算设备的集群中。cpu 1120可以连接到数据通信基础设施1110,例如总线、消息队列、网络或多核消息传递方案。
142.设备1100还可以包括主存储器1140,例如随机存取存储器(ram),并且还可以包括辅助存储器1130。辅助存储器1130(例如只读存储器(rom))可以是例如硬盘驱动器或可移动存储驱动器。这种可移动存储驱动器可以包括例如软盘驱动器、磁带驱动器、光盘驱动器、闪存等。在该示例中,可移动存储驱动器以公知的方式从可移动存储单元读取和/或向可移动存储单元写入。可移动存储单元可以包括软盘、磁带、光盘等,其由可移动存储驱动器读取和写入。如相关领域的技术人员应当理解的,这种可移动存储单元通常包括其中存储有计算机软件和/或数据的计算机可用存储介质。
143.在替选实施方案中,辅助存储器1130可包含用于将计算机程序或其他指令加载到设备1100中的其他类似装置。这种装置的示例可以包括程序盒和盒接口(例如在视频游戏设备中找到的)、可移动存储器芯片(例如eprom或prom)和相关插座、以及允许软件和数据从可移动存储单元传送到设备1100的其他可移动存储单元和接口。
144.设备1100还可以包括通信接口(“com”)1160。通信接口1160允许软件和数据在设备1100和外部设备之间传输。通信接口1160可以包括调制解调器、网络接口(例如以太网卡)、通信端口、pcmcia插槽和卡等。经由通信接口1160传送的软件和数据可以是信号形式的,其可以是电子的、电磁的、光学的或能够由通信接口1160接收的其他信号。这些信号可以经由设备1100的通信路径提供给通信接口1160,该通信路径可以使用例如电线或电缆、光纤、电话线、蜂窝电话链路、rf链路或其他通信信道来实现。
145.设备1100还可以包括输入和输出端口1150,以与诸如键盘、鼠标、触摸屏、监视器、显示器等的输入和输出设备连接。当然,各种服务器功能可以以分布式方式在多个类似平台上实现,以便分散处理负载。或者,服务器可以通过对一个计算机硬件平台的适当编程来实现。
146.在本公开中,对组件或模块的引用一般是指在逻辑上可以被分组在一起以执行功能或相关功能组的项。相同的附图标记通常用于表示相同或相似的组件。组件和模块可以用软件、硬件或软件和硬件的组合来实现。
147.上述工具、模块和功能可以由一个或多个处理器来执行。“存储”型介质可以包括计算机、处理器等的任何或所有有形存储器或其相关联的模块,诸如各种半导体存储器、磁带驱动器、磁盘驱动器等,其可以在任何时间提供用于软件编程的非暂时性存储。
148.软件可以通过因特网、云服务提供商或其他电信网络来进行通信。例如,通信可以使得能够将软件从一个计算机或处理器加载到另一个中。如本文所使用的,除非限于非暂时性的、有形的“存储”介质,否则诸如计算机或机器“可读介质”的术语指的是参与向处理器提供指令以供执行的任何介质。
149.前面的一般描述仅是示例性和说明性的,而不是对本公开的限制。通过考虑说明书和本文所公开的本发明的实践,本发明的其他实施例对于本领域技术人员来说应当是显而易见的。说明书和示例仅被认为是示例性的。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。