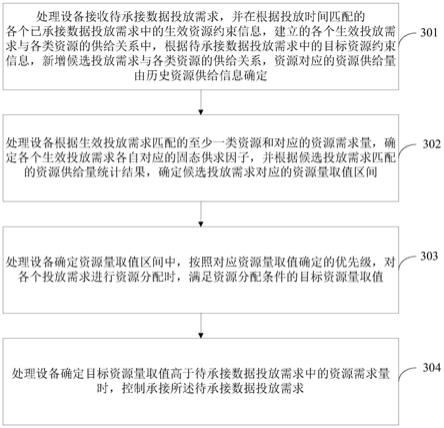
技术特征:
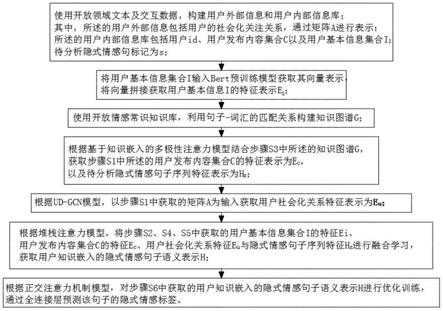
1.一种基于用户知识的个性化隐式情感分析方法,其特征在于:包括以下步骤:s1:使用开放领域文本及交互数据,构建用户外部信息和用户内部信息库;其中,所述的用户外部信息包括用户的社会化关注关系,通过矩阵a进行表示;所述的用户内部信息库包括用户id、用户发布内容集合c以及用户基本信息集合i;待分析隐式情感句标记为s;s2:将用户基本信息集合i输入bert预训练模型获取其向量表示,将向量拼接获取用户基本信息i的特征表示e
i
;s3:使用开放情感常识知识库,利用句子-词汇的匹配关系构建知识图谱g;s4:根据基于知识嵌入的多极性注意力模型结合步骤s3中所述的知识图谱g,获取步骤s1中所述的用户发布内容集合c的特征表示为e
c
,以及待分析隐式情感句子序列特征表示为h
s
;s5:根据ud-gcn模型,以步骤s1中获取的矩阵a为输入获取用户社会化关系特征表示为e
u
;s6:根据堆栈注意力模型,将步骤s2、s4、s5中获取的用户基本信息集合i的特征e
i
、用户发布内容集合c的特征e
c
、用户社会化关系特征e
u
与隐式情感句子序列特征h
s
进行融合学习,获取用户知识嵌入的隐式情感句子语义表示h;s7:根据正交注意力机制模型,对步骤s6中获取的用户知识嵌入的隐式情感句子语义表示h进行优化训练,通过全连接层预测该句子的隐式情感标签2.根据权利要求1所述的一种基于用户知识的个性化隐式情感分析方法,其特征在于:步骤s1中构建的用户社会化关注关系矩阵n为输入数据集包含的用户个数,a
ij
∈{0,1,2,3}表示用户i与用户j之间的社会化关注关系,包括i关注j、j关注i、ij互相关注以及无关系四种类型,用户的基本信息集合i包括用户性别、地域以及个人签名信息。3.根据权利要求1所述的一种基于用户知识的个性化隐式情感分析方法,其特征在于:步骤s3中所述开放情感常识知识库的知识以三元组形式呈现,形式为t=<h,r,t>,其中,h为头实体,r为实体间的关系,t为尾实体。开放情感词典库记为d,需要进行知识匹配的句子记为s,步骤s3中所述句子-词汇匹配关系定义包括如下四种:(1)情感常识三元组筛选:主要用于获取带情感信息的三元组,使用三元组与情感词匹配,确保三元组中的h或t包含情感词,即h∈d或t∈d,且h和t不会同时包含词典d中的词;(2)文本相关三元组筛选:主要用于获取与文本相关的三元组,使用隐式情感数据与筛选后的数据匹配,仅当三元组中的h或t存在于句子s中时,即h∈s或t∈s,且h和t不会同时存在于s中,保留此三元组;(3)关系类型筛选:主要用于获取合适关系类型的三元组,通过人工对一定关系下的三元组的合理性进行判别,即判别h、t和r之间是否出现逻辑问题,选取前十种匹配得到的最多三元组的关系类型,作为要引入的三元组;(4)语义相关三元组筛选:主要用于获取与隐式情感句语义相关的三元组,把三元组转化为一个句子表达以计算其与句子的语义相似度,使用bert模型学习自然语言形式的三元组表达和隐式情感句的表示,并进行余弦相似度计算,所述余弦相似度计算公式为:
其中,e1和e2表示三元组转化的句子与隐式情感句子分别输入bert模型学习得到的向量,对筛选出的三元组计算余弦值并降序排列,选取相似度值前七的三元组引入文本中。4.根据权利要求1所述的一种基于用户知识的个性化隐式情感分析方法,其特征在于:所述步骤s4具体步骤为:s4.1:对于用户u
i
发布内容集合c中的句子,将其合并成一个长文本s
i
;s4.2:根据步骤s3中获取的知识图谱g,合并获取s
i
的知识图谱g
i
,使用transe模型学习获取图谱g
i
中的各知识实体h/t及关系r的特征表示向量e
h
/e
t
、e
r
,使其满足关系:e
h-e
t
≈e
r
;s4.3:通过图注意力层对图谱g
i
进行编码,将g
i
中各知识三元组的实体向量表示拼接,并分别动态计算它们的权重,们的权重,β
ik
=(w
r
r
ik
)σ(w
h
h
ik
w
t
t
ik
)其中,g
i
为长文本s
i
的知识图谱的向量表示,假设图谱g
i
共包括l条知识三元组,分别表示图谱g
i
中的第k组知识三元组g
ik
=<h,r,t>的向量表示,表示向量拼接操作,α
ik
是三元组g
ik
的归一化权重,exp(x)=e
x
为以自然常数e为底的指数函数,β
ik
为三元组g
ik
的权重得分,w
h
,w
t
和分别是h
ik
,t
ik
和r
ik
的参数矩阵,σ(
·
)是非线性激活函数tanh(x),
t
表示向量转置。将词x
i
的表示w
i
与知识图谱的表示g
i
拼接将e
t
作为bilstm的输入单元,进行序列建模学习;行序列建模学习;行序列建模学习;行序列建模学习;行序列建模学习;h
t
=o
t
⊙
tanh(c
t
)其中,w
i
,w
f
和w
o
分别为输入门i
t
、遗忘门f
t
、输出门ο
t
中激活层的参数矩阵;表示临时信息的向量表示,c
t
是控制内部信息传递的变量;h
t
、h
t-1
分别为t时刻与t-1时刻隐层的输出,b
f
,b
i
,b
o
和b
c
为偏置向量;σ(
·
)是非线性激活函数sigmoid(x),tanh()为双曲正切函数,表示向量拼接操作,
⊙
表示向量点积操作;
s4.4:在隐式情感分析中,使用多极性注意模型来捕捉不同极性下注意力权重的差异特征,引入注意力查询向量集合q={q
pos
,q
neg
,q
neu
},q
pos
,q
neg
,q
neu
分别对应褒义、贬义和中性的查询向量,q来自步骤s3中词典d中某一情感极性下的情感词向量的平均,v
q
是句子在褒义、贬义或者中性情感极性q下的表示;褒义、贬义或者中性情感极性q下的表示;褒义、贬义或者中性情感极性q下的表示;其中,是在情感极性q下由隐层表示h
i
计算出的词i的归一化权重,n为句子中词的个数,是h
i
在情感极性q下的注意力得分,exp(x)=e
x
为以自然常数e为底的指数函数,w
q
为参数矩阵,q来自情感词典中某一情感极性下的情感词向量的平均,其中,n为情感词个数,是情感极性为q的情感词的表示;s4.5:将三种极性下的用户发布内容表示和进行拼接,得到内容集合c的新表示为s4.6:同理使用步骤s4.1-s4.5获取隐式情感句子序列特征表示为h
s
。5.根据权利要求1所述的一种基于用户知识的个性化隐式情感分析方法,其特征在于:步骤s5中所述用户社会化关系特征表示为e
u
的获取公式为:其中,n
u
是用户的个数,是除自身外的用户表示向量,是对应元素乘,k为迭代轮次,v
t
是用户间的关注类型,根据关注关系的不同分别设置用户关注关系图中边的权重为四个参数向量v1、v2、v3和v4,分别对应用户间的关注、被关注,互相关注以及无关注四种关系状态。6.根据权利要求1所述的一种基于用户知识的个性化隐式情感分析方法,其特征在于:所述步骤s6具体步骤为:s6.1:分别获取用户基本信息集合i的特征e
i
、用户发布内容集合c的特征e
c
、用户社会化关系特征e
u
与隐式情感句子序列特征h
s
的融合表示c
i
、c
c
和c
u
,融合表示获取公式为:[c
i
,c
c
,c
u
]=stacked-attention([e
i
,e
c
,e
u
],h
s
,h
s
)其中,h
s
为隐式情感句子序列特征,stacked-attention()为堆栈注意力模型函数;s6.2:利用门控机制得到权重向量z
i
、z
c
和z
u
用于度量用户基本信息集合i的特征e
i
、用户发布内容集合c的特征e
c
、用户社会化关系特征e
u
对输出结果的贡献,其公式为:z
i
=σ(w
i
c
i
w
sm
h
s
b
i
)z
c
=σ(w
c
c
c
w
cm
h
s
b
c
)
z
u
=σ(w
u
c
u
w
um
h
s
b
u
)其中,c
i
、c
c
和c
u
为s6.1获得的三种融合表示,h
s
为隐式情感句子序列特征,w
i
,w
sm
,w
c
,w
cm
,w
u
,w
um
分别为各权重向量z
i
、z
c
和z
u
计算过程中的权重矩阵,b
i
,b
c
,b
u
分别为偏置向量,σ(
·
)是非线性激活函数sigmoid(x);s6.3:将门控权重与用户知识、文本信息加权综合得到最终的用户个性化知识嵌入的隐式情感句表示向量h,其公式为:h=z
i
⊙
c
i
z
c
⊙
c
c
z
u
⊙
c
u
。其中,c
i
、c
c
、c
u
以及z
i
、z
c
、z
u
分别为s6.1和s6.2获得的三种融合表示和各自的权重,
⊙
表示向量点积操作。7.根据权利要求1所述的一种基于用户知识的个性化隐式情感分析方法,其特征在于:所述步骤s7中通过全连接层预测该句子的隐式情感标签的公式为:其中,w
out
和b
out
分别为权重矩阵和偏置,采用softmax函数进行归一化。8.根据权利要求1所述的一种基于用户知识的个性化隐式情感分析方法,其特征在于:所述s7训练阶段采用交叉熵损失函数计算预测隐式情感标签和真实标签y之间的损失并进行优化,在模型优化过程中,引入正交注意机制模型来保持注意力之间的差异,具体为:l=γl
classification
(1-γ)l
orthogonalityorthogonality
其中,l为总体损失函数,l
classification
、l
orthogonality
分别为分类损失函数和正交损失函数,x为目标句,y为句子的真实标签,为模型预测的隐式情感句标签,d为训练语料库。q
i
,q
j
∈q为步骤s4中特定情感极性的查询向量,参数γ用于调整两部分损失间的权重。9.一种基于用户知识的个性化隐式情感分析系统,其特征在于:包括数据预处理模块,所述数据预处理模块用于从原始数据中提取处理需要的基本输入数据,筛选出文本中的待分析隐式情感句,并对所有句子进行分词,以及使用开放领域文本数据,预先训练所有词的词向量表示;知识库预处理模块,所述知识库预处理模块用于对开放情感常识知识库进行筛选与过滤,并对所述情感常识三元组中的实体和关系根据transe模型学习其向量表示;用户基本信息特征提取模块,所述用户基本信息特征提取模块用于根据bert预训练模型提取用户基本信息表示,拼接得到用户基本信息特征表示e
i
;用户发布内容特征提取模块,所述用户发布内容特征提取模块用于通过建立基于知识嵌入的多极性注意力模型对用户发布内容进行建模学习,在此过程中通过知识库预处理模块将情感常识知识信息融入用户发布内容的特征表示中,获取用户发布内容特征表示e
c
以及待分析隐式情感句子序列特征h
s
;用户社会化关系特征提取模块,所述用户社会化关系特征提取模块用于根据用户的社
会化关注关系矩阵a,根据所提出的ud-gcn模型学习得到用户社会化关系特征表示e
u
;用户知识融合模块,所述用户知识融合模块用于通过建立的堆栈注意力模型,获取具有用户个性化知识嵌入的隐式情感特征句子语义表示h,并将获取的特征表示经过全连接层进行分类,通过正交注意力机制模型对输入数据进行优化训练,并输出预测的隐式情感句标签
技术总结
本发明公开了计算机文本数据挖掘与隐式情感分析技术领域的一种基于用户知识的个性化隐式情感分析方法和系统,该方法通过对用户的内容知识、社会化属性知识进行建模,得到用户的内部知识表示;针对用户的外部知识,利用社会网络关系学习用户的社会化关系表示;将用户的知识与文本序列信息相融合进行隐式情感分析,本发明解决了隐式情感分析中用户个性化建模的问题,在学习速度和模型精度上均有良好的提升效果。的提升效果。的提升效果。
技术研发人员:廖健 王素格 郑建兴
受保护的技术使用者:山西大学
技术研发日:2022.01.04
技术公布日:2022/4/5
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。