1.本技术涉及识别技术领域,具体涉及一种元器件参数识别方法、装置、电子设备及可读介质。
背景技术:
2.随着互联网技术的发展,越来越多的厂家开始通过互联网上的元器件采购平台来进行元器件的采购。通常厂家在进行采购时,根据自己需要的元器件的信息生成物料清单(bill of material,bom)文件,将bom文件导入元器件采购平台进行识别,从而得到所需要的元器件的购买详情。
3.然而,现有的元器件采购平台在通过bom文件中元器件的参数进行识别的时候,只有在bom文件中的参数文本完全无误的时候才能搜索到,若厂家在生成bom文件前输入参数文本时出现了格式错误或者字符错误,则无法成功进行识别,影响元器件的采购。
技术实现要素:
4.为了解决上述技术问题,提出了本技术。本技术的实施例提供了一种元器件参数识别方法、装置、电子设备及可读介质,能够对bom文件中的参数进行更精确地识别。
5.根据本技术的一个方面,提供了一种元器件参数识别方法,包括:从物料清单文件中获取与电子元件对应的元件文本;对所述元件文本进行预处理;对预处理后的所述元件文本进行分词,确定是否能够获得至少一个关键词;以及当能够获得至少一个所述关键词时,确定根据至少一个所述关键词是否能获得至少一个参数词,若是,将至少一个所述参数词作为所述元件文本对应的参数词。
6.在一实施例中,元器件参数识别方法还包括:当能够获得至少一个关键词时,针对每个所述关键词,执行:确定当前关键词中是否包括非标准参数字符;当所述当前关键词中包括所述非标准参数字符时,根据标准参数字符库确定所述非标准参数字符对应的目标标准参数字符,其中,所述标准参数字符库中包括至少一个标准参数字符及每个所述标准参数字符对应的至少一个非标准参数字符;以及将所述非标准参数字符替换为所述目标标准参数字符。
7.在一实施例中,所述元件文本中包括至少一个间隔符;所述对预处理后的所述元件文本进行分词,确定是否能够获得至少一个关键词:按照字符排列顺序对所述元件文本进行扫描;首次扫描到间隔符时,将所述间隔符前的字符作为一个词汇;非首次扫描到间隔符时,将扫描到的当前间隔符和上一间隔符间的字符作为一个词汇;对所述元件文本扫描完成时,将最后扫描到的间隔符之后的字符作为一个词汇;确定每个所述词汇与至少一个预设的标准关键词的相似度;以及将相似度大于阈值的词汇作为所述关键词。
8.在一实施例中,所述确定根据至少一个所述关键词是否能获得至少一个参数词包括:将每个所述关键词作为搜索条件输入预设的参数词模型中进行识别,确定是否能够得到至少一个检索结果,每个所述检索结果对应一个所述参数词。
9.在一实施例中,对所述元件文本进行预处理包括:对所述元件文本进行编码转换;和/或根据预设的允许字符库,将所述元件文本中的非允许字符进行替换;和/或将所述元件文本中的字母字符修改为大写或小写;和/或将所述元件文本中的全角字符转换为半角字符。
10.在一实施例中,所述对所述元件文本进行预处理包括:对所述元件文本进行编码转换;所述对所述元件文本进行编码转换包括:确定所述元件文本的特征信息;将所述特征信息输入预先训练的编码识别模型中,得到识别结果;以及当所述识别结果为非标准编码时,对所述元件文本进行编码转换处理。
11.在一实施例中,所述编码识别模型通过如下方式进行训练:获取标准编码特征信息样本集和非标准编码特征信息样本集;其中,所述样本标准编码特征信息样本集中包括标准编码对应的至少一个特征信息,所述非标准编码特征信息样本集中包括非标准编码对应的至少一个特征信息;以及利用标准编码特征信息样本集和非标准编码特征信息样本集对所述编码识别模型进行训练;其中,在将所述标准编码特征信息样本集作为所述编码识别模型的输入时,将标准编码作为所述编码识别模型的输出结果的比对目标结果;在将所述非标准编码特征信息样本集作为所述编码识别模型的输入时,将非标准编码作为所述编码识别模型的输出结果的比对目标结果。
12.在一实施例中,所述从物料清单文件中获取与电子元件对应的元件文本包括:获取初始物料清单文件;对所述初始物料清单文件进行解析,获取所述初始物料清单文件的目标物料清单数据;根据所述目标物料清单数据,获取所述目标物料清单数据中的列头数据以及每种电子元件的初始元件文本数据;根据所述列头数据,对所述初始元件文本数据进行清洗以及转换,生成解析元件文本数据;以及根据所述列头数据以及所述解析元件文本数据,封装成所述元件文本。
13.根据本技术的另一方面,提供了一种元器件参数识别装置,包括:获取模块,用于从物料清单文件中获取与电子元件对应的元件文本;处理模块,用于对所述元件文本进行预处理;分词模块,用于对预处理后的所述元件文本进行分词,确定是否能够获得至少一个关键词;以及选择模块,用于当获得至少一个关键词时,确定根据每个所述关键词是否对应一参数词,若是,将至少一个所述参数词作为所述元件文本对应的参数词。
14.根据本技术的另一方面,提供了一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序用于执行上述任一所述的元器件参数识别方法。
15.根据本技术的另一方面,提供了一种电子设备,所述电子设备包括:处理器;用于存储所述处理器可执行指令的存储器;所述处理器,用于执行上述任一所述的元器件参数识别方法。
16.本技术提供的一种元器件参数识别方法、装置、电子设备及可读介质,从用户上传的物料清单bom文件中获取与电子元件的参数对应的元件文本,由于用户在生成bom文件时输入的元件文本的格式、字体等并不统一,会对识别结果产生干扰,因此需要对元件文本进行预处理。对预处理后的元件文本进行分词,确定是否能够获得至少一个关键词。若获得了至少一个关键词,确定每个关键词是否对应一个参数词,若是,将参数词作为元件文本对应的参数词。在本发明实施例中,由于用户输入的元件文本中包括的词汇可能并非是完全标准的词汇,因此通过对用户输入的元件文本进行预处理,并对预处理后的元件文本进行分
词,确定是否能够得到关键词,并确定关键词是否对应参数词。由此可见,本发明实施例提供的方案,在用户生成bom 文件时,在电子元件对应的元件文本中,即使输入的并非是标准词汇,也能够通过预处理和分词将元件文本分词并确定是否包括关键词,根据关键词确定是否能够获得参数词,能够更准确地识别元件文本中可能包括的参数词。
附图说明
17.通过结合附图对本技术实施例进行更详细的描述,本技术的上述以及其他目的、特征和优势将变得更加明显。附图用来提供对本技术实施例的进一步理解,并且构成说明书的一部分,与本技术实施例一起用于解释本技术,并不构成对本技术的限制。在附图中,相同的参考标号通常代表相同部件或步骤。
18.图1是本技术一示例性实施例提供的一种元器件参数识别方法的流程示意图。
19.图2是本技术一示例性实施例提供的一种字符替换方法的流程示意图。
20.图3是本技术一示例性实施例提供的一种分词方法的流程示意图。
21.图4是本技术一示例性实施例提供的一种编码转换方法的流程示意图。
22.图5是本技术一示例性实施例提供的一种编码识别模型的训练方法的流程示意图。
23.图6是本技术一示例性实施例提供的一种元器件参数识别装置的结构示意图。
24.图7是本技术一示例性实施例提供的电子设备的结构图。
具体实施方式
25.下面,将参考附图详细地描述根据本技术的示例实施例。显然,所描述的实施例仅仅是本技术的一部分实施例,而不是本技术的全部实施例,应理解,本技术不受这里描述的示例实施例的限制。
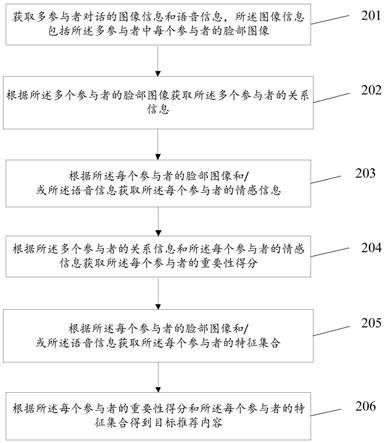
26.如图1所示,本发明一实施例提供了一种元器件参数识别方法,该方法包括以下步骤:
27.步骤110:从物料清单文件中获取与电子元件对应的元件文本。
28.具体地,物料清单bom文件是以数据格式来描述产品结构的文件,是计算机可以识别的数据文件。bom文件的通常以bom表的形式出现。在bom表中,找到电子元件对应的元件文本,即在bom表中找到表头为电子元件的行或列,这些行或列中的文本即为电子元件对应的元件文本。元件文本用于表示用户需要选购的元件的相关信息,但并非一定是与参数有关系的信息,也可能是电子元件其它属性的信息。
29.步骤120:对元件文本进行预处理。
30.具体地,由于用于在生成bom表时输入的元件文本很可能与标准的参数并不完全相符,并且在格式、编码等方面上的错误也可能会导致bom 表无法被识别,因此需要对元件文本进行预处理,消除其它因素的干扰。虽然预处理后的元件文本仍无法被认为是准确且标准的参数名称,但经过预处理后,元件文本中不会存在对识别结果产生干扰的因素,方便进行后续处理。
31.步骤130:对预处理后的元件文本进行分词,确定是否能够获得至少一个关键词。
32.具体地,在清除了干扰因素后,需要对元件文本进行分词。由于用户在输入元件文
本时通常输入的是非结构化数据,即一些数据结构不规则或不完整,没有预定义的数学模型,不方便用数据库二维逻辑表来表现数据,比如办公文档、文本、各类报表等。因此,bom表中输入的的元件文本自然也属于非结构化数据。因此,在进行识别时,需要将非元件文本进行分词。但进行分词之后,元件文本中未必一定会包括关键词。如果不存在关键词,则说明该元件文本无可识别的内容。当至少能够获得一个关键词时,才会进行下一步处理。
33.步骤140:当能够获得至少一个关键词时,确定根据至少一个关键词是否能获得至少一个参数词,若是,将至少一个参数词作为元件文本对应的参数词。
34.具体地,在从元件文本中获得至少一个关键词之后,这些关键词也并非一定对应参数词,有可能对应元件的其它属性。因此,需要确定这些关键词是否均对应一个参数词,若能够获得至少一个参数词,该参数词即为元件文本对应的参数词。参数词为用户需要查找的电子元件的参数构成要素,根据这些参数词,能够从在售的电子元件中选择元件文本对应的电子元件,方便用户进行后续的采购。
35.如图2所示,本发明一实施例提供了一种字符替换方法,当能够获得至少一个关键词时,针对每个关键词,可以执行以下步骤:
36.步骤210:确定当前关键词中是否包括非标准参数字符。
37.具体地,用户在输入元件文本时,可能会自然地根据口头习惯或者习惯书写的符号来进行填写,而并非使用行业特定的写法。比如,在文本中想要填写的内容为“电阻的阻值为1欧姆”,在填写的时候可能会写成 1r,而不是1ω。此时,字母r即为非标准参数字符。虽然用户能够理解 1r表示的是电阻阻值1欧姆,但计算机无法理分辨出该含义,因此需要提前确定关键词中是否包括非标准参数字符。
38.步骤220:当前关键词中包括非标准参数字符时,根据标准参数字符库确定非标准参数字符对应的目标标准参数字符,其中,标准参数字符库中包括至少一个标准参数字符及每个标准参数字符对应的至少一个非标准参数字符。
39.具体地,标准参数字符库中包含多个标准参数字符及每个标准参数字符对应的非标准参数字符,这些非标准参数字符为用户在填写中可能会误填的字符。比如标准字符为ω,表示电阻,对应的,用户在填写时很可能会用r或者r来表示电阻,因此r和r为标准字符ω对应的非标准参数字符。
40.步骤230:将非标准参数字符替换为目标标准参数字符。
41.举例来说,将对应电阻的r、r等非标准参数字符替换为标准参数字符ω。如图3所示,本发明一实施例提供了一种分词方法,元件文本中包括至少一个间隔符,对预处理后的元件文本进行分词,确定是否能够获得至少一个关键词可以包括以下步骤:
42.步骤310:按照字符排列顺序对元件文本进行扫描。
43.具体地,由于元件文本中可能包括电子元件其它的一些信息,在对元件文本进行分词之前,需要按照输入的字符排列顺序进行扫描,确定元件文本中包括哪些字符,方便进行后续的分词处理。通常来说,按照书写习惯的顺序,即从左至右进行扫描。
44.步骤320:首次扫描到间隔符时,将间隔符前的字符作为一个词汇。
45.具体地,在首次扫描到间隔符时,由于间隔符用于将不同字符构成的词汇区分开,形成一个词汇,因此把第一个间隔符前的所有字符作为一个词汇。
46.步骤330:非首次扫描到间隔符时,将扫描到的当前间隔符和上一间隔符间的字符
作为一个词汇。
47.具体地,如前文,间隔符用于区分开不同的词汇,因此两个间隔符之间的字符即为一个词汇。
48.步骤340:对元件文本扫描完成时,将最后扫描到的间隔符之后的字符作为一个词汇。
49.具体地,由于最后一个词汇后没有其他字符,因此也就不会出现间隔符。当元件文本的所有字符均扫描完成后,将最后一个间隔符后面的字符作为一个词汇。
50.步骤350:确定每个词汇与至少一个预设的标准关键词的相似度,将相似度大于阈值的词汇作为参数词。
51.具体地,在分词完成得到多个词汇后,这些词汇并非全部是关键词,因此需要将与关键词无关的词汇排除掉,防止影响后续的结果。标准关键词为一些标准化的用于表示电子元件属性的词汇,如果一词汇与标准关键词的相似度较高,则可以被认为是关键词;若与标准关键词的相似度较低,则表明该词汇与电子元件的属性无关或关系较小,因此不能作为关键词。
52.在本发明实施例中,确定根据至少一个关键词是否能获得至少一个参数词包括:将每个关键词作为搜索条件输入预设的参数词模型中进行识别,确定是否能够得到至少一个检索结果,每个检索结果对应一个参数词。
53.具体地,由于需要选择与关键词最为接近的参数词,通过参数词模型来对每个关键词进行识别。参数词识别模型包括字典,或者是根据关键词的形式,比如数字和单位的组合,从而识别关键词是否为参数词。若无法识别出参数词,则说明该关键词并非对应电子元件的参数。对bom 表中的其它元件文本重复上述步骤,找到对应的参数词。
54.在本发明一实施例中,对元件文本进行预处理可以包括:对元件文本进行编码转换。
55.具体地,bom表中文本通常是基于多语言文本库来实现的,多语言文本库包含了多国语言对应的文本。不同国家的语言往往编码格式不同,例如有utf
‑
8、utf
‑
16以及gbk2312等。在进行文本输入的过程中,很容易造成编码混乱。如果一条文本中包含有多种编码,那么在进行识别到时候会导致识别失败。因此,对元件文本进行编码转换,比如从 gbk2312转换为utf
‑
8(因为utf
‑
8为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码),将元件文本的编码进行统一。
56.在本发明一实施例中,对元件文本进行预处理可以包括:根据预设的允许字符库,将元件文本中的非允许字符进行替换。
57.具体地,bom表中的元件文本中一般会存在干扰字符或者很多不可见字符,这些字符会对分析结果产生干扰。详细来说,在数据处理时有一些是不需要的数据,比如文本中的句号、问号、感叹号等特殊字符,这些字符可以被看做是非允许字符;需要保留的是字母和数字,这些字符可以被看做是允许字符。为了替换这些非允许字符,减少对分析结果的干扰,可以通过正则表达式来将这些非允许字符进行替换。比如,用正则匹配小写“a”到“z”以及大写“a”到“z”以及数字“0”到“9”的范围(该范围即为允许字符库)之外的所有字符并用空格代替。这个方法无需指定所有标点符号。当然,也可以采用其他正则表达式正则匹配所有非a
‑
z、 a
‑
z和0
‑
9的字符,并将其替换为空格。
58.在本发明一实施例中,对元件文本进行预处理可以包括:将元件文本中的字母字符修改为大写或小写。
59.具体地,在英文中,所有句子的第一个单词的首字母一般是大写,有的单词也会全部字母都大写用于表示强调和区分风格,这样更易于人类理解表达的意思。但是计算机在进行识别的时候,无法进行区别。比如“word”、“word”、“word”这三个词对于计算机来说是无法区分的。因此,将元件文本中所有的字母都统一替换为大写或小写,便于进行识别。
60.在本发明一实施例中,对元件文本进行预处理可以包括:将元件文本中的全角字符转换为半角字符。
61.具体地,半角字符为一字符占用一个标准的字符位置,通常的英文字母、数字键、符号键都是半角字符。汉字字符和规定了全角的英文字符及国标gb2312
‑
80中的图形符号和特殊字符都是全角字符。在计算机内部,英文字母、数字键、符号键都是作为基本代码处理的,所以用户输入命令和参数时一般都使用半角。一般的系统命令是不用全角字符的,只是在作文字处理时才会使用全角字符。因此,当元件文本以字母、数字为主时,需要将元件文本中的全角字符转换为半角字符。
62.在本发明一实施例中,对元件文本进行预处理包括:对元件文本进行编码转换;如图4所示的一种编码转换方法的流程示意图,对元件文本进行编码转换可以包括以下步骤:
63.步骤410:确定元件文本的特征信息。
64.具体地,每种文本的编码方式都有其各自的特征,即使是同样的文本,也可能在编码上有所不同,可能是gbk2312,也可能是utf
‑
8。在进行编码转换之前需要首先确认元件文本的特征信息,通过特征信息进行后续的处理。
65.步骤420:将特征信息输入预先训练的编码识别模型中,得到识别结果。
66.具体地,将元件文本的特征信息输入预先训练的编码识别模型中,由于编码识别模型通过样本编码的特征信息与样本识别结果训练得到,因此编码识别模型能够根据元件文本的特征信息来进行识别,确定元件文本的编码类型。
67.步骤430:当识别结果为非标准编码时,对元件文本进行编码转换处理。
68.举例来说,元件文本的识别结果为gbk2312,预设的标准编码为 utf
‑
8时,由此确定元件文本的编码类型为非标准编码。如果使用非标准编码的元件文本进行识别,会出现乱码的情况,因此,需要对元件文本进行编码转换处理,将其编码类型转换为utf
‑
8。
69.如图5所示,本发明一实施例提供了一种编码识别模型的训练方法,该方法可以包括以下步骤:
70.步骤510:获取标准编码特征信息样本集和非标准编码特征信息样本集;其中,样本标准编码特征信息样本集中包括标准编码对应的至少一个特征信息,非标准编码特征信息样本集中包括非标准编码对应的至少一个特征信息。
71.步骤520:利用标准编码特征信息样本集和非标准编码特征信息样本集对编码识别模型进行训练;其中,在将标准编码特征信息样本集作为编码识别模型的输入时,将标准编码作为编码识别模型的输出结果的比对目标结果;在将非标准编码特征信息样本集作为编码识别模型的输入时,将非标准编码作为编码识别模型的输出结果的比对目标结果。
72.具体地,编码识别模型是通过将标准编码特征信息样本集和非标准编码特征信息样本集通过机器学习的方法进行训练,其目的是生成一个具有识别目标能力的编码识别模
型;本发明实施例中采用的是cart分类树算法对数据集进行训练;以cart(classification and regression tree)决策树作为机器学习方法,即误差函数为基尼系数的决策树算法为例,应当理解本发明实施例还可以应用深度神经网络(deep neural networks,dnn)、支持向量机(support vector machine,svm)等其他机器学习算法。
73.cart分类树算法的流程包括:
74.采集大量特征信息样本集,对每个特征向量标记其类别,例如,标准编码特征信息标记为1,非标准编码特征信息标记为
‑
1;将标记好类别的特征信息随机划分为验证集和训练集。
75.本技术实施例中,可以令训练集占90%,验证集占10%。
76.本实施例中,采用cart决策树生成算法对训练集进行训练,生成cart 决策树。
77.根据验证集采用决策树后剪枝算法决策树进行后剪枝,得到编码识别模型。
78.具体地,对生成的cart决策树进行后剪枝(postpruning)处理,提高其泛化(generalization)能力,所得到的剪枝后的决策树即为编码识别模型。
79.应当理解的是,本实施例中采用了cart决策树及后剪枝处理作为编码识别模型的训练方法,前述步骤中需要预留一定比例的验证集。在其他实施例中,如采用深度神经网络(deepneural networks,dnn)、支持向量机(support vector machine,svm)等其他机器学习算法,可能将验证集在训练过程中用作其他处理来降低泛化误差或不需要留验证集。
80.在本发明一实施例中,从物料清单文件中获取与电子元件对应的元件文本包括:
81.获取初始物料清单文件;
82.对初始物料清单文件进行解析,获取初始物料清单文件的目标物料清单数据;
83.根据目标物料清单数据,获取目标物料清单数据中的列头数据以及每种电子元件的初始元件文本数据;
84.根据列头数据,对初始元件文本数据进行清洗以及转换,生成解析元件文本数据;以及
85.根据列头数据以及解析元件文本数据,封装成元件文本。
86.具体地,bom文件就是以数据格式来描述产品结构的文件,是计算机可以识别的数据文件,也是电子制造供应链企业联系与沟通主要业务的纽带。初始bom文件为系统所识别到的客户上传的原始bom文件,其数据内容、格式等不尽相同,系统只有在获取得到初始bom文件后,才能进行后续的解析识别过程,便于将各种各样的bom文件进行格式的统一以及错漏的纠正。
87.bom(即物料清单)数据指的是bom文件中用于表示电子元件物料信息的数据,目标bom数据为进行了格式的统一以及错误的纠正后得到的bom数据。在bom数据进行了格式统一以及错误纠正后,系统得以更加准确地识别出电子元器件的物料信息,进而对所需电子元件进行更加准确的报价,降低出现错误报价的概率。
88.列头数据指的是每列bom数据的开头数据;电子元件即电子元器件的简称,其初始元件文本数据指的是未经清洗转换、只是进行了格式的统一以及初步纠错后的用以表示电子元件信息的初始数据。由于列头数据包含了其所在列的信息的种类,先识别列头数据,更加有利于对整列数据进行归类以及清洗。
89.解析元件文本数据为对初始元件文本数据进行清洗转换后的元件文本数据。由于
不同公司的bom表格式不一,人工输入又难以避免会出现错漏,因此,预先清洗数据并进行格式的转化统一,便于系统更加准确地识别物料信息,进而准确报价。而整个解析识别过程由系统进行,无需人力,节省人力成本的同时,再次避免了因工作人员疲劳或经验不足等原因出现的二次错误情况,且识别效率更高。
90.解析元件文本数据即为经过了数据的清洗以及转换后的元件文本数据。在获取到列头数据和解析后的元件文本数据后,输出为解析元件文本的形式,并封装成自定义的json数据进行传递,便于后续系统对其进行报价操作。需要说明的是,此处的解析元件文本数据可以为文件、字符串、数据等多种形式,在日常操作本技术不对解析元件文本数据的具体格式作出限定。
91.如图6所示,本发明一实施例提供了一种参数识别装置,包括:
92.获取模块610,用于从物料清单文件中获取与电子元件对应的元件文本。
93.处理模块620,用于对元件文本进行预处理。
94.分词模块630,用于对预处理后的元件文本进行分词,确定是否能够获得至少一个关键词。
95.确定模块640,用于当能够获得至少一个关键词时,确定根据至少一个关键词是否能获得至少一个参数词,若是,将至少一个参数词作为元件文本对应的参数词。
96.在本发明一实施例中,分词模块630还用于当能够获得至少一个所述关键词时,执行:确定当前关键词中是否包括非标准参数字符;当所述当前关键词中包括所述非标准参数字符时,根据标准参数字符库确定所述非标准参数字符对应的目标标准参数字符,其中,所述标准参数字符库中包括至少一个标准参数字符及每个所述标准参数字符对应的至少一个非标准参数字符;以及将所述非标准参数字符替换为所述目标标准参数字符。
97.在本发明一实施例中,元件文本中包括至少一个间隔符;如图6所示,分词模块630可以包括:
98.扫描单元631,按照字符排列顺序对所述元件文本进行扫描。
99.处理单元632,用于执行:首次扫描到间隔符时,将间隔符前的字符作为一个词汇;非首次扫描到间隔符时,将扫描到的当前间隔符和上一间隔符间的字符作为一个词汇;对元件文本扫描完成时,将最后扫描到的间隔符之后的字符作为一个词汇。
100.相似度确定单元633,用于确定每个所述词汇与至少一个预设的标准关键词的相似度。
101.关键词确定单元634,用于将相似度大于阈值的词汇作为所述关键词。
102.在本发明一实施例中,选择模块640可以包括:
103.检索单元641,用于将每个所述关键词作为搜索条件输入预设的参数词库中进行检索,得到至少一个检索结果,每个所述检索结果对应一个所述参数词。
104.匹配值确定单元642,用于确定每个检索结果与搜索条件的匹配值;
105.参数词确定单元643,用于当存在至少一个匹配值高于预设值的检索结果时,将匹配值最高的检索结果对应的所述参数词作为所述元件文本对应的参数词。
106.在本发明一实施例中,处理模块620在执行对元件文本进行预处理时,具体执行:
107.对元件文本进行编码转换;和/或根据预设的允许字符库,将元件文本中的非允许字符进行替换;和/或将元件文本中的字母字符修改为大写或小写;和/或将元件文本中的
全角字符转换为半角字符。
108.在本发明一实施例中,对元件文本进行预处理包括:对元件文本进行编码转换;如图6所示,处理模块620可以包括:
109.特征确定单元621,确定元件文本的特征信息;输入单元622,将特征信息输入预先训练的编码识别模型中,得到识别结果;转换单元623,当识别结果为非标准编码时,对元件文本进行编码转换处理。
110.下面,参考图7来描述根据本技术实施例的电子设备。该电子设备可以是第一设备和第二设备中的任一个或两者、或与它们独立的单机设备,该单机设备可以与第一设备和第二设备进行通信,以从它们接收所采集到的输入信号。
111.图7图示了根据本技术实施例的电子设备的框图。
112.如图7所示,电子设备70包括一个或多个处理器71和存储器72。
113.处理器71可以是中央处理单元(cpu)或者具有数据处理能力和/或指令执行能力的其他形式的处理单元,并且可以控制电子设备70中的其他组件以执行期望的功能。
114.存储器72可以包括一个或多个计算机程序产品,所述计算机程序产品可以包括各种形式的计算机可读存储介质,例如易失性存储器和/或非易失性存储器。所述易失性存储器例如可以包括随机存取存储器(ram)和/或高速缓冲存储器(cache)等。所述非易失性存储器例如可以包括只读存储器 (rom)、硬盘、闪存等。在所述计算机可读存储介质上可以存储一个或多个计算机程序指令,处理器71可以运行所述程序指令,以实现上文所述的本技术的各个实施例的参数方法以及/或者其他期望的功能。在所述计算机可读存储介质中还可以存储诸如输入信号、信号分量、噪声分量等各种内容。
115.在一个示例中,电子设备70还可以包括:输入装置73和输出装置74,这些组件通过总线系统和/或其他形式的连接机构(未示出)互连。
116.在该电子设备是单机设备时,该输入装置73可以是通信网络连接器,用于从第一设备和第二设备接收所采集的输入信号。
117.此外,该输入装置73还可以包括例如键盘、鼠标等等。
118.该输出装置74可以向外部输出各种信息,包括确定出的距离信息、方向信息等。该输出装置74可以包括例如显示器、扬声器、打印机、以及通信网络及其所连接的远程输出装置等等。
119.当然,为了简化,图7中仅示出了该电子设备70中与本技术有关的组件中的一些,省略了诸如总线、输入/输出接口等等的组件。除此之外,根据具体应用情况,电子设备70还可以包括任何其他适当的组件。
120.除了上述方法和设备以外,本技术的实施例还可以是计算机程序产品,其包括计算机程序指令,所述计算机程序指令在被处理器运行时使得所述处理器执行本说明书上述“示例性方法”部分中描述的根据本技术各种实施例的元器件参数识别方法中的步骤。
121.所述计算机程序产品可以以一种或多种程序设计语言的任意组合来编写用于执行本技术实施例操作的程序代码,所述程序设计语言包括面向对象的程序设计语言,诸如java、c 等,还包括常规的过程式程序设计语言,诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备
或服务器上执行。
122.此外,本技术的实施例还可以是计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令在被处理器运行时使得所述处理器执行本说明书上述“示例性方法”部分中描述的根据本技术各种实施例的元器件参数识别方法中的步骤。
123.所述计算机可读存储介质可以采用一个或多个可读介质的任意组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以包括但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。可读存储介质的更具体地例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑盘只读存储器(cd
‑
rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。
124.以上结合具体实施例描述了本技术的基本原理,但是,需要指出的是,在本技术中提及的优点、优势、效果等仅是示例而非限制,不能认为这些优点、优势、效果等是本技术的各个实施例必须具备的。另外,上述公开的具体细节仅是为了示例的作用和便于理解的作用,而非限制,上述细节并不限制本技术为必须采用上述具体地细节来实现。
125.本技术中涉及的器件、装置、设备、系统的方框图仅作为例示性的例子并且不意图要求或暗示必须按照方框图示出的方式进行连接、布置、配置。如本领域技术人员将认识到的,可以按任意方式连接、布置、配置这些器件、装置、设备、系统。诸如“包括”、“包含”、“具有”等等的词语是开放性词汇,指“包括但不限于”,且可与其互换使用。这里所使用的词汇“或”和“和”指词汇“和/或”,且可与其互换使用,除非上下文明确指示不是如此。这里所使用的词汇“诸如”指词组“诸如但不限于”,且可与其互换使用。
126.还需要指出的是,在本技术的装置、设备和方法中,各部件或各步骤是可以分解和/或重新组合的。这些分解和/或重新组合应视为本技术的等效方案。
127.提供所公开的方面的以上描述以使本领域的任何技术人员能够做出或者使用本技术。对这些方面的各种修改对于本领域技术人员而言是非常显而易见的,并且在此定义的一般原理可以应用于其他方面而不脱离本技术的范围。因此,本技术不意图被限制到在此示出的方面,而是按照与在此公开的原理和新颖的特征一致的最宽范围。
128.为了例示和描述的目的已经给出了以上描述。此外,此描述不意图将本技术的实施例限制到在此公开的形式。尽管以上已经讨论了多个示例方面和实施例,但是本领域技术人员将认识到其某些变型、修改、改变、添加和子组合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。