1.本发明涉及智能控制技术领域,尤其涉及用于虚拟自博弈智能体的重放经验池偏置更新方法及装置。
背景技术:
2.绝大多数的现实世界场景应当被建模成非完全信息博弈,这意味着只能提的私有信息或多或少地不为对手所见。现实世界中典型的非完全信息博弈环境包括金融:谈判、竞价、能源交易;社会管理:网络安全、交通管理;部分游戏:扑克、即时战略游戏。理论上来说,非完全信息博弈中最高的收益可以通过寻找并根据纳什均衡策略决策来获得,纳什均衡策略下任何智能体策略与其单方面的偏离都会导致更低的收益。非完全信息博弈可以建模成正则博弈和扩展式博弈,正则博弈通过表格化的方式表示所有策略和状态的可能性,扩展式博弈通过树形结构来表达状态的转移。后者具有较强的表达能力。
3.针对此类博弈活动,在智能控制技术领域,存在基于强化学习和虚拟博弈的非完全信息博弈算法:虚拟自博弈每次迭代中,强化学习策略需要重置为策略开始拟合扩展式虚拟博弈的最佳应对,其计算成本高,求解速度相对于基于博弈论的非完全信息博弈求解算法慢若干数量级。神经网络虚拟自博弈(neura l fi ct it i ous se l f p l ay)通过引入预测性动态(ant i c i patory dynami cs)使得强化学习智能体可以不在每轮迭代重置,进而加速求解过程,并使得整个算法成为端到端的强化学习算法。
4.但是,上述算法的缺陷一是无法有效利用自博弈双方的博弈动态信息:该算法迭代过程中博弈各方的平均策略与最佳应对策略会波动更新,该波动可以用损失函数值来表示。波动的不同动态时刻隐含不同的信息,可用于指导智能体更新策略,而该算法没有利用该信息的机制;二是算法的队列重放经验池存在严重数据过期问题:该算法的强化学习算法为深度q学习,并且该算法与深度q学习高度耦合,意欲使用平均策略的策略经验加入深度q学习的队列重放经验池中加速深度q学习的策略更新。然而随着平均策略本身的迭代,深度q学习的优化目标,即平均策略的最佳应对不断更新。经验池中的老旧数据已经不能准确反映当前q值分布情况,存在过期问题,使得深度q学习的更新存在延迟和偏差,大大影响了算法性能。
技术实现要素:
5.本发明实施例提供一种用于虚拟自博弈智能体的重放经验池偏置更新方法及装置,动态地对新数据赋予较高权重,使得深度q学习网络进行更有效地学习,弱化深度q学习网络更新时的延迟和偏差带来的负面效益。
6.为实现上述目的,本技术实施例的第一方面提供了一种用于虚拟自博弈智能体的重放经验池偏置更新方法,所述方法包括:
7.初始化动态预测参数、阶梯层数、层偏置系数、基础采样偏置系数、采样偏置系数限位比、先后手优势比例和变动烈度系数;
8.根据所述阶梯层数、所述层偏置系数和属于不同队列的多个重放经验池,初始化偏置重放经验池;
9.根据所述动态预测参数,设置策略源为深度q值神经网络或平均策略神经网络;所述深度q值神经网络包括动作q值神经网络和目标q值神经网络;
10.根据强化学习智能体损失函数和对手强化学习智能体损失函数乘以所述先后手优势比例后的差值、所述基础采样偏置系数和所述采样偏置系数限位比和所述变动烈度系数,更新采样偏置系数;
11.根据所述采样偏置系数,对所述偏置重放经验池进行偏置采样,并对偏置采样结果进行随机梯度下降,更新所述动作q值神经网络;
12.根据所述动作q值神经网络周期性地更新所述目标q值神经网络;
13.在监督学习经验池进行采样,并对所述监督学习经验池的采样结果进行随机梯度下降,更新所述平均策略神经网络;
14.调用目前所述策略源,采样一个当前动作并执行,获得下一个状态的状态值及下一个状态的奖励值,并将含有当前状态的状态值、所述当前动作、所述下一个状态的状态值、所述下一个状态的奖励值的元组存入所述偏置重放经验池。
15.在第一方面的一种可能的实现方式中,在所述调用目前所述策略源,采样一个当前动作并执行,获得下一个状态的状态值及下一个状态的奖励值,并将含有当前状态的状态值、所述当前动作、所述下一个状态的状态值、所述下一个状态的奖励值的元组存入所述偏置重放经验池之后,还包括:
16.若目前所述策略源为深度q值神经网络,那么将含有当前状态的状态值、所述当前动作的元组存入所述监督学习经验池。
17.在第一方面的一种可能的实现方式中,所述采样偏置系数是在所述偏置重放经验池中进行采样的依据,用于指定旧加入的经验被采样到的概率与新加入的经验被采样到的概率之比。
18.在第一方面的一种可能的实现方式中,所述根据所述采样偏置系数,对所述偏置重放经验池进行偏置采样,具体包括:
19.对所述偏置重放经验池的各层按照各层对应数目进行均匀概率采样,采样后返回各层采样结果的并集。
20.在第一方面的一种可能的实现方式中,所述将含有当前状态的状态值、所述当前动作、所述下一个状态的状态值、所述下一个状态的奖励值的元组存入所述偏置重放经验池,具体包括:
21.含有当前状态的状态值、所述当前动作、所述下一个状态的状态值、所述下一个状态的奖励值的元组加入所述偏置重放经验池的第一层队列头部,逐层将队尾最后一个经验被放入下一层队列头部。
22.本技术实施例的第二方面提供了一种用于虚拟自博弈智能体的重放经验池偏置更新装置,包括:
23.参数初始化模块,用于初始化动态预测参数、阶梯层数、层偏置系数、基础采样偏置系数、采样偏置系数限位比、先后手优势比例和变动烈度系数;
24.经验池初始模块,用于根据所述阶梯层数、所述层偏置系数和属于不同队列的多
个重放经验池,初始化偏置重放经验池;
25.根据所述动态预测参数,设置策略源为深度q值神经网络或平均策略神经网络;所述深度q值神经网络包括动作q值神经网络和目标q值神经网络;
26.系数更新模块,用于根据强化学习智能体损失函数和对手强化学习智能体损失函数乘以所述先后手优势比例后的差值、所述基础采样偏置系数和所述采样偏置系数限位比和所述变动烈度系数,更新采样偏置系数;
27.动作q值更新模块,用于根据所述采样偏置系数,对所述偏置重放经验池进行偏置采样,并对偏置采样结果进行随机梯度下降,更新所述动作q值神经网络;
28.目标q值更新模块,用于根据所述动作q值神经网络周期性地更新所述目标q值神经网络;
29.平均策略更新模块,用于在监督学习经验池进行采样,并对所述监督学习经验池的采样结果进行随机梯度下降,更新所述平均策略神经网络;
30.经验池更新模块,用于调用目前所述策略源,采样一个当前动作并执行,获得下一个状态的状态值及下一个状态的奖励值,并将含有当前状态的状态值、所述当前动作、所述下一个状态的状态值、所述下一个状态的奖励值的元组存入所述偏置重放经验池。
31.相比于现有技术,本发明实施例提供的一种用于虚拟自博弈智能体的重放经验池偏置更新方法及装置,利用各智能体距离优化目标差距的博弈动态信息对原重放经验池中数据进行赋权的方法,有效根据各方博弈动态信息,对虚拟自博弈智能体中内嵌的深度q学习智能体的队列重放经验池中的数据过期情况进行度量,进而动态地对新数据赋予较高权重,用于下次采样。指导深度q学习智能体进行更有效地学习,弱化其更新时的延迟和偏差带来的负面效益;还对在不同时刻进入重放经验池的样本能够依照其进入时刻赋予权重并依照该权重进行采样的先入先出队列重放经验池,新构成的重放经验池为偏置重放经验池,采样时间复杂度低至o(k),其中k为采样数,其数量级一般为102,这使得依权重采样的先入先出队列在使用中具备计算可行性。
32.综上,通过偏置重放经验池与神经网络虚拟自博弈集成,形成一种高效求解非完全信息博弈中纳什均衡的方法,在求解过程中具有良好的性能表现。
附图说明
33.图1是本发明一实施例提供的一种用于虚拟自博弈智能体的重放经验池偏置更新方法的流程示意图;
34.图2是本发明一实施例提供的一种偏置经验池初始化示意图;
35.图3是本发明一实施例提供的一种对偏置重放经验池进行偏置采样的流程示意图;
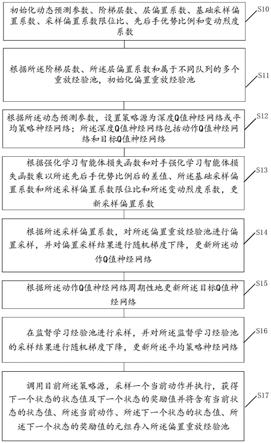
36.图4是本发明一实施例提供的一种种偏置经验池更新示意图。
具体实施方式
37.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他
实施例,都属于本发明保护的范围。
38.请参见图1,本发明一实施例提供了一种用于虚拟自博弈智能体的重放经验池偏置更新方法,所述方法包括:
39.s10、初始化动态预测参数、阶梯层数、层偏置系数、基础采样偏置系数、采样偏置系数限位比、先后手优势比例和变动烈度系数。
40.s11、根据所述阶梯层数、所述层偏置系数和属于不同队列的多个重放经验池,初始化偏置重放经验池。
41.s12、根据所述动态预测参数,设置策略源为深度q值神经网络或平均策略神经网络;所述深度q值神经网络包括动作q值神经网络和目标q值神经网络。
42.s13、根据强化学习智能体损失函数和对手强化学习智能体损失函数乘以所述先后手优势比例后的差值、所述基础采样偏置系数和所述采样偏置系数限位比和所述变动烈度系数,更新采样偏置系数。
43.s14、根据所述采样偏置系数,对所述偏置重放经验池进行偏置采样,并对偏置采样结果进行随机梯度下降,更新所述动作q值神经网络。
44.s15、根据所述动作q值神经网络周期性地更新所述目标q值神经网络。
45.s16、在监督学习经验池进行采样,并对所述监督学习经验池的采样结果进行随机梯度下降,更新所述平均策略神经网络。
46.s17、调用目前所述策略源,采样一个当前动作并执行,获得下一个状态的状态值及下一个状态的奖励值,并将含有当前状态的状态值、所述当前动作、所述下一个状态的状态值、所述下一个状态的奖励值的元组存入所述偏置重放经验池。
47.s10~s11涉及初始化博弈环境、初始化博弈各方智能体,这是为了模拟之后的虚拟自博弈。其中,每个博弈参与方初始化的智能体包括以下内容:
48.初始化参数。初始化动态预测参数η,阶梯层数l,层偏置系数ρ,基础采样偏置系数ω,采样偏置系数限位比λ,先后手优势比例ζ,变动烈度系数ψ。
49.初始化各智能体包含的经验池。初始化监督学习蓄水池经验池m
sl
。以参数l,ρ初始化深度q学习偏置重放经验池m
rl
。其中,l为重放经验池层数,ρ为各层所能容纳的最大经验数之比。如图2所示,图2描述的是某一个偏置重放经验池m
rl
容量满时的情形,该经验池阶梯层数l为3,层偏置系数ρ为2。每一层经验池为原来的队列重放经验池,这三层大小不同的队列重放经验池组成偏置经验池。实际上,它们组成的是一个多级队列结构。
50.初始化神经网络。初始化动作q值神经网络q(s,a|θq)用于深度q学习,其参数θq随机初始化。初始化平均策略神经网络π(s,a|θ
π
)用于监督学习,其参数θ
π
随机初始化。初始化目标q值神经网络参数θq′
用于深度q学习。
51.需要说明的是,在本发明实施例是在神经网络虚拟自博弈的框架下进行创新的,这个框架需要对内嵌深度q学习所做出的所有历史决策进行平均以获得非完全信息博弈下的纳什均衡这个最优策略。所以内嵌两个智能体,两个智能体分别内嵌一组神经网络,一组(动作q值神经网络和目标q值神经网络)用于深度q学习,在深度q学习中,为了降低策略波动,需要使用两套神经网络参与:θq与θq′
。具体的做法是每次训练只更新前者,后者周期性地与前者同步;另一组(平均策略神经网络)则是用于监督学习。监督学习是指用机器学习方法拟合深度q学习所做出的所有历史决策(策略)的平均。
52.示例性地,在所述调用目前所述策略源,采样一个当前动作并执行,获得下一个状态的状态值及下一个状态的奖励值,并将含有当前状态的状态值、所述当前动作、所述下一个状态的状态值、所述下一个状态的奖励值的元组存入所述偏置重放经验池之后,还包括:
53.s18、若目前所述策略源为深度q值神经网络,那么将含有当前状态的状态值、所述当前动作的元组存入所述监督学习经验池。
54.将新的经验按照采样策略加入到不同经验池。其好处在于,加入m
rl
的经验是为了使深度q学习尽量学习靠近其优化目标:“最佳应对策略”的策略。加入m
sl
是为了使平均策略神经网络π(s,a|θ
π
)通过监督学习对深度q学习所做出的所有历史决策进行平均以获得非完全信息博弈下的纳什均衡策略。
55.将新的经验按照采样策略加入到不同经验池。其好处在于,加入m
rl
的经验是为了使深度q学习尽量学习靠近其优化目标:“最佳应对策略”的策略。加入m
sl
是为了使平均策略神经网络π(s,a|θ
π
)通过监督学习对深度q学习所做出的所有历史决策进行平均以获得非完全信息博弈下的纳什均衡策略。
56.相比于现有技术,本发明实施例提供的一种用于虚拟自博弈智能体的重放经验池偏置更新装置,利用各智能体距离优化目标差距的博弈动态信息对原重放经验池中数据进行赋权的方法,有效根据各方博弈动态信息,对虚拟自博弈智能体中内嵌的深度q学习智能体的队列重放经验池中的数据过期情况进行度量,进而动态地对新数据赋予较高权重,用于下次采样。指导深度q学习智能体进行更有效地学习,弱化其更新时的延迟和偏差带来的负面效益;还对在不同时刻进入重放经验池的样本能够依照其进入时刻赋予权重并依照该权重进行采样的先入先出队列重放经验池,新构成的重放经验池为偏置重放经验池,采样时间复杂度低至o(k),其中k为采样数,其数量级一般为102,这使得依权重采样的先入先出队列在使用中具备计算可行性。
57.综上,通过偏置重放经验池与神经网络虚拟自博弈集成,形成一种高效求解非完全信息博弈中纳什均衡的方法,在求解过程中具有良好的性能表现。
58.示例性地,所述采样偏置系数是在所述偏置重放经验池中进行采样的依据,用于指定旧加入的经验被采样到的概率与新加入的经验被采样到的概率之比。
59.在实际应用中,一般使用以下公式更新采样偏置系数ω:
60.ω=max(ωλ,min(ω,ω-ψ(loss
self-ζloss
oppo
)));
61.采样偏置系数用于在重放经验池m
rl
中进行采样,用于指定旧加入的经验被采样到的概率与新加入的经验被采样到的概率之比,随着强化学习智能体自身与优化目标的差距增大而减小。在计算公式中,
62.最内层(“loss
self-ζloss
oppo”)计算的是智能体内嵌强化学习智能体策略与优化目标的差距,在这里用其强化学习智能体损失函数loss
self
与对手强化学习智能体损失函数loss
oppo
乘以其先后手优势比例ζ之差来表示,该差值越大,意味着智能体自身的相较于对手而言,距离优化目标差距越大。先后手优势比例表示在自然情况下对手损失函数与自身损失函数比例,这个值随着博弈不同,先后手位置不同而变化,是一个经验值。
63.对上一步结果(“(loss
self-ζloss
oppo
)”)乘以变动烈度系数ψ,将衡量出的距离优化目标差距缩放至一定范围内,用于调整采样偏置系数。
64.用基础采样偏置系数ω减去上一步结果(“ψ(loss
self-ζloss
oppo
)”)。这个结果
(“ω-ψ(loss
self-ζloss
oppo
)”)将随着智能体自身距离优化目标差距增大而减小。该值越小,新加入经验被采样到的概率就越大。
65.为了避免距离优化目标太大导致上一步结果(“ω-ψ(loss
self-ζloss
oppo
)”)为负,或过大,需要对上一步结果进行截取,将其控制在[ωλ,ω]范围内。所以使用一个max和一个min函数来实现(“max(ωλ,min(ω,ω-ψ(loss
self-ζlossoppo”)。
[0066]
示例性地,所述根据所述采样偏置系数,对所述偏置重放经验池进行偏置采样,具体包括:
[0067]
对所述偏置重放经验池的各层按照各层对应数目进行均匀概率采样,采样后返回各层采样结果的并集。
[0068]
请参见图3,使用偏置系数ω在偏置经验池m
rl
上采样一组经验数据。
[0069]
为了方便说明,本实施例实现于“采样数据批大小n=7,偏置系数ω=0.6”的情形。采样过程分为以下几步(设采样数据批大小为n):
[0070]
(1)设置重放经验池中各层采样概率p,其概率在第一层为1,并按层以偏置系数ω比例递减,即pi=ω
i-1
,其中i为所处层数;
[0071]
(2)设置重放经验池中各层实际采样数比例υ,它表示了在该层中进行采样数目占采样批数据总数的比例。它的计算公式为
[0072]
(3)设置各层采样数n,它是各层中实际进行采样的数目。即ni=nυi,该结果要求为整数,故应当对结果进行四舍五入。若四舍五入后各层采样数n之和小于总采样数小于n,则在各层从前向后分配剩余采样配额;
[0073]
(4)对各层按照对应数目进行均匀概率采样,返回各层采样的结果的并集。
[0074]
使用随机梯度下降在各层采样结果的并集上依照下列损失公式更新q值神经网络参数θq:
[0075][0076]
周期性地(并非每次)将动作q值神经网络参数θq更新至目标q值神经网络参数θq′
,即θq′
←
θq。
[0077]
然后在监督学习经验池m
sl
上采样一批监督数据。
[0078]
使用随机梯度下降在该批监督数据上依照下列损失公式更新平均策略神经网络参数θ
π
:
[0079][0080]
至此,一轮博弈完成。
[0081]
博弈各方智能体完成一轮对局后,在s17中调用当前轮次应执行动作的智能体的策略σ,采样一个动作a
t
,执行它,并获取给出的下一个状态s
t 1
和奖励r
t 1
。
[0082]
示例性地,所述将含有当前状态的状态值、所述当前动作、所述下一个状态的状态值、所述下一个状态的奖励值的元组存入所述偏置重放经验池,具体包括:
[0083]
含有当前状态的状态值、所述当前动作、所述下一个状态的状态值、所述下一个状态的奖励值的元组加入所述偏置重放经验池的第一层队列头部,逐层将队尾最后一个经验被放入下一层队列头部。
[0084]
请参见图4,如果某层没满则在该层停止向下传递经验。如果该层是最后一层则丢弃队尾经验。
[0085]
在实际应用中,本发明实施例在勒杜克扑克(leducpoker)运行有效参数为:η=0.1,l=3,ρ=0.2,ω=0.6,λ=0.5,ζ=0.7,ψ=0.08。
[0086]
本发明实施例综合利用自身与对手信息评估自身强化学习智能体在非完全信息博弈中距离优化目标的差距,将偏置重放经验池的结构设计、依照偏置值进行不同权重快速采样的方法并形成一种新的高效基于强化学习和虚拟自博弈的非完全信息博弈算法。
[0087]
本技术另一实施例提供一种用于虚拟自博弈智能体的重放经验池偏置更新装置,包括参数初始化模块、经验池初始模块、根据所述动态预测参数、系数更新模块、动作q值更新模块、目标q值更新模块、平均策略更新模块和经验池更新模块。
[0088]
参数初始化模块,用于初始化动态预测参数、阶梯层数、层偏置系数、基础采样偏置系数、采样偏置系数限位比、先后手优势比例和变动烈度系数。
[0089]
经验池初始模块,用于根据所述阶梯层数、所述层偏置系数ρ和属于不同队列的多个重放经验池,初始化偏置重放经验池。
[0090]
根据所述动态预测参数,设置策略源为深度q值神经网络或平均策略神经网络;所述深度q值神经网络包括动作q值神经网络和目标q值神经网络。
[0091]
系数更新模块,用于根据强化学习智能体损失函数和对手强化学习智能体损失函数乘以所述先后手优势比例后的差值、所述基础采样偏置系数和所述采样偏置系数限位比和所述变动烈度系数,更新采样偏置系数。
[0092]
动作q值更新模块,用于根据所述采样偏置系数,对所述偏置重放经验池进行偏置采样,并对偏置采样结果进行随机梯度下降,更新所述动作q值神经网络。
[0093]
目标q值更新模块,用于根据所述动作q值神经网络周期性地更新所述目标q值神经网络。
[0094]
平均策略更新模块,用于在监督学习经验池进行采样,并对所述监督学习经验池的采样结果进行随机梯度下降,更新所述平均策略神经网络。
[0095]
经验池更新模块,用于调用目前所述策略源,采样一个当前动作并执行,获得下一个状态的状态值及下一个状态的奖励值,并将含有当前状态的状态值、所述当前动作、所述下一个状态的状态值、所述下一个状态的奖励值的元组存入所述偏置重放经验池。
[0096]
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的装置的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赞述。
[0097]
相比于现有技术,本发明实施例提供的一种用于虚拟自博弈智能体的重放经验池偏置更新装置,利用各智能体距离优化目标差距的博弈动态信息对原重放经验池中数据进行赋权的方法,有效根据各方博弈动态信息,对虚拟自博弈智能体中内嵌的深度q学习智能体的队列重放经验池中的数据过期情况进行度量,进而动态地对新数据赋予较高权重,用于下次采样。指导深度q学习智能体进行更有效地学习,弱化其更新时的延迟和偏差带来的负面效益;还对在不同时刻进入重放经验池的样本能够依照其进入时刻赋予权重并依照该权重进行采样的先入先出队列重放经验池,新构成的重放经验池为偏置重放经验池,采样时间复杂度低至o(k),其中k为采样数,其数量级一般为102,这使得依权重采样的先入先出队列在使用中具备计算可行性。
[0098]
综上,通过偏置重放经验池与神经网络虚拟自博弈集成,形成一种高效求解非完全信息博弈中纳什均衡的方法,在求解过程中具有良好的性能表现。
[0099]
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。