1.本发明涉及脑电信号处理技术领域,具体涉及一种基于改进经验小波变换和k-均值奇异值的脑电信号字典学习方法。
背景技术:
2.脑电信号(electroencephalography,eeg)是一种复杂的生物电信号,通过对脑电信号的深入分析研究,可以更好了解人脑的信息处理过程,加速人们对脑神经结构与生理活动的认知和脑电信号合理应用等各个方面的探索。传统方法按照奈奎斯特采样定理进行信号的采样,然后压缩、编码,最后在接收端进行解压得出原始信号。这种方法必然会产生海量的信号数据,给信号数据的传输和存储带来很大的困难。因此,研究快速、高效的脑电信号采集方式具有重大的实际意义和应用价值。为了克服传统压缩采样方式的弊端,d.l.donoho等人在21世纪初提出了压缩感知技术,这种采集方式在节约存储空间的同时减少了信号采集传输时需要的功耗,减少了采集系统的压力,提高了系统的持久性,在系统硬件方面也得到了改善,减小了系统的体积,增强了系统的便携性。
3.在压缩感知理论中,脑电信号在字典下的系数越稀疏,则信号重构质量越高,所以通过何种方法得到与信号特性相匹配的字典是非常重要的。字典选取是信号压缩感知的重要研究内容之一,获取字典的方式可以划分为两个类别:解析方法和学习方法。解析方法使用一些数学变换和适量的参数来构造字典,这种方法优势在于不复杂,计算较为简单,但缺点也十分明显,由于字典中的原子是根据数学变换得到的,字典原子形态单一,不能与信号本身的复杂结构形成最佳匹配,即非最优表示。近年来学习方法研究有了长足的发展,该方法通过学习信号中的信息,来不断地更新字典中的原子,使得原子包含更加丰富的信息,愈加贴合脑电信号的特性。
4.随着字典学习领域研究的深入,学者们提出了诸多有效的字典学习方法,早期有多成分(multi component dictionary,mcd)字典、奇异值分解(singular value decomposition,svd)字典等。1993年mallat s等人第一次描述了过完备字典的概念,并提出了利用匹配追踪算法来解决过完备字典的稀疏表示问题。aharon m在2006年首先提出了k-奇异值分解算法(k-singular value decomposition,k-svd),这是一种自适应字典学习的稀疏表示方法,随后engan等提出了最优方向法(method ofoptimal directions,mod)算法。现在使用最多的字典学习方法是k-svd算法,与mod算法略有不同,k-svd算法不是对整个字典同时更新,而是对字典原子逐列进行更新,进而学习出能对信号进行稀疏表示的过完备字典。吴建宁等人使用k-svd优化学习算法对脑电信号数据集进行学习,获得了多通道脑电信号的过完备字典。国内外学者将信号特征加入到字典学习当中而不是利用信号本身学字典,从而提高重构信号的效果。为了贴合脑电信号的特性,高畅等人对音频信号使用经验模态分解(empirical mode decomposition,emd)得到的模态分量进行字典学习,使得字典稀疏表示性能更好。
5.综上所述,目前字典学习方法虽然能够对脑电信号进行稀疏表示,但是信号重构
后的质量有待提高,同时不同测试者在不同时间信号本身存在比较大的差异,如果不考虑信号的特性,用信号本身学习字典,使得学习字典对于训练样本的依赖性很大,造成重构准确度低。因此,需要深入研究字典学习方法。
技术实现要素:
6.针对现有字典学习方法对脑电信号稀疏表示性能低的问题,本发明提供一种基于改进经验小波变换和k-均值奇异值的脑电信号字典学习方法(eeg empirical wavelet transform and k-singular value decomposition,eewt-ksvd),使得字典能够对脑电信号特征进行更优的稀疏表示,同时将信号本身的特性考虑在内,减小了学习字典对于训练样本的依赖性,提高重构准确度。
7.为实现上述目的,本技术的技术方案为:基于改进经验小波变换的脑电信号字典学习方法,包括:
8.获取脑电信号数据集;
9.将所述脑电信号数据集中的信号分割成同等长度的脑电信号片段;
10.利用改进经验小波变换方式将所述脑电信号片段分成若干本征模态分量,所述本征模态分量能够反映原始脑电信号本质的特征;
11.对所述原始脑电信号本质的特征进行筛选并放入本征模态分量集合中;
12.在所述本征模态分量集合中随机挑选k个样本作为质心,即随机初始化k个原子,使用k-均值奇异值分解方法进行字典学习,输出训练好的字典;
13.使用所述训练好的字典在重构端进行脑电信号重构。
14.进一步的,所述改进经验小波变换方式,具体为:
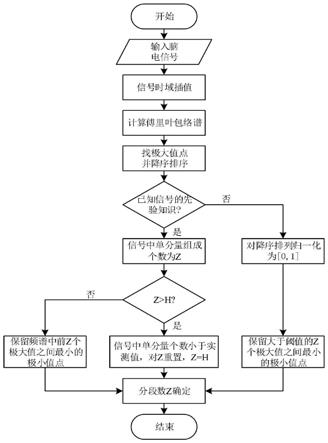
15.对所述脑电信号进行插值运算,并采用频谱包络线进行极值点选取;
16.根据otsu准则自适应确定幅值阈值h;
17.利用所述幅值阈值h对局部极值进行判断,大于幅值阈值的极值对应的下标视为有用边界,相应频带作为被分析脑电信号的有效频带;
18.统计所述有用边界,得到有效的频带区间,获得分解模态数z。
19.进一步的,对所述原始脑电信号本质的特征进行筛选,具体为:利用下式获取每一个本征模态分量和其他本征模态分量之间的相关系数,然后得到每一个本征模态分量的平均相关系数并归一化为[0,1],设定相关系数的绝对值小于0.5为弱相关,因此选取相关度小于0.5的模态;
[0020][0021]
上式中,cov(xi,xj)表示第i个模态和第j个模态的协方差,var[xi]和var[xj]分别表示第i、j个经验小波分解的本征模态分量的方差。
[0022]
本发明由于采用以上技术方案,能够取得如下的技术效果:本发明充分考虑脑电信号的特征,减少字典学习对脑电信号的依赖,通过使用改进经验小波变换方式得到的本征模态分量代替信号进行字典学习。首先,利用改进经验小波变换方法对脑电信号进行分解,得到本征模态分量;其次再对本征模态分量进行筛选;然后,使用基于k均值奇异值分解
的字典学习方法对选择的模态生成自适应字典,实现了无监督的字典学习。本发明方法提升了字典的稀疏表示能力和准确性,进而提高了脑电信号重构的质量。
附图说明
[0023]
图1为改进经验小波变换的确定分段数流程图;
[0024]
图2为基于eewt-ksvd的字典学习整体框图;
[0025]
图3为一段采样点数为256的脑电信号图;
[0026]
图4为三种方法对图3信号的频谱边界分割图;
[0027]
图5为经验小波变换方法得到的模态分量图;
[0028]
图6为三次样条-经验小波变换方法得到的模态分量图;
[0029]
图7为改进经验小波变换得到的模态分量图;
[0030]
图8为四种字典方法重构前后脑电信号对比图。
具体实施方式
[0031]
下面结合附图和具体实施例对本发明作进一步详细的描述:以此为例对本技术做进一步的描述说明。本发明的实施例是在以本发明技术方案为前提下进行实施的,提供基于改进经验小波变换的脑电信号字典学习方法,具体如下:
[0032]
步骤1.获取脑电信号数据集;
[0033]
步骤2.将所述脑电信号数据集中的信号分割成同等长度的脑电信号片段;
[0034]
步骤3.利用改进经验小波变换方式将所述脑电信号片段分成若干本征模态分量,所述本征模态分量能够反映原始脑电信号本质的特征;
[0035]
经验小波变换(empirical wavelet transform,ewt)是一种自适应信号分解方法,该方法继承了emd和wt方法的优点,通过提取频域极大值点自适应地分割傅里叶频谱以分离不同的模态,然后在频域自适应地构造带通滤波器组从而构造正交小波函数,以提取具有紧支撑傅立叶频谱的调幅-调频(am-fm)成分。ewt方法可以分为以下几个过程:
[0036]
第31步:对于一段时域离散脑电信号序列x∈r
n*1
,计算其傅里叶频谱f(x),并且归一化到[0,π];
[0037]
第32步:根据局部极大值法分割频谱,将频谱相邻极大值点之间的中间频率作为边界;
[0038]
第33步:ewt的母小波被定义为使用littlewood-paley和meyer小波的结构来设计每个区间λn上的低通和带通滤波器;所处理的信号为一维脑电信号,使用的是meyer小波,其构造首先定义分割区间λn,然后添加小波窗函数,依据分割的频谱构造其经验尺度函数和经验小波函数
[0039]
[0040][0041][0042]
在上面的几个公式中,ω是频率,ωk是第k个边界频率,γ是转换参数,用来保证两个连续频率之间没有重叠,满足这个特性的函数有很多,常用的是:
[0043]
β(x)=x4(35-84x 70x
2-20x3)
ꢀꢀꢀ
(5)
[0044]
第34步:在构造一组紧支撑后,根据小波变换理论构造ewt,通过尺度函数与小波函数来获取不同的模态分量。由此可得经验小波变换的细节系数和近似系数,公式如式(6)和(7)所示;
[0045]
细节高频系数由信号x和经验小波φn(t)的内积得到:
[0046][0047]
近似低频系数由信号x和经验尺度函数的内积得到:
[0048][0049]
最后,应用傅里叶反变换计算f(x)
×
ψn(t)和从而可得到各个分量的时域表示。
[0050]
由于脑电信号具有随机性、非平稳性,如果直接使用局部极大值的频谱分割方法来分割脑电信号的傅里叶频谱,可能会导致分割不合理,存在数量过多或不足的问题。在截断时域信号时不免造成栅极效应和频谱泄露问题,一方面,一般使用补零的方式减少栅极效应,使频谱的外观更加平滑;另一方面,对数据截短时引起的频域泄漏,有可能在频谱中出现一些难以确认的谱峰,为了避免有用的频谱峰值丢失,从而可以准确找到有用峰值,补零后有可能消除这种现象。同时发现在时域进行插值比在频域插值更容易实现,因此本发现提供一种基于时域插值和频域分割阈值选择的脑电信号频谱分割方法。
[0051]
为了使脑电信号极值点更加清晰,提高寻找极值点速度,首先对脑电信号进行插值运算,同时为了进一步确定极值点,采用频谱包络线来代替原始频谱进行极值点选取。相对于原始频谱,包络谱更加适用于脑电信号的非平稳性;然后根据otsu准则自适应确定幅值阈值h,找到局部极值点以及对应的下标号。利用幅值阈值对局部极值进行判断,大于阈值的极值对应的下标视为有用边界,相应频带作为被分析信号的有效频带。统计有效边界,得到有效的频带区间,便可获得分解模态数z,其过程如图1所示。
[0052]
步骤4.对所述原始脑电信号本质的特征进行筛选并放入本征模态分量集合中;
[0053]
步骤5.在所述本征模态分量集合中随机挑选k个样本作为质心,即随机初始化k个原子,使用k-均值奇异值分解方法进行字典学习,输出训练好的字典;
[0054]
步骤6.使用所述训练好的字典在重构端进行脑电信号重构。
[0055]
上述ewt-ksvd字典学习方法,可以自适应地学习一个表征脑电信号特性的字典。首先对原始的脑电信号进行eewt分解;为了降低字典学习的时间复杂度,然后对得到的所有本征模态分量进行相关性分析,筛选出相关性较小的imf,使用k-svd字典学习算法进行学习,学到一个模态字典。具体的算法整体框架如图2所示。
[0056]
为了验证本发明提出方法的性能,将所提出的eewt-ksvd算法与k-svd算法进行了综合比较。本发明实验数据采用physionet生理信号库中多通道脑电信号运动想象数据库eegmmidb中的数据,此数据集采集了109名志愿者的64通道信号,每一名志愿者进行了14次采集实验。采样频率为256hz,在eeglab中对64通道脑电信号去噪,按照采样点进行分段,每段长度为256,进行归一化操作,然后使用70%的脑电数据训练字典,剩余的30%脑电数据作为评价几种字典的测试集。为了验证提出的改进字典学习算法的性能,比较两种方法构造的字典对于信号稀疏表示的系数的稀疏程度和压缩感知重构的效果,将信号的稀疏指数ρ和重构前后的均方误差(mean square error,mse)来作为衡量字典的客观评价指标。
[0057]
为验证eewt在分解eeg方面的性能,分别利用ewt、eewt以及最常见的在频域三次样条插值包络方法对图3所示的随机一段脑电信号进行分解,图4为频谱边界分割图,三种方法分别分解的模态情况如图5-7所示。
[0058]
通过三种方法检测到的边界如图4(a-c)所示,图中虚线是被检测到的边界,表示频谱被划分为许多部分。从频谱分割图可以看出,图4(a)在a和b的位置箭头方向表示频谱被划分时产生无效边界,这将导致无用的分解,即在图中存在不必要的边界;图4(b)只产生了三条边界,c位置表明封闭的频率分量不能被分割,对频谱的分割效率不高,没有将需要的边界检测出来;图4(c)中分割点主要在频谱连续极大值之间的最小的极小值点处,符合ewt的尺度空间分割原则,得到了合理的频谱分割。
[0059]
任何信号都是由本征模态分量imf组成,由图5-7可得,三种方法都将信号分解成了不同数量的imf,每个imf都包含了信号的成分。图5中imf6和imf7极其相似,存在轻微模态混叠问题,产生无用的imf;图6没有将信号的imf完全分离开,产生太少的imf;图7中得到了相对合理的分解结果。同时,ewt的重建误差是3.92e-6,三次样条-ewt的重建误差是3.77e-6,eewt的重建误差是3.46e-6,eewt的误差略小于其他两种方法。因此,eewt在分解eeg方面的性能表现更好。经过实验验证,在对信号做插值时,二倍相对不插值与插三四倍效果更好,误差更小的情况下不需要消耗很长时间,因此本发明所提的插值为二倍插值。
[0060]
由于小波基等一些固定基字典不太适用于大规模非平稳脑电信号字典,重构误差大,目前主要使用k-svd算法来学习一个大规模的超完备字典,基于k-svd算法学习的字典emd-ksvd、ewt-ksvd以及本发明优化字典eewt-ksvd,都是对大规模脑电信号直接或间接进行训练从而得到的学习字典,所以下面主要这四种字典学习算法进行比较。
[0061]
实验中,使用训练集脑电信号分别训练了规模为1024,2048和4096的字典,其中稀疏表示使用正交匹配追踪算法,原子更新使用svd分解算法。为了测量和评价四种字典的稀疏程度,引入稀疏指数进行对比:
[0062]
表1不同规模字典稀疏指数情况表
[0063]
[0064][0065]
表2不同规模字典的稀疏系数矩阵稀疏指数情况表
[0066][0067]
表1是四种字典学习算法对脑电信号数据集学习得到的不同规模字典的稀疏指数情况表,表2是字典对脑电信号进行稀疏表示时稀疏系数矩阵的稀疏情况表。从表1中可以看出,在不同字典规模下,eewt-ksvd学习字典的稀疏指数小于其他三种学习字典的稀疏指数,稀疏指数越小,就代表字典的稀疏表示能力越强,在字典原子数为1024时,k-svd字典的稀疏指数最高,值为2.7063,但eewt-ksvd字典的稀疏指数的值为1.5727,相比k-svd稀疏指数降低了41.89%,比emd-ksvd降低了31.01%,比ewt-ksvd降低了20.16%,字典稀疏效果更明显。在表2中,eewt-ksvd字典对信号稀疏表示的稀疏系数矩阵稀疏指数最低,因此,使用稀疏指数作为学习字典稀疏性的衡量数据指标时,eewt-ksvd的稀疏表示能力更好。
[0068]
为了进一步验证eewt-ksvd方法的有效性,在不同压缩比(分别为0.1、0.2、0.3、0.4、0.5)和字典规模下,对四种方法学习到的字典进行精确度评价,重构前后信号的均方误差进行比较结果如表3所示。
[0069]
表3不同压缩比下字典学习算法均方误差情况表
[0070]
[0071][0072]
从表3看出,使用不同字典学习方法得到的字典对信号进行稀疏表示并重构,总体上在字典原子规模相同的条件下,压缩比越大,重构误差越小,因为随着压缩比的增大,也就是测量值数量增加,相同条件下采集到的脑电信号数量越多,所以误差更小;在压缩比相同的情况下,字典的原子规模越大,信号稀疏表示系数中非零值的数量就越多,重构误差也就越小。但是eewt-ksvd的误差相比其他几种方法的误差更小,即重构准确度更高。比如,在压缩比为0.3、字典原子数为1024时,eewt-ksvd比emd-ksvd的误差减少9.70%,比ewt-ksvd减少5.41%,比k-svd减少21.71%,具有更高的实用性。
[0073]
为了更加直观地看出四种不同学习字典对脑电信号压缩感知的重构效果,在压缩比为0.5的时候,随机选取一段信号,使用不同字典对这段信号的重构前后对比如图8所示。
[0074]
由此可知,本发明所提改进经验小波变换字典学习算法优于原始ksvd、emd-ksvd和ewt-ksvd字典学习算法,说明本发明提出的算法对于脑电信号的稀疏表示问题具有一定优势。
[0075]
本发明以稀疏指数和重构均方根误差指标为基础,建立脑电信号字典学习模型,同时对经验小波变换进行改进,得到更加合理的模态分割。仿真结果显示,本发明研究的字典学习方法合理有效且易于实现,充分利用了信号自身特性,具有更高的稀疏度和重构准确度。
[0076]
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员
可以理解的其他实施方式。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。